有道智云翻译API在图书馆信息服务中的应用研究*
2019-09-06刘邦国
袁 润 刘邦国 王 丹
(江苏大学科技信息研究所 镇江 212013)
1 引言
高校图书馆在开展信息服务过程中,经常遇到翻译工作。例如,在定题跟踪、专题报告、文献计量、竞争情报、研究前沿探测等服务工作中,有时需要翻译外文文献的题名、摘要,也包括国家地区名称、机构名称,有时还需要翻译关键词、主题词、研究前沿等学术词汇。虽然可以利用的在线翻译工具很多,但是针对批量的重复性翻译,工作量仍然显得比较繁重。随着技术的发展,各种工具已成为图书馆信息服务的好帮手,学科馆员经常利用CiteSpace 做文献计量分析,使用Ucinet 做网络分析,采用R 语言做各种统计分析等。因此,开发一个翻译工具,以减轻馆员工作量,是本文研究的目的所在。
目前,基于深度学习的神经机器翻译方法获得迅速发展,已取代传统的统计机器翻译成为学术界和工业界新的主流方法,翻译质量得到显著提升[1]。研究机器翻译在图书馆信息服务中应用的文献较少,具有代表性的研究工作是陈江萍[2-3]等对数字图书馆多语言信息存取和元数据记录的机器翻译,结果显示,机器翻译系统可以胜任翻译一些常用的信息存取点,如主题、创建者、标题等,但是对概述或文摘的翻译仍是一大挑战。
有道翻译API 接口提供的翻译服务,包含了中英翻译和小语种翻译功能,通过编程调用有道翻译API,传入待翻译的内容,并指定要翻译的源语言和目标语言种类,就可以得到相应的翻译结果。R 语言是一个自由、免费、源代码开放的软件,特别在统计计算和统计绘图方面具有强大功能,通过编程可以极大地减轻重复性的工作量。本文采用R 语言函数调用有道翻译API,实现了自动翻译功能,并对翻译结果开展了测评研究。
为保证翻译与测评过程条理清晰,本研究工作分为四个步骤:第一,整理分类翻译的内容,主要包括题名、摘要、国家、机构、研究前沿等;第二,调用R 语言函数完成翻译;第三,从翻译结果当中随机抽样,生成测评试卷;第四,采用人工测评方法对翻译结果打分并写上评语。研究表明,翻译结果基本能够满足图书馆信息服务需求,对专有名词的翻译表现最好,对句子、段落的翻译表现较好,对缩写词汇、新生词汇以及结构过于复杂句子的翻译欠佳。基于R 语言开发的翻译工具在图书馆学科服务、定题跟踪、专题报告、科技查新等服务中得到了应用,一定程度上减轻了信息服务过程中的翻译工作量。
2 有道智云API 的自然语言翻译
国内提供在线翻译服务的公司主要有百度和有道,两者均提供了互联网应用编程接口。目前,有道智云API 接口可以提供的翻译服务主要包含中文在内的8 种语言相互翻译功能,分别是中文、日文、英文、韩文、法文、俄文、葡萄牙文和西班牙文。
API 是互联网服务应用编程接口,直接通过HTTP 协议与客户程序进行通信。应用程序一般需要执行三个步骤:第一步,按要求准备好相关参数,使用HTTP 协议调用接口;第二步,接口对源文数据进行机器翻译,并返回结果;第三步,按需要的格式提取返回结果。应用程序无需关心接口处理的细节,这使得第三方可以利用有道翻译提供更具灵活性的,能够满足用户个性化需求的特色服务,例如,嵌入到浏览器、网站或应用程序中。
调用有道智云API,需要向其传入待翻译的内容、源语言的种类和目标语言的种类,同时还需要传入应用ID 及其密钥等参数,若通过接口的认证,就可以得到相应的翻译结果。这一过程可以分解为三个步骤:构建HTTP 请求指令、获取翻译结果、转换翻译结果。
第一步,构建HTTP 请求指令。HTTP 请求指令包含7 个变量,如表1所示。

