区块链共识机制研究综述*
2019-09-10刘懿中刘建伟张宗洋徐同阁
刘懿中,刘建伟,张宗洋,2,徐同阁,2,喻 辉
1.北京航空航天大学 网络空间安全学院,北京100191
2.北京航空航天大学 合肥创新研究院,合肥230012
1 引言
2008年,Nakamoto 首次提出了比特币[1],数字货币进入了新的篇章.而数字货币底层的区块链技术得到各界人士越来越多的重视[2].区块链技术是在分布式、不可信环境中,所有节点通过一定的共识机制就公共账本达成一致的技术.共识机制作为区块链技术的核心,从根本上决定了整个区块链系统的安全性、可用性和系统性能等.研究区块链的共识机制对区块链扩容、交易处理速度增快和安全性提升有着重要的意义,区块链技术要在未来得到更广泛的应用,就必须研究共识机制.
1.1 区块链概述
区块链技术通过特定的共识机制实现了分布式节点之间账本的一致.区块链之所以被称为“链”,是因为每个区块(block)都以特定密码学的方式链接到前一个区块.一般而言,区块链最开始的区块被称为“创世区块(genesis block)”,而区块中存储的内容主要包括每段时间网络中产生的交易(transaction).
区块链一般具有以下几个特点[3]:第一是去中心化.去中心化是指网络中没有可信第三方存在,不同于传统中心化模式的交易,一般有政府、银行或其他金融机构的存在作为可信第三方; 第二是去信任化.去信任化是指节点之间不需要彼此信任,通过特定共识机制能够最终达成对账本的一致认知; 第三是公开透明性.在非授权网络(permissionless network)中,所有节点能随时加入、退出,节点能随时获得区块链的历史账本数据,接收到新生成的区块; 第四是不可篡改性.区块链中历史数据不能被非法篡改,拿比特币来说,当区块的“深度” 超过6 个之后,则可认为区块中的内容大概率不会被篡改; 第五是匿名性.在比特币中,虽然通过一些手段(如交易图分析[4]等)能对历史交易数据实施去隐私化分析,但通过采用一些隐私保护技术,如群签名、环签名和零知识证明等,能够有效保护区块链中的用户隐私数据.
1.2 共识概述
共识机制是区块链技术的基础和核心.共识机制决定参与节点以何种方式对某些特定的数据达成一致.共识机制可以分为经典分布式共识机制和区块链共识机制.早在1975年,Akkoyunlu、Ekanadham和Huber[5]提出了计算机领域的“两军问题”,对于共识机制的研究从此开始.Lamport、Shostak和Pease[6]提出了“拜占庭将军问题”,研究在可能存在故障节点或恶意攻击的情况下,非故障节点如何对特定数据达成一致.拜占庭将军问题成为了共识机制研究的基础.Lamport[7]提出了解决拜占庭将军问题的Paxos 算法,该算法能够容忍网络中一定数量节点发生崩溃(crash),在分布式系统中,就某个特定值达成一致.1999年,Castro和Liskov[8]提出了实用拜占庭容错协议(practical Byzantine fault tolerance,PBFT),作为拜占庭将军问题的解决方案,PBFT 允许网络中存在一定数量的拜占庭节点,这些节点能够在共识达成过程中制造虚假信息,以各种手段阻碍其他诚实节点完成共识.PBFT 能够在敌手数量占比不超过全部节点数量1/3 的情况下,实现最终诚实节点的共识.
2008年,Nakamoto 提出比特币,共识机制进入区块链共识时代.目前区块链共识可以分为两大类,一类是授权共识(permissioned consensus)机制,授权网络中节点一般通过公钥基础设施(public key infrastructure,PKI)完成身份认证后,才能参与后续共识机制; 另一类是以比特币为代表的非授权共识(permissionless consensus)机制.非授权网络中,节点随时加入和退出,节点数量动态变化且不可预知,非授权共识通过特定算法完成出块者(block proposer)选举、区块生成和节点验证更新区块链等过程.
本文主要研究区块链共识机制,其基本流程如下:
(1)选举出块者.“出块者” 是指区块链中负责产生区块的节点,又被称为记账者.目前的出块者可以分为两种,一种是单一节点作为出块者,另一种是多个节点构成委员会(committee),整个委员会作为出块者.出块者选举的过程中,需要充分考虑到女巫攻击(sybil attack)[9]的存在,参与选举的节点需要完成一定的任务或具备某种条件才能够成为出块者.目前区块链中大多数采用工作量证明(proof of work)或权益证明(proof of stake)的方式来防止女巫攻击.工作量证明要求参与节点完成一定的计算任务,而权益证明要求节点拥有一定的财产.
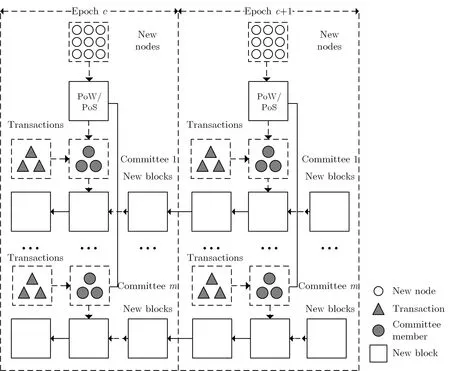
(2)生成区块.出块者主要完成生成区块的工作,即将一段时间内网络中产生的交易数据打包放到当前区块中,而为了让区块成为链状结构,就必须在区块中包含其他内容.一般来说区块可以分为区块头(block header)和区块体(block body)两部分.区块头中一般包括上个区块的哈希值(hash)、时间戳等内容,区块体中包含了完整的交易数据.目前可以按照出块者与区块的对应关系将区块生成过程分为两类:一类是“一对一” 关系,一个出块者对应一个区块,下一个区块由新选举的出块者负责生成,如比特币; 一类是“一对多” 关系,一个出块者在其“任职” 期间,能够生成多个区块,一般将一个出块者的任职时间称为一个时期(epoch),每个时期由多个轮(round)组成,每一轮生成一个区块.
(3)节点验证更新区块链.出块者生成区块后,将区块在网络中广播.收到区块的节点验证区块正确性并更新本地区块链.在部分共识机制中,节点可能还需验证区块中交易合法性和出块者身份合法性等.
对于区块链共识,主要的评价标准有如下几点.
(1)安全性.区块链共识机制的安全性主要是指在敌手存在且能操控一定的网络资源和其他资源的情况下,诚实用户能够在不可信网络环境中达成最终的一致,并且能够抵抗一些针对共识机制的攻击.安全性是共识机制应当满足的最基本、最重要的属性.
(2)交易吞吐率.交易吞吐率是指区块链系统的交易处理速度,一般采用每秒钟处理交易的数量作为评判标准.交易吞吐率受到区块产生间隔、区块大小和网络延时等因素的影响.
(3)可扩展性.可扩展性是指网络处理交易的性能是否能够随着节点的增多而增强,其关注的是网络处理能力的可增长性.可扩展性一般通过对网络实施分片(sharding)来实现,将整个网络节点分为不同的分片,每个分片并行处理分片内部的数据.
(4)交易确认时间.交易确认时间指得是交易从被提交至共识网络,到交易被完全确认所需要的时间.交易完全确认是指交易被写入到区块中,且确保大概率不会被篡改,交易双方能够以此作为凭证完成整个交易过程.在比特币中,交易确认时间大约为60 分钟(6 个区块的生成时间),60 分钟过后,才能保证区块大概率不会出现分叉,即保证交易大概率不会被篡改.在确定性共识中,由于区块链一般不会产生分叉,因此交易确认时间能够降低.
(5)去中心化.去中心化是指区块链采用的共识机制中没有可信第三方存在.与此同时,区块由参与共识的节点共同决定,而不是集中在少数几个节点上.网络中节点的权力应当分散化,而不是集中化.目前比特币挖矿采用的“矿池(mining pool)” 在一定程度上影响了比特币的去中心化[10].
(6)资源占用.资源占用主要考量的是共识机制带来的节点间的通信复杂度(communication complexity)和节点需要的计算复杂度(computation complexity).资源占用通常与交易确认时间和交易吞吐率指标紧密联系.
1.3 本文贡献
本文主要研究了以下内容:
(1)总结了区块链共识机制的基本流程,将其分为出块者选举、区块生成和节点验证更新区块链等几步.根据出块者选举过程,将区块链共识机制的特性分为弱一致性和强一致性两类; 根据区块生成过程,将出块者和区块关系分为“一对一”和“一对多” 两类.
(2)总结了共识机制的评判标准,包括安全性、交易吞吐率、可扩展性、交易确认时间、去中心化和资源占用等内容.
(3)分类研究了共识机制的系统模型,将网络模型分为同步网络、部分同步网络和异步网络,将腐化模型分为静态敌手、温和敌手和适应性敌手,将敌手模型分为n=2f+1、n=3f+1和n=4f+1,指出了各类模型之间的区别.
(4)分类研究了现有共识机制,分析了各类共识机制的基本原理、典型方案和优缺点.
经典分布式共识主要在节点之间完成状态机复制,实现一致性和活性.典型方案包括Paxos、PBFT、Hot-Stuff[11]、SBFT[12]、MinBFT[13]和Honey Badger BFT[14]等;
授权共识机制是节点经过身份认证后,通过分布式一致性算法完成区块的生成和维护.典型方案包括Hyperledger[15,16]、DFINITY[17]和PaLa[18]等;
基于工作量证明的共识机制,节点利用自身算力通过寻找哈希函数原像完成出块者选举.典型方案包括比特币、以太坊[19]、Bitcoin-NG[20]、FruitChains[21]、GHOST[22]和Spectre[23]等.可能面临的安全问题包括日蚀攻击、双花攻击和自私挖矿等;
基于权益证明的共识机制,在所有合法持币者中随机选取节点作为出块者.典型方案包括PPCoin[24]、Casper FFG[25]、Ouroboros[26]、Snow White[27]和DPoS[28]等.可能面临的安全问题包括无利害关系问题、打磨攻击、长程攻击和权益窃取攻击等;
采用单一委员会的混合共识机制主要利用PoW 或PoS 选出部分节点作为共识委员会,在委员会内部运行类似于PBFT 的分布式一致性算法完成区块的生成.典型方案包括PeerCensus[29]、ByzCoin[30]、Solida[31]、hybrid consensus[32]、Thunderella[33]和Algorand[34]等.可能面临的安全问题主要是恶意节点干扰委员会选举和重配置过程;
采用多委员会的混合共识将网络划分为多个片区,每个片区运行并行的委员会对交易分别处理.典型方案包括ELASTICO[35]、Omniledger[36]、Chainspace[37]和RapidChain[38]等.可能面临的安全问题主要是跨片交易的高效处理和敌手对重配置过程的偏置.
(5)分析了未来共识机制的研究热点和发展方向.
本文对区块链时代的共识机制研究总结如表1所示.其中,符号“/” 代表当前系统没有该特性值或没有具体可查的系统参数; 符号“√” 代表满足当前特性; 符号“×” 代表不满足当前特性.
1.4 相关工作
共识机制是区块链技术的核心,在基本层面上决定了区块链系统的安全性、可扩展性和分布式特性.近几年国内外对于区块链时代共识机制的综述研究主要包括以下内容.
在国内研究方面,文献[39]研究了区块链共识机制,系统整理了区块链技术发展过程中有代表性的共识机制,将共识机制分为传统分布式一致性算法和区块链共识机制,并提出区块链共识机制的基础模型和分类方法,该工作侧重于整体层面研究,对每一类共识机制的介绍过于简单,而本文在对区块链共识机制分类的基础上,总结每一类共识机制的基本流程,并且深入研究了典型协议,给出了协议的具体步骤,指出了协议可能存在的问题.文献[40]研究了区块链不同共识机制的组合,分析了工作量证明和权益证明的组合、拜占庭一致和权益证明的组合,但是对于混合共识没有给出具体的分类,研究过于简单.文献[41]侧重分类对比各种区块链共识机制,指出了部分共识机制的不足之处,其对于共识机制的分类较为简单.文献[42]主要关注拜占庭容错技术,重点研究了PBFT 及其改进,并给出了拜占庭容错的应用场景.文献[43]简单分析了Bitcoin、Ouroboros、ByzCoin和Omniledger 四种典型区块链共识机制.
在国外研究方面,Bano 等人[44]主要研究了区块链的可扩展性,分析了多种共识机制的交易吞吐率和交易处理的可扩展性,指出了未来共识机制的研究方向.该工作侧重于研究区块链共识机制,对于经典共识只是简要概括,本文深入研究了PBFT 等经典共识机制及其改进,分析了其具体流程.经典共识作为混合共识的重要组成部分,起到了十分关键的作用.与此同时,本文研究了最新的区块链共识机制,对每一类共识机制的研究更加细致.Zohar[45]侧重于研究区块链激励机制,分析了以工作量证明为基础的区块链系统中激励机制的重要性,不合理的激励能够导致整个系统不安全.Cachin和Vukolić[46]主要分类研究经典分布式一致算法,总结了PBFT 等协议的核心思想,列举出其在授权共识中的应用.他们侧重于授权共识机制的研究,却没有对整个区块链共识机制分类并介绍特性.Bano、Al-Bassam和Danezis[47]研究了可扩展区块链体制,提出了区块链扩容可能采取的方法,如分片共识、基于委员会的混合共识等,却没有给出每个协议的设计细节.Pass和Shi[48]以形式化的方式描述了非授权共识机制的特性,包括链质量、链增长和一致性,并且给出了能够满足公平性、快速响应等特性的非授权区块链共识机制.Garay和Kiayias[49]研究了区块链共识的分类方法,侧重于网络模型、敌手模型等分类问题.
2 模型和定义
2.1 定义
定义1(状态机复制)状态机复制(state machine replication)是指存在一组节点且所有节点共同维持一个线性增长的日志,并且就日志内容达成一致[50].
一般来说,节点中存在一个主机(primary),而其他节点被称为从机(backups),主机的身份可以变化.状态机复制具备一定的容错功能,在可容忍的范围内,允许一定比例的节点出现故障或遭受敌手攻击.它需要满足两个重要的安全特性:第一是一致性(consistency),即所有诚实节点最终输出的日志彼此一致;第二是活性(liveness),任一诚实节点收到的交易在一定时间之后出现在所有诚实节点的日志中.
另外,Pass和Shi[32]提出了状态机复制的快速响应特性.
定义2(快速响应特性)快速响应特性(responsiveness)是指交易确认时间与网络真实时延δ有关,与网络时延上限∆无关.
状态机复制过去经常被用于大型数据库的同步,如Google和Facebook 将状态机复制用于其数据库核心部分的同步.
定义3(授权共识)授权共识(permissoned consensus)是指在授权网络中,PKI 存在且为每个节点实施身份认证.注册完成后,每个节点都能获知所有参与者节点数量和身份等信息.所有节点运行内部分布式共识机制,实现状态机复制,完成账本的生成和维护,并将账本以区块链的形式实现.授权共识需要满足一致性和活性.
定义4(非授权共识)非授权共识(permissionless consensus)是指在非授权网络中,节点不需要经过身份认证,网络中节点数量随时变化,节点无法获知所有参与者节点数量和身份等信息.所有节点通过一定的共识机制实现非授权网络中的状态机复制.非授权共识同样需要满足一致性和活性.
非授权网络与授权网络的区别主要有以下两点:第一,任何节点在任意时间都能随时加入或退出非授权网络,不需要完成身份认证; 第二,参与非授权共识的节点数目随时变化,不可预知.
定义5(公共账本)公共账本(public ledger)是指能够满足一致性和活性的可信“公告牌”,任何人都能够在上面存放消息,任何人都能够读取账本上的内容.
公共账本的概念是对状态机复制的延伸,状态机复制在过去仅仅被用在授权网络中完成数据的同步,而公共账本意味着在非授权网络中,实现公开透明、任何节点能够随时访问、添加信息的公共的账本.
公共账本应当满足以下两个安全特性[51].
定义6(持续性)持续性(persistance)是指诚实用户在账本的某个位置,如第i个区块的第j个位置上传了合法交易tx,则最终所有诚实用户的账本中,第i个区块的第j个位置的交易一定存在,且一定是tx.
定义7(活性)活性(liveness)是指在某个时间,诚实用户上传了交易tx 至公共账本,则在等待时间t之后,交易tx 一定出现在每个诚实用户的账本中.
定义8(共同前缀)共同前缀(common prefix)用符号Qcp表示,安全参数k∈N任意两个诚实节点P1,P2在两轮r1,r2中所提交的链C1,C2,一定满足即当r1≤r2时,满足代表的是链C1去掉末尾的k个区块,代表C1是C2的前缀.节点P1,P2代表的可以是同一个节点.

