柱面全景视频拼接算法
2019-09-17李晓禹陈杰
文/李晓禹 陈杰
视频拼接技术将多路具有重叠区域的小视野视频拼接为一路完整大视野场景,有效地解决了单个摄像头视野局限性的问题,在虚拟现实、智能监控等领域有着广泛的应用。
视频图像是由每秒若干帧的静态图像组成的,所以视频拼接的本质是图像拼接,而图像配准又是图像拼接最核心的一步,通常使用的方法是基于图像特征的配准。David G.Lowe 提出的尺度不变特征算子SIFT[1,2]在图像拼接中被经常使用,但是SIFT 算法的计算速度较慢,无法满足视频实时性的要求,不适合应用于实时视频的拼接。文献[3]在SIFT 算法基础上,提出了一种改进的尺度不变特征—SURF( Speeded Up Robust Features)。文献[4]研究表明:SURF算法提高了特征检测的速度,同时与SIFT 算法性能基本相同。但是视频拼接与图像拼接又有着很大的不同,最大的不同是视频拼接需要有良好的实时性。文献[5]和[6]虽然对SURF算法进行了改进,但是拼接速度仍然达不到实时性的要求。因此,SURF 虽然速度较快,但是为了能将其应用在实时视频拼接中仍需要改进,文中采用一种改进的SURF 算法来进行图像配准。
文中采用的视频拼接流程是:实时地采集视频图像帧,以30帧/s 的速率提取视频帧,提取模板帧,对模板帧多路视频图像利用改进的SURF进行配准以确定变换矩阵,利用这个变换矩阵对后续的每一帧图像进行融合,形成一个大视角的图像,最后将这些图像以视频的形式输出。
1 柱面图像全景拼接算法
图像拼接算法在图像正畸之后的下一个步骤是图像配准。图像配准是为了使图像间相互重叠部分对齐,将待拼接图像转换到参考图像的坐标系,构成完整的图像,它是整个图像拼接中的核心部分。图像配准包括三个方面,即特征提取、特征匹配和确定变换矩阵。
1.1 特征点提取
本文首先要提取模板帧图像的特征并进行匹配。为了加快匹配过程,SURF 在特征矢量中增加了一个新的变量,即特征点的拉普拉斯属性,这两类特征点具有不同的属性,在匹配时只需对同类的特征点进行匹配,这样会大大地提高匹配速度和精度。图像中两个特征点之间相似性的度量一般采用欧氏距离等距离函数进行度量,通过相似性的度量就可以得到待配准图像间的潜在匹配点对。这其实是一个距离检索问题,如果用穷举法则浪费太多时间。由于用标准的K-d 树时,数据集的维数不应该超过20[7],而改进的SURF的维数为16,所以采用K-d 树进行特征匹配。
通常使用比值匹配法,即将其中的一幅图像作为样本,在样本的特征点中寻找在另外一幅图像中与它距离最近的特征点和次近特征点,然后计算这两个特征点与样本点之间欧氏距离的比值。对于比值小于某一阈值范围内的特征点,则认为是正确匹配的特征点。
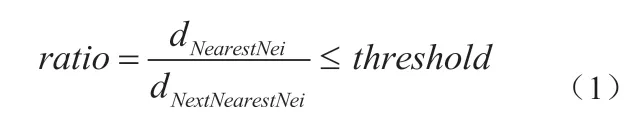
原有的SURF 算法是对整个图像区域提取特征点,然后在整个图像范围内进行特征匹配,由于实际环境中两个摄像头拍摄的画面必然会有重叠区域的存在,所以只需在重叠部分进行特征点提取就可以,这样的好处是可以减少特征提取的时间,进而减少匹配的时间并能减少误匹配。
由于提取的特征点存在误匹配,本文根据相邻两个摄像头之间重叠区域的大小对匹配的特征点进行高效筛选。筛选算法如下:设图像的宽度为Width,重叠区域比例为factor,那么重叠区域的宽度为factor*Width,左边图像的特征点为leftPoints,右边图像的特征点为RightPoints,那么筛选算法如下:如果,leftPoints的cols值大于factor*Width,小于Width,该匹配点保留,否则丢弃;如果,RightPoints的cols值小于(1-factor)*Width,大于0,该匹配点保留,否则丢弃。该算法对重叠区域的之外的匹配特征点对剔除,提高了特征匹配的精准度。避免了重叠区域之外的误匹配特征点对,同时减少了程序的耗时。
1.2 柱面投影
