智能机器人语料库的自动分词方法研究
2019-09-10高秀艳耿兴隆李战军
高秀艳 耿兴隆 李战军
【摘 要】智能机器人自动回复功能的实现依赖于足量的语料库,语料库的基本单位为词语,因此将整篇的文章语料进行分词并对出词语进行词频统计,可以为下一步的机器学习做好准备。Python语言在自然语言处理过程中广受编程者青睐,它简洁的语法和强大的第三方库为编程提供了极大的方便。Jieba模块在自然语言处理中功能强大,能按照全模式、精确模式和搜索引擎模式对文章进行分词,使用该模块对文章进行分词后,再利用analyse子模块进行词频统计,可以为后期的模型训练提供更准确的数据集,从而提高机器人的回复准确率。
【关键词】机器人;语料库;Jieba模块
自然语言处理是和语言紧密相关的一门学科,是统计和机器学习和语言学的交叉学科,是让计算机能够理解人类语言的一种技术。自然语言处理的主要目的是研究能够表示自然语言的模型,及如何通过计算机处理这些数学模型[1]。智能机器人即依据此进行工作,获取足量的语料后进行分词,并对词语按一定的规则进行建模,用模型训练机器人,使它具备根据输入内容自动检索答案并给出反馈的功能,从而实现自动回复。
一、汉语分词的研究现状
中文分词有人工分词和机器分词两种,鉴于分词效率,目前多使用机器分词,目前常用的机器自动分词方法有:基于词典的分词方法、基于统计的分词方法和混合方法[2][3],其中词典和统计的方法是目前分词技术的主要方法,但基于词典的分词方法在处理歧义字段时性能欠佳,而基于统计的分词方法虽能解决这一问题,但由于其需要大量的计算,时间消耗相当可观,因此混合方法是目前被最多采用的方法。
二、python语言及jieba分词模块介绍
Python语言是当今流行的开源编程语言,它可以跨平台使用,语法简洁,安装方便,广受編程者青睐,其丰富的第三方库也使它如虎添翼,更加方便的完成各种数据处理及运算。
Jieba模块是免费的第三方模块,也是目前Python中最好的中文分词组件,它可以以精确模式、全模式、搜索引擎模式三种模式对语料进行分词,并可使用子模块analyse进行关键词提取及词频统计。
Jieba模块使用cut函数或lcut函数实现分词,使用cut_all参数来判断是否使用精确模式:
cut_all = True:使用全模式,获取文本中所有可能的组词方式。
cut_all = False: 使用精确模式,也即默认模式。
Cut函数返回可迭代序列,可以使用for循环进行遍历,lcut则直接返回分词后的词语列表。
jieba的安装及导入:
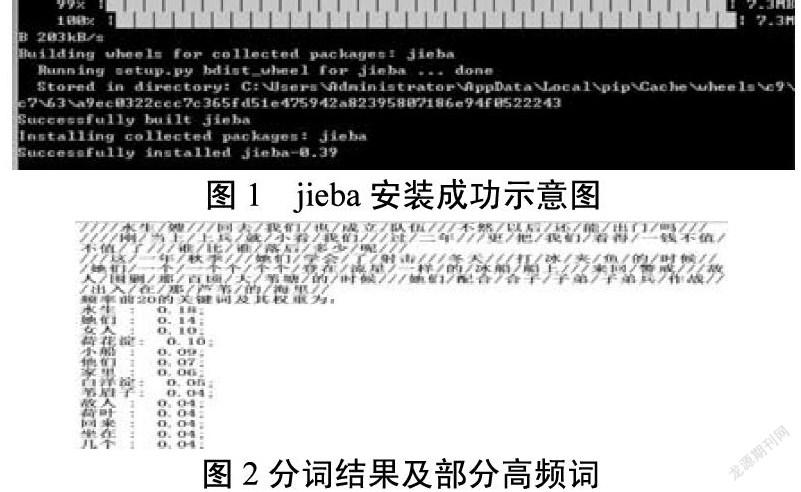
Jieba的安装非常方便,可以直接使用python中的pip命令进行安装,保证电脑联网的情况下,在windows运行窗口输入pip install jieba,即可进行安装,成功安装后的提示如图1。
若遇此种方法安装不成功,也可以单独下载jieba的安装包,并使用cd命令切换到该安装包所在目录下,执行python setup.py install命令进行安装。
Jieba成功安装后,可以使用import jieba来在程序中导入模块。
三、使用jieba模块实现对文章的分词及词频统计
Jieba模块提供了丰富的函数用于处理语料文本,但在此之前我们应先获得文本,为不再额外安装其它的文字处理模块,本文使用txt文件进行语料文章存储,进行分词及词频统计的基本流程为:打开文件→读取文件内容→进行分词→统计各词权重。
由于全模式分词时可能带来大量的词汇冗余,影响后期模块训练时的数据集,进而影响模型的准确性,本文选取精确模式进行分词,两种模式对部分语句的分词结果比较如下:
原句:战士们的三只小船就奔着东南方向,箭一样飞去了。
全模式分词结果:战士/们/的/三只/小船/就/奔/着/东南/南方/方向///箭/一样/飞去/了.
精确模式的分词结果:战士/们/的/三只/小船/就/奔/着/东南/方向/,/箭/一样/飞去/了.
本文使用jieba模块的cut函数对读取到的语料内容进行分词,将分词结果以斜线(/)连接进行打印,使用analyse模块的extract_tags函数统计出现频率最高的前20个单词及单词频率,部分源码如下:
f=open("hehuadian.txt",'r')#打开《荷花淀》文件
content = f.read()
print(type(content))
f.close()
word_list = jieba.cut(content,cut_all=False)#精确模式实现分词
print("分词结果:",'/'.join(word_list))
#统计出现频率最高的20个单词及其频率
tags = jieba.analyse.extract_tags(content,topK=20,withWeight=True)
print("频率前20的关键词及其权重为:")
for i in tags:
print("%-3s:%6.2f;"%(i[0],i[1]))
运行效果如图2所示:
对语料源进行分词是实现智能机器人的第一步工作,接下来将根据分词及词频统计结果构建训练模型,进而构建问题/答案库,从而实现针对给定提问内容的自动回复。
参考文献:
[1]]董永汉.一种网络聊天机器人的研究与实现[D].杭州:浙江大学,2017.
[2]张喜.基于主义模板与知识库的智能导购机器人系统的研究与实现[D].北京:中央民族大学,2012.
[3]黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3):8-19.
