基于Hadoop的实时数据处理系统设计与实现
2019-09-10李明东王英焦杰
李明东 王英 焦杰


摘要:本文基于Hadoop平台设计了一个实时数据处理系统,通过对主流实时计算框架的研究,解决了Spark,puma没能解决的数据源主动接入问题.本系统设计主要包括核心计算模块设计、数据接入模块设计和存储模块设计.主要用到的算法包括可靠性机制算法、信号量机制算法、事务性机制算法等.实践结果表明,系统处理效率高且运行稳定.
关键词:Hadoop;实时数据处理;可靠性机制
中图分类号:TP311.13 文献标识码:A 文章编号:1673-260X(2019)04-0047-03
随着大数据技术的快速发展,要求现有平台不仅能够处理海量数据,还要能够快速的对接批量数据,实现数据的实时处理与结果的展现;本文以Hadoop主流数据处理平台为基础,使用storm计算框架完成各个模块的功能设计.在整个系统框架下,分别对可靠性等机制进行了内外部环境的功能及性能的测试.为后续数据可视化的实时展现以及预测提供了坚实的理论和实验基础.
1 实时数据处理系统结构与功能设计
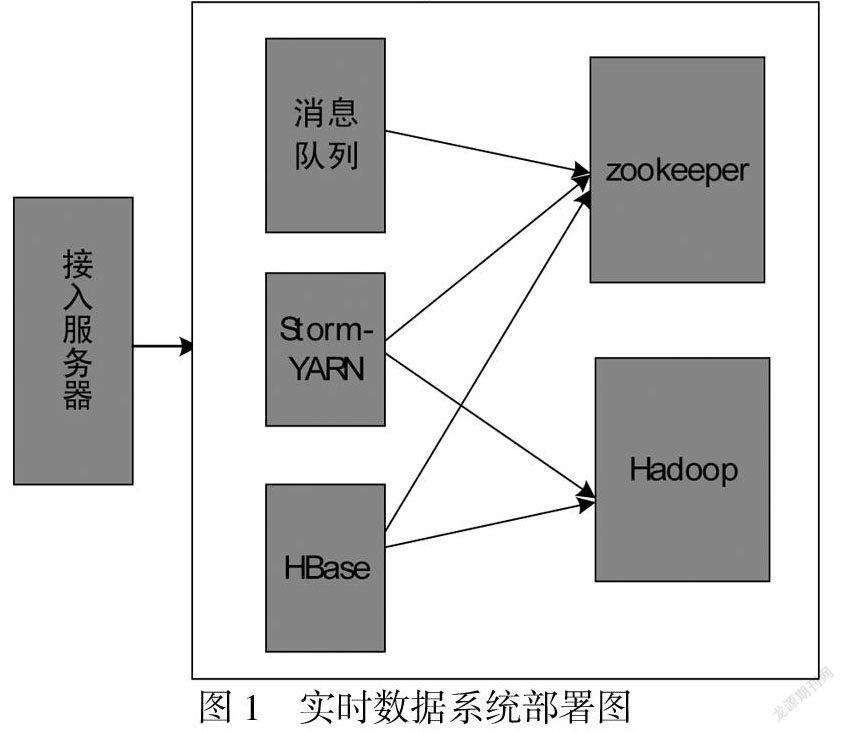
基于ARM微处理器芯片的智能远程防盗系统的结构功能设计主要包括:电源模块、无线本系统开发核心基于Hadoop架构,结合了kafka[1]、HBase、Thritf,以及Zookeeper[2]集群等开源工具,使用Storm作为数据计算模块.实时数据处理系统的环境和服务部署框架如图1所示.
1.1 Storm-YARN
Hadoop集群中的3台机器提供给Storm- YARN使用,一台作为Nimbus,另外两台作为Supervisor机,每个开启4个工作进程.
