基于数据挖掘技术的图书推荐算法应用研究
2019-09-10王红
摘 要:通过构建个性化图书推荐系统,图书馆可以为读者提供更加准确的图书检索推荐服务,也可以通过对读者借阅兴趣的分析来提高图书馆的馆藏借阅率,降低闲置图书的管理成本。本文从图书的特征值分析入手,研究了目前国内通用的中图分类法图书相似度算法,分析了两种基于数据挖掘技术的图书过滤推荐算法的优缺点,提出了一种基于协同和内容混合过滤的图书推荐算法。
关键词:图书推荐;过滤推荐算法;混合过滤
中图分类号:TP311.13;TP391.3 文献标识码:A 文章编号:2096-4706(2019)23-0020-03
Research and Application of Book Recommendation
Algorithm Based on Data Mining
WANG Hong
(Northeast Agriculture University Library,Harbin 150030,China)
Abstract:By building personalized book recommendation system,library can provide most accurate book searching and recommendation for the users. By studying the book interest to the users,library can advance the rate of book circulation and cost reduction of idle books. In this paper,starting from the analysis of book eigenvalues,we study the book similarity algorithm of Chinese library classification,analyze the advantages and disadvantages of two kinds of book filtering and recommendation algorithms based on data mining technology,and propose a book recommendation algorithm based on collaborative and content mixed filtering.
Keywords:book recommendation;filtering recommendation algorithm;hybrid filtering
0 引 言
通过图书馆信息管理系统来提高读者检索和借阅图书的效率是目前各图书馆提高服务质量和客户满意度的有效手段。借阅者能够在使用图书管理系统时快速检索到所需的书籍,有助于提高图书借阅率,也能为图书管理节省一些成本。在图书馆系统中对检索结果的处理和显示是提高检索效率的关键技术,这些检索推荐算法也都是建立在图书特征划分体系基础上的。目前图书馆图书管理系统的图书特征信息划分采用的是中图分类法,图书推荐算法基于聚类分析技术,分别从内容和协同过滤两个方面进行计算和推荐。
1 中图法图书相似度计算
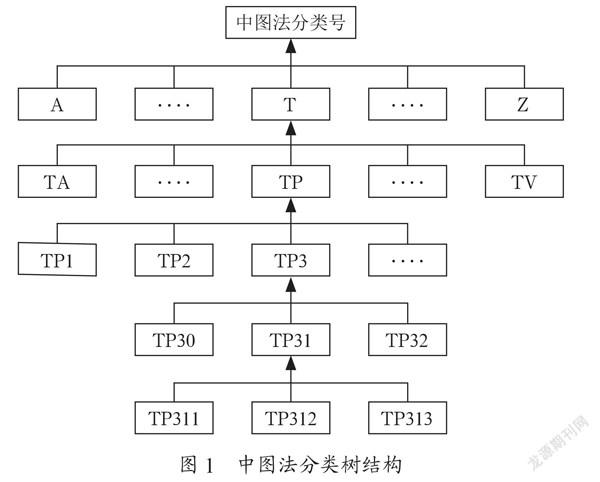
