基于三次指数平滑法和时间卷积网络的云资源预测模型
2019-08-29谢晓兰张征征王建伟程晓春
谢晓兰,张征征,王建伟,程晓春
(1.桂林理工大学广西嵌入式技术与智能系统重点实验室,广西 桂林 541004;2.桂林理工大学信息科学与工程学院,广西 桂林 541004;3.密德萨斯大学计算机科学系,伦敦 NW4 4BT)
1 引言
从2013 年至今,以容器为中心的容器云平台发展迅速。AWS、Azure、阿里云作为三大公有云巨头,面向所有用户提供了类别丰富、服务完善的容器产品,阿里云、腾讯云、百度云、华为云等互联网公司为用户提供了优化的容器服务产品[1-3]。目前,越来越多的互联网公司和社区对容器云技术展开深入研究,根据CNCF 欧洲峰会的调查数据,2017 年容器的使用规模从20%增加到45%。Docker、Kubernetes、cloud native、Kata 和gVisor 等容器云平台的出现,表明容器云技术始终是云计算发展的趋势。基于容器技术的容器云平台可以更轻量级地为应用程序提供构建、发布和运行分布式应用程序的环境,为在其上运行的应用程序按需提供资源,然后根据每个应用程序的资源使用情况向用户收费。
与传统的云计算相比,虽然容器云具有额外资源开销较少、启动时间较短等优点[4],但仍存在过度供应和供应不足的资源管理问题,而且相关文献较少。在过度供应问题中,用户不会受到影响,但过度供应会增加能源浪费,甚至增加网络、冷却、维护等成本。供应不足则会导致服务水平协议(SLA,service level agreement)违约、服务质量(QoS,quality of service)降低,甚至导致用户不满从而使用户流失和收入减少。因此,为用户分配的资源应尽可能地接近用户目前的申请需求。
Kubernetes 作为目前发展比较迅速的容器云代表,为了使Kubernetes 集群能够“预知”部署在其上应用的未来资源使用量,需要为其建立预测模型,然后根据预测值为应用及时、准确、动态地调度和分配资源。本文提出了一种基于三次指数平滑法和时间卷积网络(ES-TCN,exponential smoothing-temporal convolutional network)的云资源预测模型,根据历史数据预测未来的资源需求,与其他预测模型相比,所提模型具有更好的预测性能,对提高资源利用率、降低能耗和成本及按需规划容器资源十分有利。本文的主要贡献如下。
1)提出了一种解决Kubernetes 资源使用量预测的ES-TCN 模型。根据云资源时间序列的特点,设计了一种加权分配策略,为ES 模型和TCN 模型分配不同的权重,从而提高了模型的预测精度、稳定性和泛化能力。
2)使用TPOT(tree-based pipeline optimization tool)调参思想优化TCN 模型的参数组合,一方面减少了模型的训练时间,另一方面为TCN 模型找到了全局最优参数组合。
3)使用Google 数据集对所提模型进行了评价,并与2 种单一预测模型以及现有的其他模型进行了对比实验。
2 相关工作
云资源预测由于潜在和显著的优点,长期以来一直受到研究者的关注。针对云资源预测的不同方面、目标和应用,国内外学者提出了多种预测模型。最初,一些学者提出了基于灰色理论、回归分析等算法的云资源预测模型。灰色理论模型只能描述具有强规律性和较差普遍性的云资源序列,回归分析法虽然可以追踪云资源变化的整体趋势,但不能描述变化的随机性,而且预测误差较大,因此2 种算法都不能对云资源进行很好的预测。
随着云计算领域的迅速发展,云计算数据海量倍增和复杂多变的特性越加凸显,传统的预测模型已经不能满足有效预测云计算资源的需求。得益于机器学习和数据挖掘技术的迅速发展,一些学者提出了基于神经网络[5-6]、隐式马尔可夫[7]、贝叶斯[8]、支持向量机[9-11]等的云资源预测模型,它们可以挖掘云计算资源负荷随机、动态的变化趋势,得到相对理想的云资源预测结果。虽然神经网络具有良好的非线性映射能力,但是它需要的样本量大,而且不同类型的云计算资源的网络结构不同,因此,神经网络预测结果的稳定性较差。此外,神经网络阈值和权重的计算采用梯度下降的方式,具有收敛速度慢、容易陷入局部最优解等不足,降低了预测精度。文献[12]提出了一种贝叶斯模型,该模型用于预测CPU/内存密集型应用程序的短期和长期虚拟资源需求。与其他模型相比,贝叶斯模型能够更好地预测云环境中的虚拟资源。贝叶斯模型的优点是能够全面识别虚拟化云场景中变量之间的依赖关系,缺点是没有考虑几种应用程序类型的组合,而且它只适合特定的问题。支持向量机预测结果更加稳定、可靠,但其参数对云计算资源预测结果影响较大。
有研究表明,云计算的资源序列与时间高度相关[13],因此一些学者将云资源序列看作一个时间序列,并使用时间序列预测算法对云资源进行研究。时间序列预测算法是基于时间序列的历史信息来完成预测,它的基本思想是从现有的序列数据中发现某种隐含的规则来预测序列的未来趋势。由于能够更好地挖掘事物发展规律与时间的关系,基于时间序列的预测模型已广泛用于金融、交通等领域。