1.2 Kafka
用于提供高吞吐消息服务的Kafka队列部署在一台Linux物理机器上,Kafka可以有效地解决在线数据活跃导致与系统之间速度不匹配的问题.Kafka通过追加数据的方法完成对磁盘数据的长久保持,提高系统运算能力的同时又能稳定存储数据.
1.3 HBase
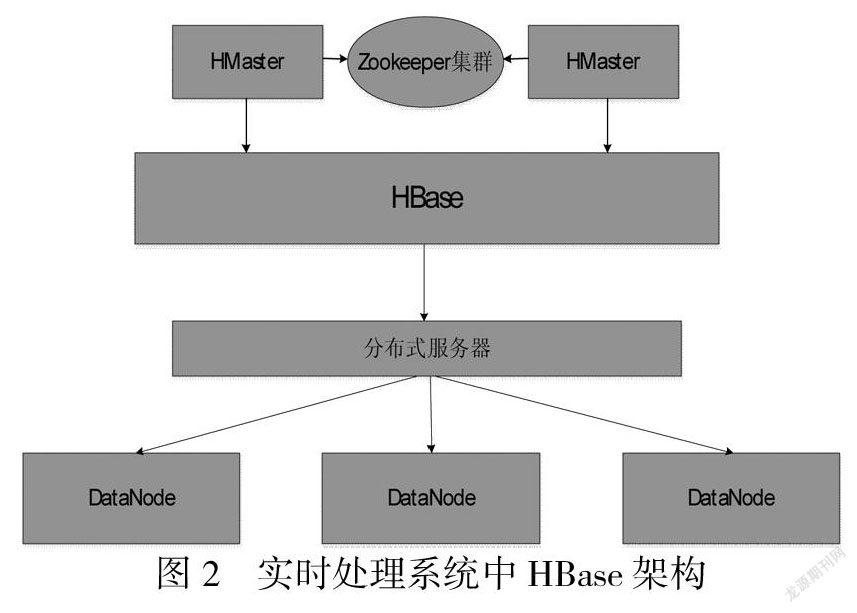
Hadoop集群中的3台机器被划分用于部署HBase服务.HBase架构图如图2所示.
HBase中客户端通过远程过程调用机制与HRegionServer和HMaster进行通信.当用户对数据进行读写操作时,客户端通过远程过程调用机制与HRegionServer通信,对数据进行创建、权限、删除等操作时,客户端通过远程过程调用机制与HMaster通信.
1.4 实时系统中Hadoop集群配置
本系统Hadoop集群包括10台机器,一台机器为Namenode,其余为Datanode.Namenode用于维护文件系统树,包括树内的文件和目录,Datanode存储和检索数据块,并维护数据块存储列表,一定周期内将信息发送给Namenode[3].
1.5 Zookeeper集群配置
Zookeeper集群分配4台机器,Zookeeper采用与文件系统相似的目录节点树来存储数据,数据的集群管理通过维护和检测数据的变化以实现,此外Zookeeper在本系统中为HBase等程序提供服务.