图书馆现有的图书信息管理系统会根据图书的特征信息对图书进行划分,具体包括图书分类号、题名、学科、作者、ISBN号、馆藏时间等,这些能够区分图书类别的信息称为图书特征值。图书信息管理系统就是根据特征值数据的结构化存储和管理来实现图书检索和借阅服务的。特征值中被用于图书检索和推荐服务的关键信息就是图书分类号,目前国内最为通用的图书分类号计算方式就是中国图书馆图书分类法(下文简称中图法)。中图法按照树状结构划分图书类别,从上至下按照由一般到具体的过程分为5大部类,22个基本大类。中图法计算生成的图书分类号,不仅可以确保图书分类的准确性,还能确保推送项目的真实性,对于图书推荐算法的研究具有非常重要的参考价值。中图法的分类树结构如图1所示。
从分类树的结构可以看出,分类树的同级节点会随着层级的下降逐渐失去关联性,同一分支的节点则在延伸过程中逐步提高关联性。由此可以得出结论,在分类树中统一分支的节点,可以视为同学科类型的特征值。
图书推荐算法是一种典型的聚类分析技术,是按照数据对象集合的相似程度进行分类的非假设性算法。图书推荐的核心问题就是如何通过相似度的计算来划分数据集合。作为图书分类的主要特征值,中图法分类号的相似度计算对于提高图书推荐算法的准确性有非常重要的意义。中图法图书相似度是依据分类树的最近公共父節点深度进行计算得出的,计算公式如下:
SIM(U,V)=DEPTH(LCA(U),LCA(V))/MAX-DEPTH
式中,U和V分别代表分类树的任意两个节点,SIM(U,V)用于计算分类树节点的相似度,LCA(U)用于计算与U节点最近的父节点,DEPTH用于计算得出父节点深度,MAX_DEPTH是该分类树的深度最大值。DEPTH的计算过程使用了Tarjan算法和倍增法。
2 基于内容的图书推荐算法
基于特征值计算和用户档案信息的图书推荐算法是目前图书推荐系统最为常见的内容推荐算法。基于内容的图书推荐算法首先对馆藏数据和借阅数据进行分析,得出用户的检索关键词和图书特征值,分别得出关键词集合和特征值集合并建立图书属性数据库;然后利用图书属性数据库进行用户借阅特征分析,得出用户特征与图书特征之间的关联关系;最后使用余弦相似度算法来得出特征值关联性较高的图书推荐给读者。计算过程中要根据推荐项目的数量适当调整计算参数,调节推荐书目的特征值范围和用户特征范围。
图书推荐算法的优势首先是无需考虑用户的借阅记录数据,这对于借阅数据积累不足的馆藏系统有较大帮助,可以避免因数据不足造成的推荐偏离现象;其次,对用户检索关键词的计算可以最大限度获取用户阅读兴趣信息,提高推荐算法的准确性,也能保证推荐项目集中在统一分支的区域内,保证关联性;第三,图书特征和用户特征相关联的推荐算法,可以将新增馆藏加入推荐体系,解决了以往推荐算法无法为用户推荐新增馆藏的问题。基于内容的图书推荐算法的局限性在于:用户特征值的获取如果不是在一个较长周期内,会造成推荐图书与用户借阅偏好的一定偏离,新用户的借阅推荐则更加没有准确性的保证。
3 基于协同过滤的图书推荐算法
协同过滤是一种互联网领域炙手可热的信息过滤和推荐算法,它利用具有共同经验的群体喜好来给用户推荐信息。协同过滤算法是以合作为基础,使用评分机制或群体过滤等方式来给予信息一定的评价,记录评价信息(最好的与最不好的)并筛选得出推荐结果。图书推荐系统应用协同过滤算法也比较适合,针对用户的不同教育背景、身份以及职业都可以区分经验群体,借阅过程给出的反馈信息也可以形成过滤的数据支持。协同过滤算法的推荐过程与用户的群体和偏好有直接的联系,选择相似偏好的用户组成用户群体,根据用户对馆藏图书的评价得分来进行具有普遍性的偏好分析,得出该群体的推荐结果。
基于过滤协同的图书推荐算法有两个思路:一是可以基于用户的借阅数据进行相似度矩阵分析,得出群体兴趣特征,划分组别后进行定向过滤推荐;另一种是基于建立项目相似度矩阵,将用户感兴趣或不感兴趣的项目进行组别划分后进行定向过滤推荐。
3.1 基于用户的协同过滤
