长江上游流域暴雨洪水相似性判别指标研究
2019-09-10陈建李春红王峰王建平
陈建 李春红 王峰 王建平


摘要:暴雨洪水发生演化的各个阶段之间存在一定的关联性和规律性。以长江上游流域为研究对象,将暴雨洪水指标分为降雨、洪水、时间、雨洪关系、水库、形状和初始指标7大类,共67个指标。通过整理暴雨历史洪水资料,摘录暴雨洪水过程和计算暴雨洪水特征值,结合洪量相似度、洪峰相似度、形状相似度和灰色关联度4种相似性评价方法,优选出降水量、降水历时、起涨流量和洪水涨率4个指标作为相似洪水判别指标。以113场三峡入库洪水为样本进行相似性检验,基于几场典型洪水特征值寻找的历史相似洪水之间的相似度较高,确定性系数都达到了0.9以上。结果表明,降水量、降水历时、起涨流量和洪水涨率4个指标作为相似洪水判别指标,对指导实时洪水预报具有较高的参考价值。研究成果在三峡水库以上长江上游流域进行了试验应用,在寻找历史相似洪水方面具有较好的效果。
关 键 词:暴雨洪水相似性; 相似洪水判别指标; 相似性分析; 长江上游流域
中图法分类号: P33 文献标志码: ADOI:10.16232/j.cnki.1001-4179.2019.01.011
1 研究背景
一场暴雨洪水的形成是一个逐步演化的过程,包括前期大气环流背景条件、特定的天气系统配置、雨区分布与移动、产汇流过程、水库调蓄和洪水演进等诸多阶段。每个阶段都具有其自身的变化规律,阶段之间也存在相互的关联性。暴雨洪水演变过程中的这些规律,往往是以相似性的特征在历史场次雨洪资料中重复出现,而这种相似性对未来实际发生的雨洪过程的预测及防洪决策具有十分重要的借鉴价值。一方面由于暴雨洪水过程的形成具有其内在的联系性,另一方面经过多年的水文观测与资料整理,积累了大量的一手水雨情历史资料,通过数据相似性分析手段对历史暴雨洪水进行分级归类,找出历史上洪水过程相似的洪水,进一步从相似的洪水过程中发掘出洪水形成的共同关键因素。
长江上游流域面积大、洪水形成比较复杂,有不少学者针对长江上游流域的洪水组成[1]、洪水分类[2-3]、洪水遭遇等进行了分析研究[4-5]。国内外学者在水文相似性分析方面也做了大量的工作,有的以相似性算法为基础开展了研究工作,比如DTW算法[6]、水文模型参数法[7-9]、主成分分析法[10]、聚类分析法等[11];有的从流域暴雨洪水物理成因分析出发对洪水相似性进行了总结分析[12-13];有的以地形地貌因子为基础分析洪水产生的规律[14]。王继民等采用多种相似度量算法进行组合得到的一种多度量相似度BORDA算法,对淮河流域王家坝水闸洪水过程相似性进行了验证分析[15]。张艳平等采用相关系数法和加权距离系数法对大伙房水库的暴雨洪水进行了分类研究,用于指导大伙房水库汛限水位动态控制应用[16]。沈强等在EBSM方法的基础上提出了嵌入式索引的相似性搜索模型,能够比较快速地找出与基准序列最相似的时间序列[17]。汪丽娜等采用投影寻踪和人工鱼群算法对宜昌站历史洪水进行分类分析[18]。
图1 长江上游流域水文站点和水库分布 Fig.1 Distribution of hydrological stations and reservoirs in upper Yangtze River
