一种特殊的下降算法
2019-09-10钱晓慧王湘美
钱晓慧 王湘美



摘 要:求解无约束优化问题,常用的方法有下降算法,牛顿法,共轭梯度法等。当目标函数为几个光滑函数的和时,一些学者提出并研究了增量梯度算法。其基本思想是循环选取单个函数的负梯度作为迭代方向。增量梯度算法的迭代方向不一定是下降方向,所以不能用下降算法的一维搜索确定步长,因为受限于步长的选择,收敛效率不高。本文结合了下降算法和增量梯度算法的思想,提出了分裂梯度法。简单的说,分裂梯度法循环考虑单个函数的负梯度方向,如果这一方向是下降方向,则选择这一方向为迭代方向;否则选取函数的负梯度方向为迭代方向。最后通过数值实验与最速下降算法、随机下降算法以及增量梯度算法进行对比,结果表明对于某些优化问题,采用分裂梯度法更有效。
关键词:无约束优化;下降算法;增量梯度法;分裂梯度法;Armijo步长规则
中图分类号:O224
文献标识码: A
本文研究的是优化问题
minx∈Rnf(x)∶=∑i∈Ifi(x)。(1)
其中fi∶Rn→R为一阶连续可微函数, i∈I∶={1,2,…,m}(m为正整数)。该问题是一个无约束优化问题。它在最优控制、机器学习、数据挖掘等许多实际问题中也有着广泛应用,例如求解最小二乘问题以及无线传感器网络中的分布式优化问题、神经网络训练问题等[1-7]。对于此类问题,我们可采用最速下降算法[8]、下降算法[9]、共轭梯度法[8]和拟牛顿法[8]等。但运用此类算法时,每次迭代都需要计算整个函数的梯度SymbolQC@
f(即需计算每一个fi的梯度SymbolQC@
fi)。考虑到目标函数f的特殊性(由多個函数之和的构成形式),一些学者提出了增量梯度算法[10-11]来求解问题(1)。我们知道下降方向的选择对算法的迭代次数有着至关重要的作用。(i)最速下降算法是选择迭代方向为dk=-SymbolQC@
f(xk);(ii)下降算法则是选择迭代方向dk满足dkTSymbolQC@
f(xk)<0;(iii)增量梯度算法是循环选择单个函数fi的负梯度方向为迭代方向。(i)是1847年由著名数学家Cauchy给出的,它是解析法中最古老的一种,其他解析方法或是它的变形,或是受它的启发而得到的,因此它是最优化方法的基础,在文[8]定理313中给出了此算法收敛性定理。由于精确一维搜索准则下的最速下降算法在相邻两次迭代过程中的迭代方向相互垂直,因而整个迭代路径呈锯齿状。此算法开始时步长较大,当其越接近最优值点,收敛速度越慢。因此后来提出了(ii),下降算法在文[8]定理2.5.5中给出了收敛性证明。