低秩判别性字典学习及组织病理图像分类算法
2019-09-09毛丽珍汤红忠范朝冬曾淑英
毛丽珍,汤红忠,2,范朝冬,曾淑英
1(湘潭大学 信息工程学院 ,湖南 湘潭 411105)2(湘潭大学 智能计算与信息处理教育部重点实验室,湖南 湘潭 411105) E-mail:diandiant@126.com
1 引 言
现如今,癌症已成为世界上最常见的疾病之一,世界卫生组织的报告显示,近年来癌症统计数据迅速增长,每年世界各地约有170万新增的癌症病例登记在册,预计发病率为25.2%.因此,癌症的预防、早期诊断和治疗引起了广泛的关注和讨论.病理检查仍然是癌症检测的黄金标准.而病理学家手工分析大量的组织病理学图像是一项繁重的工作,非常耗时且容易出错.与此同时,显微镜成像技术与机器学习的发展共同促进了数字病理学的出现[1].数字病理学旨在利用计算机来自动分析数字化组织病理学图像特征,从而服务于不同任务,如检测、分割和检索,而其中研究最广泛的莫过于组织病理图像分类了.
许多早期的组织病理图像分类算法一般包括两个阶段,即特征提取与分类器构造.在特征提取阶段,基于生物学先验知识,如fractals[2],LBP[3]和HOG[4]特征被提出并用于组织病理图像分类.而另一些研究者关注于分类器的构造,并提出了AdaBoost[5]和随机森林[6]等分类器.以上这些算法在某些特定的数据集上取得了很好的分类效果,但这些算法一般是针对特定数据集设计的,其泛化性能有限.
得益于人类视觉系统稀疏机制的启发,稀疏表示在计算机视觉领域得到了广泛的应用[7,8].基于稀疏表示的算法主要可分为两大类:第一类是基于预定义字典的算法,如Srinivas等人[9]利用彩色图像RGB三通道之间的相关性来构造字典,并应用于组织病理图像表示与分类.由于字典是用训练样本构造的,这种基于预定义字典的算法可能不能充分利用到隐藏在训练样本中的判别信息.因此,第二类算法应运而生,即从训练样本中学习字典.这一类算法又可以分为非监督学习与监督学习.
非监督学习算法关注于组织病理图像的精确重构.例如,通过利用图像的多尺度和空间信息,Tang等人[10]提出了一种用于乳腺图像分类的多尺度表示学习算法.Zhang等人[11]提出了一种异质特征融合算法并应用于乳腺组织图像分类.上述算法主要关注组织病理图像的重构,因此其分类性能不一定是最佳的.
而监督学习是在非监督学习的基础上发展起来的,这一类算法通过在字典训练过程中考虑到训练样本的类标信息,从而学习出判别性字典,例如文献[12-14]通过在目标函数中引入线性分类器[12]、类标一致性约束[13]、对稀疏编码系数的Fisher约束[14],提高了学习的字典的判别性.除此之外,VU等人[15]提出了一种基于判别性特征的字典学习算法(DFDL),通过约束类内和类间的重构误差,学习出每一类的判别性子字典.受文献[15]启发,文献[16]提出了一种面向判别性特征的字典学习算法(FCDFDL),利用Fisher准则约束字典的类内和类间距离,提升了分类性能.进一步,Tang等人[17]利用图像RGB通道的互信息,构造了共享字典和RGB通道独有字典,并用SVM进行分类.
然而,在组织病理图像分类中,样本特征之间一般具有很高的相关性.为了解决这一问题,一些学者认为编码系数应该是满足低秩的,因此在字典学习过程中约束稀疏编码的低秩性[18,19].与上述算法不同,本文提出了一种基于低秩约束的判别性字典学习算法(Discriminative dictionary learning with low-rank constraint,LRCDDL).在训练阶段,LRCDDL算法将子字典对同类和非同类样本的重构误差项加入到字典学习的目标函数中,增强子字典对同类样本的重构能力,降低子字典对非同类样本的重构能力.同时,在目标函数中构造了子字典的低秩约束项,为每一类样本寻找最具判别性的特征,从而学习出结构最为紧凑的字典.在测试阶段,本文利用重构误差对测试图像进行分类.本文在ADL数据集上进行的实验结果证明了LRCDDL算法的有效性.
2 低秩矩阵恢复理论
近年来,低秩矩阵恢复理论的出现有助于准确地恢复数据中的底层低秩结构,因此,低秩矩阵恢复在背景建模[20]、子空间聚类[21]等方面应用广泛.
假设一个矩阵可以分解为两个矩阵之和:X=A+E,其中A是低秩矩阵,E是稀疏矩阵.低秩矩阵恢复的目的是从X中获得低秩矩阵A,因此可得到以下优化问题:
(1)
其中rank(A)表示A的秩,‖E‖0表示E中非零元的个数,λ是控制E的权重.以上问题是NP难问题,因此转化为下式求解:
(2)
其中,‖A‖*表示A的核范数,近似等于A的秩.而‖E‖1是‖E‖0的凸优化形式.这一形式通常被用来图像恢复.近年来,低秩矩阵理论也被应用于图像分类领域,如文献[18,19]强调保证编码系数的低秩性可以增强学习字典的判别性.而本文认为,从同一类样本中学习出的子字典应该是满足低秩的.因此,本文构造字典的低秩约束项.