目前关于采用相似历史洪水指导实时洪水预报还较少。本文在前人相似暴雨洪水研究的基础上,旨在分析三峡水库以上长江上游流域的相似洪水,通过构建暴雨洪水各个阶段的指标体系,优选指标组合进行相似场次洪水识别,搜索与未来发生洪水指标相似的洪水,用于流域实时洪水预报参考。
2 暴雨洪水资料收集整理
长江上游流域面积大、水系发育、测站数量多。本研究涉及的测站范围为长江上游流域所有的水雨情报汛/遥测站,收集的历史水雨情资料序列为1998~2014年。具体资料包括:金沙江流域石鼓至屏山区间(除雅砻江支流外)共涉及8座水库、21个水文/水位站、118个雨量站;雅砻江流域获取的测站资料较少,仅涉及6座水库、7个水文/水位站;岷江流域紫坪铺、瀑布沟至高场区间共涉及2个水库站、8个水文/水位站、58个雨量站;沱江全流域共3个水文/水位站、26个雨量站;嘉陵江流域共涉及2个水库站、24个水文/水位站、107个雨量站;乌江流域共涉及7座水库,3个支流水文站和武隆干流水文站,流域内共涉及52個雨量站;长江干流屏寸区间共统计8个水文站,67个雨量站。水文水库站点分布如图1所示。
3 暴雨洪水相似性分析指标
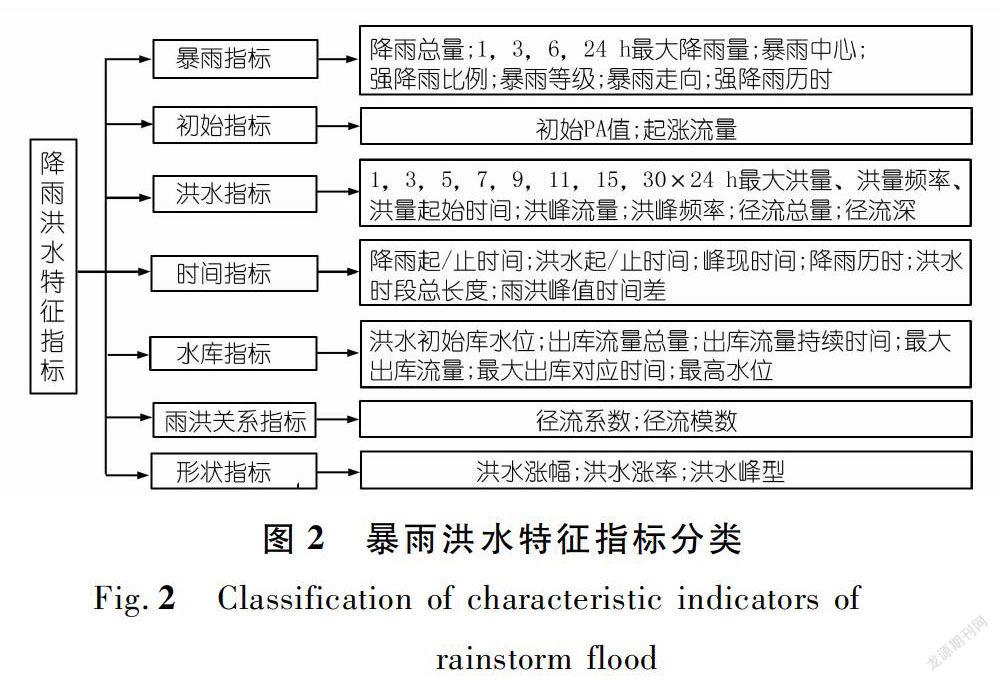
由于各场洪水发生的时间、地点和形成的规模和条件互不相同,每次洪水过程都有其不同的特征,常用一些特征值来表示。主要特征值有:洪峰水位、洪峰流量、洪水历时、洪水总量、降雨量、洪峰传播时间、洪峰频率等等。为了全面、准确地反映长江上游流域重要干支流断面洪水特征,在王海潮等提出的暴雨洪水指标体系的基础上[19],进一步细化指标,将暴雨洪水特征指标分为降雨指标、洪水指标、初始指标、时间指标、雨洪关系指标、水库指标、形状指标7类,共67个指标,如图2所示。
几个指标的解释如下。
(1) 暴雨测站比。统计场次降雨量超过50 mm的测站占比。
(2) 暴雨等级。 N=3lg(IW)-8(I为24h最大雨量,W为降水总量);当N≥8级时为巨型暴雨;当8>N≥6级时为大型暴雨; 当6>N≥4级时为中型暴雨;当N<4级时为小型暴雨 。
(3) 降水走向。降水中心的移动方向,定义为东-西、东北-西南、东南-西北、南-北等等。
(4) 强降雨历时。小时降雨量超过规定数值(>5 mm/h)的时间长度。
(5) 洪水涨幅。洪峰流量-起涨流量。
(6) 洪水涨率。(洪峰流量-起涨流量)/洪水历时。
(7) 雨洪峰值时间差。洪峰时间-降雨最大值时间。
(8) 洪水峰型。可分为单峰、双峰、峰偏前型、峰偏后型、中间型、矮胖型、尖瘦型等。
4 暴雨洪水摘录整编
针对长江上游流域24个重要的干支流控制断面进行历史洪水摘录,历史水雨情资料时间为1998~2014年。由于出口控制断面的洪水过程是由上游各干支流来水组合形成的,为便于摘录洪水资料的分析,在摘录各控制断面洪水过程期间,考虑上游各站的传播时间,同时摘录上游各水文断面的来水过程和对应的降雨过程。洪水摘录流程如图3所示。
本文洪水摘录共涉及长江上游流域24个重要的干支流断面,具体分布如下。
(1) 金沙江流域:1个雅砻江控制站(桐子林),其余6个均为干流断面(攀枝花、金江街、龙街、华弹、溪洛渡、向家坝/屏山)。