表1 HTTP 请求指令变量说明
表1中的前三个变量很好理解,变量q 用来存储要翻译的文本,其使用的编码必须是UTF-8格式;变量from 用来存储源语言的类型,可以设置成auto 让服务器自动检测,由于本次仅对英文进行了翻译测试,故源语言类型为“EN”。变量to用来存储要翻译的目标语言。由于有道智云API是一项收费服务,所以需要创建应用ID 和密钥,以便服务器根据该ID 提交数据的字节数来收费。应用ID(appKey)及其密钥(secretKey)需要预先到有道智云网站申请,步骤如下:①登陆有道智云官网,点击右上角“注册”按钮,在注册页面(http://ai.youdao.com/register.s)选择用网易邮箱或者合作账号,比如QQ、微博和微信登陆,然后完善个人信息,成为开发者;②登陆有道智云平台后,点击“应用管理”—>“我的应用”—>“创建应用”,根据提示信息,完成应用创建;③选择“自然语言翻译”—>“翻译实例”—>“创建实例”,完成实例的创建;④点击“应用管理”—>“我的应用”,在应用列表找到新需要绑定的应用,点击“绑定服务”。变量salt 存储的是一个从1 到65 535 之间的一个随机数。签名变量(sign)需要通过MD5(appKey+q+salt+密钥)生成。R语言代码如下:

构建的HTTP 请求指令保存在变量httpClient 当中,其形式如下所示,其含义表示请求有道智云翻译网站将英文“good”翻译成中文。
http://openapi.youdao.com/api?q=good&from=EN&to=zh_CHS&appKey=ff889495-4b45-46d9-8f48-946554334f2a&salt=2&sign=1995882C5064805BC30 A39829B779D7B
第二步,访问网站获取翻译结果。本文应用R 语言的RCurl 包访问网页,返回JSON 格式的结果。将HTTP 请求指令代入RCurl 包的getURL函数即可得到Web 服务器返回的结果,用R 语言表示就是以下一条指令。
URI <- getURL(httpClient)
变量URL 当中存放的是服务器返回的JSON 格式的翻译结果。JSON 是一种轻量级的数据传输格式,能够在多种语言之间进行数据交换,具有简洁和易于使用的特点,在Web 开发中得到广泛应用。JSON 有对象和数组两种主要形式。对象是一个无序的“名称/值”对集合,如图1所示。一个对象以“{”开始,以“}”结束,每个“名称”后跟一个“:”,“名称”使用双引号括起来,名称的每个“值”之间使用“,”将其分隔。数组是值的有序集合,如图2所示。一个数组以“[”开始,以“]”结束,值之间使用“,”将其分隔[4]。

图1 JSON 对象格式

图2 JSON 数组格式

图3 返回的JSON 格式的结果
翻译结果的JSON 格式示例如图3所示。Web 服务器端在处理客户端的HTTP 请求时,将处理结果“序列化” (Serialization),即将对象状态转换为可保持或传输的格式的过程,然后传输到客户端。由于这种序列化的数据格式不便于阅读,所以客户端需要执行“反序列化”操作,这就是接下来的第三步,将“数据流”转换为“数据对象”。
第三步,转换翻译结果。JSON 是JavaScript Object Notation 的缩写,在R 语言环境中可以使用rjson 包中的fromJSON 函数将JSON 文件转换成R 语言的list 对象,指令如下。
obj <- fromJSON(URI)
数据对象obj 是一个包含10 个元素的列表结构,如表2所示。