表1 共识机制总结Table 1 Summary of consensus mechanisms
共同前缀特性可以这样理解,诚实节点产生的链最终会彼此一致,且诚实节点已经确定的链不会被改写.
定义9(链质量)链质量(chain quality)用符号Qcq表示,安全参数任何诚实节点P的链C中除去最新的k0区块后,任意k个连续的区块中,恶意区块的比例不超过µ.
链质量属性是指连续的区块中必定有足够比例的区块由诚实用户产生.
定义10(链增长)链增长(chain growth)用符号Qcg表示,安全参数为对于任意轮r(r>r0),诚实节点P在第r轮的输出的区块链为C1,在第r+s轮输出的区块链为链C2,满足
此外,区块链特性还包括公平性.
定义11(公平性)公平性(fairness)是指诚实用户实际产生的区块占比大致与诚实用户的算力占比(或与诚实用户所拥有的财产占比)相符.对于采用PoW 的区块链来说,如果诚实用户的算力占全网算力的1/2,那么能够保证大约1/2 的区块由诚实用户产生.
定义12(弱一致性)弱一致性(weak consistency)也被称为最终一致(eventual consistency),一般根据出块者选举的方式,同一个时期可能有两个甚至两个以上合法的出块者,这种情况下,区块链可能出现分叉,如比特币.但是经过很长一段时间之后,最终区块链的区块是确定的.
定义13(强一致性)强一致性(strong consistency)是指区块的生成是确定性的,具有强一致性的共识又被称为确定性共识,通过选取一个确定的委员会,再由委员会内部运行的分布式一致性算法生成新区块,每一轮的区块都是确定的,一般情况下不会产生分叉.
相比于弱一致性,强一致性具有以下优点:
(1)区块链无分叉,通过运行分布式一致性算法,实现状态机复制,节点不需要浪费大量算力;
(2)交易能够得到较快速度的确认,节点上传的交易只要被写入到区块中,便可以确认交易的合法性,完成整个交易过程;
(3)能够提供前向安全(forward security).只要区块被写入到区块链上,就可以确保区块不会被篡改,区块将一直保持在链上.
2.2 模型分类
以下分别介绍共识机制的网络模型、腐化模型和敌手模型.
2.2.1 网络模型
定义14(同步网络)同步网络(synchronous network)是指诚实节点之间的消息按照轮来传播,在每一轮中,诚实用户发出的消息能够在下一轮之前到达其他所有诚实用户.同步网络是比较强的网络模型.
定义15(部分同步网络)部分同步网络(partially synchronous network)是指网络中的消息传输存在一定的上限∆,时延上限不能作为协议的参数使用,但是能够确保诚实用户发出的消息在∆时间之后到达其他所有诚实用户[62].部分同步网络是区块链协议分析中常用的网络模型.
定义16(异步网络)异步网络(asynchronous network)是指敌手能够任意拖延诚实用户的消息或将其打乱顺序,只要保证最终诚实用户的消息能够到达彼此.
2.2.2 腐化模型
腐化(corruption)是指敌手通过向目标节点发动攻击,获取目标节点的秘密信息,进而控制目标节点的输入输出消息,使其完全受到自身的控制.
定义17(静态敌手)静态敌手(static corruption)是指敌手只能在协议开始前选定其腐化的目标,一旦协议开始运行,便不能够腐化诚实节点.敌手控制的节点数量在协议运行期间不会发生改变.
定义18(τ-温和敌手)τ-温和敌手(τ-mildly corruption)是指敌手腐化一个节点需要一定的时间τ来完成.敌手发布对目标节点的腐化指令,经过τ时间后,目标节点被腐化,受到敌手的控制,成为恶意节点.在实施腐化的t时间内,节点仍然属于诚实节点.温和敌手是区块链协议分析中经常采用的腐化模型.
定义19(适应性敌手)适应性敌手(adaptive corruption)是指敌手能够根据协议运行过程中搜集的信息,动态且适应性对目标节点完成腐化.适应性敌手的能力十分强大.
2.2.3 敌手模型
敌手模型是指对敌手能够掌握的算力或财产占比作出一定的限制,一般用f代表敌手数量,n代表网络中节点总数,利用n与f的关系来刻画敌手模型,将其分为如下几类:
定义20(n=2f+1)敌手算力(或财产)占全网算力(或财产)的比例不超过1/2.
比特币采用的敌手模型是n=2f+1,敌手算力一旦超过1/2,便可以制造区块链的分叉,发动所谓的“51%” 攻击.
定义21(n=3f+1)敌手算力(或财产)占全网算力(或财产)的比例不超过1/3.
如PBFT 之类的经典分布式共识机制要求敌手模型为n=3f+1,而在一些混合共识中,受到委员会内部分布式一致性算法的限制,同样需要敌手模型为n=3f+1.
定义22(n=4f+1)敌手算力(或财产)占全网算力(或财产)不超过1/4.
考虑到自私挖矿导致链质量下降,某些混合共识在选举委员会时,为了满足委员会成员中敌手数量不超过1/3,需要要求区块链链质量大于2/3,这种情况下需要满足n=4f+1,才能满足委员会中诚实用户占据2/3 以上的要求.
3 经典分布式共识机制
3.1 概念
经典分布式共识机制是指在授权网络中,一组节点实现状态机复制.它主要面向一些分布式数据库系统,像Paxos 算法主要针对网络中可能出现的崩溃节点而设计,而PBFT 能够容忍一定的拜占庭错误节点.根据网络模型假设,可以将经典分布式共识机制分为以下三类:第一类是部分同步网络分布式一致算法,部分同步网络模型是经典分布式共识和区块链共识机制最常用的模型; 第二类是异步网络分布式一致算法,异步网络模型也是共识研究中经常采用的模型,在完全异步网络中实现共识通常需要随机数发生器来完成; 第三类是同步网络分布式一致算法,同步网络模型假设较强,在实际运用中可能会遇到很多问题.
3.2 典型方案分析
3.2.1 部分同步网络分布式一致算法
(1)Paxos
Paxos 在n=2f+1 模型中,能够容忍f个崩溃节点,实现了基于消息传递的一致性算法.Paxos 中提出了主节点、备份节点的概念,其主要过程如下:
Paxos 允许多个主节点提议,并对主节点赋予不同的等级,等级高的主节点的提议能够打断等级低的主节点提议,即使等级低的主节点提议已经得到备份节点的承诺消息.Paxos 协议被用于分布式系统中数据库的维护,只能对崩溃节点容错,不能对拜占庭节点实现容错.
(2)PBFT
PBFT 的敌手模型为n=3f+ 1,网络模型为部分同步网络.PBFT 算法中,存在一个主节点(primary)和其他的备份节点(replica),PBFT 共识机制主要包含两部分:第一部分是分布式共识达成,在主节点正常工作时,PBFT 通过预准备(pre-prepare)、准备(prepare)和承诺(commit)三个步骤完成共识; 第二部分是视图转换(view-change),当主节点出现问题不能及时处理数据请求时,其他备份节点发起视图转换,转换成功后新的主节点开始工作.主节点以轮转(round robin)的方式交替更换.
PBFT 的分布式共识达成过程如下:
①请求(propose).客户端(client)上传请求消息m至网络中的节点,包括主节点和其他备份节点.
②预准备(pre-prepare).主节点收到客户端上传的请求消息m,赋予消息序列号s,计算得到预准备消息(pre-prepare,H(m),s,v),其中H(·)是单向哈希函数,v代表的是此时的视图(view),视图一般用于记录主节点的更替,主节点发生更替时,视图随之增加1.消息发送者节点在发送消息前需利用自身私钥对消息实施数字签名.主节点将预准备消息发送给其他备份节点.
③准备(prepare).备份节点收到主节点的预准备消息,验证H(m)的合法性,即对于视图v和序列号s来说,备份节点先前并未收到其他消息.验证通过后,备份节点计算准备消息(prepare,H(m),s,v)并将其在全网广播.与此同时,所有节点收集准备消息,如果收集到的合法准备消息数量大于等于2f+1(包含自身准备消息)个,则将其组成准备凭证(prepared certificate).
④承诺(commit).如果在准备阶段中,节点收集到足够的准备消息并生成了准备凭证,那么节点将计算承诺消息(commit,s,v)并广播,将消息m放入到本地日志中.与此同时节点收集网络中的承诺消息,如果收集到的合法承诺消息数量大于等于2f+1(包含自身承诺消息),那么将其组成承诺凭证(committed certificate),证明消息m完成最终承诺.
⑤答复(reply).备份节点和主节点中任意收集到足够承诺消息并组成承诺凭证的节点,将承诺凭证作为对消息m的答复发送给客户端,客户端确认消息m的最终承诺.
PBFT 的分布式共识过程如图1 所示:
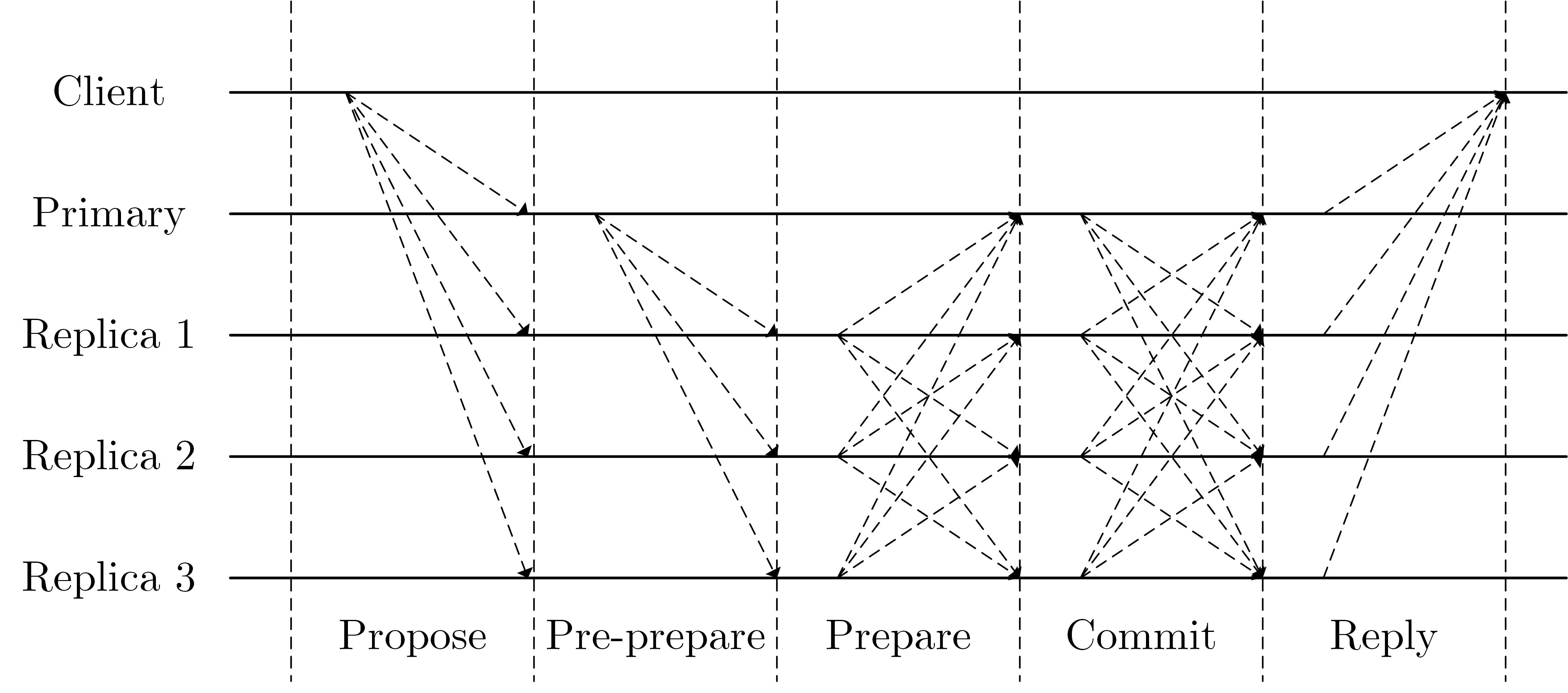
图1 PBFT 算法流程图Figure 1 Process of PBFT algorithm
在PBFT 中,存在检查点(checkpoint)机制,由于每个消息都被赋予了一定的序列号,如消息m对应的序列号为118,当不少于2f+1 个节点组成消息m的承诺凭证,完成消息承诺之后,序列号118 成为当前的稳定检查点(stable checkpoint).检查点机制被用于实现存储删减,即当历史日志内容过多时,节点可以选择清除稳定检查点之前的数据,减少存储成本.另外稳定检查点在PBFT 的视图转换中也起到了关键作用.
当主节点(主节点)超时无响应或其他节点大多数认为其存在问题时,会进入视图转换过程.PBFT的视图转换过程如下:
①视图转换信息广播.备份节点i的当前视图v,当前稳定检查点S∗,对于稳定检查点S∗的凭证C(即2f+1 个节点的有效承诺凭证).U为节点i当前视图下,序列号大于S∗,且已经形成准备凭证的消息集合.节点i计算视图转换消息:vci:(view-change,v+1,S∗,C,U,i),并将其在全网广播.
②视图转换确认.备份节点收集对视图v+1 的转换消息并验证其合法性,验证通过后计算视图转换确认消息vcai:(view-change-ack,v+1,i,j,H(vcj)),其中i是当前备份节点,j是发送视图转换消息vcj的节点,H(vcj)是视图转换消息的摘要.vcai消息相当于对每个节点发出的视图转换消息确认.备份节点将消息vcai直接发送给视图v+1 对应的新的主节点.视图v+1 的主节点由轮转方式决定.
③新视图广播.对于每个视图转换消息,如节点j的消息vcj,如果vcj合法,则其他节点将会向主节点发送对vcj的视图转换确认消息,因此,当主节点收集到2f−1 个对vcj的视图转换确认消息,则可认为vcj有效,并将vcj和其对应的视图转换确认消息放入到集合S中.主节点收集其他节点的有效视图转换消息,如果S中消息不少于2f个,则主节点计算新视图消息nv:(new-view,v+1,S,U∗).其中U∗包括当前的稳定检查点和稳定检查点之后序列号最小的预准备消息.
PBFT 中节点之间采用消息认证码(message authenticated codes,MAC)[63]实现身份认证.MAC是指在消息传输时,通过特定哈希函数计算消息摘要,将消息摘要和消息一并传输.任意两个节点之间存在一对会话密钥来计算消息的MAC.会话密钥可以通过密钥交换协议来产生并实现动态更换.PBFT 实现了状态机复制的一致性和活性,在协议正常运行时,通信复杂度为O(n3).在视图转换时,通信复杂度为O(n4).
(3)Hot-Stuff
Hot-Stuff 算法由Abraham、Gueta和Malkhi[11]提出,它对PBFT 做出改进.Hot-Stuff 网络模型为部分同步网络,敌手模型为n=3f+1.其采用并行流水线处理提议,相当于将PBFT 中的准备和承诺阶段合并成一个阶段.Hot-Stuff 算法流程如图2所示.

图2 Hot-Stuff 算法流程图Figure 2 Process of Hot-Stuff algorithm
a(1)是指节点a在第1 轮的提议,当节点a收集到对a(1)的准备消息大于等于2f+1 个时,节点a便组成了对a(1)的准备凭证CC(a(1)),并将CC(a(1))与第二轮的提议a(2)组成第二轮的消息发送给其他节点.如果其他节点对第二轮的消息投票大于等于2f+1 个,相当于完成了如下两个过程:第一是确认了a(2)的提议,能够组成对于a(2)的准备凭证CC(a(2)); 第二是确认了CC(a(1)),即完成了提议a(1)的最终承诺.对于准备和承诺的并行流水线处理能够很大程度上提升内部共识的效率.
与此同时,Hot-Stuff 采用线性视图转换(linear view change,LVC),降低了视图转换中的通信复杂度.在PBFT 中,当视图转换发生时,新的领导者需要广播目前的稳定检查点,并且提供2f+1 个节点的承诺凭证,证明检查点的合法性,通信复杂度为O(n4).而在LVC 中,新的领导者只需广播1 个承诺凭证.其他节点只有在收到比本地稳定检查点更高的检查点时,才判定新领导者的合法性.在这种情况下,如果新的领导者隐藏了更高的检查点,不会影响到协议的安全性,只会让其受到惩罚.