(2) 沱江流域:沱江控制站富顺。
(3) 岷江流域:岷江控制站高场。
(4) 嘉陵江流域:三汇、武胜、小河坝、罗渡溪、北碚。
(5) 乌江流域:乌江控制站武隆。
(6) 横江流域:横江控制站横江。
(7) 赤水流域:赤水控制站赤水。
(8) 綦江流域:綦江控制站五岔。
(9) 南广河流域:南广河控制站福溪。
(10) 屏山至宜昌区间干流:李庄、朱沱、寸滩、三峡入库。
(11) 三峡库区:无实际控制站,采用平滑后的三峡入库流量减去考虑传播时间后的寸武合成流量计算得到库区流量过程。
因金沙江流域部分为新建测站,资料年限较短,部分年份无洪水摘录;因向家坝水库建设,屏山站摘录后期为向家坝入库洪水;金沙江屏山下游至宜昌区间16个控制断面除富顺缺少1998~2000年资料外,其余测站资料完备;三峡区间因三峡水库建设情况,计算整理的洪水资料为2004年后。共摘录三峡入库洪水113场,为相似洪水指标分析提供样本。
5 相似性分析方法
5.1 洪水相似指标
评价2场洪水是否相似,主要从洪量、洪峰、洪水过程形状3个方面进行判定;其中洪量、洪峰为洪水的可确定值,洪水过程形状需要一个可度量的指标来确定。
在进行洪水过程模拟时,为判断2个洪水过程的吻合程度通常采用确定性系数作为指标,若去除洪水总量的偏差,确定性系数所反映的即为洪水形状的相似性。本文选用归一化后洪水过程(洪水单位线)的确定性系数来反映洪水形状相似性。
灰色关联度分析是依据各因素数列曲线形状的接近程度做发展态势的分析[20]。灰色关联度分析的意义是指在系统发展过程中,如果2个因素变化的态势是一致的,即同步变化程度较高,则可以认为两者关联较大;反之,则两者关联度较小。因此,基于洪量、洪峰、洪水形状的灰色关联度也可作为判断2场洪水是否相似的判别指标。
5.2 洪量相似度
洪量相关分析采用两场洪水洪量相似度作为指标,基本公式为
ΔQ ri =1- Q r0 -Q ri Q ro (1)
式中,Q ro 为基准洪水的洪量;Q ri 为第i场洪水的洪量。
5.3 洪峰相似度
洪峰相关分析采用两场洪水洪峰相似度作为指标,基本公式如下
ΔQ mi =1-Q m0 -Q mi Q mo (2)
式中,Q mo 为基准洪水的洪峰流量;Q mi 为第i场洪水的洪峰流量。
5.4 形状相似度
确定性系数可描述2个洪水过程之间的吻合程度。在洪量基本一致的情况下,该系数主要反映洪水过程形状的相似度。计算公式为
DC=1- ni=1[yc(i)-yo(i)]2ni=1[yo(i)- yo ]2(3)
式中,DC为确定性系数; yo(i)为实测值; yc(i)为计算值; yo 为实测值的均值; n为资料序列长度。
5.5 灰色关联度
灰色关联分析是定量地比较或描述系统之间或系统中各因素之间,在发展过程中随时间或不同对象而相对变化的情况,即分析时间序列曲线的几何形状,用它们变化的大小、方向与速度等的接近程度,来衡量它们之间关联性大小。在系统发展过程中,如果两个比较序列关联程度较大,则表示两者的变化态势基本一致或相似,其同步变化程度较高。