表2 翻译结果数据对象结构
从表2可见,如果要获取翻译结果,可以直接通过obj$translation 指令操作,其它字段信息可以根据应用需要,有选择性地利用,例如,根据obj$ errorCode 代码处理出错信息等。
本文使用的R 语言版本为R3.4.1,使用到的主要贡献包(package)有4 个:digest 包,通过digest()函数对sign 进行md5 算法加密完成数字签名,数字签名是一种非对称加密的认证模式,其目的是为了让接收方(服务器)确认发送方的信息是否被篡改,这也是服务器常用的一种保证数据安全的方式;RCurl 包,通过包内getURL()函数获取拼接后的URL 地址返回的网页内容,通过这个包可以实现向服务器发送翻译请求后再接收服务器返回的相关数据,该数据内的元素如表2中所示;rjson 包,通过包内fromJSON()函数读取JSON 并解析成R 语言能够识别的list 结构,目的是为了让非结构化数据结构化,再按需对list 对象中的翻译结果、语音朗读等具体内容进行展示。
3 翻译结果测评
机器翻译结果测评就是对给定翻译系统生成译文的质量进行量化的评价,一般分为人工测评与自动测评两类[5]。其中,人工测评是根据测评者的主观判断对翻译结果进行打分,该方法容易操作,也较为成熟,测评结果一般比较准确,但成本较高,周期较长。
人工测评的标准随着机器翻译的发展进步和时间的推移,在描述上产生了一些变化。最早的人工测评可以追溯到1966年,分为“可理解性”和“保真度”两个标准[6-7]。可理解性指的是翻译后内容应使人能够理解,保真度指的是翻译后的内容能够真实还原原意。到90年代后,ARPA 提出了“忠实度”和“流利度”两个标准[6,8],这也是90年代至今都应用较为广泛的人工测评指标[9],忠实度指的是译文是否如实表达原文的意思,流利度指的是语句是否流畅通顺[10]。2000年后也出现过其它一些人工测评标准,但其实质是基于忠实度和流利度两个标准的补充。2010年,LDC(语言学数据协会)制定了以流利程度(fluency)和充分程度(adequacy)为机器翻译人工测评指标[3]。
本文通过R 语言自编函数完成了一批翻译工作,包括ESI 学科分析过程中涉及的150 多个国家或地区的名称,5 465 个机构名称,8 683个研究前沿的翻译,还包括1 万余篇论文题名和摘要的翻译,从各项的翻译结果中随机抽样并按一定标准生成试卷后进行测评。
测评借鉴孙连恒等[11]的方法和测评标准,我们聘请了四位具有博士学位且从教多年的英语教师对翻译结果打分并给出相关评语。实际操作时,针对“国家名称、机构名称、研究前沿、论文题名、论文摘要”等5 个类别,随机抽取翻译结果组成试卷。每张试卷的总分设为100 分,按照题量为4:4:4:4:1,分值为1:1:1:1:4 的比例随机生成。前4 类每一类题量为4,每题5 分,这5 分全部来自充分程度的得分;论文摘要题量为1,每题20 分,这20 分中流利程度和充分程度各占10分。之所以对前4 类只进行充分程度的评分,是因为考虑到这四类的内容都是单词、词组或者名词性短语、非完整句组成,所以对于国家、机构、前沿和题名只做充分程度的测评,对于摘要则进行流利程度和充分程度的测评,具体标准如表3所示。