对于每个消息,如对提议a(1),PBFT 中使用完整的2f+1 个签名作为其准备凭证CC(a(1)),而Hot-Stuff 中使用门限签名技术,将一个门限签名作为准备凭证CC(a(1)),领导者作为签名的收集者完成签名份额的收集和门限签名的重建.综合LVC和门限签名技术,Hot-Stuff 最终每轮的通信复杂度为O(n2).
Hot-Stuff 利用门限签名、并行流水线处理和线性视图转换等技术,极大提高了分布式一致性算法的效率.Abraham 等人[64]提出了同步网络模型下的Hot-Stuff 协议,实现了快速响应特性.交易确认时延为2∆+O(δ),∆表示网络时延上限,δ表示网络真实时延.
(4)SBFT
可扩展拜占庭容错协议(scalable Byzantine fault tolerance,SBFT)由Golan-Gueta 等人[12]提出.SBFT 主要解决拜占庭容错协议在应用到区块链中的去中心化和扩容问题,SBFT 的敌手模型n=3f+1,能够允许200 多个节点同时完成共识.SBFT 利用领导者作为信息、签名的收集者,采用门限签名降低通信复杂度.在PBFT 中,每一轮的投票,节点需要向网络中其他节点广播投票,并且收集其他节点的投票,而SBFT 利用领导者收集每一轮投票,收集到的签名数量达到门限要求以后,领导者便能恢复总的门限签名,从而将通信复杂度从O(n3)降低为O(n2).
3.2.2 异步网络分布式一致性算法
Fischer、Lynch和Paterson[65]提出了FLP 不可能定理,在网络可靠,但允许节点失效的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识机制.Rabin[66]和Ben-Or[67]利用所有节点可见的随机数发生器实现了异步网络中的分布式一致性协议,敌手对于随机数发生器生成的随机数是不可预知的,随机数发生器成为了异步网络共识中常用的工具.
Cachin、Kursawe和Shoup[68]在2005年提出了异步二元拜占庭一致算法(asynchronous binary Byzantine agreement,ABBA),在异步网络中实现分布式一致算法.ABBA 正常运行之前需要建立初始化设置,由可信中心参与,对协议和数据初始化.初始化阶段过后,利用RSA 门限签名生成每一轮的随机数,作为不可预知的随机数发生器.ABBA 算法主要包括预处理、预投票、主投票、决策检验和随机数生成等步骤.ABBA 敌手模型为n=3f+1,通信复杂度为O(n3).
Veronese 等人[13]提出了MinBFT,在异步网络中实现共识,敌手模型为n=2f+1.MinBFT 主要利用了唯一连续标识符生成器(unique sequential identifier generator,USIG)作为可信计数器,网络中节点均能获得USIG 的信息.MinBFT 采用与PBFT 类似的流程,网络中存在主节点和备份节点,主节点即领导者利用USIG 为每一轮提议值分配序列号,序列号与提议值一一对应.由于USIG 产生的序列号是单调增加的,且每个节点获得的数值都保证相同,保证领导者不能对提议值模棱两可,即保证领导者不能将一个序列号分配给不同的提议值.USIG 作为可信计数器确保了每个序列号只能对应唯一的提议值,这也是敌手模型为n=2f+1 的原因.MinBFT 的主要步骤包括客户端请求、准备、承诺和答复阶段.
Miller 等人[14]提出了蜜獾拜占庭容错协议(Honey Badger BFT),不需要任何时间假设实现异步网络中的分布式一致性共识.该协议对文献[68]提出的ABBA 作出改进,提出了异步共同子集(asynchronous common subset,ACS),ACS 包括可靠广播(reliable broadcast,RBC)和异步二元一致算法(asynchronous binary agreement)两个阶段.Honey Badger BFT 通过门限加密的方式解决了交易审查(transaction censorship)问题.
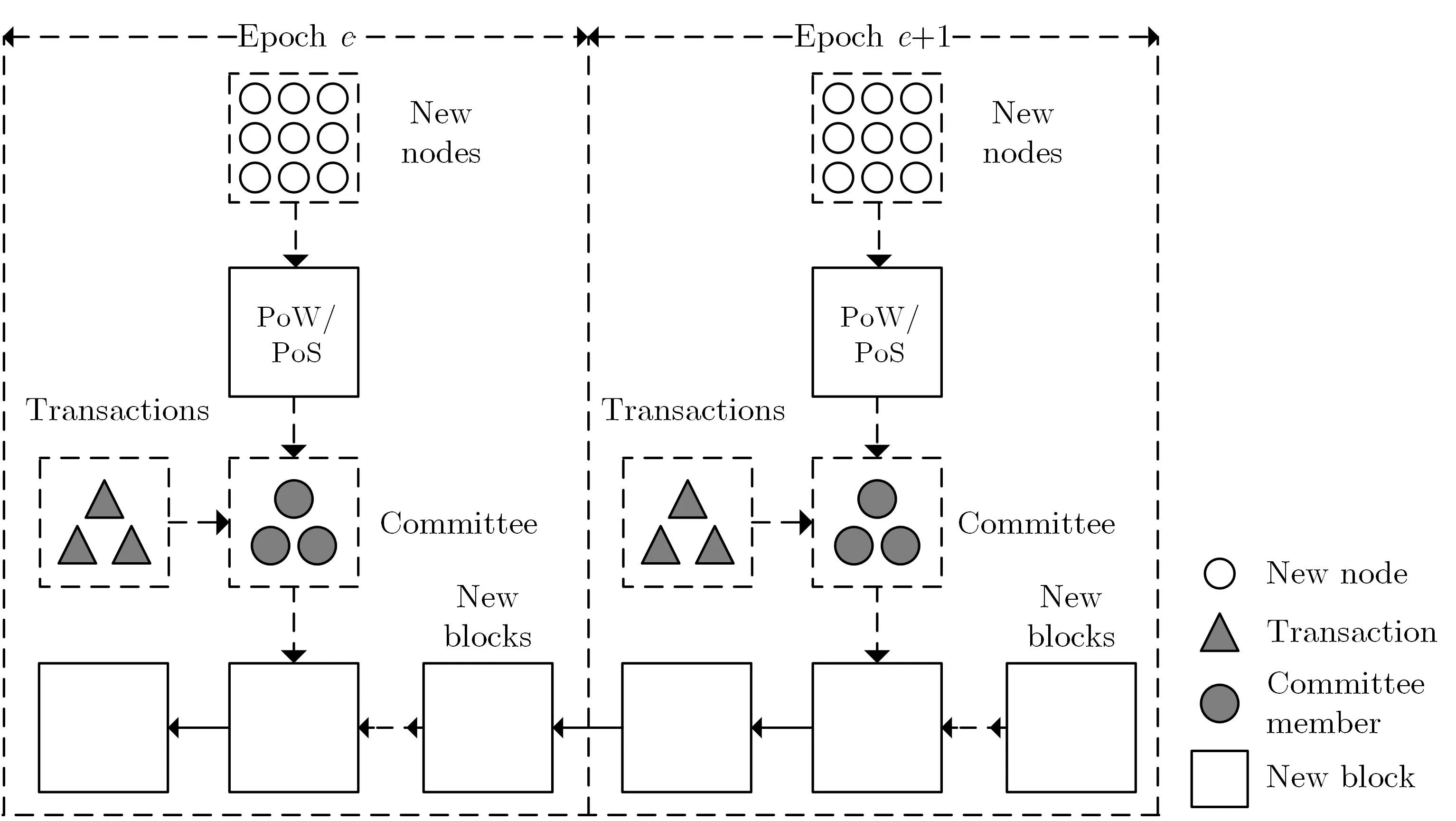
假设网络中共n个节点,每一轮共识就大小为B的数据运行共识机制.Honey Badger BFT 算法的主要过程如下:
①节点收集交易.每个节点收集交易数据,放到自身的交易数据缓冲区,每一轮共识运行之前,节点取出缓冲区中的前B/n个交易.②交易数据门限加密.节点对前B/n个交易门限加密,生成每个节点对应的加密后的数据.③RBC 广播.节点将门限加密后的密文数据利用RBC 广播.④ABA 共识.领导者收集节点发送的加密后的交易数据,组成交易集密文,就交易集发起ABA 共识.⑤交易数据门限解密.ABA 共识完成,即对交易集密文数据达成一致,此时节点运行门限解密算法,只要至少f+1 个节点完成解密,即可恢复交易集中的交易明文数据,完成交易确认.
Honey Badger BFT 敌手模型为n=3f+1,防止了交易审查,实现了网络性能和吞吐量的提升.
验证的异步拜占庭一致算法(validated asynchronous Byzantine agreement,VABA)由Abraham、Malkhi和Spiegelman[52]提出.在异步网络环境下,VABA 实现了多值拜占庭一致算法,敌手模型为n=3f+1.VABA 基于随机预言模型,在每次共识过程中,采用多个并行的领导者提议,从中随机选取一个作为最终结果.VABA 采用门限签名等技术使每一轮的通信复杂度为O(n2).
3.2.3 同步网络分布性一致算法
Bazzi[69]在2000年提出了同步拜占庭“法定人数(quorum)” 系统,在同步网络模型中,给出了拜占庭法定人数系统的定义.假设协议中敌手数量为f,在一轮中就某个数值v运行分布式共识达成算法,敌手为了扰乱协议执行,可能对数值v′投票.此时协议需要规定对某个数值的投票数必须达到某个法定人数,如2f+1(假设敌手模型为n=3f+1),才能确保一轮共识运行完毕后最多对一个特定值达成共识.因为假设v′=v,且v′跟v同样获得了2f+1 的投票,此时对于二者的投票必然存在交集,其人数至少为f+1,即这f+1 个节点同时对v′和v投票.由于敌手个数最多为f,所以此f+1 个节点至少包含一个诚实节点,这与诚实节点不能模棱两可的假设相矛盾.拜占庭法定人数系统在同步网络环境中达成了共识.
Liu 等人[53]研究了同步网络、认证信道条件下的拜占庭共识,提出了XFT.XFT 能够同时容忍崩溃节点和拜占庭错误节点,敌手模型为n=2f+1.XFT 在n和f数值很小的时候运行较为高效,但随着节点和错误节点增加,其性能严重下滑.
Abraham 等人[54]提出高效同步拜占庭共识(efficient synchronous Byzantine consensus,ESBC),在同步网络和认证信道中,其敌手模型为n=2f+1.该协议的设计借鉴了Paxos 的思路,每个时期有一个领导者,领导者在处理新提议前,必须先处理上个领导者未处理完的提议.该协议利用网络同步假设抵抗了拜占庭节点的攻击,每一轮提议经过四步便可达成共识.
Kiayias和Russell[70]提出Ouroboros-BFT,在同步网络中,其敌手模型为n=3f+1.在乐观情况下,交易能够以网络实际速度得到确认,即实现交易快速响应.上传交易的客户端能够得到交易确认的证明.即使在网络情况较差,出现网络隔离时,Ouroboros-BFT 仍然能够确保系统的安全性.
Malkhi、Nayak和Ren 等人[71]提出了Flexible BFT,在同步网络中实现了状态机复制.Flexible BFT 只有在承诺步骤要求网络是同步的,即只在承诺步骤中使用网络延时参数,在其他步骤不需要网络同步的假设.
3.3 综合分析
经典分布式共识主要研究的是在授权网络中实现状态机复制,并且保证协议的安全性和活性.从网络模型方面来说,最为典型的是部分同步网络,网络中消息能够在一定的时间上限内到达所有诚实节点,最贴近现实网络,也是目前区块链协议经常采用的网络模型.从容错角度来看,Paxos 协议只能容忍崩溃节点,而PBFT 等拜占庭容错协议能够容忍网络中的拜占庭节点,拜占庭节点可以是崩溃节点,也可以是被敌手控制的恶意节点,因此拜占庭容错共识更符合实际网络,在区块链共识中的应用也更为广泛.经典分布式共识的研究方向主要有以下三点:
第一,高效的轮内投票算法.经典分布式共识机制一般采用多轮投票的方式来对某个值达成共识,如何降低每一轮的通信复杂度,提高算法的执行效率是未来的研究热点,如采用并行流水线技术并行处理每一轮提议的数值、采用门限签名等技术降低节点间的通信复杂度等[72];
第二,更强的容错能力.经典分布式共识机制需要假设网络中敌手数量不超过特定比例,当网络中敌手数量超过该比例时,如何有效检测以及恢复.如何借助其他可信硬件等使网络的整体容错能力更强;
第三,高效的视图转换.视图转换是经典分布式共识机制需要解决的重要问题,当委员会领导者为恶意节点或消极怠工时,需要一定的机制选举新的领导者,在新领导者接任的过程中,如何高效地获取其他节点当前的状态、处理之前未处理完的提议是需要研究的问题[73].
4 授权共识机制
4.1 概念
授权共识机制是指在授权网络中,节点首先经过身份认证加入网络中,然后在节点之间运行某种分布式一致性算法,实现状态机复制,对数据达成共识,进而生成和维护授权网络内部的区块链.授权共识机制产生的区块链不同于比特币之类的“公链”,节点只有在获得身份认可之后才能加入授权网络中,进入到授权网络内部,从而完成共识过程.
4.2 典型方案
(1)Hyperledger
超级账本(Hyperledger)是Linux 基金会发起的开源区块链项目,意在提供企业级的开源分布式账本框架和源代码.Hyperledger 包括八大项目,其中Hyperledger Fabric 是基于社区的项目,为区块链的应用提供支持框架.Cachin[15]提出了Hyperledger Fabric 的基本框架.Androulaki 等人[16]对Hyperledger Fabric 进一步完善.Hyperledger Fabric 将智能合约称为链码(chaincode),链码是整个分布式应用平台的核心部分,可以由不可信的开发者开发.系统链码用来配置整个区块链系统的安全参数.
Hyperledger Fabric 中,主要有以下角色:①客户端(clients).客户端主要产生交易并上传至网络,在链码执行过程中起到一定的辅助作用.②普通节点(peers).系统中所有节点都需要完成身份认证,Hyperledger Fabric 采用成员服务提供商(membership service provider,MSP)来为每个节点授予身份.③背书节点(endorsers).背书节点是指在系统中负责执行链码的节点,每个交易根据链码都会有一组背书节点负责其执行.④排序节点(orderers).排序节点负责对已执行链码运行分布式一致性算法,对交易排序,并将其写入到区块中,形成公共账本.
Hyperledger Fabric 共识过程如下:①执行(execute).客户端首先将交易发送至背书节点,背书节点执行对应的链码,并记录执行后的结果.②排序(order).链码在执行之后,进入排序阶段.排序者内部运行分布式一致性算法来将已执行交易排序,输出总交易序列,并将其打包写入到区块中.排序者将以上信息广播给所有节点.Hyperledger Fabric 运用拜占庭容错一致性算法实现对交易的排序和区块的共识.③验证(validate).所有收到新区块的节点验证其中交易的正确性,验证背书节点对交易的执行是否一致,验证通过后将新区块更新到本地区块链.
Hyperledger Fabric 采用的模块化的设计思想将智能合约的执行、排序和验证分离开来,节点在处理合约时更加具有针对性和高效性.
