基于BP神经网络预测模型与聚类分析的上市企业的估值与预测
2019-09-12侯志贤
侯志贤
(山东科技大学,山东 泰安 271000)
考虑到不同企业类别其估值有所不同,因此本文首先对数据进行预处理,利用SPSS对提供的数据进行聚类分析,将前几年的数据进行分类统计,并且以平均市销率作为基本数据,利用皮尔逊系数对科创板与纳斯达克数据进行检验进而得出两者市场的估值溢价。
采用逻辑回归的方法对数据进行分析,设置参数以及进行调试,拟合出估值指标与基本面指标以及流动性指标的关系,然后对各项指标之间的关系进行分析、比较差异。
一、模型假设
1.假设条件都为理想情况
2.分析各个指标之间无直接影响
3.不会突然爆发经济危机等情况
二、企业估值水平的预测
由于不同企业的估值的依据有一定差异,因此为建立一个统一的标准,对提供的数据进行聚类分析。考虑到提供数据有许多为0的值,因此首先对数据进行预处理,然后利用spss对数据进行分类,以时间轴形式划分,以平均市销率为基本依据,最终通过皮尔逊系数与纳斯达克数据关系进行检验即可得出两者市场的估值溢价。
聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
在统计学中,皮尔逊积矩相关系数用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。这个相关系数也称作”皮尔森相关系数r”。
考虑到提供给出的数据有错误的地方,因此利用SPSS对变量进行预处理,然后利用SPSS聚类分析功能,最终得出聚类谱系图,即对表格的数据进行了大致分类。
市销率是指股票市价与每股销售额的比率。主要适用在对销售收入较大但盈利水平还不明显的企业。PS估值法的优点在于:首先对于盈利能为为负值的企业,PS佑值法依然适用,因为企业的销售额一直是正值的,所W理论上PS估值法适合任何企业;相对于利润与净资产而言,企业的销售额更为真实,估计法的结果可能更为可靠;市销率的波动没有市盈率大。
PS估值法的缺点在于:企业的销售额较高并不一定代表企业的营业利润也高;并且对于一些受成本波动较大的行业而言,PS估值法不太适用。[1]
总体而言,与绝对估值法相比较,相对估值法的优势在于计算比较筒单,也便于普通投资者理解和掌握,同时通过可比公司也揭示了行业外在的一些因素对公司发展的影响制约。同时相比于绝对估值法,相对估值法的缺点在于:市巧波动较剧烈时,市盈率、市净率的变动比率也较为剧烈,可能对上市公司的价值评估产生较大的误差。并且在选择可比公司作为参照物时,实践过程中可能不能选择较好的可比公司,导致最终价值估计出现误差。
纳斯达克是当今世界最大的电子股票市场,其股票交易系统是利用电子信息技术而建立的,它主要是为快速成长的高科技企业服务,其市场结构独特、上市环境宽松,吸引了众多的高科技企业,微软、英特尔、苹果等企业都在纳斯达克上市,并获得飞速的成长成为世界知名大企业,因此,纳斯达克代表了新技术的发展方向,并成功树立了一个”扶持创业企业”的形象。[2]
根据测算最终算出2018年中国A股市场与美国NASDAQ市场的估值水平平均值分别为2.099与0.765.
三、估值溢价
本文选用多项式逻辑回归来建立估值指标与基本面指标,流动性指标之间的关系,即进行拟合回归。通过逻辑回归模型对中国A股市场的估值指标与基本面指标、流动性指标之间的关系进行定量分析,对美国NASDAQ市场也进行此种分析,最终比较出两个市场之间的差异。
LR模型是应变量为二值分类变量的回归模型,在滑坡敏感性评价中是应用较为广泛的一种非线性多元统计模型。本研究选取LR模型主要包括以下2个原因:1)能进行不同类型的自变量分析;2)该模型不要求自变量符合正态分布,对识别变量的分布无限制,可以用来预测具有二项特点的因变量概率问题;LR模型将因变量转化为发生 (记为1)和不发生 (记为0)的二元逻辑变量。滑坡发生的概率与影响因子之间的关系可表示为
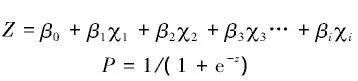
其中,P代表发生的概率,范围为[0,1]。Z代表变量叠加后的线性权重值得和;Xi代表各个影响因子,βi是逻辑回归系数。利用SPSS软件对提供的训练样本进行逻辑回归,得到每个影响因子分级的回归系数,该系数越大则表明相应的影响因子影响越大。R模型属于多元统计分析,不同于二元统计分析法,该方法对各个影响因子进行综合评价。
为了定量地评价空间预测结果,将训练后的模型分别以训练样本和验证样本数据作为模型输入进行计算,得到2种样本的输出结果。本文采用ROC曲线对模型的精度进行评价。ROC曲线为受试者工作特征曲线,是反映敏感性和特异性连续变量的综合指标,并采用构图法揭示两者的相互关系。将通过训练样本集与验证样本集得到的输出结果分别导入至SPSS软件进行计算,所得的ROC曲线结果如下图所示。其中训练样本和验证样本的AUC分别为0.91和0.89,表明LR模型的预测精度较为理想。
经过预测发现无论是中国A股市长的各项指标还是美国NASDAQ市场的估值指标,都有一定的关系,并且这种关系可以通过模型证实。