在平面上提取的经过筛选的高度匹配特征点进行柱面投影变换,以便准确计算两幅图像在后期融合时需要的变换量。
如图1所示,两个摄像头环形排列,每个摄像头拍摄到的画面为前方实线,图像拼接就是将两张图像按照重叠区域融合,但是由于图中两个摄像头朝向不同,使得拍摄画面不满足视觉一致性。因此考虑将图像投影到柱面,即摄像头前方弧线上,投影后的图像重叠区域在柱面重合,具有较好视觉一致性。而且柱面图像容易展开为矩形图像,可直接用于图像处理。图1 (b)中点O 为摄像头所在位置,前方矩形为拍摄画面,柱面投影就是将其投影到红色圆柱上。
既然投影后的图像具有较好的视觉一致性,因此先对图像进行柱面投影然后再拼接。源图像Img上一点被映射到Imgcyl上的点。图1(c)是图1(b)的俯视图,其中,Img 的宽AB和摄像头的视角∠AOB均已知,分别是W和α,那么摄像头的焦距f = W/(2×tan (α/2)),的宽度W′ = f×α。因为,PB = x,所以∠AOC = β = arctan ((x -W/2)=f),所以同样的,图1(d)是图1(b)截面图,其中,Img的高为H,PR = y,并且△PQO ~△ P′Q′O,所以可以得到P′R′ 值。坐标变换公式(2)如下:

根据上面的坐标变换公式,可以得到平面上匹配的特征点投影到柱面上的坐标。
1.3 确定变换量
经过柱面投影后的高度匹配特征点集用来进行图像对齐融合。本算法的图像对齐融合操作很简单,只需要利用匹配的特征点集计算出图像之间的平移量,然后将源图像平移到目标图像上即可。1&1图像拼接平移量的计算方法是取所有匹配特征点平移量的平均值作为图像的平移量,计算公式为(3):
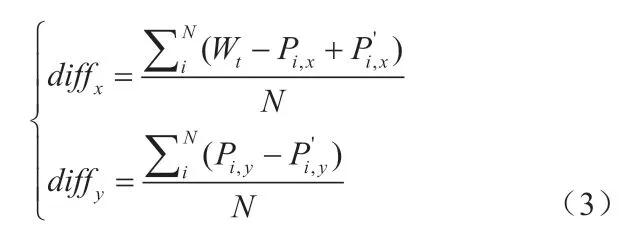
其中,Wt是目标图像宽度,Pi,x是目标图像上的特征点,P'i,x是源图像上的对应特征点,N是匹配的特征点数量,diffx是x方向平移量,diffy是y方向平移量。
图像拼接结果Ires可由源图像I′src和I′tar按照公式(4)平移拼接得到:
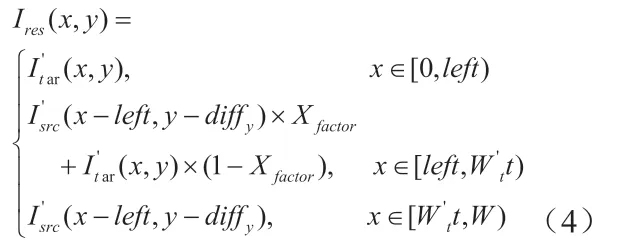
其中,left = I′tar(x, y) - diffx,Xfactor=(xleft)/|diffx|。图像融合过程简单的说就是,左侧区域取自左图,右侧区域取自右图,中间重叠区域为左图右图线性融合。以上是1&1图像拼接的平移量计算。在多路摄像头视频拼接之前,采用公式(3)事先计算好多路摄像头视频帧两两之间的变换矩阵(1&1平移量),以8路摄像头为例,后续2&2,4&4图像拼接的平移量计算需在前次(1&1)拼接变化矩阵的基础上累加。并将每次的平移量保存起来,用于后续视频帧图像的拼接融合。
1.4 模板帧融合
计算好图像之间的平移量之后,就可以对其进行融合。两幅融合之前需要对基于平面坐标的图像进行柱面投影。
在进行柱面全景图的拼接过程中,为了保持实际场景中的空间约束关系和实际场景的视觉一致性,需将拍摄得到的反映各自投影平面的重叠图像序列映射到一个标准的柱面坐标空间上即柱面投影,采用上述公式(2)可以得到源图像Img的柱面投影图像Imgcyl。对每路摄像头图像进行柱面投影,得到柱面图像序列,再进行拼接得到柱面全景图。
柱面投影后的图像具有视觉一致性,可以用来做图像对齐和融合,具体方法为:取左边的图像为目标图像,右边的图像为源图像,源图像在平移量的作用下,可以与目标图像完美融合。
1.5 后续视频帧拼接
后续视频帧图像融合过程中所需的摄像头参数和畸变系统、图像平移量在模板帧处理中就已得到,所以在后续视频帧的融合过程中免于进行摄像头标定、特征检测和匹配以及平移量计算,这对算法速度的提升起到很大作用。
另外,柱面投影变换和图像融合过程都可以使用GPU 的CUDA平台并行加速(CUDA是NVIDIA推出的通用并行计算架构,支持对图像进行并行运算处理)。所以后续视频帧的处理速度快,可以做到实时拼接。实验结果表明,在NVIDIA 1080Ti GPU上运行该算法,可以实时地生成无缝清晰的全景视频。