2 实时数据接入
2.1 实时数据处理
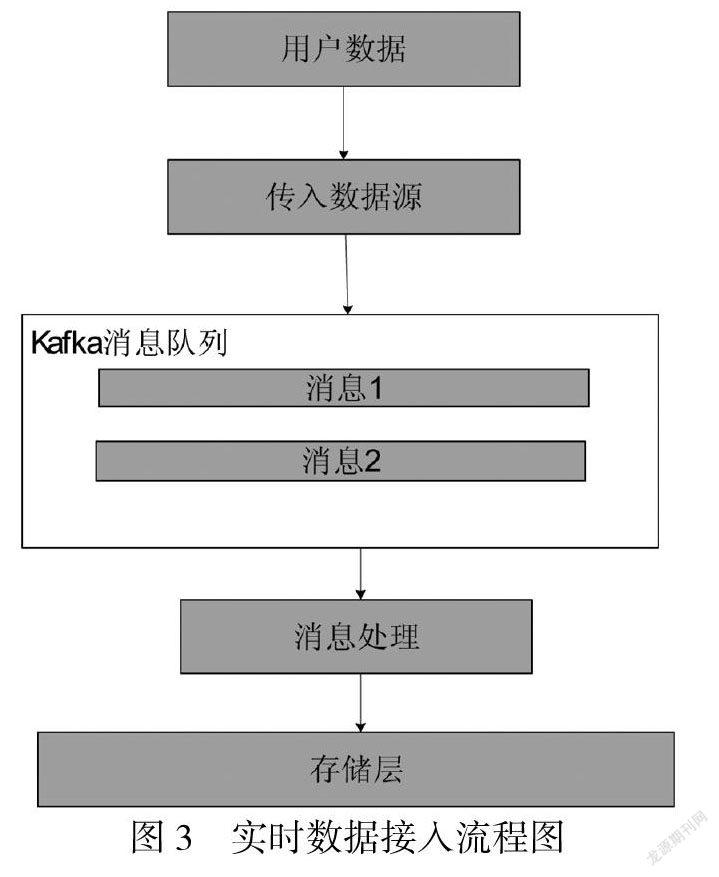
首先启动kafka消息队列服务,将用户数据源接入系统缓冲池,第二步启动位于数据源层的数据源接入模组,读取配置,向外提供服务.用户向系统发送一项任务时,系统首先对任务进行逻辑解析,将解析后的任务发送到计算層,完成实时计算和存储.系统外应用使用应用程序编程接口将数据发送到系统,并在消息队列中进行缓存,数据在消息队列中排队等待,对数据处理需要在计算层有相关的在线处理进程.
在采用C/S架构的数据源接入层中,外部应用被称为Client,系统即为Sever端.Client端可以通过发送数据给Server后,等待Server确定后继续发送数据或者不经过Server确定一直发送数据这两种方式传输数据[4].实时数据接入流程图如图3所示.
2.2 数据处理模式设计
数据处理[4]包括对数据的统计、提取、过滤、计算TopN、数据聚合等,还要对中文数据流进行分词操作.数据处理流程如图4所示.
2.3 实时处理系统实现
实时处理系统由数据接入模块、存储模块、核心计算模块组成.
(1)数据接入工作流程如图5所示.
模块中分为客户端、服务器、通信以及消息队列;客户端发送流式数据至服务器,同时为了提升消息的传输效率和质量,在客户端中加入了Retey机制,并设置最大的Retry次数是5次,当连续5次调用失败才算最终失败.
当客户端调用失败时抛出异常,系统调用handleTException方法处理异服务器需要能快速响应客户端的请求,因此本文服务器采用线程池工作模式,设置最小线程数8,最大线程数256,这样提高了服务器响应速度,又最大程度减少了资源的消耗[5].