选取n场资料齐全的场次洪水,由每场洪水k个相似性指标的数据构成一个n×k的矩阵X=(xu) n×k ,其中xu(i=1,2,…,n;j=1,2,…,k)为第i场洪水的第j个相似性指标的数据。由于特征指标量纲不同,数量级也可能相差悬殊,为了消除量纲和量级不同带来的影响,使数据具有可比性,首先要对数据进行预处理。采用标准化变换,即
X′ i,j =X i,j /X i,1 (4)
式中,X′ i,j (i=1,2,…,n;j=1,2,…,k)為第i场洪水第j个特征指标经过初值化变换后的值。
为了模拟评估灰色关联分析方法在识别相似洪水中的有效性,从X=(xu) n×k 中任一场洪水的特征指标作为母序列X0,其他场次洪水的特征指标作为子序列Xi,计算母序列X0与各子序列Xi每个相似性指标差的绝对值,以Δ oi (j)表示第i场洪水第j个相似性指标与母洪水相应相似性指标之差的绝对值,即
Δ oi (j)=|X0(j)-Xi(j)| i=1,2,…,n;j=1,2,…,k(5)
从矩阵Δ=(Δ oi (j)) n×k 中取差值绝对值中的最大值Δ max 与最小值Δ min ,即
Δ max =maxΔ oi (j),i=1,2,…,n;j=1,2,…,k(6)
Δ min =minΔ oi (j),i=1,2,…,n;j=1,2,…,k(7)
求在各个相似性指标上母序列X0与各子序列Xi的关联系数,计算公式为
L oi (j)=Δ min +ρΔ max Δ oi (j)+ρΔ max (8)
式中,ρ为分辨系数,一般取ρ=0.5。
求各子序列Xi与母序列Xo洪水各特征指标关联系数的平均值,即关联度
γ oi =1kkj=1L oi (j)(9)
式中,γ oi 为第i场洪水与母序列洪水的关联度。
如果关联度比较大,则认为母序列洪水与子序列洪水的变化态势基本一致或相似,其同步变化程度较高,则可认为两场洪水相似。
6 相似洪水判别指标分析
6.1 技术路线
以暴雨洪水摘录结果为基础,将历史洪水指标进行筛选、聚类分析,分析步骤如图4所示。
6.2 指标聚类分析
针对长江上游流域摘录洪水统计的特征变量采用离差标准化和标准化方法分别进行聚类分析[21], 聚类结果见图5。
结合聚类分析结果和各指标的物理意义,最终确定16项特征指标,见图6。
6.3 洪水特征指标分析与洪水相似指标分析
依据聚类、归类分析方法选取的16个洪水特征指标,分别分析各指标与洪水相似指标(洪量、洪峰、形状相似度、灰色关联度)的相关关系。上面共统计了三峡入库113场历史洪水16个特征变量与本研究选定的相似洪水判别指标的相关关系,分析结果见表1。
由表1和图6可知,根据16个洪水特征指标的分析,选择降水量、降水历时、起涨流量、洪水涨率4个相关程度较高的指标作为相似洪水判别的备选指标。之所以选择以上4个指标作为判别相似洪水的指标还有一个重要的原因,那就是历史相似洪水的一项重要的意义是寄希望于通过当前掌握的暴雨洪水特征参数,来判断和预测未来洪水的量级和变化趋势,而降水量、降水历时是可以结合当前气象数值天气预报进行获取,起涨流量可根据实时监测数据获取,洪水涨率也可以通过正在上涨当前流量或者水位的斜率估算获取。它们的易获得性和与洪量、洪峰的较高相似度使它们成为当前最合适的相似指标。