针对时间序列预测问题,国内外相关学者已经开展了一些研究。最初,人们使用布朗提出的指数平滑、自回归移动平均(ARIMA,auto regressive integrated moving average)等算法进行建模[14-15]。ES 使用加权平滑系数在时间序列模型中通过上一期预测值与真实值的加权平均得到下一期的预测值,ES 不需要像ARIMA 那样去进行复杂的数据预处理,它的参数选择可以通过交叉验证直接实现。同时,它只需要上期的预测值与观测值,不需要大量的数据计算,因此建模速度非常快,但主要针对小规模的资源预测问题。随着资源规模的增大,ES的预测性能也随之下降,无法很好地拟合数据,而且云资源的变化具有动态性和时变性,因此ES 和ARIMA 无法满足云用户的各种需求。近年来,时间序列预测在越来越多的应用领域中成为最佳预测方法。文献[16]应用非线性时间序列方法提出了一种网络传播行为预测模型,并用粒子群优化算法对模型参数取优,结果表明,短期内该模型能够对网络传播行为做出准确预测。文献[17]针对流量数据具有高度的非线性和复杂性,现有的预测方法大多不能很好地捕获数据的时空相关性的问题,因此提出了一种新颖的基于深度学习的多组件时空图卷积网络(MCSTGCN,multi-component spatial-temporal graph convolution network),以解决交通流量预测问题,结果表明,MCSTGCN 模型的预测效果优于现有的预测方法。文献[18]针对目前民航运输业对机场延误预测高精度的要求,提出了一种基于区域残差和长短时记忆(RR-LSTM,regional residual and long term memory network)网络的机场延误预测模型。实验结果表明,RR-LSTM 网络模型预测准确率可达95.52%,取得了比传统网络模型更好的预测效果。
循环神经网络(RNN,recurrent neural network)及其变体长短时记忆(LSTM,long short term memory)网络一直被认为是时序预测领域的最佳算法,然而,文献[19]提出了一种可用于解决时间序列预测的新算法——时间卷积网络(TCN,temporal convolutional network),并在文中对TCN 和循环网络进行了系统的评估。结果表明,TCN 在不同任务和数据集上的性能优于典型的循环网络(如LSTM)。而且TCN 提出后在学术界引起了巨大的反响,许多原来使用RNN 的领域都转而使用TCN。因此,一些学者认为TCN 将取代RNN 的地位。
尽管LSTM、TCN 等时序预测模型的预测效果要远远优于以往的预测模型,然而,面对复杂多变的云计算资源,只用单一模型很难达到期望的预测效果。大量实际研究结果表明,结合各种单一模型的优势构建合理的组合优化预测模型,可以更准确、全面地描述具有复杂性、非线性、动态性特点的云资源使用量情况,显著提升预测模型的预测精度和预测性能[20-25]。
目前,有许多组合模型可用于云资源预测。文献[26]提出了一种结合线性和非线性的动态组合预测模型来预测云资源的CPU 负载。该模型的优点是可以动态调整预测器以适应时间模式序列。然而,它并不一定保证能准确地预测各种时间序列的未来值,而且无法集成同构或异构模型。文献[27]提出了一种组合预测模型,用于预测未来云计算环境中虚拟机(VM,virtual machine)资源、基础设施和服务水平的能源效率状况。该模型的优点是适合根据云计算趋势预测云系统的能耗,缺点是准确性取决于工作负载类型,性能与应用的组合模型中的每个单一预测模型高度相关。文献[28]提出了一种使用遗传算法来结合多个模型的自适应预测方法。更准确地说,该方法是结合不同时间序列预测模型的预测值进行预测,然后采用遗传算法对每个组成模型分配一个值,即每个组成模型的比例,这些值的总和必须为1。该模型的优点是在使用前不需要训练,它独立于其组合预测模型,而且易于扩展其预测模型的数量,然而时间复杂度太高。文献[29]针对在部署过程中对重要的资源使用预测对于实现科学应用的最优调度至关重要,现有的云资源预测模型针对云度量的高方差而不能提供合理的精度的情况提出了一种集特征选择和资源利用预测技术于一体的智能回归集成预测方法,对未来的资源需求进行准确的预测以实现资源的自动配置。虽然预测结果在各衡量指标表现很好,但该方法仅对CPU 的使用量进行了预测,对其他资源可能存在不通用的情况。
虽然目前有许多组合模型可用于云资源预测,更深层次的是每个预测模型具有不同的性能,并且在预测某些指标方面是有效的,而在其他指标中则可能非常不准确。虽然在组合模型中将这些模型视为组成模型可能是合适的,但它在提高组合模型某一性能的同时也可能导致其他性能变差。基于此,本文提出了ES-TCN 模型,该模型通过给单个预测模型赋予权重得到组合模型的预测值。
3 ES-TCN 模型
指数平滑法对不同时间数据的非等权处理较符合实际情况,在实际应用中仅需选择一个模型参数即可进行预测,简便易行,而且预测模型能自动识别数据模式的变化并对其进行调整,具有适应性,但对数据的转折点不能很好地预测,长期预测的效果较差,故多用于短期预测。在TCN 中可以进行大规模并行处理,网络训练和验证的时间都会变短。TCN 的反向传播路径和序列的时间方向不同,这避免了RNN 中经常出现的梯度爆炸或梯度消失问题。TCN 训练时需要的内存更少,尤其是对于长输入序列。但是TCN 在预测时需要在内存中存储足够长的原始输入信息,以保证能获取到历史信息,且在不同领域的超参数(如i和d)可能不同,因此在迁移模型时需要调整这些参数。
针对此,本文提出了ES-TCN 云资源预测模型,并根据云资源时间序列的特点,设计了一种加权分配策略,为ES 模型和TCN 模型分配不同的权重,从而提高了模型的预测精度、稳定性和泛化能力。ES-TCN 模型的计算式为