3 LRCDDL算法
3.1 LRCDDL算法整体流程介绍
本文提出了一种基于低秩约束的判别性字典学习算法,整体框架如图1所示,由两部分组成:训练阶段和测试阶段.首先,利用训练样本通过LRCDDL字典学习模型学习出判别性字典.在测试阶段,基于学习的字典,利用重构误差对测试图像进行分类.
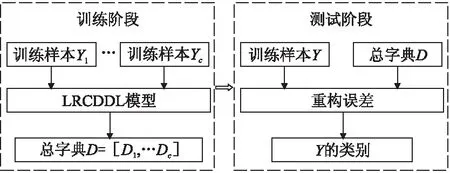
图1 LRCDDL算法整体流程Fig.1 Overall flow of the LRCDDL algorithm
3.2 训练阶段
本文提出的字典学习模型为:
(3)
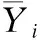

固定字典Di,公式(3)可化为:
(4)
(5)
(6)

2)字典Di更新
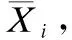
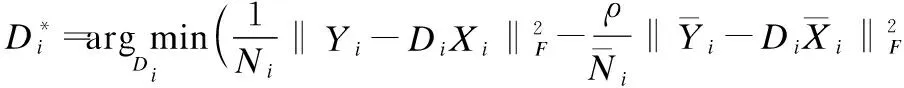
(7)
公式(7)可化为如下所示:
(8)
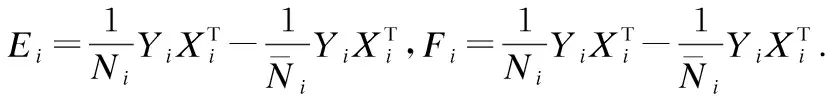
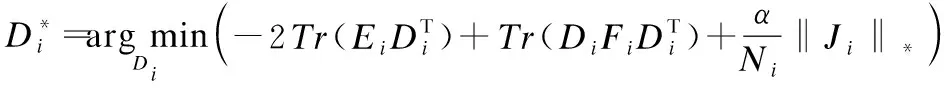
(9)
公式(9)可利用ADMM算法[23]求解,求解过程如下:
(10)
其中λ>0是调节因子,Di可通过ODL算法求解,Ji可通过SVD算法求解.
3.3 测试阶段
在训练阶段学习出字典后,得到总字典D=[D1,…,DC],因此可以对测试图像Y进行分类.首先通过下式求出其在D上的编码系数X:
(11)
其中,L是稀疏度.其中,L是稀疏度,公式(11)可通过OMP算法求解得到X=[X1;…;XC].
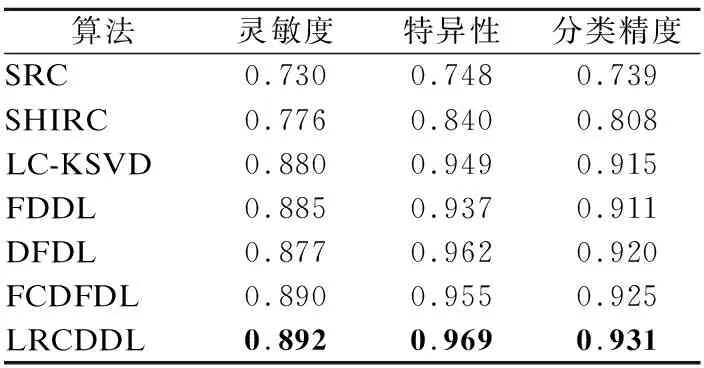
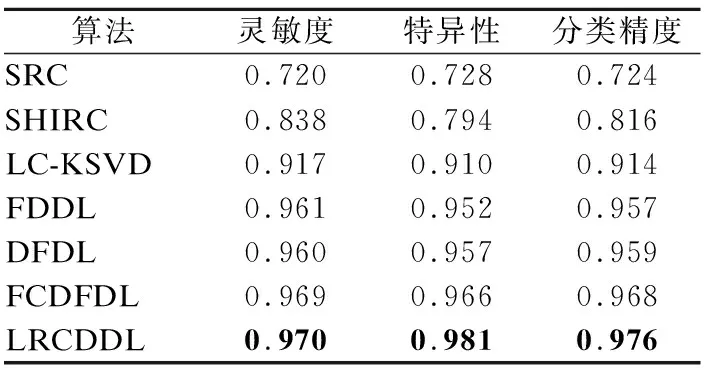
接着,计算各子字典对测试样本Y的重构误差:Ri=Y-DiXi(i∈{1,…,C}),并通过比较重构误差的大小来判断测试图像Y的类别:若Rr 为验证LRCDDL算法的有效性,本节在ADL数据集上进行了实验.所有实验均在Windows 10的电脑上进行,电脑配置如下:处理器为Intel(R)Pentium(R)CPU G3220@3.00GHz,内存3.82G.使用的软件是MATLAB. 图2 ADL数据库图像示例Fig.2 Example of the ADL dataset ADL数据集(1)http://signal.ee.psu.edu/medical_imaging.html一共有900多幅组织病理图像.该数据集一共包括3种动物器官的图像:肾脏,脾脏和肺部.每种器官有健康和炎症两类情况,每类拥有150多幅尺寸为1360×1024×3的图像.在实验过程中,本文将图像尺寸缩小为680×512×3.图2是ADL数据集的图像示例.其中,第一行分别是肾脏、脾脏和肺部的健康图像,第二行分别是肾脏、脾脏和肺部的炎症图像. 对于每种器官,本文从健康和炎症两类中随机选择50幅图像用于训练,余下的100幅图像用于测试.从每幅训练图像中随机选择200个20×20×3的图像块,然后将图像块三个通道连接成一个列向量,组成训练样本Y∈R1200×20000,字典原子个数设为200,训练阶段迭代次数设为50.