6.4 指标有效性验证
以三峡入库洪水为例,选择降水量、降水历时、洪水涨率和起涨流量指标计算各场洪水与基准洪水的灰色关联度,进行相似洪水的搜索,分别以2010072007、2011082307、2013092113、2014071213为基准洪水,对它们分别找到的相似洪水如图7所示。2010072007号洪水与2010082413号洪水关联度最大,为0.90;2011082307号洪水与2010062419号洪水关联度最大,为0.965;2013092113号洪水与2013091319号洪水关联度最大,为0.96;2014071213号洪水与2012052913号洪水关联度最大,为0.91。
从上述选取的4场洪水搜索的历史相似洪水过程和形状的匹配度来看,采用降水量、降水历时、洪水涨率和起涨流量来进行找寻历史洪水的贴合度是比较好的,同时也存在类似2010072007洪水找到的相似洪水2010082413与其只是形状上较为相似,洪水量级上相差较多的情况,这种情况的出现一方面是因为当前洪水场次的样本还不够多,1998~2014年,三峡入库洪水一共113场,还没有找到与2010072007暴雨洪水特征较为相似的洪水过程;另一方面,需要进一步地挖掘利用各种洪水特征要素来搜索相似洪水。
图7 基准洪水与相似洪水过程对比Fig.7 Comparative analysis of baseline flood and similar flood
7 结 语
本文收集整理了1998年以来长江上游流域的时段雨水情资料,在历史暴雨洪水资料整编的基础上,采用洪量相似度、洪峰相似度、形状相似度和灰色关联度等相似分析方法开展了相似洪水判别指标分析,以113场三峡入库洪水为样本,采用聚类分析、物理概念分析方法统计归类历史场次洪水的67项指标,并对数值型指标进一步筛选、聚类,选定具有代表性的16项洪水特征指标用于洪水相似性判别研究;最终确定可获取且能反映洪水相似性的4项洪水特征指标作为洪水相似的判别指标,并经过了有效性验证。
洪水由暴雨形成,从物理意义上分析,降水的不同時间、空间分布直接影响来水过程,洪水过程的相似性应结合降水过程进行分析。设定多种气象预报要素与洪水特征要素组合进行相似洪水查询,并与研究所得的相似洪水判别指标查询的相似洪水进行了比较。同时,长江上游流域面积巨大,暴雨的时空分布组合千变万化,影响洪水过程的降水时空分布因素多种多样;在相似洪水搜索中每一类降水成因要素都有类似筛选的效果,因此直接导致相似洪水查询的样本大量减少,少量的洪水样本暂不足以支撑分类相似洪水的搜索判别,样本积累越多,相似性洪水的判别搜索表现将会越来越好。
參考文献:
[1]刘冬英,张明波.长江三峡以上洪水组成分析[J].人民长江,2010,41(19):14-17.
[2]程海云,葛守西.长江洪水分类指标体系研究[J].人民长江,2008,39(8):1-2,118.
[3]张雅琦,李妍清,戴明龙,等.基于投影寻踪法的三峡入库洪水与坝址洪水分类[J].人民长江,2016,47(9):25-28.
[4]肖天国.金沙江、岷江洪水遭遇分析[J].人民长江,2001,32(1):30-32,48.
