基于机器学习的股票趋势预测方法研究
2019-09-10黄敏健刘钰萱
黄敏健 刘钰萱




摘 要:随着我国经济制度和保障体制的不断完善,越来越多的人投入到股票交易市场中,而在错综复杂的股票市场中,根据股价趋势选取最优股并采取适当的交易策略,是投资者和相关学者的讨论中亟待解决的问题,如何有效地对股票趋势进行预测成为研究领域的一个热门。根据上市公司的股票数据和变化情况,运用4种机器学习模型对股价进行预测,实验结果表明,各类模型可以提高预测的准确率,相较于K近邻、逻辑回归模型以及支持向量机模型,使用Tensorflow建立的模型各类评价指标上都表现出最好的预测结果。不同模型在结合金融投资特征适当调整之后,预测准确率有一定的提升。根据以上数据和分析,评价各种机器学习算法模型在股票趋势预测方面的效用。
关键词:机器学习;股票预测;python
随着我国经济制度和保障体制的不断完善,越来越多的人投入到股票交易的市场中,而在错综复杂的股票市场中,根据股价趋势选取最优股并采取适当的交易策略,是投资者和相关学者的讨论中亟待解决的问题。
尽管股票市场是一个非线性、非平稳的系统,但是相对稳定条件下的股票市场依然存在一定的规律性。近年来,随着数理统计、概率论及神经科学的发展融合,机器学习理论的日益完善,各类机器学习的模型在股票预测领域也得到了广泛的应用。越来越多的人通过机器学习的方法实现对股票趋势的预测。本文在sklearn框架下,分析清洗过后的股票历史数据,通过训练来得到可以预测股价的模型,在不同评测指标下将预测结果进行对比,并针对模型的不足对模型结构和参数进行改良,将改进前后的数据进行对照并作出分析。
1 相关技术和理论知识
1.1 机器学习的基本方法
机器学习通过研究计算机怎么模拟或实现人类的学习行为,以获取新知识和技能,重新组织已有知识结构使不断改善自身性能。针对经验E(Experience)和一系列任务T(Tasks)和一定表现的衡量P,如图1所示,如果随着经验E的积累,针对定义好的任务T可以提高表现P,说明计算机在过程中逐渐具备学习能力[1]。
1.2 基于Python预测股票价格的模型
1.2.1 K近邻
K近邻(K-Nearest Neighbor,K-NN)通过计算测试对象和所有训练对象的距离,如式(1)所示,找出最近距离的k个对象中出现频率最高的对象,通过其所属类别确定测试对象的类别。
1.2.2 逻辑回归和支持向量机
逻辑回归(Logistics Regression,LP)模型为了线性拟合并且约束目标值域,使用sigmoid函数作为逻辑回归单元来进行约束。数学模型如式(2):
不同于使用均方误差,为了达到尽可能使得曲线光滑以及尽可能使类似于一元二次函数的目的,采用如式(3)代价函数进行二分类,寻找全局最优点:
即转化为优化交叉熵函数,最小化损失的求解过程,如式(4)所示;支持向量机就是将向量进行二分类的算法。核心思想是使分开的两个类别有最大间隔,使得分割具有更高的可信度。同为二元分类器,SVM将股票指标这样线性不可分的数据投影至完美线性可分或基本线性可分的空间,从而将股价价格涨跌问题转化为涨跌分类问题。损失函数则构合页函数加上正则化项如式(5):
1.2.3 TensorFlow与Keras
对神经网络的建立,主要使用多层感知机(Multi-Layer Perceptron,MLP),包括输入输出层和隐层,其中,股票价格将被输入到模型中,并且会使用特定权重值通过隐藏层向前送入以产生输出。通过损失函数(Loss Function)来进行评价和优化,如式(6)所示:
2 评价指标
2.1 部分回归指标