基于用户的协同过滤算法的核心内容就是确定项目偏好度相似的临近用户组别,通过其他临近用户组别的项目推荐评分得出目标用户的项目兴趣权重系数,从而推断出用户感兴趣但未曾评分的项目来进行定向的图书推荐。除了图书推荐外,图书馆可以根据临近兴趣组别来为用户推荐好友,为目标用户推荐偏好相似度较高的其他用户,并对结为书友的用户进行加权兴趣组别计算,构建更加准确的图书推荐系统应用。
3.2 基于项目的协同过滤
基于项目的协同过滤的核心内容是以相似度为加权系数,对已评价的项目进行加权计算,得出未评价项目的预测评分。相比基于用户的协同过滤算法,基于项目的协同过滤的项目关系相对稳定,只要定期对相似度加权系数进行更新就可以实现准确的推荐,可以保证推荐系统的系统性能,这也是目前各领域商业网站采用较多的推荐算法。
对项目相似度的计算,基础数据源是该项目的用户群体,使用Jaccard相似度算法来进行相似度计算,得出的相似度加权系数再作用于已评价项目的评分结果之上,得出目标用户群体的未推荐项目加权评分,将评分较低的项目去除后按照评分高低为用户进行定向图书推荐。除了图书推荐应用外,基于项目的协同过滤算法也可以应用于用户图书检索的结果集生成,将相似度加权系数作为检索条件排序的参考依据之一,可以有效提高用户检索结果的准确性,提高用户体验。
基于协同过滤的推荐算法的优势在于:首先,算法的数据源面向所有用户群体和馆藏项目,根据预先设定的计算程序就可以实现推荐项目的自动更新,保证了推荐算法的准确性;第二,用户评分可以有效提高资源项目的相似度分析数据的采集准确性,可以解决一些采集难度较大的多媒体资源无法进行相似度计算的问题;最后,临近群体的兴趣推荐可以为借阅倾向较为单一的用户推荐接近的图书项目,有助于用户扩宽阅读范围。基于协同过滤的推荐算法的主要缺点就是对新项目的推荐更新较慢,当数据源较为稀疏时会出现冷启动现象等。
4 基于混合过滤的推荐系统
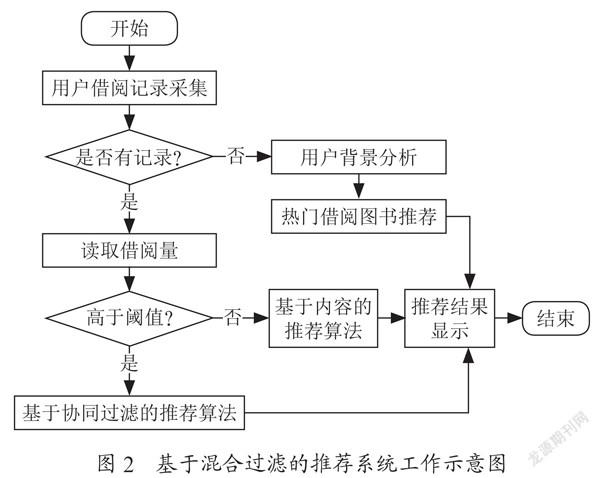
通过比较和分析基于协同过滤、基于内容过滤的推荐算法的优缺点,为了进一步提升推荐系统的用户体验,本文设计了一种基于混合过滤的推荐系统,实现了两种推荐算法的优势互补。基于混合过滤的推荐系统工作示意图如图2所示。
(1)从图2可以看出,基于混合过滤的推荐系统首先采集用户的借阅记录信息,对于并未进行过图书借阅的用户进行非推荐算法处理,按照用户注册信息中的性别、年龄、教育背景、工作单位等信息进行热门图书推荐。
(2)对于有借阅记录的用户群体,根据预先设定的借阅量阈值进行区分计算,借阅量低于阈值的用户采用基于内容的推荐算法进行推荐。推荐算法首先采集图书中图法分类号信息,构建图书的属性数据表得出中图法分类号集合;然后利用中图法图书相似度计算公式得出用户阅读特征值;最后使用余弦相似度算法对图书特征值进行加权排序得到推荐结果序列。
(3)借阅量高于阈值的用户采用基于协同过滤的图书推荐算法。该过程首先以用户兴趣群体和项目信息为源数据,通过Jaccard算法計算得出项目相似度加权系数;然后对临近项目的相似度进行加权计算,得到推荐集合推荐给用户群体。
5 结 论
基于混合过滤的图书推荐算法,整合了基于内容和基于协同过滤两种推荐算法的优点,对图书推荐的场景进行划分并有针对性地利用中图法、用户阅读特征值计算、余弦相似度算法、Jaccard算法等先进算法进行处理,有效提高了推荐算法的准确性,提高了用户借阅率。
参考文献:
[1] 高晟.基于关联规则与贝叶斯网络的高校图书馆个性化图书推荐服务 [J].情报探索,2019(8):87-94.
[2] 彭文惠.基于数据挖掘的自动化推荐系统改进ART算法探究 [J].现代信息科技,2019,3(8):44-46.
[3] 任杰.关联规则应用下的高校图书馆图书推荐服务 [J].办公室业务,2018(23):148.
作者简介:王红(1969-),女,汉族,辽宁沈阳人,副研究馆员,硕士,研究方向:文献信息服务。
