浅谈Python爬虫技术的网页数据抓取与分析
2019-09-12吴永聪
吴永聪
摘 要: 近年来,随着互联网的发展,如何有效地从互联网获取所需信息已成为众多互联网企业竞争研究的新方向,而从互联网上获取数据最常用的手段是网络爬虫。网络爬虫又称网络蜘蛛和网络机器人,它是一个程序,可以根据特定的规则和给定的URL自动收集互联网数据和信息。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并利用python实现了一个网络爬虫程序系统。
关键词: 网络爬虫; Python; MySQL; 正则表达式
中图分类号:TP311.11 文献标志码:A 文章编号:1006-8228(2019)08-94-03
Abstract: In recent years, with the development of the Internet, how to effectively obtain the required information from the Internet has become a new direction that many Internet companies are competing to research, and the most common means of obtaining data from the Internet is the web crawler. Web crawlers are also known as web spiders or web robots, it is a program that automatically collects Internet data and information according to a given URL and a specific rule. In this paper, the main issues in the implementation of web crawlers are discussed, such as how to use Python to simulate login, how to use regular expressions to match strings to get information and how to use MySQL to store data, and so on. At the end, a Python-based web crawler program system is realized through the research of Python language.
Key words: web crawler; Python; MySQL; regular expression
0 引言
在网络信息和数据爆炸性增长的时代,尽管互联网信息技术的飞速发展,从如此庞大的信息数据中仍然很难找到真正有用的信息。于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字在Internet上檢索网页,并为用户查找与关键字相关或包含关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要的作用。因此,网络爬虫的研究,对于搜索引擎的发展具有十分重要的意义。对于编写网络爬虫,python有其独特的优势。例如,python中有许多爬虫框架,这使得web爬虫更高效地对数据进行爬行。同时,Python是一种面向对象的解释性高级编程语言。它的语法比其他高级编程语言更简单、更易阅读和理解。因此,使用Python来实现Web爬虫是一个很好的选择。