(2)DFINITY
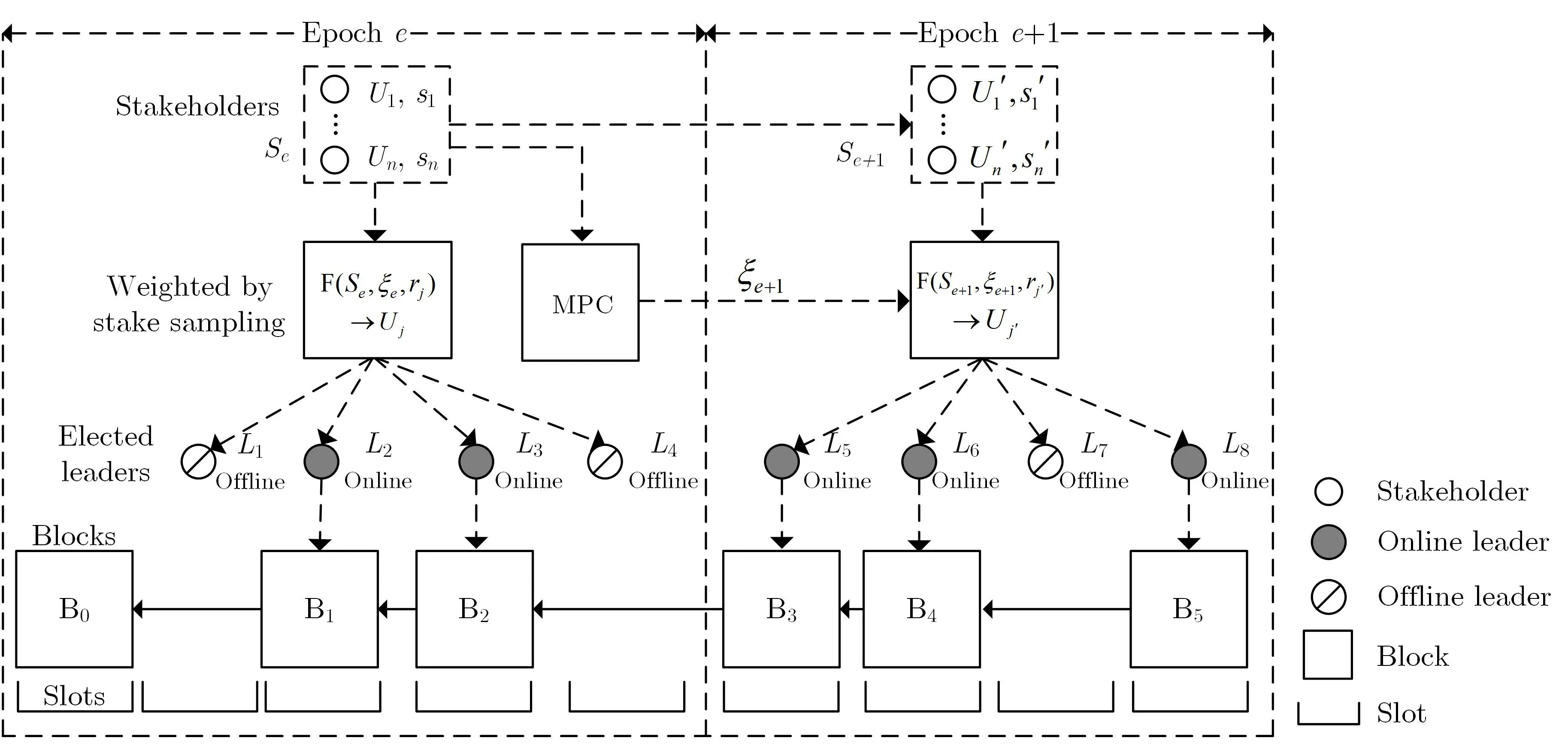
DFINITY 由Hanke、Movahedi和Williams[17]提出.DFINITY 网络模型为部分同步网络,敌手模型为n=2f+1.DFINITY 采用模块化的设计思想,将整个共识机制分为身份层、随机信标层、区块链层、公示层.DFINITY 协议以时期为单位运行,提出了“门限转发” 算法,将所有参与节点分为m个不同的组,每一组相当于委员会,每个时期由一个随机的委员会负责交易处理、共识运行,而在时期结束时,委员会运行随机数生成算法,利用BLS 门限签名和可验证随机函数生成随机数,根据随机数决定下一时期的由哪个组担任委员会.DFINITY 共识机制如图3所示.
DFINITY 共识机制具体运行流程如下:
①节点身份确认.DFINITY 是授权共识,因此所有参与共识的节点需要完成身份注册,注册人需要抵押一部分资产,若在参与协议期间,节点出现恶意操作,则扣除其抵押资产.
②协议初始化.根据创世区块中随机数的设定,DFINITY 的节点被随机分配到不同委员会,每个委员会内部运行分布式密钥生成算法(distributed key generation,DKG)[74]生成每个成员的公私钥对和整个委员会的总验证公钥,用于BLS 门限签名算法[75]对签名的计算和验证.DKG 算法由多个并行的可验证秘密分享算法(verifiable secret share,VSS)[76]构成.根据创世区块中的随机数选择初始委员会.
③随机数生成.当前委员会内部成员运行(t,n)-BLS 门限签名算法,t是指门限值,n是委员会内成员个数,令n=2t+1,当敌手数量f小于t时,可以保证能够顺利恢复BLS 门限签名.委员会成员将上一轮随机数作为消息并产生BLS 签名,任意节点如果收集到t个有效签名份额,便能利用BLS 门限签名的签名重建函数恢复总签名.BLS 门限签名的唯一性保证了所有节点恢复出的总签名完全一致,不会因为选择的签名份额集合不同而导致最终签名的不同.将总签名作为可验证随机函数(verifiable random function,VRF)[77]的输入,运行哈希运算得到本轮的随机数ξr.
④区块提议和公示.委员会成员将本轮随机数ξr作为伪随机数生成器(pseudo-random number generator,PRG)[78]的种子,为每个节点生成对应的随机数.然后将每个节点对应的随机数放入到伪随机置换函数(pseudo-random permutaions,PRP)[79]中,确定每个成员在委员会中的排序等级.DFINITY允许委员会中的每个成员作出区块提议,但排序等级高的成员提出的区块具有更高的“重量”.类似于比特币采取的“最长链” 原则,DFINITY 采用“最重链” 原则来处理区块链的分叉.为了防止自私挖矿攻击,DFINITY 采用区块公示机制,只有在一定时间范围内公开的区块才合法.在计算区块链“重量”时,合法区块才被计算入内.
⑤区块最终确认.区块最终确认是指网络中的所有节点在观察到已公示区块达到一定的深度时,将其确定为最终确认区块,其中的交易也完成最终确认.
⑥下一任委员会工作.在当前时期结束后,根据本时期随机数ξr随机选取下一任委员会.
DFINITY 利用门限签名实现了抗偏置随机数的生成,并利用随机数随机选取委员会工作.与此同时,DFINITY 加入的区块公示步骤有效防止了自私挖矿攻击和无利害关系攻击.
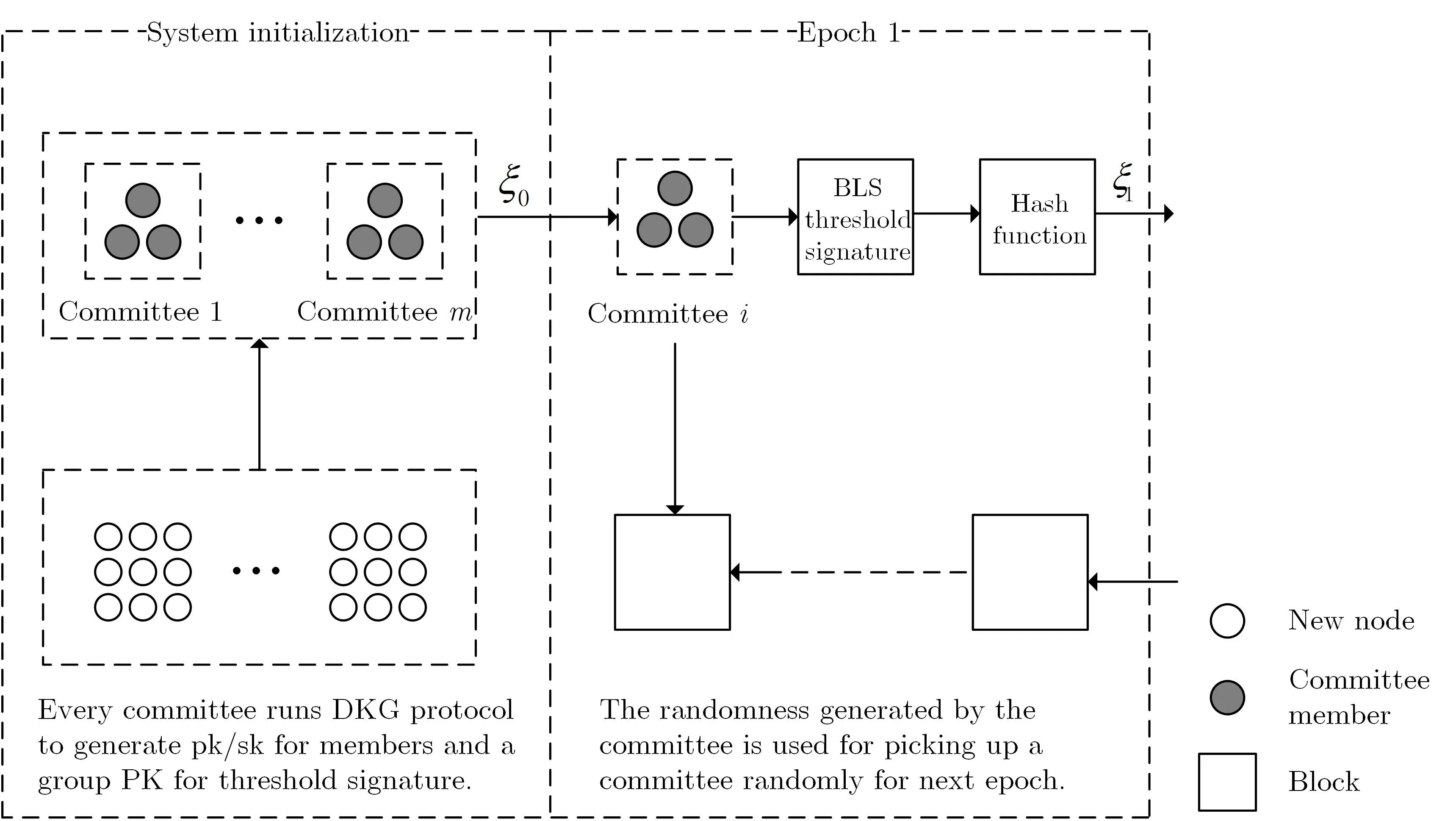
图3 DFINITY 算法流程图Figure 3 Process of DFINITY algorithm
(3)PaLa
PaLa 由Chan、Pass和Shi[18]提出,PaLa 实现了授权网络中的快速共识.PaLa 的网络模型为部分同步网络,敌手模型是n=3f+1.
PaLa 主要在两方面对授权共识作出改进,一方面是对拜占庭容错协议作出改进,在PBFT 中,对每个区块需要3 个阶段的投票和节点之间的信息交互,而PaLa 利用并行流水线的方式处理对区块的投票.如果区块Br首先被提出,经过一轮投票后得到超过2/3 的票,则区块Br提议被确认,在下一轮中,区块Br+1被提出,此轮的投票包括对区块Br的最终确认票和对区块Br+1的公示票,如果此轮的得票数超过2/3,那么认为区块Br被最终确认,区块Br+1提议被确认.并行流水线的处理方法能够在一定程度上提升委员会共识的效率.
另外一方面,PaLa 改进了了委员会重配置的方式.在PaLa 中,每个委员会包含两个子委员会(C0,C1).在投票时,需要每个子委员会都有超过2/3 的成员投票才代表投票通过.在委员会重配置时,委员会由(C0,C1)切换到(C1,C2),只有其中一个子委员会发生变动.这样的重配置方式既能保证充分的安全性,又能确保在委员会重配置期间,协议处理交易的可持续性.
PaLa 利用并行流水线的方式,提高了区块处理的效率,采用子委员会滑窗式的重配置方式,能够保证重配置期间交易处理的可持续性.
4.3 综合分析
授权共识机制中的所有节点在参与共识前,必须要经过身份注册.授权共识主要适用于企业、组织之间的联盟等,在联盟节点参与共识的情况下,能够实现较高的交易吞吐率.授权共识中,网络处理交易的性能受到参与节点计算能力的影响较大.目前,由于授权共识的应用场景大多为联盟之间的数据处理和存储,授权共识需要考虑智能合约的处理问题,因此授权网络中节点分工的明确化和数据处理的模块化显得越来越重要.
5 基于工作量证明的共识机制
5.1 概念
工作量证明最早被用来防止垃圾邮件,由Dwork和Naor[80]在1992年提出.邮件在被发送之前,必须要求邮件发送方完成一定量的计算,如找到某个特定数学难题的解答.Back 在1997年提出,并在2002年正式发表了Hashcash[81],对工作量证明作出了改进,利用单向哈希函数实现工作量证明,即找到哈希函数原像才能完成工作量证明的过程.比特币的出现,将工作量证明运用到非授权网络的共识中,主要用来防止敌手制造假身份发动女巫攻击.
5.2 典型方案分析
(1)比特币
基于工作量证明的共识机制最典型的代表是比特币.在比特币区块链系统中,用户可以上传自身的交易,交易的实质是将一个账户中的比特币转移到另外账户中,一个交易可能存在多个输入和多个输出.合法交易被打包放到区块中,区块最大为1MB(在实施隔离见证[82]之后,区块有适度增大).区块包括区块头和区块体两部分,区块头主要包括指向上个区块的哈希值、交易默克尔树树根值、时间戳和随机数等,区块体主要包括产生的交易.
在比特币中,每个区块的生成者,即上文提到的出块者,会得到一定数量的比特币奖励(目前为12.5 BTC),因此节点为了成为出块者获得收益而持续执行哈希运算,以期寻找到工作量证明,这一过程也被称为“挖矿”,而寻找工作量证明的节点被称为“矿工”.比特币中,每隔大约10 分钟产生一个区块,比特币的区块间隔时间跟比特币的安全性紧密相关,而区块间隔跟当前挖矿难度相关.忽略与共识无关的细节,简化的比特币的共识流程如下:
①节点获取挖矿难度、交易信息.比特币中,节点能够自由加入、退出网络,不需要完成身份注册.节点在挖矿前,首先获取当前工作量证明难度D,并且收集本时期内网络中产生的交易,将交易排列成默克尔树形式,并计算交易构成的默克尔树树根Merkle.与此同时,根据比特币的最长链原则,选取合适的区块链,获取其最末端区块哈希值Ar−1.