表3 流利程度和充分程度分值及含义
四位测评员根据以上测评标准,对翻译结果进行人工测评打分。测评过程要求单独进行,且所有内容须在2 小时内完成,测评结果如表4所示。
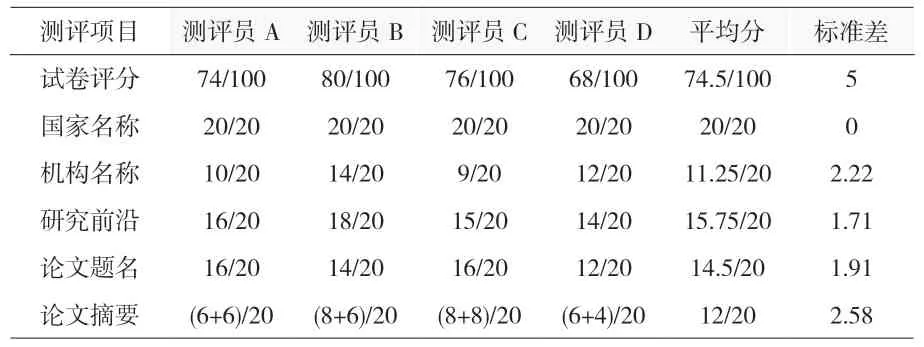
表4 四位测评员的测评结果
表4为四位测评员的测评结果,其中“/”左侧为该项得分,右侧为该项总分。将各项标准差进一步处理,假设每一项总分均为5 分,最大的标准差也仅为0.645,表明各项翻译得分较为稳定。
国家名称、机构名称、研究前沿、论文题名、论文摘要这五项各20 分的翻译内容里,国家、前沿、题名这三项平均得分均大于14.5,单题平均也都都超过了3.6 分,在充分程度上均可以达到基本表达主要意思及以上的效果,尤其是研究前沿的翻译上,单题得分接近4 分,效果最好。而在机构名称的翻译上,有两位测评员给出了12 分以下的分数,最低的一位评测员该项只给出了9 分,平均一题仅得2.25 分,这也是导致平均分低于12 分的原因所在,进而分析这两项得分较低的翻译内容,发现是由于机构名称的缩写所致。
论文摘要得分上,“/”左侧的得分包含了流利程度和充分程度,各占该项总分20 分的一半,得分可以看出充分程度和流利程度差别并不是很大,且充分程度得分均小于流利程度,这和对翻译内容分析后的结果相同,在句子段落的翻译上,有道智云往往是流利度优先,少数情况会出现个别单词的漏译或误译。在平均分上也达到了12 分,平均单题获得3 分,总体达到基本通顺。
接着我们分析了4 位测评员对试卷打分后给出的评语,并对每位测评员的观点进行了总结。测评员A 认为,可以正确翻译摘要中的主要单词和短语,部分单句不符合汉语的语法规则;测评员B 认为,译文可以为科研人员提供辅助性的理解,但与人工翻译仍存在差距;测评员C 认为,根据翻译的基本原则和要求,即忠实原文的基础上可以达到通顺,但倘若用于学术、商业、法律、外教、文化交流等方面的翻译,后期的人工编辑(纠错)非常重要;测评员D 认为,基本通顺,但存在不符合汉语语法规则的单句,句子之间的逻辑关系有待加强。
4 翻译服务在图书馆信息服务中的推广应用
本文是实际工作的总结,用R 语言开发的工具在学科信息、文献检索、科技查新等服务中得到了应用,取得了预期效果,较大的减轻了馆员的人工翻译工作量。
2015年,国家将“双一流”建设写入“十三五”规划,作为高等教育发展的一项重要决策[12]。在遴选一流学科中,ESI 成为一项重要指标,这使得全国高校开始追踪ESI 学科排名,图书馆开展的相关服务工作量显著增加,这其中就包括了ESI 高被引论文题录信息的翻译。由于ESI 每两个月更新一次数据,分析工作呈现出重复性特征,非常适合采取工具软件辅助完成分析任务,以提高工作效率。本文利用R 语言编写的计量分析软件不但可以进行统计分析,还可以对原始文献的相关内容提供翻译,这既能满足学者的学术信息需求,也能满足科研管理部门的宏观信息需求,翻译工具对基于ESI 的学科服务发挥了辅助作用,为高校学科建设和科研活动提供更有价值的参考。
科技查新是我国高校图书馆的一项特色工作,最早可以追溯到1980年[13],其目的是查证科研课题或成果的新颖性[14]。科技查新通常涉及中英文检索,查全率和查准率是其关键指标。查新员经常需要翻译中英文专业术语,还需要大量阅读检索结果,这对图书馆员是一大挑战,目前通常应用“取词翻译”和“划词翻译”工具辅助阅读外文文摘。事实上,可以在科技查新的过程中嵌入翻译工具,自动翻译文摘,提高查新员阅读外文文献的效率。
此外,高校图书馆在定题跟踪、专题报道、科技情报编译等信息咨询服务中,有时也需要提供翻译工作,开发一个翻译工具,有助于提高图书馆信息服务效率和水平。
5 结语
基于4 位测评员的打分和评语,测评员们普遍认为在国家名称、研究前沿、论文题名的翻译上,有道智云在大多数文本翻译上已经达到“信达雅”中“信”的基本水平,尤其是研究前沿等片段性的文本翻译效果最好,满足了图书馆在信息咨询服务中使用机器翻译替代人工翻译提高效能的要求。在摘要这类长文本的翻译上,测评员们认为尽管上下文中还会出现不合乎逻辑顺序的问题,单句也会存在不符合语法规则的情况,但绝大多数情况下可以较好的翻译句中主要单词和短语,在忠实原文的基础上达到基本通顺。这依然表明了片段性文本内容的翻译在目前看来已对机器翻译产生不了大的难度,也证明了有道智云API 提供的翻译功能在图书馆信息咨询中是有价值的,并且在科研工作中也可以提供一定程度上辅助性的帮助。而要达到为科研工作者提供更为有效的帮助,还是建议要把机器翻译和人工翻译结合起来,各取所长,在进行高效的机器翻译后有针对性的对部分内容进行人工校正和润色。同时,本文的研究存在一定局限,仅对英文进行了翻译测试,未开展多语种测试分析,今后可进一步开展其他语种的测试分析。
综上所述,本文既验证了陈江萍[2]提到的文摘翻译仍然存在挑战以及人工打分主观性较高导致了同一标准下得分的一致性较低的情况,又增加了其文中机器翻译没有实现的批量化、自动化的功能。图书馆在提供信息咨询服务时,要翻译的内容存在很大一部分是片段性的文本,诸如关键词、研究前沿、摘要等。R 语言调用有道智云API 所提供的批量化、自助化的翻译服务是可以完成这些工作中的大多数内容,从而也是可以解决信息咨询服务中馆员工作量大、效率低的问题。并且利用R 语言的便利性,可以很方便的对文献数据进行文献计量操作。
机器翻译作为人工智能具体研究方向之一,发展至今依然存在很大的前景和上升空间,随着神经机器翻译等各类相关技术的不断发展,各类方法的不断优化,未来机器翻译可以更加完善,服务更多的用户。