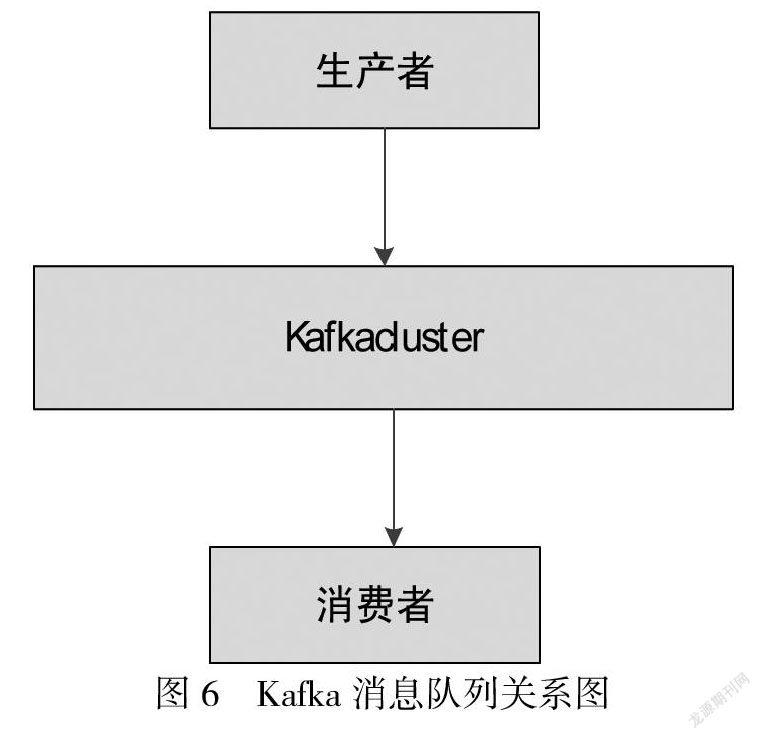
Kafka消息队列部署在一台linux机器上,Kafka将来自同一数据源的消息即同一主题,默认分区个数为10.在Kafka中,生产者产生消息并且将消息发送给服务器;消费者负责使用消息,这三者的关系如图6所示.
通信部分有handleMsg以及handleMsg两个接口方法,用户根据需求选择调用.
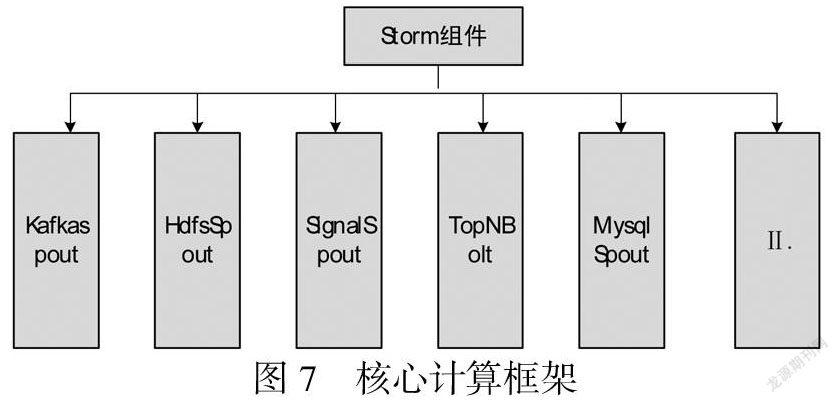
(2)实时数据处理系统核心计算框架
本系统中的实时计算部分是基于Storm框架开发,spout组件提供数据喷发服务,Bolt组件提供数据处理操作,二者构成Storm的在线计算任务.核心计算框架如图7所示.
3 实时数据处理系统算法的设计与处理
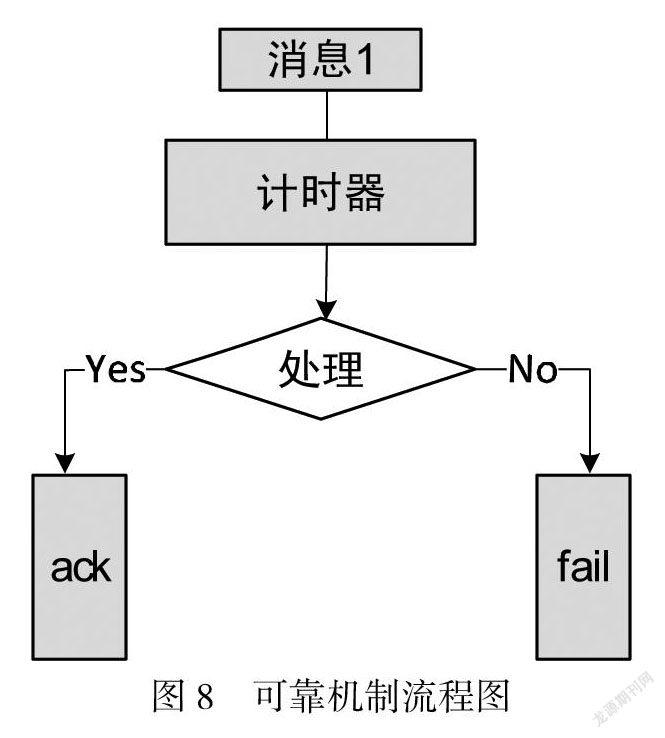
3.1 可靠性机制算法设计
在基于Storm平台的可靠性机制算法下构建流程如下图所示.