[5]熊莹.长江上游干支流洪水组成与遭遇研究[J].人民长江,2012,43(10):42-45.
[6]任继周,彭德才,乔伟,等.基于DTW算法的云南昭通地区场次洪水相似性研究[J].水利水电快报,2017,38(8):35-38.
[7]吴碧琼,周理,黎小东,等.基于BTOPMC的无资料区水文模拟及相似性分析[J].人民长江,2015,46(4):21-25.
[8]潘杰.辽宁西部沿海地区无观测流域水文相似性分析[J].吉林水利,2013(8):46-48.
[9]姚成,章玉霞,李致家,等.无资料地区水文模拟及相似性分析[J].河海大学学报:自然科学版,2013,41(2):108-113.
[10]万新宇,包为民,荆艳东,等.基于主成分分析的洪水相似性研究[J].水电能源科学,2007(5):36-39.
[11]孙杰,龚翰.洪水相似性分析方法研究[J].东北水利水电,2008,26(12):9-10.
[12]刘卫林,董增川,梁忠民,等.暴雨洪水相似性分析及其应用研究[J].中国农村水利水电,2007(2):132-135,148.
[13]牛俊,董增川,梁忠民.流域暴雨洪水天气成因相似性分析[J].东北水利水电,2006(5):20-22,72.
[14]孔凡哲,芮孝芳.基于地形特征的流域水文相似性[J].地理研究,2003(6):709-715.
[15]王继民,朱跃龙,李薇,等.多度量水文时间序列相似性分析[J].水文,2014,34(4):15-20,73.
[16]张艳平,周惠成.基于暴雨洪水相似性分析的洪水分类研究[J].水电能源科学,2012,30(9):50-54.
[17]沈强,万定生,王亚明.基于嵌入式索引的水文时间序列相似性搜索模型[J].水文,2016,36(6):64-69.
[18]汪丽娜,陈晓宏,李粤安. 投影寻踪和人工鱼群算法的洪水分类[J].人民长江,2008,39(24):34-37.
[19]王海潮,董增川,梁忠民,等.暴雨洪水相似性分析指标体系研究[J].水文,2006(2):13-17.
[20]刘思峰,蔡华,杨英杰,等.灰色关联分析模型研究进展[J].系统工程理论与实践,2013,33(8):2041-2046.
[21]杨艳林,叶枫,吕鑫, 等.一种基于DTW聚类的水文时间序列相似性挖掘方法[J].计算机科学,2016,43(2):245-249.
引用本文:陈 建, 李春红,王 峰,王建平.长江上游流域暴雨洪水相似性判别指标研究[J].人民长江,2019,50(1):58-63.
Study on similarity discriminant index of storm flood in upper reaches of Yangtze River
CHEN Jian,LI Chunhong,WANG Feng,WANG Jianping
(NARI Group Corporation /State Grid Electric Power Research Institute, Nanjing 211000, China)
Abstract:The correlations and regularity of storm floods exist in various stages of their development. Taking the upper reach of the Yangtze River as an example, we classified 67 storm flood indexes as seven categories, including precipitation, flood, initial state indexes, time, the relationship between storm and flood, reservoir shape and process. Four indicators including total rainfall, rainfall duration, initial rising flow and flood rising rate were optimized as the similar flood discrimination indicators by collating storm flood historical data, extracting storm-flood processes and calculating their characteristic values, and combining with runoff similarity, flood peak similarity, flood process similarity and grey correlation degree. Taking 113 floods of the Three Gorges Reservoir inflow for similarity test samples, several typical floods were chosen to search the similar history floods. The results showed that there were high similarity between them and the deterministic coefficients were all above 0.9, indicating that the four indicators had highly reference value to guide the real-time flood forecasting. The results have been applied to the upper reach of the Yangtze River above the Three Gorges Reservoir, and it has a good effect in finding historical similar floods.
Key words: storm flood similarity; similar flood discrimination indicator; similarity analysis; upper reaches of Yangtze River