但因每次的迭代方向并未明确,所以下降算法效率不稳定。(iii)是文[10]中Bertsekas 和Tsitsiklis 提出的,此算法每次以一个函数的负梯度方向为迭代方向,这样对求解大型数据集时,理论上增量梯度算法会比普通梯度法有更快速率的收敛。但由于此算法选择的迭代方向不一定是下降方向,因此不能采用线搜索方法来解决增量梯度算法的问题,而目前主要采用有发散步长规则(收敛速度较慢,迭代次数较大)和恒定步长准则(如果恒定正步长α选择太大,算法产生的点列{xk}可能不收敛;如果恒定正步长α选择太小,又会增加迭代的次数)。结合上述算法,本文提出了求解问题(1)的一种特殊下降算法——分裂梯度法。这一算法主要思想是,根据目标函数中一个函数的负梯度选择下降方向dk。具体来说,分裂梯度法主要选择与上一迭代方向dk成锐角且为下降方向的一个负梯度作为迭代方向;否则,选取-SymbolQC@
f(xk)为当前下降方向。所以,分裂梯度法本质上就是一种下降算法。只是上文提到的下降算法,其迭代方向并没有具体给出,而分裂梯度法则针对问题(1)明确给定了每次迭代的下降方向。通过数值实验可以看出,与上文提到的三种算法比较,大多数情况下采用分裂梯度算法更有效,更稳健。
1 预备知识
在本文,我们将用到以下基本知识(见文[8,10])。
设函数f∶Rn→R为一阶连续可微函数。对任意x∈Rn,f在点x的梯度记为SymbolQC@
f(x)。
定义1 设DRn是Rn一个子集,若存在常数L>0,使得
SymbolQC@
f(x1)-SymbolQC@
f(x2)≤Lx1-x2, x1,x2∈D
成立,则称SymbolQC@
f在D上满足模为L的Lipschitz连续。
定义2 设DRn是Rn一个子集,若对任意给定一个正数ε>0,存在一个实数δ>0,使得对任意的x1,x2∈D,且满足x1-x2<δ,总有
SymbolQC@
f(x1)-SymbolQC@
f(x2)<ε,
则称SymbolQC@
f在D上一致连续。
显然若SymbolQC@
f满足Lipschitz连续,则SymbolQC@
f一定满足一致连续,反之不然。
2 算法及收敛性定理
考虑无约束优化问题
minx∈Rnf(x)∶=∑i∈Ifi(x),(2)
其中I={1,2,…,m},fi(i∈I)∶Rn→R为一阶连续可微函数。
我们提出了下述算法。
算法2.1 (分裂梯度法)
Step 0 取x0∈Rn,令k=0,ε>0,σ∈(0,1),dk=-SymbolQC@
f1(xk)。
Step 1 如果SymbolQC@