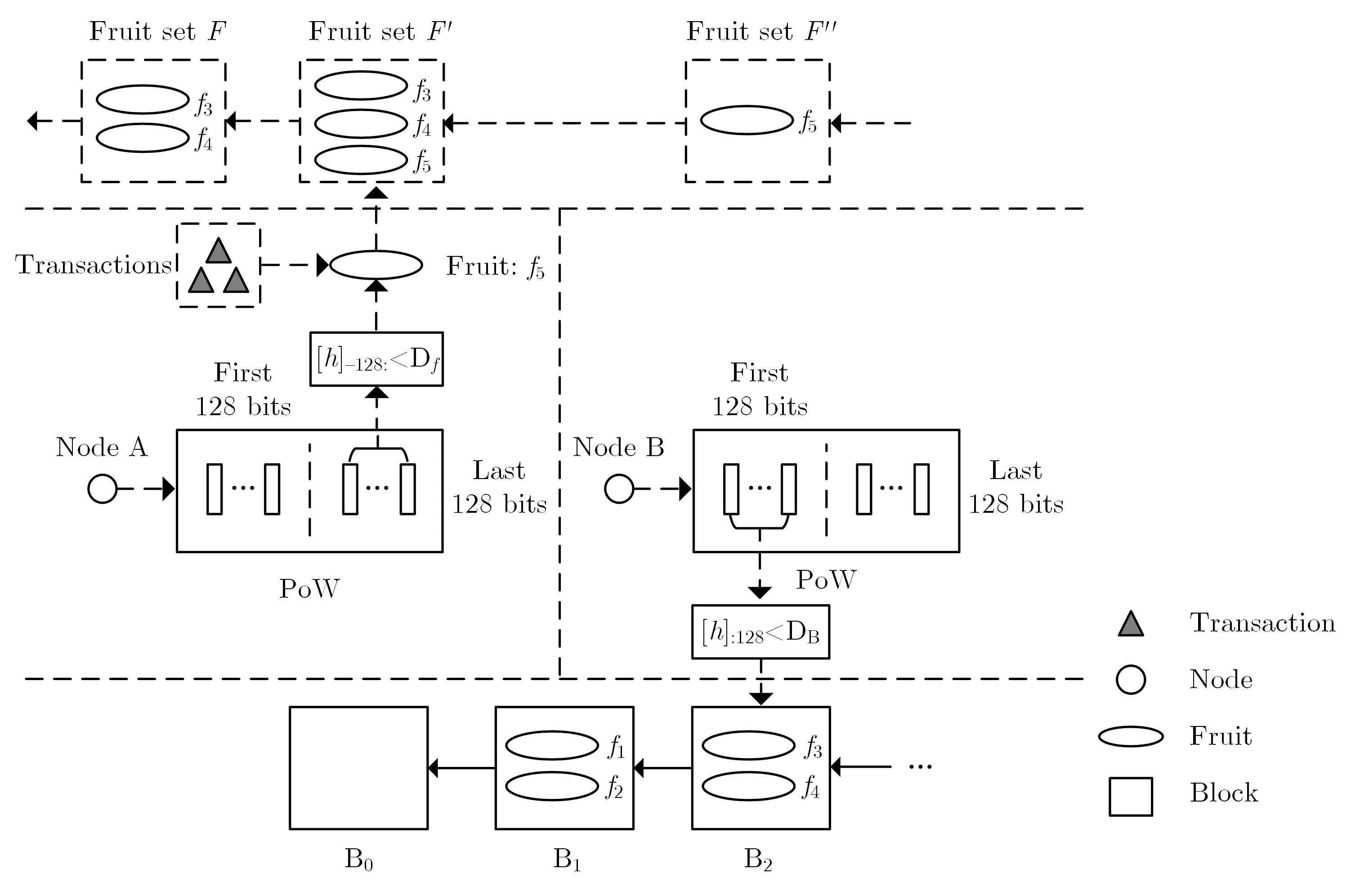
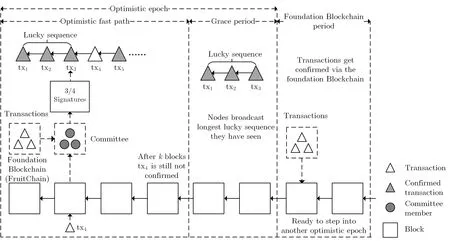
②节点寻找工作量证明.节点通过工作量证明函数开始挖矿:H(Ar−1,Merkle,Nonce) ③新区块广播与验证.找到工作量证明的节点广播新区块和其哈希值,收到新区块的节点验证其区块的合法性和其中包含交易的合法性,检查是否存在双花交易,通过后更新本地区块链并在更新后的区块上继续挖矿.比特币对矿工的激励除了每个区块能够获得的基础奖励外,还包括区块中所有交易的交易费(transaction fees). Garay、Kiayias和Leonardos[51]提出了比特币区块链骨干协议,分析了其基本安全特性.Pass、Seeman和Shelat[83]分析了区块链在部分同步网络环境下的安全性.根据上述文献定义,区块链具有共同前缀、链质量、链增长、公平性、强一致性和弱一致性等特性. (2)以太坊 以太坊(Ethereum)由Buterin[19]提出.以太坊是能够运行智能合约(smart contract)的公共区块链平台.智能合约是以信息化方式传播、验证或执行合同的计算机协议,以脚本代码的形式出现.智能合约允许双方在没有可信第三方存在的情况下实现可信交易. 以太坊的区块大约每隔15 s 产生,为了解决比特币中矿工利用专用集成电路ASIC 挖矿而导致的算力中心化和挖矿资源集中化问题,以太坊设计了抵抗ASIC 且支持轻客户端(light client)快速验证的PoW 算法Ethash,在一定程度上缓解了挖矿中心化问题. 为了解决PoW 挖矿带来的巨大能源消耗问题,以太坊正在从PoW 共识机制向PoS 共识机制转变,并且提出了转变需要经历的四个具体阶段:前沿(frontier)、家园(homestead)、大都会(metropolis)和宁静(serenity)阶段.前沿阶段是2015年以太坊刚开始发布时的试验阶段,家园阶段是以太坊正式发布的版本,完全采用PoW 共识机制.大都会阶段又被分为拜占庭硬分叉和君士坦丁堡硬分叉阶段,2017年10 月,以太坊拜占庭硬分叉成功,为后期引入ZK-Snarks 零知识证明技术[84]提供准备.而君士坦丁堡硬分叉将引入混合PoW和PoS 的共识机制.在宁静阶段,以太坊将完全实行PoS 共识机制.对以太坊和智能合约的研究可以参考文献[85,86]. 以太坊中,区块出块间隔大约为15 秒,短暂的区块间隔时间造成了以太坊区块链容易产生分叉.如果某个矿池算力较大,且由于节点数量多导致其与网络中其他节点的连接数量更多,那么其产生的区块在网络中传播速度较快.当出现分叉时,其他算力较小的矿池或单一节点只能沦为被裁剪掉的分叉,导致这些节点失去了挖矿的动力,进而影响到整个以太坊系统的安全.为了解决上述问题,以太坊调整了区块结构.在比特币中,只有在主链上挖矿得到区块的矿工才会得到酬金,也只有主链的区块能够被接下来的区块所引用.而以太坊允许主链包含分叉,分叉上的区块被称为后产生区块的“叔区块(uncle block)”,能够被后产生的区块所引用,且叔区块的引用者和被引用者都能够获得一定比例的酬金.以太坊的区块结构如图4所示. 图4 以太坊区块链结构Figure 4 Structure of Blockchain in Ethereum 第二个位置的区块首先由算力较大的矿池M产生,称之为M(2),矿池M将区块M(2)在全网广播,由于区块间隔时间只有15 秒,而由于网络延迟的存在区块的广播需要花费一定的时间,在M(2)还未完全到达网络中其他节点的时间,节点a,b和c分别挖到了第二个位置的区块a(2),b(2)和c(2),并在全网广播,此时矿池M 收到了这三个区块,由于其算力较大,很可能最先挖到第三个位置的区块M(3),此时为了防止其他节点在其他分叉上挖矿,矿池M可以选择将在M(3)中引用第二位置的区块,即M(3)区块的叔区块.根据以太坊的设定,每个区块中能够引用叔区块的个数最多为2 个,每个叔区块的引用能够为引用者带来额外的1/32 的出块酬金(block reward),出块酬金为每个区块对应的基本酬金,以太坊中为5个以太币(ETH),因此矿池M选择在a(2),b(2)和c(2)中选出两个区块,如a(2)和b(2),在M(3)区块中引用它们.被成功引用的叔区块,其对应的矿工,能够获得一定比例的酬金,“直系” 叔区块,即叔区块与主区块相隔“一代”,其对应矿工能够获得7/8 的出块酬金,相隔“二代” 的被引用叔区块,其矿工能够获得6/8 的出块酬金,酬金以此规则递减,直到相隔“八代” 的叔区块不会得到酬金,以防止恶意节点在历史区块上制造分叉.在本文所述情境中,由于M(3)区块引用了a(2)和b(2)区块,因此节点a和b分别能够获得7/8 的出块酬金,而矿池M获得了1 个完整的出块酬金和2/32 的额外出块酬金.此时,理智的节点a和b应当选在M(3)区块后继续挖矿.而在第四个位置,如果矿池M找到了新的区块M(4),仍可以选择将相隔二代的叔区块c(2)在M(4)中引用,此时c节点将获得6/8 的出块酬金,矿池M将获得1 个完整的出块酬金和1/32 的额外出块酬金. (3)Bitcoin-NG Bitcoin-NG 由Eyal 等人[20]提出,意在提升比特币处理交易的能力,其敌手模型为n=2f+1.Bitcoin-NG 的区块分为两种,第一种是关键块(key block),关键块类似于比特币中的区块,每十分钟产生一个关键块,节点同样通过工作量证明的方式成为关键块的出块者,关键块包括上个区块哈希值、时间戳、随机数和出块者公钥等信息,主要用来选定一个时期的出块者,不用来记录交易; 第二种是微块(micro block),微块在关键块之间,由本时期的出块者负责生成,微块中包含了当前发生的交易,微块以不超过10秒/个的速度产生.Bitcoin-NG 共识机制如图5所示. Bitcoin-NG 的激励机制与比特币有所不同,在Bitcoin-NG 中,激励主要包括两部分,一部分是挖到关键块的矿工直接获得一定数量的新币,这一点类似于比特币,另一部分是交易费的分配,假设两个连续的关键块分别由节点A和节点B产生,则其中间包含的微块中的交易费的40% 分配给前一个节点A,60% 分配给后一个节点B,为了预防区块链产生分叉,Bitcoin-NG 中的酬金在100 个关键块之后才能使用.Bitcoin-NG 的激励机制存在一定的问题,交易费的分配比例能够优化[87].敌手对Bitcoin-NG 发动自私挖矿等攻击获得的收益相比于Bitcoin 更高[88]. 图5 Bitcoin-NG 共识机制Figure 5 Consensus mechanism of Bitcoin-NG 在Bitcoin-NG 中,微块的产生不需要工作量证明,因此节点能够快速廉价的产生微块,恶意节点可能通过产生微块分叉来发起双花攻击,因此Bitcoin-NG 采用“毒药交易(poison transaction)”,允许后面的出块者对恶意节点举报,举报成功则恶意节点获得的酬金无效,举报者能够获得恶意节点酬金5% 的奖励. Bitcoin-NG 与比特币相比,能够在增加交易区块频率、提升交易吞吐率的同时,保证协议的安全性和公平性.其提出的微块思想,将交易区块与出块者选举的过程分离开来,体现了协议设计的模块化思想. (4)FruitChains FruitChains 由Pass和Shi[21]提出,主要为了解决比特币区块链系统中存在的公平性问题,即由于自私挖矿攻击导致的诚实用户链质量的下降,其敌手模型为n=2f+1. FruitChains 首次提出了“水果(fruit)” 的概念,一个水果可能包含多个交易,而一个区块可能包含多个水果,水果的产生也是通过寻找工作量证明来完成,FruitChains 中水果和区块的挖矿同时运行,且利用同一个哈希函数完成,该算法的设计主要受到Garay、Kiayias和Leonardos[51]的比特币骨干协议中提出的“2 合1 PoW” 算法的启发.FruitChains 共识机制过程如图6所示. FruitChains 中,水果被定义为f=(h−1;h′;η;digest;m;h),其中h−1是指上个区块的哈希值,h′是指水果f指向的区块,此处,水果指向的区块只能为区块链末端几个区块之一,以此保证水果的新鲜性.η长度为128 位,它是挖矿的随机数,即工作量证明的解.digest 是指目前有效水果集合F的哈希摘要,有效水果集合F是指当前新鲜的且未被区块包含的水果的集合.m是指要被写入水果f中的交易集合.h长度是256 位,它是指当前水果f的哈希值.如果h的后128 位小于水果挖矿难度Df,则代表找到了水果.在水果f中,h−1和digest 对于水果本身是没有含义的,它们被用于同时运行的区块挖矿中. FruitChains 中,区块被定义为B=((h−1;h′;η;digest;m;h),F).其中h−1,h′,η,digest,m和h的含义与之前水果中的含义相同,注意此处的h值是指前面元素的哈希值,即h=H(h−1;h′;η;digest;m),与水果挖矿中的h相同,并不包含水果集合F.F是指要被包含到区块中的有效水果集合.当哈希值h的前128 位小于区块挖矿难度DB时,表示节点成功挖到了区块,此时的随机数η便是工作量证明的解. 在FruitChains 中,交易是与水果绑定的,新挖到的水果被放入到有效水果集(fruit set)F中,有效水果集随着水果的挖出和使用不断更新,新挖到的区块负责将F中的水果放入到区块中,此时敌手如果针对底层区块采取自私挖矿或是扣块攻击,便毫无意义,因为包含交易的水果会被其他诚实节点产生的区块收录.因此FruitChains 防止了自私挖矿攻击,实现了公平性. FruitChains 重新设计了矿工的激励机制,将连续几个区块的奖励和其中包含的所有交易费平均分给找到工作量证明的节点.与此同时,FruitChains 为了解决目前比特币矿池算力集中化的问题,将水果挖矿难度降低,矿工能够以比特币1000 倍的频率获得回报,平均每2 天获得一次,因此在FruitChains 中,节点不再需要参与矿池就能频繁获得挖矿收益,降低了矿池带来的算力集中化. 图6 FruitChains 共识机制Figure 6 Consensus mechanism of FruitChains (5)GHOST GHOST 协议由Sompolinsky和Zohar[22]提出.GHOST 协议是一种主链选择算法,利用最重子树原则来代替最长链原则.在区块链出现分叉时,计算每个分叉所有子区块的个数,作为该分叉的“重量”,将重量最大的分叉作为主链.GHOST 协议设计的目的在于提高吞吐率时保证区块链的安全性.Kiayias和Panagiotakos[89]对GHOST 协议作出了形式化的安全分析,通过提出的“新鲜区块定理(fresh block lemma)” 证明了GHOST 协议能够满足一致性和活性两大安全特性. (6)Spectre 基于有向无环图(derected acyclic graph,DAG)的共识机制Spectre 由Sompolinsky、Lewenberg和Zohar[23]提出.不同于比特币中单一主链的方式,Spectre 采用并行区块,利用多条链跟随主链的形式,支链与主链的目标方向一致,且彼此之间不存在环路.DAG 采用的数据结构已经不是简单的链状结构,每个新加入的区块都会链接到之前的多个区块,将其哈希值包含在自身区块中,通过溯源可以到达创世区块,所有交易区块最终形成图状结构.历史交易数据不可篡改,一旦更改,则会引起整个DAG 区块图的变更.采用DAG 结构的区块链技术能够实现交易处理的可扩展性,随着网络中节点的增多,交易处理速度提高,交易吞吐率增加.采用DAG 结构的区块示意连接方式如图7所示. IOTA[55]、Byteball[90]]和Hashgraph[91]同样采用DAG 结构处理数据.Conflux[92]在DAG 结构的基础上,引入区块排序算法,将所有区块确定性排列为单链结构,不产生分叉,充分利用每个区块,将交易吞吐率提升到每秒钟数千次. 除此之外,关于区块链扩容问题的研究还有许多[93],如比特币链下支付[94–96]等,由于不属于共识机制的研究范围,本文不作讨论.相关工作可参考综述[97,98]. 采用工作量证明的共识机制主要面临以下几个问题: (1)巨大的能源消耗 工作量证明的寻找需要投入大量的算力,而算力的维持需要消耗巨额的电力.挖矿可能采用的CPU、GPU、FPGA和专用集成电路(ASIC)都需要连接至电网不间断运行,导致消耗的电量十分巨大.据统计[99],截止到2018年11 月11 日,仅仅比特币挖矿造成每年的电量消耗为73.12 TW·h,TW·h 是太千瓦时,与千瓦时之间的换算关系为:1 TW·h=109kW·h.相当于全球电力总消耗的0.33%,与整个澳大利亚消耗的电力持平.每年比特币挖矿消耗的电力大概相当于3656 073 069 美元.而其中每个交易需要消耗746 kW·h 的电量,可见造成的能源浪费十分严重. 图7 DAG 结构示例图Figure 7 Structure of block using DAG (2)存在安全隐患 任何共识机制都可能存在被敌手攻击的可能性,基于工作量证明的共识机制也不例外,主要面临以下几种攻击: 1)日蚀攻击(eclipse attack) Heilman 等人[100]分析了针对比特币的日蚀攻击.日蚀攻击属于网络层攻击的一种,在比特币网络中,每个节点有117 个信息输入连接(incoming connections)和8 个信息输出连接(outgoing connections),攻击者首先占据目标节点的网络地址,然后利用非比特币网络ID 地址来覆盖目标节点的连接地址,目标节点此时会实施网络重启,而重启后的信息输入连接很大概率都是处于敌手控制下的节点,此时目标节点所接收到的网络中的消息全是敌手控制之下的消息.Marcus、Heilman和Goldberg[101]分析了以太坊网络可能遭受的日蚀攻击,指出了以太坊点对点网络的脆弱性. 2)双花攻击(double spending) 双花攻击是指攻击者将已经花费过的代币重新花费.一般来说,攻击者可以通过制造区块链分叉的方法来实施双花攻击.攻击者首先通过代币完成一笔交易,假设交易被包含在区块链的区块B上,在交易完成后,攻击者通过分叉产生一条更长的新链,使得区块B作废,这样一来,区块B中的交易也作废,因此攻击者拿回了自己的代币. 攻击者还可以结合日蚀攻击来实施双花攻击.攻击者选定要交易的目标节点T,对其实施日蚀攻击,控制节点T的信息输入通道,攻击者将与节点T的交易放到自己生成的私链上,通过网络传播给节点T,这时节点T由于信息缺失,只能看到攻击者的区块链,因此相信交易的合法性,与攻击者完成交易.然而实际的区块链上并不存在这笔交易,因此攻击者成功实施双花攻击.双花攻击也是其他共识机制面临的主要安全威胁之一. 双花攻击一般针对具有弱一致性的区块链系统,矿工能够在同一个区块的不同分叉挖矿,当敌手算力超过50%时,敌手便能够发起双花攻击; 当敌手算力不足或接近50%时,敌手可以实施贿赂攻击(bribe attack)[102,103],通过一定的利益交换来获取其他敌手的算力,使自身的算力超过50%. 3)自私挖矿(selfish mining) 文献[104,105]针对比特币提出了自私挖矿攻击.