回归类指标中,y为预测的真实值,为预测值,在模拟的过程中,它们越小那么模型预测的效果就越好,均方误差(MSE)、均误差(RMSE)和平均绝对误差(MAE)如式(7)所示:
2.2 部分分类评价指标
查准率(精准率):Precision = TP÷(TP+FP)。
查全率(召回率):Recall = TP÷(TP+FN)。
正确率(准确率):Accuracy=(TP+TN)÷(TP+FP+ TN+FN)。
其中,TP—真正例,實际为正预测为正;FP—假正例,实际为负但预测为正;FN—假反例,实际为正但预测为负;TN—真反例,实负预测。
3 股票预测模型的构建
通过网络爬虫获取20只国内上市公司股票的交易指标和S&P 500 Index,也就是标准普尔500指数,记录了美国500家上市公司的股票指数,其成分股由工业、运输业、公用事业和金融业股票组成。采样面广、代表性强。数据预处理环节如图2所示。
运用理论部分监督学习模型策略的知识对将对多支股票的交易特征分别进行建模,预测涨跌趋势。对于神经网络部分分别采用同步和异步预测,同样对价格趋势进行预测[2]。
4 预测模型的实现
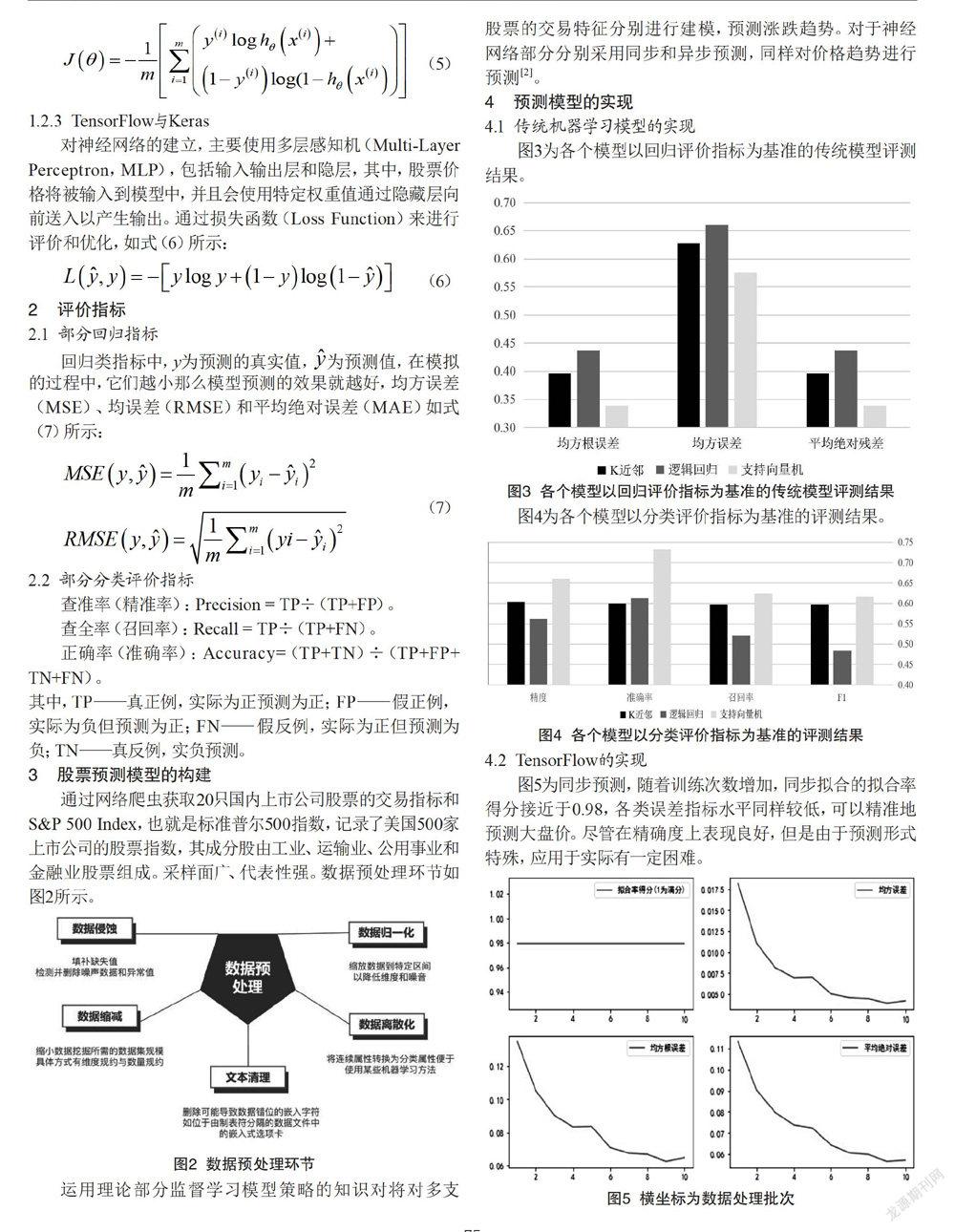
4.1 传统机器学习模型的实现
4.2 TensorFlow的实现
图5为同步预测,随着训练次数增加,同步拟合的拟合率得分接近于0.98,各类误差指标水平同样较低,可以精准地预测大盘价。尽管在精确度上表现良好,但是由于预测形式特殊,应用于实际有一定困难。
使调用历史若干个时刻的股票指数,通过神经网络循环神经网络进行预测实际指数预测大盘指数,结果如图6所示。
结果拟合程度较高,均方误差为(0.10±0.05),测试集上为0.001 5。由于采用的是历史价格,此方法更适合于用于实际预测。
5 未来发展方向
对股票交易的不同预测需求场景下对应的指标和方法选取需要有准确的认识。回归评价指标和分类评价指标呈现出较大的差异性,因此,评价指标和相应机器学习方法的选取必须结合对股票预测的具体需求。如果策略更加偏向于准确价格范围预测,由前文所述使用回归评价指标,精度较高的可以有效地基于此比较误差。此类指标的误差均值对被评估数据的异常点(outliers)较敏感,如果交易指标中有一些异常值出现,会对以上指标的值有较大影响,同时也对数据的清洗提出了更严格的要求。对于分类评价指标,则更看重业务逻辑。对于倾向性问题,如带有感情色彩的策略制定,精度评价无法胜任;对于盈利亏损的接受程度,调整倾向决定了调整查全率、查准率还是使用兼顾两者的F1-Score的标准,均能较好地适合期望稳定收益的场景。AUC由于和概率的相对大小(概率排序)有关,与绝对值无关,不适合准确价格的预测。因此更加适合非均衡(涨跌不均匀分布)时预测,或基于趋势选取交易策略的场景。
6 结语
从本文的相关研究发现,机器学习算法可以通过一定范围的指标评估从而辅助交易策略。通过结合具体交易场景选取适当的参数和评价指标,则可以实现从价格趋势的预测到实际收益提升的转换。然而在实际环境中,模型预测的准确率具有数据依赖性,无法训练一个模型适用于所有场景。一方面考虑到本文所取的股票样本仍然不够全面,且现实中的股票市场还有复杂的政治、经济因素会造成无法预估的影响,要得出具有泛化能力的模型,还需要对股票所属产业和具体交易场景作进一步的分类和深入的调查,更加全面的数据分析和模型调整,将机器学习算法的思想和现实应用更好地结合。
[参考文献]
[1]傅航聪,张 伟.机器学习算法在股票走势预测中的应用[J].软件导刊,2017,16(10):31-34,46.
[2]文 成.基于机器学习方法的股票数据研究[D].重庆:重庆理工大学,2011.