f(xk)≤ε,算法终止;否则,转下一步。
Step 2 令i=kmodm+1,计算gk=-SymbolQC@
fi(xk),如果
〈-SymbolQC@
f(xk),gk〉SymbolQC@
f(xk)·gk>σ 且 〈dk,gk〉dk·gk>σ,(3)
令dk=gk;否则,令dk=-SymbolQC@
f(xk)。
Step 3 選取步长因子αk>0。令xk+1=xk+αkdk,k=k+1,转Step 1。
对于上述算法,在Step 3 中可选取的步长{αk}的准则主要有以下几种:
(1)精确一维搜索准则:αk=argminα≥0f(xk+αdk) 。
(2)Wolfe步长准则:令ω∈0,12,αk满足:
f(xk)+(1-ω)αkSymbolQC@
f(xk)Tdk≤f(xk+αkdk)
≤f(xk)+ωαkSymbolQC@
f(xk)Tdk。
(3)Goldstein步长准则:αk同时满足下列条件:
f(xk+αkdk)≤f(xk)+σ1αkSymbolQC@
f(xk)Tdk和
SymbolQC@
f(xk+αkdk)Tdk≥σ2SymbolQC@
f(xk)Tdk,
其中,0<σ1<σ2<1。
(4)Armijo步长准则:αk=βγnk,其中nk为满足下式的最小非负整数n:
f(xk+βγndk)≤f(xk)+δβγnSymbolQC@
f(xk)Tdk,
其中β>0,δ,γ∈(0,1)为常数。
上述四种步长准则在下降算法中皆有相似的收敛结果[8-9]。本文主要以Armijo步长规则为例,来比较算法2.1与已有算法的收敛效率,包括(随机)下降算法、最速下降算法、增量梯度法。现在我们首先给出下降算法和最速下降算法(可参考文[8-9])。
下降算法。设当前迭代点为xk(k∈N),选择迭代方向dk满足dkTSymbolQC@
f(xk)<0,利用Armijo步长准则产生步长因子αk。令xk+1=xk+αkdk。
最速下降算法。设当前迭代点xk(k∈N),选择迭代方向dk=-SymbolQC@
f(xk),利用Armijo步长准则产生步长因子αk。令xk+1=xk+αkdk。
注2.1 (i)由算法2.1中Step 2 的(3)式中的第一个式子可以看出算法2.1本质上就是下降算法,算法2.1只是在选取迭代方向时选取单个函数fi的负梯度或函数f的负梯度作为下降方向。(ii)算法2.1中Step 2 的(3)式中的第二个式子则是为避免迭代路径呈锯齿形,提高收敛速率。
对于下降算法,有以下收敛性结果,可在[8]定理2.5.5中找到。