1 网络爬虫的概述
1.1 网络爬虫的原理
网络爬虫,又称网络蜘蛛和网络机器人,主要用于收集互联网上的各种资源。它是搜索引擎的重要组成部分,是一个可以自动提取互联网上特定页面内容的程序。通用搜索引擎Web爬虫工作流[1]:①将种子URL放入等待抓取URL队列;②将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;③将下载的网页放入下载的网页库;④将下载的网页URL放入已爬URL队列;⑤分析已爬URL队列中的URL提取新的URL被放置在要等待抓取URL队列中,并进入下一个爬网周期。
爬虫的工作流程:①通过URL抓取页面代码;②通过正则匹配获取页面有用数据或者页面上有用的URL;③处理获取到的数据或者通过获取到的新的URL进入下一轮抓取循环。
1.2 网络爬虫的分类
网络爬虫大体上可以分为通用网络爬虫,聚焦网络爬虫[2]。
通用网络爬虫,也叫全网爬虫,它从一个或者多个初始URL开始,获取初始页面的代码,同时从该页面提取相关的URL放入队列中,直到满足程序的停止条件为止。相比于通用网络爬虫,聚焦网络爬虫的工作流程比较复杂,它需要事先通过一定的网页分析算法过滤掉一些与主题无关的URL,确保留下来的URL在一定程度上都与主题相关,把它们放入等待抓取的URL队列。然后再根据搜索策略,从队列中选择出下一步要抓取的URL,重复上述操作,直到满足程序的停止条件为止。聚焦网络爬虫能够爬取到与主题相关度更高的信息,例如:为了快速地获取微博中的数据,可以利用聚焦爬虫技术开发出一个用来抓取微博数据的工具[3-5]。在如今大数据时代,聚焦爬虫能做到大海里捞针,从网络数据海洋中找出人们需要的信息,并且过滤掉那些“垃圾数据”(广告信息等一些与检索主题无关的数据)。
2 Python
Python的作者是一个荷兰人Guido von Rossum,1982年,Guido从阿姆斯特丹大学获得了数学和计算机硕士学位[6]。相比于现在,在他的那个年代里,个人电脑的主频和RAM都很低,这导致电脑的配置很低。为了让程序能够在个人电脑上运行,所有的编译器的核心都是做优化,因为如果不优化,一个大一点的数组就能占满内存。Guido希望编写出一种新的语言,这种语言应该具有功能全面,简单易学,简单易用,并且能够扩展等特点。1989年,Guido开始编写Python语言的编译器。
3 系统分析
本系统是基于Python的网络爬虫系统,用于登录并爬取豆瓣网的一些相册、日记、主题、评论等动态的数据信息。并且能够把通过关键字查询的动态信息数据存储到数据库一些数据保存到数据库,存储到本地txt文件,同时能够把相册动态中的图片下载到本地,且把相册信息也记录下来,在每一页的操作完成后可以进行翻页和选页,继续操作。因此该系统应该满足以下要求。
(1) 能够通过验证码的验证模拟登录豆瓣网。即不需要通过浏览器登录,通过在控制台输入用户名、密码和验证码实现登录豆瓣网。
(2) 登录成功后能够爬取豆瓣网首页页面代码。即通过登录成功后的cookie能够访问游客权限不能访问的页面并把页面代码抓取下来。
(3) 能够在页面代码中提取出需要的信息。即需要通过正则表达式匹配等方法,从抓取到的页面上获取到有用的数据信息。
(4) 能够实现翻页和选页的功能。即在访问网站动态页面时,能够通过在控制台中输入特定的内容进行翻页或输入页码进行选页,然后抓取其它的页面。