在肾脏分类时的参数分别设置为ρ=1E-4,α=1E-3;在脾脏分类时的参数分别设置为ρ=1E-2,α=1E-5;在肺部分类时的参数分别设置为ρ=1E-2,α=1E-3. 4.3.1 分类性能评估 为评估本文算法的性能,本文与SRC、SHIRC、LC-KSVD、FDDL、DFDL和FCDFDL等算法进行了实验比较.其中,SRC与SHIRC无需学习字典,而是直接使用训练样本构成字典,LC-KSVD、FDDL、DFDL和FCDFDL是图像分类领域非常有效的字典学习算法. 表1 肾脏图像分类结果Table 1 Kidney image classification results 表2 脾脏图像分类结果Table 2 Spleen image classification results 表3 肺部图像分类结果Table 3 Lung image classification results 在本文实验中,我们采用10倍交叉验证评估以上算法的分类性能.所有算法采用相同的实验设置,如训练样本、测试样本和字典尺寸相同.我们比较了三个在组织病理图像分类中使用非常普遍的三个指标:灵敏度、特异性和总体分类精度,表1-表3分别显示了在肾脏、脾脏和肺部图像分类中所有算法的实验结果. 由表1-表3可知,在肾脏、脾脏和肺部图像分类中,LRCDDL算法的灵敏度虽然在肾脏图像上低于DFDL和FCDFDL等算法,但在脾脏和肺部图像的分类上高于所有对比算法.此外,LRCDDL算法在特异性和整体分类精度均高于其他对比算法.这说明本文提出的LRCDDL算法有助于学习出紧凑的判别性字典,获得更好的分类性能. 4.3.2 实验参数分析 本小节讨论了参数ρ和α对实验分类精度的影响.实验设置参照4.2节.ρ和α取值为{1E-5,1E-4,1E-3,1E-2,1E-1}.图3分别显示了肾脏、脾脏和肺部上的实验结果. 图3 ρ和α对图像分类的影响Fig.3 Influence of ρ and α on the image classification 从图3中可知,在肾脏图像中设置为ρ=1E-4,α=1E-3;在脾脏图像中设置为ρ=1E-2,α=1E-5;在肺部图像中设置为ρ=1E-2,α=1E-3,LRCDDL算法可以获得最高的分类精度. 本文提出了一种基于低秩约束的判别性字典学习算法(LRCDDL),并将其应用于组织病理图像分类.在字典学习的目标函数中,LRCDDL算法加入了子字典对同类和非同类样本的重构误差项,从而增强子字典对同类样本的重构能力和降低其对非同类样本的重构能力.考虑到样本之间具有很高的相关性,LRCDDL算法在目标函数中构造了子字典的低秩约束项,为每一类样本寻找最具判别性的特征,从而学习出结构最为紧凑的字典.这一策略与主流的低秩表示中关注稀疏编码的低秩性不同.最后,在ADL数据集上的实验证明了本文提出的LRCDDL算法的有效性,与一些现有算法相比,LRCDDL算法获得了更好的组织病理图像分类效果.4 实验分析
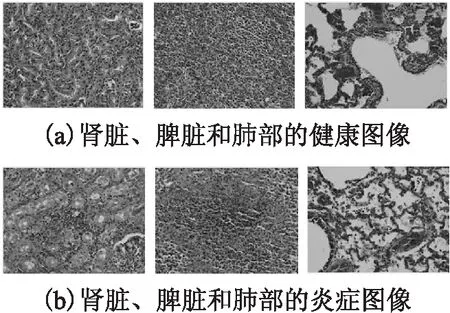
4.1 数据集介绍
4.2 实验设置
4.3 实验结果与分析


5 结束语