命题2.1 假设目标函数f在
Rn上一阶连续可微有下界,其梯度函数SymbolQC@
f在水平集
{xf(x)≤f(x0)}上一致连续。设{xk}是下降算法采用Armijo步长规则产生的以x0为初始点的序列。若存在0<θ≤π2,使搜索方向dk与-SymbolQC@
f(xk)的夹角θk满足
θk≤π2-θ,k∈N,(4)
则有 limk→SymboleB@
‖SymbolQC@
f(xk)‖=0 。
下面给出算法2.1(分裂梯度法)的收敛性结果。
定理2.1 假设函数fi(i∈I)在
Rn上一阶连续可微有下界,梯度函数SymbolQC@
f在水平集{xf(x)≤f(x0)}上一致连续。设{xk}是算法2.1采用Armijo步长规则产生的以x0为初始点的序列,则有 limk→SymboleB@
SymbolQC@
f(xk)=0 。
证明 设k∈N,θk是搜索方向dk与-SymbolQC@
f(xk)的夹角。由Step 2 的(3)式中的第一个式子得
cosθk=〈-SymbolQC@
f(xk),dk〉SymbolQC@
f(xk)·dk
=〈-SymbolQC@
f(xk),gk〉SymbolQC@
f(xk)·gk≥σ〈-SymbolQC@
f(xk),-SymbolQC@
f(xk)〉SymbolQC@
f(xk)·-SymbolQC@
f(xk)=1,
其中σ由算法2.1的Step 0给出,所以cosθk≥σ,θk≤arccosσ。因此(4)式成立,其中θ=π2-arccosσ。所以由命题2.1,有 limk→SymboleB@
SymbolQC@
f(xk)=0。
为求解问题(2),有每次考虑一个函数的增量梯度算法[10-11],算法迭代格式如下。
增量梯度算法[4]。设当前迭代点xk(k∈N)。其迭代方式为:xk+1=φm,其中φi=φi-1+αkSymbolQC@
fi(φi-1)(i=1,2,…,m),φ0=xk。其中步长αk满足
αk>0,∑SymboleB@
k=0αk=SymboleB@
,∑SymboleB@
k=0α2k<SymboleB@
。(5)
关于增量梯度算法,有以下收敛性结果(见文[10] Proposition 2)。设函数fi(i∈I)在Rn上一阶连续可微有下界,梯度SymbolQC@
fi在Rn上满足模为L的Lipschitz条件, 并且存在实数C,D>0,使得SymbolQC@
fi(x)≤C+DSymbolQC@
f(x),(x∈Rn,i∈I)。設{xk}为增量梯度算法产生的点列,则有limk→SymboleB@