自私挖矿是指敌手在挖到新区块后,暂时不公布自己的区块,而是在自己的区块之后继续私下挖矿,私下寻找自己的“私链”,当网络中其他节点挖到新区块时,敌手再选择性的释放自己私链中的区块,如果敌手此时私链的长度大于主链的长度,那么敌手的私链将被网络中大部分节点认可,敌手的私链成为了主链; 如果敌手此时私链长度等于主链长度,则敌手可以配合日蚀攻击控制网络中其他节点获取的消息内容,使其先收到自己发出的私链,获得其认可.在自私挖矿攻击中,敌手浪费了诚实用户的算力,造成了诚实用户链质量的下降. 其他对自私挖矿攻击策略拓展的攻击方式,还有顽固挖矿(stubborn mining)[106]、优化自私挖矿(optimal selfish mining)[107]、扣块(block withholding,BWH)[108]和扣块后分叉(fork after withholding,FAW)[109]等攻击.另外,攻击者能够将日蚀攻击、双花攻击、自私挖矿等攻击相结合,侵害诚实节点的利益.对于以上攻击方式的研究可以参考文献[110,111]. 为了解决工作量证明带来的巨大能源消耗问题,基于权益证明的共识机制被提出.权益是指节点或用户拥有的资产,如代币,根据用户拥有资产比例决定成为下一个区块生产者的概率,拥有资产比例越高,其成为生产者的概率就越大. (1)PPCoin PPCoin 由King和Nadal[24]提出,首次引入了权益证明的概念,其敌手模型为n=2f+1.PPCoin首先通过一定阶段的PoW 生成一定数量的代币,然后进入PoS 阶段.PPCoin 提出了“币龄” 的概念,节点拥有的币数量越多,拥有币的时间越长,其被选为出块者的概率越大.PPCoin 采用的币龄机制存在着被攻击的可能性,节点可能首先保持离线状态,在积累一定的币龄之后才参与共识网络,然后再次离线,这样PPCoin 中节点没有充分的激励保持在线状态. (2)Casper FFG Casper FFG[25]是以太坊PoS 共识机制,由Buterin和Griffith 提出.Casper FFG 的区块产生仍然依靠以太坊的Ethash 工作量证明算法,但是每隔50 个区块出现一个检查点,验证者(validator)通过PoS 的方式来对检查点完成最终确定. 想要成为验证者的成员首先需要将持有的以太币押注到Casper FFG 的智能合约中.在验证者选择过程中,节点被选中概率与押注的以太币数量成正比.被选中的验证者验证检查点,每个检查点需要经过预确认、最终确认两轮验证才能完成最终确认,每一轮中需要得到不少于2/3 验证者的合法投票.经过最终确认的检查点作为合法的当前状态,能够被新加入节点成功获取. Casper FFG 的押注机制主要为了解决PoS 共识可能面临的“无利害关系(nothing-at-stake)” 问题.如果节点试图实施无利害关系攻击,则节点的保证金将被没收.与此同时Casper FFG 对离线矿工采取了一定的惩罚机制,使得节点有充分的理由保持在线,维持以太坊网络的安全性. PPCoin和Casper FFG 都属于PoW 与PoS 结合的共识机制,类似的共识机制还有2-hop[56]和活动证明(proof of activity,PoA)[57]. (3)Ouroboros 系列 Ouroboros 由Kiayias 等人[26]提出,利用形式化的方法建立了PoS 共识机制的模型,并证明了Ouroboros 能够满足安全性.Ouroboros 在所有的持币者中,利用随机数随机选取每一轮的出块者,其敌手模型为n=2f+1,网络模型为同步网络. Ouroboros 将时间分为多个时期,每个时期包含多个轮,一轮中最多产生一个区块,而如果区块对应的出块者不在线时,该轮不产生任何区块.Ouroboros 假设每个时期内的权益分布是不变的,在时期e发生的权益改变将在之后的时期体现.与此同时,Ouroboros 要求在连续的几个时期内,权益分布情况的变化不能太大,即权益分布的统计距离应当有限.在每个时期的最开始,将有一个该时期的创世区块,记录在该时期所有合法的出块者候选人和本轮的随机数ξe.在每个时期,Ouroboros 利用以下函数选出时期e第j轮的出块者:Uj=F(Se,ξe,rj),其中Se是指时期e所有合法出块候选人组成的集合(U1,U2,··· ,Un),每个候选人持有的权益分别为(s1,s2,··· ,sn).rj代表第j轮,Uj代表第j轮的出块者,函数F(·)根据随机数从集合Se中随机选取出块者. 在Ouroboros 中,每一轮的随机数ξe由安全多方计算协议[112]产生,该协议使用公开可验证秘密分享算法[113],保证在敌手存在的情况下,能够产生抗偏置的随机数.Ouroboros 共识机制如图8所示. 图8 Ouroboros 共识机制流程图Figure 8 Consensus mechanism of Ouroboros 在Ouroboros 中,每一轮除了选出单一的出块者之外,还选出多个交易的验证者,被称为“背书节点(endorsers)”.背书节点验证交易的合法性,并将合法交易打包发送给出块者.Ouroboros 在设计激励机制时,充分考虑理性节点的存在,为了鼓励权益持有者保持在线,并执行交易验证和出块的工作,Ouroboros把多个区块的交易费放入到交易费池中,并根据参与节点的贡献度按比例分配给相应节点. David 等人[58]提出了Ouroboros Praos,改进了Ouroboros 中出块者的选举方式,其敌手模型为n=2f+1,网络模型为部分同步网络.Ouroboros 中出块者的选举结果是公开可验证的,所有节点都知道本轮的出块者的身份,而Ouroboros Praos 中,节点私下确定是否被选为出块者,节点之间不能提前判断其他节点是否被选中,直到出块者成功将区块生成,这样有效防止了敌手可能对出块者发起的贿赂攻击或DDoS 攻击.Ouroboros Praos 中,参与者通过可验证随机函数VRF 产生可验证随机数,如果其数值低于某个目标值,则可确定被选中为出块者.出块者在生成区块时,将其产生的随机数和由VRF 产生的对随机数的证明一起在全网广播,网络中其他节点可以确认其合法性.Ouroboros Praos 的激励制度跟Ouroboros 相同.Ganesh、Orlandi和Tschudi[114]改进了Ouroboros Praos,加入了隐私保护,并且提出了匿名可验证随机函数的概念. Badertscher 等人[59]提出了Ouroboros Genesis,详细设计了新节点加入网络时的自启(bootstrap)过程,解决了PoS 共识机制存在的长程攻击.Ouroboros Genesis 保留了Ouroboros Praos 中利用VRF随机选择出块者的部分,修改了最长链原则,新节点在加入网络时,需要从不同节点获得多个链,并将其对比,最终选定的区块链需要与其他链具有共同前缀且是最长链.Ouroboros Genesis 在没有采用检查点机制的前提下能够抵抗长程攻击,并且在通用可组合(universally composability)模型下,形式化证明了协议的安全性. Kerber 等人[115]提出了Ouroboros Crypsinous,首次提出了基于PoS 的隐私保护区块链,并且给出了形式化安全证明.Ouroboros Crypsinous 采用了UC 通用可组合安全证明框架,能够抵抗适应性攻击. (4)Snow White Snow White 由Daian、Pass和Shi[27]提出,其敌手模型为n=2f+1.Snow White 提出了适合PoS 的可重配置共识机制,重配置的间隔时间短暂,能够满足节点随机加入和退出网络的需求.每次重配置过程选出系统中最近的权益拥有者作为活动成员集合,然后按集合中成员权益占比随机选择出块者.Snow White 每个时期运行重配置的目的是,根据系统目前的权益分布来选择活动成员集合和出块者,即活动成员集合随着系统中权益的变化而重新选择,防止敌手的后来腐化(posterior corruption)攻击.Snow White 要求系统中权益分布变化不能过快,在此基础上达成了节点投票权与其持币数量成正比的目的. Snow White 采用的网络模型为睡眠模型(sleepy model)[116],即节点不会保持永久在线,可能在某段时间内在线,也可能在某段时间内离线,间断参与共识.该模型中节点的状态更加符合现实网络中节点的状态.Snow White 采用与FruitChains 类似的激励制度,并且同样采用区块和水果同时生成的挖矿机制,交易放在水果中,水果放在区块中,将连续几个区块的奖励和其中包含的交易费平均分给区块对应的出块者,实现了公平性. (5)DPoS 委托权益证明(delegated proof of stake,DPoS)[28]采用委托人的形式,权益持有者投票给信任的委托人,票数与其权益大小成比例关系,最终选出101 名委托人以平等的权利轮流作为区块生产者行使权利.如果委托人在委任期间未按规则产生正确区块,该委托人将会被除名,所有权益持有者选出新的超级节点将其替代.比特股(Bitshares)以DPoS 为原理实现.DPoS 以选举委托人的形式实现共识,带来了严重的中心化问题. 6.2 节简单介绍了基于权益证明的共识机制的典型方案,侧重于具体流程.下面介绍基于权益证明共识机制面临的主要攻击. (1)无利害关系攻击(nothing at stake attack) 无利害关系攻击[117]是指攻击者在过去链的不同分叉上挖矿试图获取更高利益.在PoS 共识机制中,制造区块链的分叉不像PoW 共识机制中需要花费一定的算力成本,攻击者不会对自身利益造成损失.如果没有预防机制,当区块链出现分叉时,节点为了增加自身获利的可能性,在区块链的每个分叉上都挖矿.无利害关系攻击可以通过在PoS 共识中引入相应的惩罚机制来预防,即对在不同分叉上产生区块的节点作出惩罚. (2)打磨攻击(grinding attack) 打磨攻击[118]是指在某些PoS 共识机制中,第r+1 轮的出块者选举受到第r轮出块者的影响,选举结果不随机,不能抗偏置.在这些PoS 共识机制中,第r+1 轮的出块者通常与第r轮生成的区块相关,这样一来,如果第r轮的出块者被敌手控制,敌手为了继续成为第r+1 轮的出块者,便在第r轮尝试不断生成新的区块,对生成的区块不断的“打磨”,直到最终生成的区块对自身有利.打磨攻击可以通过使用抗偏置随机数决定每一轮出块者的方式来防止. (3)长程攻击(long range attack) 长程攻击[119]主要是PoS 网络中的离线节点或新节点加入网络时,敌手伪造一条从创世区块到最新区块的区块链,试图让新加入节点相信其伪造的区块链.在PoW 为基础的区块链中,通常采用最长链原则或最重链原则来判断哪条区块链是真正合法的主链.假设主链为A,敌手想制造假的链B来让新加入的节点相信B为主链,在PoW 为基础的区块链中,新节点可以通过判断两条链中挖矿难度轻松判断A为主链,因为A中区块的挖矿难度一定非常明显的高于B,而敌手想要制造一条类似于A的主链,将花费相当庞大的算力,攻击成本将大大超过可能带来的收益.而在PoS 为基础的区块链中,想要仿造一条主链A则容易的多,敌手可以通过贿赂节点,使其出售过去使用过的重要私钥,不需要花费太多的成本便可以伪造出一条假链B,让新加入的节点认为链B才是真正的主链,从而达到其他不法目的.长程攻击可以通过检查点机制来防范. (4)权益窃取攻击(stake bleeding attack) Gaži、Kiayias和Russell[120]提出了针对PoS 共识机制的权益窃取攻击.权益窃取攻击主要在长程攻击成功后实施,对于未采用检查点机制的PoS 共识系统,敌手发动长程攻击后,使得新加入的节点相信敌手的链B为当前主链,则新节点产生的交易将会被提交到链B处理,链B中的节点完全由敌手控制,因此交易费全部归敌手所有. 混合共识机制的含义是将经典分布式共识机制与区块链共识机制相结合,即采用PoW 或PoS 的方式选举特定的委员会,在委员会内部运行经典分布式共识机制,生成区块.采用单一委员会的混合共识机制选举一个委员会负责全网所有交易的处理,而采用多委员会的混合共识机制选举多个并行运作的委员会,将全网划分为多个片区,分片处理网络中的交易.混合共识机制的一般过程如下: (1)选举委员会成员.委员会成员通过PoW 或PoS 的方式选举,用来防止女巫攻击.采用PoW 的选举方式需要设定一定的挖矿难度,保证每个时期找到PoW 的节点数目替换掉委员会内部分节点.采用PoS 的选举方式,需要在持币者中,根据持币者拥有币数量,随机选取一定数量节点作为委员会新成员. (2)选举委员会领导者.委员会内部共识的运行需要领导者发起,并且采取一定的机制防止领导者不作为或者发生恶意行为.委员会领导者可以通过随机数或投票的方式选择. (3)运行委员会内分布式一致性算法.委员会领导者在委员会内部对区块发起共识请求,一般可以运行类似PBFT 或其改进协议,实现委员会内部的拜占庭容错,达成分布式一致性共识,进而生成和维护区块链. (4)广播区块.委员会成员将生成的区块广播至全网,使得网络中非委员会的节点和客户端收到新产生的区块,更新交易和区块链. (5)重配置委员会.一个委员会工作的时间对应为一个时期,系统应当合理设置每个时期的时间长度,用来防止敌手腐化委员会成员.在一个时期过后,委员会开始重配置过程,按照一定的方式替换原本的委员会,然后新委员会接任下个时期的工作.委员会的更新方式一般有滑窗式、随机更新等方式,随机更新是指新找到PoW 或被PoS 选中的节点成为委员会新的成员,替换原委员会中的部分成员,进入新时期. 采用单一委员会的混合共识机制流程如图9所示. 图9 单一委员会混合共识Figure 9 Single-committee based hybrid consensus (1)PeerCensus PeerCensus 由Decker、Seidel和Wattenhofer[29]提出,首次将经典分布式一致性算法PBFT 与区块链结合,其敌手模型为n=4f+1.PeerCensus 利用比特币作为底层链,选出一定数量的节点,对其完成身份认证后通过链一致(chain agreement,CA)算法,来完成最终区块的生成,链一致算法通常采用PBFT 来实现.PeerCensus 允许加入新节点,新节点需要通过委员会的共识决定才能加入到委员会中.PeerCensus 的委员会管理存在一定问题,它采用离开检测机制来判断节点是否离开.正常节点通过发送ping 消息,如果未收到相应节点的回复,则判断其离线,然后正常节点发起对该离线节点的“ 离开” 提议,提议通过委员会共识后,委员会才完成重配置.这样一来,恶意用户能够通过不断制造离开提议的方式降低整个系统的运行效率. (2)ByzCoin ByzCoin 由Kokoris-Kogias 等人[30]提出.ByzCoin 同样是将PoW 与PBFT 相结合,ByzCoin 采用的敌手模型为n=4f+11在 ByzCoin 原文中,敌手模型为 n=3f +1,后来hybrid consensus [32]指出由于自私挖矿导致链质量下降,ByzCoin敌手模型应为n=4f +1..其共识流程如下: ①委员会成员选举.ByzCoin 采用工作量证明的方式选取委员会.它借鉴了Bitcoin-NG 的思想,将区块分为关键块和微块,关键块决定委员会成员和领导者,找到最近 144 个关键块(相当于一天)或 1008个关键块(相当于一周)的节点进入委员会.节点的投票权由其产生的关键块的比例决定. ②委员会内分布式一致性算法.委员会成员采用改进的PBFT 算法完成共识,每两个节点之间利用MAC 实现通信,在每一轮共识的每一个阶段,节点需要利用跟每个节点对应的私钥,向每个节点广播消息.