(5) 实现关键字查询的功能,对查到的数据爬取下来并存储到数据库表中。即在抓取到的页面上获取数据时,能够通过在控制台输入关键字来爬取所需的信息。
(6) 对爬取到的图片URL能够下载到本地并把图片的详细信息存储到本地txt[12]。即不仅要把图片下载到本地,还要把图片的主题信息,图片的所属用户,图片的具体URL等信息存储到txt文件。
(7) 对日记和其他的动态信息存储到本地不同的文件中。即对抓取到的不同的数据信息进行不同的存储方式和存储路径。
(8) 在登录成功的情况下能够进入個人中心中把当前用户关注的用户的信息存储到数据库表中。这些信息可能包括用户的id,昵称,主页url,个性签名等等。
以上就是本课程爬虫系统的一些基本需求,根据这些需求就可以明确系统的功能。由于本系统注重网络信息资源的爬取,所以在用户交互方面可能不太美观,在该系统中并没有编写界面,所有的操作都在Eclipse的控制台中进行。例如:在控制台中输入用户名、密码和验证码进行登录,登录成功后的页面选择,页面选择后的数据爬取等。
但是,系统运行后爬取的数据可以在存储数据的本地txt文件中或者在数据库中查看。所以,本系统是否真的能够爬取到数据的测试就可以通过观察本地txt文件的内容变化或数据库表中记录的变化来验证。
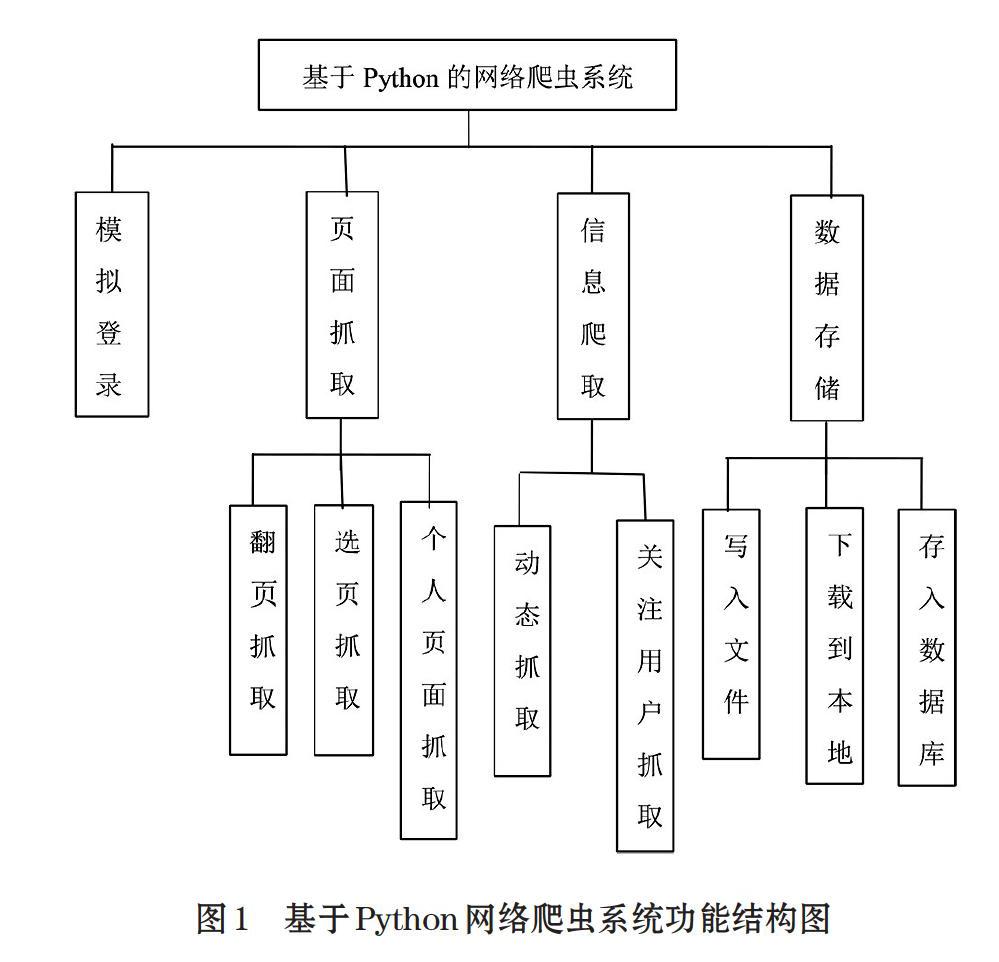
本爬虫系统包括模拟登录、页面抓取、信息爬取、数据存储等主要功能。其中,页面抓取又包括翻页抓取,选页抓取,个人页面抓取;信息爬取又包括动态抓取,关注用户抓取;数据存储又包括写入文件,下载到本地,存入数据库,如图1所示。
一段自动抓取互联网信息的程序称为爬虫,主要组成:爬虫调度器、URL管理器、网页下载器、网页解析器。
⑴ 爬虫调度器:程序的入口,主要负责爬虫程序的控制。
⑵ URL管理器:
① 添加新的URL到待爬取集合;
② 判断待添加URL是否已存在;
③ 判断是否还有待爬取的URL,将URL从待爬取集合移动到已爬取集合。
URL存储方式:Python内存即set()集合,关系数据库、缓存数据库。
⑶ 网页下载器:根据URL获取网页内容,实现由有urllib2和request。
⑷ 网页解析器:从网页中提取出有价值的数据,实现方法有正则表达式、html.parser、BeautifulSoup、lxml。
4 结束语
爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择地访问万维网上的网页及其相关的链接,获取所需要的信息。
本文通过爬虫对于将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现了网页数据抓取与分析。
参考文献(References):
[1] 曾小虎.基于主题的微博网页爬虫研究[D].武汉理工大学, 2014.
[2] 周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005. 25(9):1965-1969
[3] 周中华,张惠然,谢江.于Python的新浪微博数据爬虫[J].计算机应用,2014.34(11):3131-3134
[4] 刘晶晶.面向微博的网络爬虫研究与实现[D].复旦大学,2012.
[5] 王晶,朱珂,汪斌强.基于信息数据分析的微博研究综述[J].计算机应用,2012. 32(7):2027-2029,2037.
[6] (挪) Magnus Lie Hetland. 司维,曾军崴,谭颖华译.Python基础教程[M]. 人民邮电出版社,2014.