SymbolQC@
f(xk)=0。
3 数值算例
在这一节,我们将用算法2.1求解几个具体优化问题(2),并通过数值计算结果比较该算法和最速下降算法、随机下降算法以及增量梯度算法的收敛效率(这里的随机下降算法是指随机产生下降方向的下降算法)。特别地,我们应用算法2.1求解例3.2和例3.3中的稳健估计问题和源定位问题,这两个算例均来自参考文献[4],可以转化为问题(2)求解,有重要的实际应用背景。在所有算例中算法计算精度均取为ε=10-6,最大迭代次数设为5000次,编程软件为Matlab 2016a[12]。最速下降算法、随机下降算法和算法2.1均采用Armijo步长规则,参数选取为β=1,δ=0.4,γ=0.5;而增量梯度算法采用满足(5)式的迭代步长αk=1k+k0,(k0∈N) (例3.1选择的k0较大,是为保证算法最终得到较好的运行结果;例3.2和例3.3中取k0=1)。
例3.1 设f1,f2∶R2→R分别定义为:对(x1,x2)∈R2,
f1(x1,x2)=(1-x1)2,f2(x1,x2)=100(x2-x12)2。
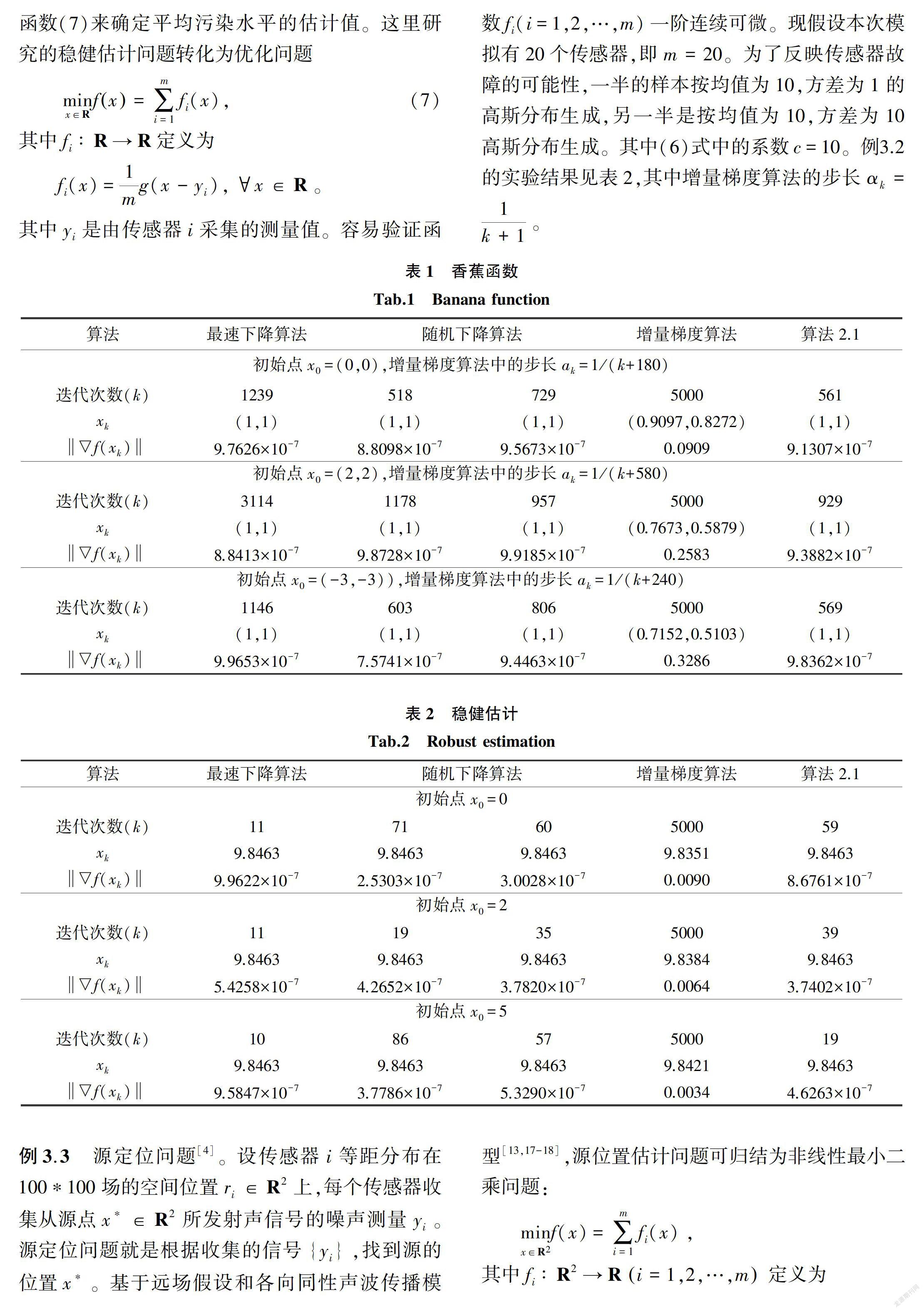
显然函数fi(i=1,2)一阶连续可微,容易验证问题minx∈R2f(x)=f1(x)+f2(x)有唯一最优解x*=(1,1),最优值f(x*)=0。例3.1的实验结果见表1。
例3.2 稳健估计问题[4]。传感器网络是部署大量低成本传感器来密集监视某个区域的某种性态。由于低成本传感器的可靠性有限,系统必须设计成对单个传感器的可能故障具有鲁棒性。这意味着在评估任务中一些传感器会产生不合理的测量结果,即异常值。在文献[13]中,作者建议使用稳健
的统计数据来减轻数据中的异常值的影响(见[14]或[15])。稳健估计使用的是赋予异常值较少权重的目标函数,可以实现此目的的一个常用函数是“Fair”函数g∶R→R[16],定义为
g(x)=c2xc-ln1+xc,x∈R。(6)
与参考文献[4]类似,我们模拟了一个用于测量污染水平的传感器网络,并假设一定比例的传感器损坏且提供不合理的测量结果。每个传感器都收集污染水平的单个噪声测量值,通过最小化目标
函数(7)来确定平均污染水平的估计值。这里研究的稳健估计问题转化为优化问题
minx∈R
fx=∑mi=1fi(x),(7)
其中fi∶R→R定义为
fi(x)=1mg(x-yi), x∈R。