而ByzCoin 利用群体签名(collective signing,CoSi)[121]来替换MAC,采用默克尔树的形式对每个消息的节点签名排列2Cosi 签名方案的安全性并没有得到证明[122]..每一轮对微块达成共识,微块中包括当前时间内发生的交易. ③委员会重配置.ByzCoin 的委员会重配置采用“滑窗” 的形式,即新找到关键块的节点进入委员会,并成为当前委员会的领导者,将委员会中“最久远” 的区块的出块者踢出委员会. 在144 个委员会成员且区块大小为32 MB 的情况下,ByzCoin 能够达到的交易吞吐率为974 tps. (3)Solida Solida 混合共识机制由 Abraham 等人[31]提出.Solida 主要解决了委员会重配置时可能出现的问题.首先,Solida 的领导者选举方式借鉴了 Paxos 的思想,为每个领导者赋予不同的等级(c,e,v),其中c代表委员会序号,当新节点通过委员会重配置加入到新委员会中后,(c,e,v)变为(c+1,0,0),新加入的节点成为委员会领导者.e代表一个 PoW 对应的生存时期,如果有节点新找到 PoW,则(c,e,v)变为(c,e+ 1,0),新找到 PoW 的节点成为领导者.v的含义是视图,当现任领导者停滞不前,利用函数L(c,e,v)=H(c,e)+vmodn(其中n代表委员会成员个数)在委员会内部选出新的领导者,(c,e,v)变为(c,e,v+1). Solida 共识机制的流程如下: ①委员会内分布式一致性算法.Solida 改进了PBFT 算法,删除了预准备阶段,增加了公示阶段,包括(a).提议(propose).领导者将交易打包并广播 tx和(propose,c,e,v,s,h),其中h是交易的哈希值.(b).准备(prepare).收到上述信息的成员检查交易和领导者身份的合法性,验证通过后广播消息(prepare,c,e,v,s,h).如果委员会成员收到超过2f+1 个对h的准备消息,那么该成员接受(accept)提议h,并将该 2f+1 个准备消息组成接受证明(accept certificate)A.(c).承诺(commit).如果成员接受了h,那么广播消息(commit,c,e,v,s,h),同样,如果其收到超过 2f+1 个合法的承诺消息,则认为h被最终确认,并将 2f+1 个合法承诺消息组成承诺凭证(commit certificate)C.(d).公示(notify).节点完成对h的承诺之后,在全网广播公示消息((notify,c,e,v,s,h),C),收到该消息的用户验证其合法性,通过后完成交易的确认. ②重配置.(a).新时期(new-lifespan).节点获取当前PoW 的难题,为了防止自私挖矿,Solida 将难题设置为任取f+1 个合法公示消息(notify,c,e,v,s,h).找到PoW 的节点将其广播给委员会成员.委员会成员确认PoW 的合法性,并进入(c,e+1,0),将发现PoW 的节点视为新的领导L′=(c,e+1,0).(b).状态上传(status).节点进入新时期后,向新领导发送当前状态信息((status,c,e,0,s−1,h,s,h′),C,A),其中h是已承诺交易的哈希值,C为对应的承诺凭证,h′为已接受交易的哈希值,A为对应的接受凭证.新领导者收到超过 2f+1 个 status 消息,将其组成状态凭证(status certificate)S.(c).重提议(re-propose).新领导者将最高的h视为已承诺值,将排名最高的已接受值h′重新提议,经过接受、承诺和公示步骤后,完成对h′的承诺,并开始新的委员会内分布式一致性算法.Solida 重配置的过程如图10所示. 在Solida 中,重配置时采用新找到PoW 的矿工作为下个时期的领导者,此时的新领导者能够打断当前委员会领导者,经过委员会内部共识后,新领导者正式接管委员会,新领导者必须将之前被打断的提议重新发起共识.Solida 的敌手模型为n=3f+1,为了防止自私挖矿带来链质量的下降,Solida 在PoW中嵌入了新鲜的随机数,将每一轮提议最终得到的f+1 个签名嵌入到PoW 中,保证诚实用户的链质量,从而保证委员会中有超过2/3 的诚实用户. 图10 Solida 重配置流程图Figure 10 Reconfiguration process of Solida (4)Hybrid consensus 混合共识hybrid consensus 由Pass和Shi[32]提出.Hybrid consensus 将经典共识机制与非授权共识机制结合,利用工作量证明,提出混合共识机制,实现非授权环境中的状态机复制.Pass和Shi 提出了交易的快速响应特性(responsivenss),是指交易的确认时间与网络真实时延有关,而与网络时延上限无关.Hybrid consensus 成功实现了交易的快速响应特性. 在hybrid consensus 中,Pass和Shi 指出了ByzCoin 存在的问题,ByzCoin 原本采用的敌手模型为n=3f+1,而由于自私挖矿攻击导致诚实节点维护的关键块链质量下降,只有当敌手所占比例不超过1/4时,诚实节点产生的关键块比例才能够超过2/3,委员会内诚实用户的数量占比才能得到确保. Hybrid consensus 首次利用形式化的安全模型和模块化的设计建模混合共识机制,并证明了其能够满足一致性和活性等安全特性. (5)Thunderella Thunderella 由Pass和Shi[33]提出,敌手模型为n=4f+1/n=2f+1.Thunderella 的核心思想是在类似于比特币的底层链之上,组成委员会,实现交易快速响应.Thunderella 共识机制流程如图11所示. 图11 Thunderella 共识机制流程图Figure 11 Consensus mechanism of Thunderella Thunderella 共识机制的流程如下: ①委员会选举.Thunderella 提供了两种非授权网络中委员会选举的方式:第一种是利用PoW,通过底层链将最新找到PoW 的节点作为委员会成员,并按顺序依次替换老节点.为了实现公平性和防止自私挖矿攻击,Thunderella 采用FruitChains 作为底层链; 第二种是利用PoS,随机选取一定数量的权益持有者作为委员会成员. ②乐观期(optimistic fast path period).需满足条件:(a).领导者诚实;(b).委员会中诚实节点数量超过3/4.设委员会成员数量共n个,乐观期交易确认过程如下:(a).客户端提交交易txi至委员会领导者;(b).领导者赋予交易序列号i,并将(i,txi)广播给其他委员会成员;(c).委员会成员验证交易txi,通过验证则对其签名并广播;(d).网络中任意节点收集对交易txi的签名,如果有效签名数量超过3n/4 个,则认为交易txi被最终确认. 连续的被确认交易组成交易的“幸运序列(lucky sequence)”,如tx1,tx2,tx3,tx5完成了确认,则组成的交易幸运序列为:((1,tx1),(2,tx2),(3,tx3)),其中并不包括tx4和tx5. ③宽限期(grace period).宽限期是乐观期向底层区块链确认期的过渡,当未满足乐观期条件时,进入宽限期.宽限期具体的识别标准如下:如果节点发现其提交的交易txi长时间未被确认,则将其发送到区块链上.若经过k个区块(k为安全参数,图中假设k=2)之后,交易txi仍然未被添加到幸运序列,则进入宽限期. 宽限期包括k个区块,宽限期未结束时,节点输出其认同的最长交易幸运序列; 宽限期结束后,节点输出所有已确认和未确认交易,进入底层区块链确认期. ④底层区块链确认期(foundation Blockchain period).底层区块链确认期采用底层链共识机制,Thunderella 利用FruitChains 作为底层链,实现公平性,抵抗自私挖矿攻击.在该时期,Thunderella能够随时重新进入乐观期,快速确认交易. Thunderella 乐观期需要有超过3/4 的委员会成员投票,原因同样是对于两个不同的交易,如果其投票数量都满足条件,则其中必然有超过1/2 的委员会成员对两个交易都投票,而Thunderella 假设恶意节点不超过总节点个数的1/2,因此与假设矛盾.Thunderella 底层链采用FruitChains 能够保证恶意节点算力不超过全网算力1/2 的条件下,恶意节点产生的区块数量不超过区块总数量的1/2,因此保证了委员会中恶意成员数量不超过1/2.Thunderella 同样用形式化的方法证明了协议满足一致性和活性. (6)Algorand Algorand 由Gilad 等人[34]提出.Algorand 是将PoS 与经典分布式一致性算法结合的混合共识机制,其敌手模型为n=3f+1,网络模型为同步网络. 在Algorand 中,区块结构如下:Br=(r,PAYr,SIGℓr(Qr−1),H(Br−1)).其中r是指区块的序列号,即当前的轮数,PAYr是指当前时间内发生的交集集合,Qr−1是指上一轮产生的随机种子,H(Br−1)是指上一个区块的哈希值,ℓr是指当前轮的领导者,SIGℓr(Qr−1)是指ℓr利用自身私钥对Qr−1计算的数字签名. Algorand 算法的流程如下: ①随机数计算.在每一轮r中,节点获取上个区块的信息,计算本轮随机数,即上个区块为Br−1=(r−1,PAYr−1,SIGℓr−1(Qr−2),H(Br−2)).然后通过函数计算得到Qr−1=H(SIGℓr−1(Qr−2),r−1). ②判断是否被选中为本轮领导者/参与者.节点i私下判断其是否被选中为本轮的领导者和本轮的委员会成员.若满足则其被选中为本轮领导者; 若满足pc,则其被选中为本轮委员会成员,此处pℓ和pc对应不同的难度系数. ③委员会内分布式一致性算法.当前轮被选中的节点运行委员会内分布式一致性算法.Algorand 提出了新的拜占庭一致算法BA,BA包括分级共识(graded consensus,GC)和二元拜占庭一致(binary Byzantine agreement,BBA)算法,在分级共识中,Algorand 将对整个区块哈希值的共识转化为对二元数值的共识,并将二元数值放入到BBA 中,通过BBA 对二元数值达成一致从而确认本轮区块. Algorand 的敌手模型为适应性敌手.如果委员会内分布式一致性算法采用类似于PBFT 的协议,委员会成员在一个提议过程中,需要至少三轮的投票,而敌手可以在成员第一轮投票之后辨认出委员会成员,并对其实施腐化,从而控制整个委员会.Algorand 采用了GC和BBA 结合的方式,每一轮投票采用全新选择的委员会,经过一轮投票之后,虽然委员会身份暴露在敌手之下,但是其已经失去了被腐化的意义,因为实施下一轮投票的成员是利用PoS 重新选择的节点.PoS 在所有权益持有者中随机选择一定数量的委员会成员,相比于PoW,PoS 选择成员的方式更加快速、高效,因此可以被Algorand 用于委员会的快速更新.Algorand 实现了仿真,当50 k 个用户时,交易吞吐量大约为比特币的125 倍. 混合共识机制将经典分布式一致性算法与非授权共识相结合,具有强一致性特性,区块链分叉概率很小,交易能够得到较快速度的确认.但是,混合共识机制引入了一些新的问题. 第一,协议启动问题.在协议运行的初始阶段,如何安全的初始化,创建创世区块; 如何不依赖可信启动来对协议运行初始化配置[123,124],如利用安全多方计算等算法等; 第二,委员会重配置问题.委员会重配置期间,如何确保新的委员会成员中诚实用户达到相应比例; 如何确保新旧委员会成员交替时,交易能够持续处理; 如何确保敌手不能影响新节点加入委员会等; 第三,新节点加入问题.在新节点加入网络时,如何实现快速自启[125,126],避免下载海量的交易历史和状态等信息; 如何确保新节点加入时获得的交易状态信息真实有效,识别敌手产生的虚假信息等; 第四,委员会内分布式一致性算法问题.在委员会内运行分布式一致性算法期间,如何确保客户端提交的交易能够被快速响应; 如何提高委员会内分布式一致性算法的运行效率,降低委员会成员间的通信复杂度和计算复杂度; 如何实现区块的并行提议等. 为了解决区块链处理交易的可扩展性,利用多个并行的委员会来处理网络中不同分片的交易的混合共识机制被提出,也被称为分片共识(sharding consensus)机制. 目前分片有以下几种含义: (1)通信分片(communication sharding) 通信分片是指将全网分为不同的片区,每个片区由一个对应的委员会处理,每个委员会内部成员大部分时间只需内部通信,每个片区内部的其他客户端、节点大部分时间可以通过与该分片内委员会通信获得目前区块链的状态. (2)计算分片(computation sharding) 计算分片是指每个分片委员会只负责处理其对应的交易,如根据交易的ID 判断其对应的分片,交易ID 最末位数字如果是i,则由i号分片委员会处理该交易,对交易运行委员会内分布式一致性算法,验证该交易的合法性,决定该交易是否被添加到区块链中. 计算分片使不同的交易以并行的形式被不同的委员会处理,当网络中节点数量增多时,可以增加更多的委员会,这样不同的交易能够以并行的形式被不同的委员会同时处理,交易处理性能随着网络中节点数量的增多而增加,进而实现了交易处理的可扩展性. (3)存储分片(storage sharding) 存储分片是指不同分片委员会将处理后的交易分片存储,每个分片委员会只负责处理本分片对应的交易,将交易放到本分片专属的交易区块链上.交易区块链用于存储本分片产生的交易历史或当前分片的未花费交易池信息.存储分片将整个区块链系统的交易数据或未花费的交易输出(unspent transaction output,UTXO)数据分片存储,降低了节点的存储负担. 多委员会混合共识机制流程如图12所示,其包括选举委员会成员、委员会成员分配、选举委员会领导者、运行委员会内分布式一致性算法、广播区块和重配置委员会等步骤.以上步骤与单一委员会混合共识机制相类似,但是存在三个关键区别.第一,增添了委员会成员分配步骤,在选举委员会成员后,需要将新选举的委员会成员分配到不同委员会中,为了防止敌手在此过程中影响成员分配,需要设置合理的分配策略.第二,在运行委员会内分布式一致性算法步骤中,需要考虑到跨片交易的处理,即当一个交易包含多个输入且其属于不同分片时,需要多个分片协作完成对该交易的处理,防止交易双花攻击.第三,在广播区块的步骤中,如果采用存储分片,那么可能每个分片各自生成和广播其区块链,不存在全局的区块链. (1)ELASTICO 分片共识机制由Luu 等人[35]提出.ELASTICO 假设网络模型为同步网络,敌手模型为n=4f+1,以保证委员会中诚实节点数目达到2/3 以上.ELASTICO 将参与共识的n个节点分为k组,在一轮中,每一组输出一个区块协议输出一个总区块Br.其中r代表当前轮数,i代表委员会的序号.ELASTICO的流程如下: 图12 多委员会混合共识Figure 12 Multi-committee based hybrid consensus ①节点身份建立.想要参与共识的节点产生公钥PK和其IP 地址ip,节点利用上个时期产生的随机数ξr−1,寻找工作量证明其中nonce 是指节点选中的随机数,γ表示哈希函数的输出一共有γ位,D表示挖矿难度,如D=10 表示w至少前10 位必须为0.满足条件的nonce 即为工作量证明的解.找到满足条件w的节点在全网广播w. ②节点分片确认.ELASTICO 的委员会包括一个目录委员会和多个普通委员会,每个委员会包括c个成员.