如果消息处理失败,则调用fail方法.首先将消息队列头中的消息移除,消息处理结果被标记为失败,进行计时.消息处理成功,调用ack方法,将消息队列头中的消息移除,消息处理结构被标记为成功,开始计时,计时结束调用nextTuple方法发送接下来的消息[6].
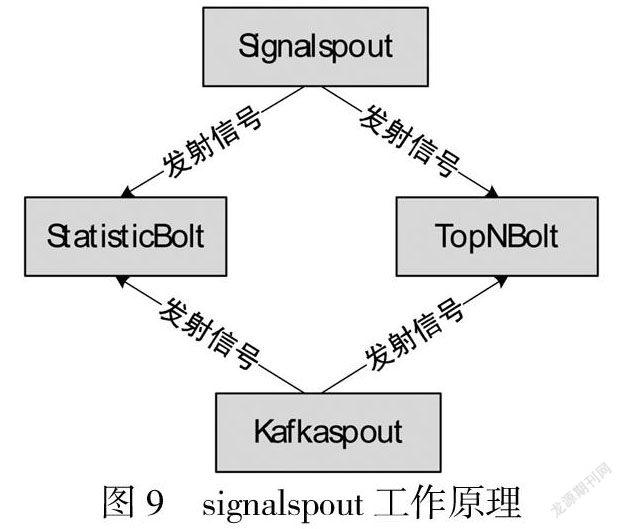
3.2 信号量机制算法
本系统基于Storm信号量机制开发了一个组件Signalspout.Signalspout组件用于发送清空缓存等操作的信号给其他组件,只需signalspout组件定时发射信号就能实现从一个方面控制多个时间粒度[7],signalspout工作原理如图9所示.
3.3 事务性机制算法
使用TridentTopology事务性在线任务完成该算法,Trident包括Partition-local操作、Merge/Join操作、流分组操作、Pepartitionning操作、Aggregation操作[8].
4 总结
本文基于Hadoop平台设计了一个实时数据处理系统,弥补了spark、Hadoop平台不能供多用户实时操作数据的不足.HBaseBolt组件实现了存储消息序列到HBase数据库中,将tuple数据样例转变为put实例进行存储.改进后的实时处理系统确保数据源组件spout发出的信息能被bolts及时捕捉并处理.系统采用的信号量机制控制对时间粒度不同时,控制数据分流并进行置零计数;通过多次运行试验,系统处理数据及时且运行稳定,提升了平台处理数据的效率.
参考文献:
〔1〕曲风富.京东基于Samza的流失计算实践[J].程序员,2014(2):40-43.
〔2〕Yang L,Yan Z.A method to avoid single failure of Namenode in HDFSZookeeper[J].Software,2016.
〔3〕金晓军.Trident Storm与流计算经验[J].程序员,2015(10):99-103.
〔4〕朱珠.基于Hadoop的海量數据处理模型研究与应用[D].北京邮电大学,2014.
〔5〕陈飞.基于MapReduce的数据清洗算法研究[D].昆明理工大学,2016.101-103.
〔6〕徐媛媛.基于MapReduce的相似性连接研究[D].宁波大学,2014.22-25.
〔7〕雷斌.面向复杂距离度量的MapReduce相似性连接技术研究[D].东北大学,2016.55-58.
〔8〕韩来明.基于遗传算法的分布式数据挖MapReduce架构研究[D].天津大学,2015.31-35.