其中yi是由传感器i采集的测量值。容易验证函数fi(i=1,2,…,m)一阶连续可微。现假设本次模拟有20个传感器,即m=20。为了反映传感器故障的可能性,一半的样本按均值为10,方差为1的高斯分布生成,另一半是按均值为10,方差为10高斯分布生成。其中(6)式中的系数c=10。例3.2的实验结果见表2,其中增量梯度算法的步长αk=1k+1。
例3.3 源定位问题[4]。设传感器i等距分布在100*100场的空间位置ri∈R2上,每个传感器收集从源点x*∈R2所发射声信号的噪声测量yi。源定位问题就是根据收集的信号{yi},找到源的位置x*。基于远场假设和各向同性声波传播模型[13,17-18],源位置估计问题可归结为非线性最小二乘问题:
minx∈R2f(x)=∑mi=1fi(x),
其中fi∶R2→Ri=1,2,…,m定义为
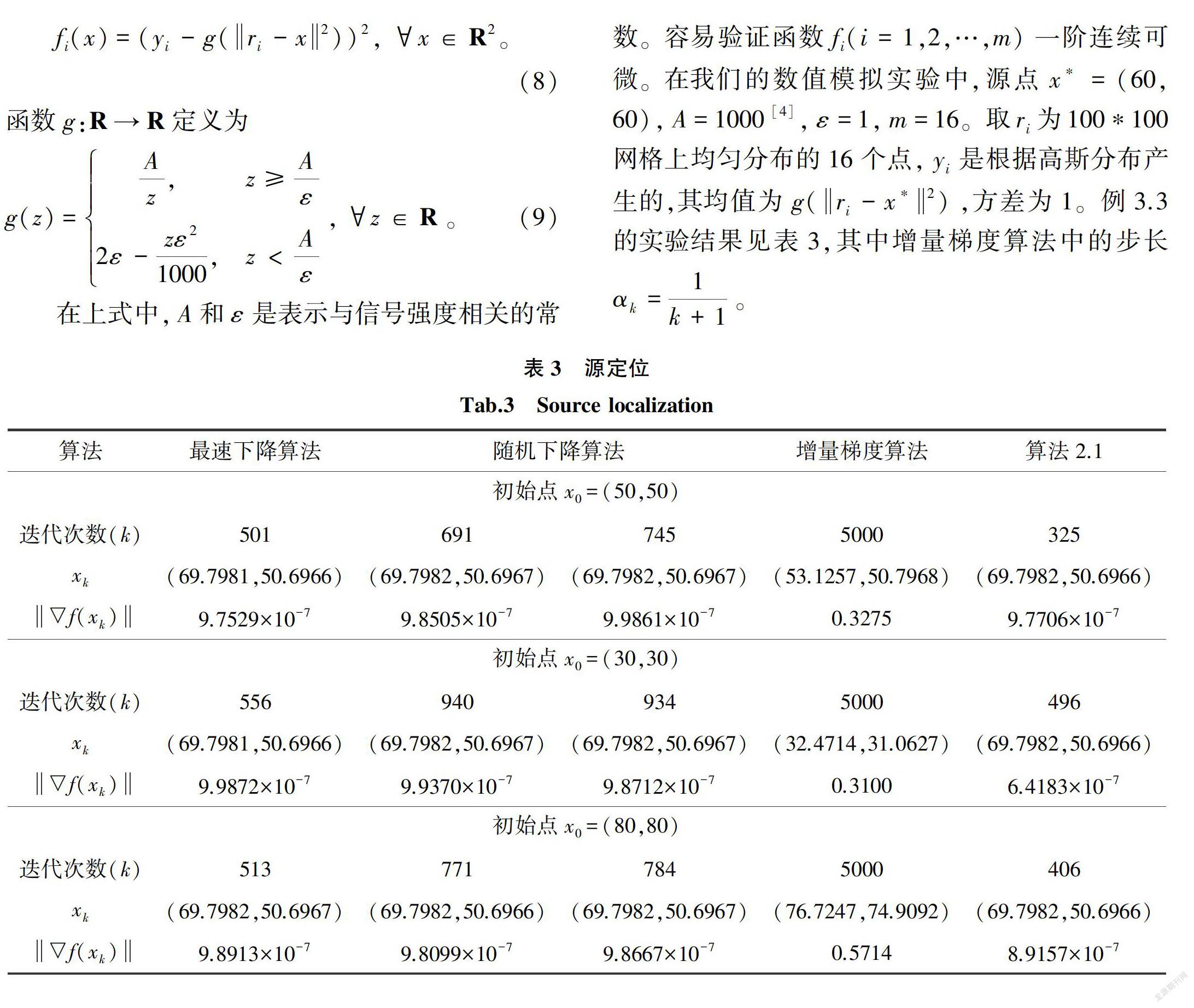
fi(x)=(yi-g(ri-x2))2, x∈R2。(8)
函数g:R→R定义为
g(z)=Az,
z≥Aε
2ε-zε21000,z<Aε,z∈R。 (9)
在上式中,A和ε是表示与信号强度相关的常数。容易验证函数fi(i=1,2,…,m)一阶连续可微。在我们的数值模拟实验中,源点x*=(60,60),A=1000[4],ε=1,m=16。取ri为100*100网格上均匀分布的16个点,yi是根据高斯分布产生的,其均值为g(ri-x*2),方差为1。例3.3的实验结果见表3,其中增量梯度算法中的步长αk=1k+1。
注3.1 (i)算法2.1与最速下降算法比较。由例3.1和例3.3的数值结果可知,取不同的初始点,算法2.1的收敛效率明显都高于最速下降算法。在例3.2中,算法2.1的迭代次数大于最速下降算法的迭代次数,分析其原因为自变量x是一维的,采用最速下降算法时,迭代路径不会出现锯齿形,数值结果表明最速下降算法的收敛速率快于其他算法。
(ii)算法2.1与下降算法比较。由例3.1~3.3的数值结果可知,对于不同的初始点,算法2.1的收敛效率平均优于随机下降算法,并且可以看出随机下降算法的迭代次数并不稳定。
(iii)算法2.1与增量梯度算法比较。对比同样考虑由多个函数之和构成的增量梯度算法,由例3.1~3.3的数值结果表明在相同精度要求下,算法2.1的迭代次数明显少于增量梯度算法,且在控制迭代步数(5000步)内都达到计算精度要求,而增量梯度算法均运行5000次,未达到计算精度要求。
參考文献:
[1]钱伟懿,张洵. 一种改进的粒子群优化算法[J]. 渤海大学学报(自然科学版),2017,38(2):97-103.