前c个找到工作量证明的节点广播w,进入目录委员会,为后续节点提供委员会分配和委员会成员身份列表服务.目录委员会人满之后,后找到工作量证明的节点将工作量证明发送给目录委员会成员,根据w的后s位进入相应委员会.当所有委员会成员到达c之后,目录委员会将每个委员会成员列表发送给对应委员会成员.每个普通委员会的成员只需跟本委员会内部成员通信. ③委员会内部共识.每个委员会内部运行PBFT 算法,就本轮自身委员会内部交易集合达成共识,并将和对其确认签名发送至最终委员会. ④广播确认区块.最终委员会收集普通委员会本轮的区块,每个成员验证区块的有效性,验证通过后,组成本轮的总区块Br,其中交易是所有之前收到的有效交易集的并集.然后,最终委员会内运行PBFT对Br达成共识,并在全网广播Br. ⑤随机数生成.最终委员会运行随机数生成协议,每个成员首先选择随机数Ri,并将其哈希值H(Ri)在委员会内广播,最终委员会运行PBFT 确认所有哈希值H(Ri)构成的列表S,并在全网广播S.最终委员会成员在全网公布自己选取的随机数Ri,网络中任意用户获得其中c/2+1 个随机数Ri,并将其异或,便可得到本时期随机数ξr,用于下个时期寻找PoW.每个用户接收到的随机数可能不一样,因此规定任意c/2+1 个有效的随机数Ri计算得到的ξr都是合法的.当用户在下个时期找到PoW 的解并上传时,需要将c/2+1 个有效的随机数Ri同时上传,以便验证其使用的ξr的合法性. (2)Omniledger Omniledger 由Kokoris-Kogias 等人[36]提出,其敌手模型为n=4f+1.它解决了ELASTICO 分片共识中存在的一些问题,如当恶意节点占比超过1/4时,协议运行失败率高; 节点在寻找工作量证明时,若通过工作量证明的后几位决定进入对应的委员会,抗偏置性较差,找到多个工作量证明的节点可以选择进入的分片; 跨片交易可能锁死,导致系统不能正常工作等. Omniledger 采用UTXO 模型,网络中不同分片的节点只需处理和存储该分片对应的UTXO 数据.与此同时,Omniledger 提出了跨片交易防锁死解决方案.在Omniledger 中,有两种区块链,身份区块链和交易区块链,身份区块链用于记录协议每个时期参与的节点和其对应的分片信息,每个时期更新一次,而一个时期能够产生多个交易区块,每个分片负责产生和维护自己分片的交易区块链.Omniledger 协议的具体过程如下: ①节点身份确认.与ELASTICO 类似,节点想要参加时期e的共识,就必须在时期e−1 寻找工作量证明,找到工作量证明的节点将身份信息和相应的工作量证明广播,在e−1时期完成注册.时期e−1的领导者收集所有合法注册者信息,运行委员会内分布式一致性算法,将合法注册者信息写入身份区块链. ②委员会领导者选举.在时期e开始时,通过密码抽签的方式选举领导者,每个节点计算票据ticketi;e;v=VRFski(‘‘leader”|confige|v),其中VRFski(·)代表可验证随机函数,leader 为VRF 的附加输入,表示此次计算的目的是选择领导者,confige代表时期e的合法参与者,v代表当前视图编号,i代表节点序号.在一定的时间∆内,用户交换票据信息,选出数值最小的ticketi;e;v,将其对应的节点作为领导者.然后领导者启动随机数生成算法RandHound[127],如果在时间∆内,RandHound 仍未被启动,则视本轮领导者选举失败,令v=v+1,开始新一轮的领导者选举,直到RandHound 成功运行为止. ③随机数生成.领导者启动RandHound 算法,生成本轮随机数ξr.领导者在全网广播随机数ξr和其证明.节点收到信息后验证随机数ξr是否正确生成,若生成正确,则将其作为种子运行伪随机数生成器进而生成随机数,产生随机置换,并根据随机置换确认本轮所在的分片. ④委员会内分布式一致性算法.每个委员会内部按照ByzCoin 的方式处理分片内部交易. ⑤委员会成员重配置.为了持续处理交易,Omniledger 设置合理挖矿难度,使得每次重配置,每个委员会只将部分节点替换,替换节点数量不超过总人数的1/3.在节点替换过程中,利用本轮随机数决定现任委员会中被替换的节点. 由于交易的分片存储,当交易存在多个输入且属于不同分片时,需要多个分片协作完成对交易的处理.Omniledger 提出跨片交易解决方案,利用原子性跨片交易防止跨片交易锁死,主要流程如下: ①初始化.客户端上传交易,交易的输入分片可能存在多个,假设为IS1和IS2,输出分片假设为OS. ②锁定.每个分片的领导者验证交易输入是否属于当前分片的UTXO,如果验证通过,则提供交易的接受证明(proof of acceptance,PoA),即交易输入在本分片UTXO 中的默克尔树路径,并将该交易输入设置为锁定状态,后续其他想要花费该交易输入的交易将被拒绝.如果验证未通过,则提供交易的拒绝证明(proof of rejection,PoR). ③解锁.解锁分为以下两种情况:第一种是解锁至提交状态,如果所有输入分片领导者都提供PoA,那么交易可以被提交,客户端提交交易及其所有输入的PoA.输出分片OS 收到交易后,验证所有交易的合法性,验证通过后将该交易加入到输出分片的下个区块.第二种是解锁至取消状态,如果有一个输入分片领导者提供了PoR,那么客户端创建“取消交易”,包含该交易对应的PoR.所有输入分片领导者收到“取消交易” 后,将原交易的输入解锁至可用状态. Omniledger 解决了ELASTICO 存在的许多问题,在分片数量为16 个且每个分片人数为70 人时,能够达到5000 tps 的交易吞吐率,且交易吞吐率随网络中节点增多而增加.文献[128]对Omniledger 使用的随机数生成算法改进,采用公开可验证秘密分享,确保了随机数的不可预测性、抗偏置性和公开可验证性,并且保证了随机数的持续生成. (3)Chainspace Chainspace 由Al-Bassam 等人[37]提出,其敌手模型为n=3f+1.Chainspace 在分片的基础上,构建了智能合约应用平台.任何人能够发布智能合约,智能合约的参与者可以是多个用户.Chainspace中存在系统智能合约CSCoin,为整个协议的运行设定一定的安全参数.Chainspace 将智能合约的执行和验证步骤分离开来,并且提出了跨片交易处理的原子承诺协议(sharded Byzantine atomic commit,SBAC).Chainspace 将智能合约和交易称为“对象(objects)”,每个对象由不同的分片分别执行、处理和验证.S-BAC 的实质是BFT和原子承诺(atomic commit)的结合.Chainspace 中对交易或智能合约的处理过程如图13所示. 图13 Chainspace 共识流程图Figure 13 Consensus mechanism of Chainspace ①准备(prepare).用户向输入分片发送准备消息prepare(tx),假设交易tx 有两个输入和一个输出,其对应的分片分别为分片1、分片2和分片3. ②处理准备消息(process prepare).输入分片1和分片2 的节点收到prepare(tx)消息后,锁定交易tx 的输入,在各自的委员会内部通过运行拜占庭算法处理准备消息,如果交易tx 合法,即输入未被花费且没有其他的交易使用该输入,输入分片向其他节点广播承诺消息prepared(tx,commit).如果交易tx 不合法,未通过拜占庭算法,则广播消息prepared(tx,abort). ③处理准备完成的消息(process prepared).所有分片之间进行交互,如果所有分片在上一步广播的都是prepared(tx,commit)消息,则对交易tx 达成最终共识,广播accept(tx,commit)消息.如果分片中有大于等于一个分片提交了prepared(tx,abort)消息,则对交易tx 的共识失败,广播accept(tx,abort)消息. ④处理接受消息(process accept).当上一步中有分片广播accept(tx,commit)时,交易tx 的输出分片运行委员会内分布式一致性算法,将tx 添加到该分片中.当分片广播accept(tx,abort)时,所有分片将交易tx 的输入解锁,放弃交易tx. Chainspace 实现了交易和智能合约的通信分片和计算分片.在15 个委员会,每个委员会4 个节点的情况下,其交易吞吐量为350 tps. (4)RapidChain RapidChain 由Zamani、Movahedi和Raykova[38]提出.RapidChain 实现了计算分片、通信分片和存储分片,主要模块包括启动(bootstrap)、共识和重配置.RapidChain 敌手模型为n=3f+1,网络模型为部分同步网络.协议的具体流程如下: ①启动.启动阶段是指生成创世区块和初始委员会的阶段.在之前的区块链中,如比特币等,采用可信启动来实现.RapidChain 无需可信启动,首先在所有参与节点中,利用随机图(random graph)选举出根群组(root group),然后利用根群组运行分布式随机数生成协议,生成参考委员会.参考委员会负责生成其他k个普通委员会.在RapidChain 中,启动阶段只需运行一次,不需要任何可信第三方和可信启动的存在,便能够完成协议的初始化. ②时期内共识.协议分时期运行,每个时期分为多个轮,每一轮中,委员会中运行Ren 等人[129]提出的实用同步拜占庭容错协议,敌手模型为n=2f+1,此阶段假设网络模型为同步模型. ③重配置.时期之间需要运行委员会重配置,节点通过寻找PoW 加入委员会,为了抵抗自私挖矿攻击,在PoW 中嵌入每一轮产生的随机数.重配置采用了有界布谷鸟规则(bounded Cuckoo rule),即新节点尽量替换掉原本委员会中不活跃的节点. RapidChain 在网络层中,采用消息扩散算法(information dispersal algorithms,IDA)代替传统区块链网络采用的八卦通信协议(gossip protocol).发送者利用纠错编码,将区块拆分为小区块后传播,接收者接收到一定数量的小区块后可以恢复原始区块.采用IDA 传播方式能够将区块传播速度提升约5.3 倍. RapidChain 对于跨片交易的处理如下:用户将交易 tx 发送至网络中任意节点,收到 tx 的节点将其发送至 tx 对应的输出委员会Cout.Cout将交易 tx 拆分,假设交易 tx 包括 2 个输入I1和I2,及 1 个输出O,则将交易tx 拆分为3 个新交易:并且令和属于Cout.Cout成员根据交易和输入判断所属委员会Cin,将对应交易发送至Cin.Cin验证和的合法性,通过后将对应的tx1或tx2添加到其区块,最后Cout将tx3收入自身区块. 由于时期内共识采用同步网络模型,交易确认时延与网络真实时延无关,导致交易确认不能满足快速响应特性.但 RapidChain 协议其他部分采用部分同步网络模型,均能满足快速响应特性.RapidChain采用一定措施,使得其时期内共识也能够接近快速响应特性. (5)其他分片共识机制 Manuskin、Mirkin和Eyal[130]提出了Ostraka.Ostraka 采用了节点差异化环境模型,即认为每个节点处理交易的能力是不同的.在Ostraka 中,每个节点处理所有的交易.Ostraka 能够抵抗拒绝服务攻击,交易处理能力随网络规模的扩大而线性增加.Dang 等人[131]采用数据库分片的方式来实现区块链的可扩展性,并利用可信硬件Intel SGX 产生的可信随机数将节点分配到不同分片中,确保了整个协议的活性和安全性. 分片共识在实现交易处理可扩展性的同时,引入了一些新的问题,主要包括如下几点. 第一,跨片交易处理.包含多个输入的交易,由于其输入大概率分布在不同的分片中,因此需要多个分片共同协作安全和高效地处理交易.在处理过程中,需要防止双花攻击、重放攻击[132]和交易锁死,并且采用一定的方式提升交易的处理速度; 第二,委员会人数动态管理.分片共识中,不同分片对应的委员会人数可能存在一定的差异,当两个委员会之间交流过于频繁时,可以考虑将其合并为一个委员会,提高交易处理速度等; 第三,恶意委员会检测与恢复.如果新加入成员分配到不同委员会的过程受到敌手的偏置,则可能造成某些委员会中恶意成员个数超过限制,敌手可能进一步控制委员会.如何检测恶意委员会并建立恢复机制是未来需要研究的重要问题. (1)能力证明机制(proof of capacity) 能力证明是指根据参与者能够使用的硬盘空间大小作为标准,选出区块的生产者.Miller 等人[133]提出了 Permacoin,要求参与者有能力存储大文件的一部分.Park 等人[60]提出了 Spacecoin,采用非交互式空间证明(proof of space)达成共识. (2)消逝时间证明(proof of elapsed time) 消逝时间证明是基于硬件芯片执行某个命令的等待时间来实现的,其实质是利用可信硬件产生随机数来决定下一个区块生产者.Hyperledger 使用英特尔可信芯片 Intel SGX 中的 “飞地” 模块,参与者在发布块之前都需要向飞地获取一个随机的等待时间,等待时间最短的节点被选为领导节点.Zhang 等人[134]提出了资源高效利用挖矿(resource-efficient mining,REM),同样采用可信硬件来计算PoW,用时最短节点将被选为领导节点. (3)融入知识证明的工作量证明(entangled proof of work and knowledge,EWoK) Armknecht 等人[61]提出了 EWoK,主要将 PoW 与 PoK 结合,鼓励节点对于区块链系统历史数据的存储.节点先通过工作量证明找到 PoW 的解,然后证明节点本地存储了区块链某个分片的完整数据,完成证明的节点成为出块者,EWoK 通过鼓励节点存储数据来增强系统的安全性. 区块链共识机制是区块链技术的核心,未来的发展趋势主要有以下几点: 第一,安全层面.设计并完善可证明安全的区块链共识机制,如基于PoS 的共识机制,解决PoS 共识机制面临的安全威胁; 将经典分布式一致性算法与区块链技术结合,利用委员会实现强一致性,解决委员会重配置的安全问题; 第二,扩容层面.利用分片技术,通过计算分片、通信分片和存储分片,实现交易处理的可扩展性,解决跨片交易问题; 利用DAG 技术,采用并行区块的架构,使得同一时间内区块链能够容纳更多的交易; 第三,启动层面.通过安全多方计算等密码技术在非可信环境下完成协议自启动,解决区块链协议的初始化问题; 通过对区块链历史数据的合理裁剪,使新加入节点能够快速获取当前区块链状态,参与共识运行,解决新加入节点的启动问题; 第四,激励层面.设计合理可行的奖励和惩罚机制,以理性用户作为出发点,激励用户以诚实行为参与共识机制的运行和维护; 合理惩罚恶意用户,同时给予举报者一定的奖励.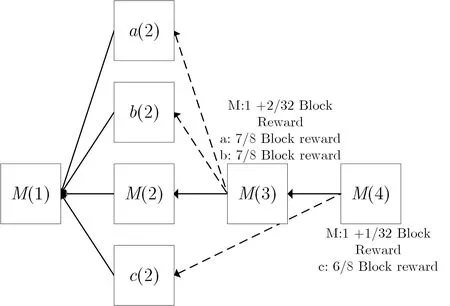

5.3 综合分析
6 基于权益证明的共识机制
6.1 概念
6.2 典型方案分析
6.3 综合分析
7 采用单一委员会的混合共识机制
7.1 概念
7.2 典型方案分析

7.3 综合分析
8 采用多委员会的混合共识机制
8.1 概念
8.2 典型方案分析
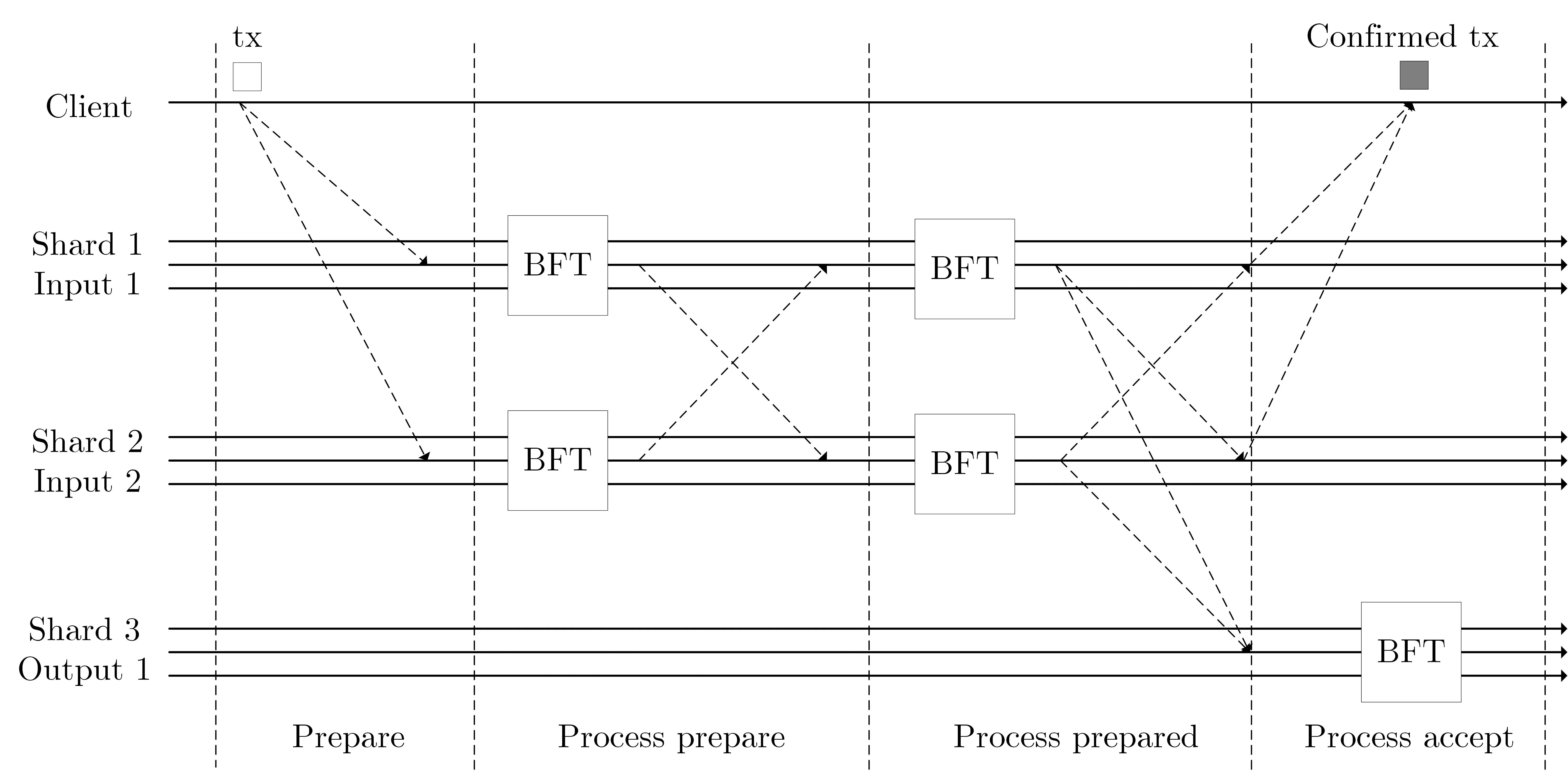
8.3 综合分析
9 其他共识机制
10 未来研究方向