[2]Solodov M. V. Incremental gradient algorithms with step sizes bounded away from zero[J]. Comput. Optim. Appl., 1998, 11(1):23-35.
[3]Grippo L. A class of unconstrained minimization methods for neural network training[J]. Optimization Methods and Software,1994, 4(2):135-150.
[4]Blatt D, Hero A,Gauchman H. A convergent incremental gradient method with a constant step size[J]. SIAM Journal on Optimization,2007,18(1):29-51.
[5]Bertsekas D P. A new class of incremental gradient methods for least squares problems[J]. SIAM Journal on Optimization, 1997, 7(4):913-926.
[6]Tseng P. An incremental gradient(-projection) method with momentum term and adaptive step size rule[J]. SIAM Journal on Optimization, 1998,8:506-531.
[7]Defazio A, Bach F, Lacoste ̄Julien S. A fast incremental gradient method with support for non ̄strongly convex composite objectives[J]. International Conference on Neural Information Processing Systems, 2014,1:1646-1654.
[8]袁亚湘,孙文瑜. 最优化理论与方法[M].北京:科学出版社, 2007.
[9]王宜举,修乃华. 非线性最优化理论与方法[M].北京:科学出版社, 2015.
[10]Bertsekas D P,Tsitsiklis J N. Gradient convergence in gradient methods with errors[J]. SIAM Journal on Optimization,2000, 10(3):627-642.
[11]Bertsekas D P. 非线性规划[M]. 2版.北京:清华大学出版社, 2013.
[12]Trefethen. Spectral Methods in MATLAB[M]. New York: SIAM, 2000.
[13]Rabbat M G,Nowak R D. Decentralized Source Localization and Tracking[C]. Montreal: IEEE International Conference on Acoustics, 2004.
[14]Huber P. Robust Statistics[M]. New York: John Wiley & Sons, 1981.
[15]Polyak B T. Introduction to Optimization[M]. New York: Optimization Software Income,1987.
[16]Rey W J J. Introduction to Robust and Quasi ̄robust Statistical Methods[M]. Berlin: Springer Verlag, 1983.
[17]Sheng X H, Hu Y H. Information Processing in Sensor Networks[M]. California: Springer, 2003.
[18]Chen J C, Yao K, Hudson R E. Source localization and beam forming[J]. IEEE Signal Processing Magazine, 2002(19):30-39.
(责任编辑:曾 晶)
A Special Descent Algorithm——Split Gradient Method
QIAN Xiaohui,WANG Xiangmei*
(College of Mathematics and Statistics,Guizhou University,Guiyang 550025,China)
Abstract:
The common methods to solve unconstrained optimization problems include the descent algorithm, Newton method and the conjugate gradient method, etc. When the objective function is the sum of several smooth functions, some authors propose and study the incremental gradient algorithm. The algorithm cyclically select the negative gradient of a single function as the iteration direction, which is not necessarily a descent direction. Therefore, incremental gradient algorithm is not a descent algorithm in general. In this paper, the split gradient method was proposed which combines the ideas of the descent algorithm and the incremental gradient algorithm. Finally, some numerical experiments were provided to compare the split gradient method with the steepest descent algorithm, the random descent algorithm and the incremental gradient algorithm, respectively. The numerical results show that the split gradient method is more effective than the others for some optimization problems.
Key words:
unconstrained optimization; descent algorithm; incremental gradient method; split gradient method; Armijo step rule