其中,Yt表示最终的预测值,Et表示ES 模型得到的预测值,Nt表示TCN 模型得到的预测值,ω1+ω2=1。
一次指数平滑法常用于没有明显函数规律但确实存在某种前后关联的时间序列,线性时间序列通常使用二次指数平滑法,当时间序列的变动呈现出二次曲线趋势时,常使用三次指数平滑法,因此通过分析云资源时间序列的特点,本文使用三次指数平滑法。由于高次的指数平滑法是在低次的指数平滑法的基础上建立的,例如,二次指数平滑法是建立在一次指数平滑法基础之上的,所预测的效果也优于一次指数平滑法;三次指数平滑法是在二次指数平滑法基础之上再进行一次平滑,因此设Kubernetes 的资源使用量的值为{kt}(t=1,2,3,...),依次计算第t时刻不同次数的指数平滑法,并将得到的预测值分别记为各指数平滑法计算式为

其中,表示三次指数平滑法得到的预测值,即式(1)所述的Et。在指数平滑算法中,α的取值是决定最终预测结果的关键。一般情况下,α取值范围为0~1,根据经验,通常在0.10~0.80 范围内取值[30]。α的取值一旦固定就不能修改其加权系数。通常情况下,α取较小值时,预测模型的平滑能力较强;α取较大值时,模型对时间序列的变化反应速度较快。不同情况下的α取值如表1 所示。

表1 α 值的适用情况
用yt表示TCN 模型得到的预测值,即式(1)所述的Nt。yt的求解计算式如式(5)~式(7)所示。
作为一种特殊类型的一维卷积网络(1D CNN,one-dimensional convolutional neural network),TCN是对序列信息进行编码的一种自然方法[31]。一个普通的一维卷积层可以写成

其中,k为输入序列,y为输出序列,f∈Rid为大小为i的卷积滤波器。然后将几个普通的一维卷积层叠加起来构成1D CNN。然而,1D CNN 在应用于模型序列时会受输出尺寸大小和接收域的限制,因此,TCN使用因果卷积(causal convolution)和空洞卷积(dilated convolution)2 种技术来解决这些问题。
1)因果卷积。如式(5)所示,普通一维卷积层将长度为n的序列作为输入,并输出长度为n-i+1的序列。如果将更多这样的层堆叠在一起,则可以进一步缩小误差。因为本文希望所提模型在每个时间步长进行预测并实时更新它们,这个属性在本文的域中可能会有问题。因果卷积层通过在输入序列的开头填充长度为i-1 的零来解决这个问题。此外,它能确保没有未来的信息泄露到过去,这是预测未来交互的关键。它确保了输出序列y在每个时间步长上被很好地定义,并且预测值yt仅取决于输入k≤t。计算式为

2)空洞卷积。CNN 通常都是可以被反向训练的,但是如果使用过多的历史信息就会导致CNN的深度增大,当CNN 的深度增大到一定程度时就需要一种新的办法来解决反向训练的问题。TCN 使用空洞卷积来解决普通1D CNN 的接收域与层数呈线性关系的问题。空洞卷积是一种技术,它允许接收域与层数呈指数关系。具体地,当与因果卷积结合时,第r层空洞卷积可以表示为
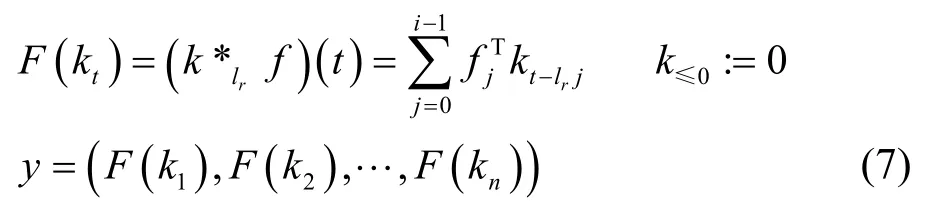
其中,lr是扩张因子,可以设定为(i-1)r-1,以实现指数大的感受野。式(7)为时间卷积层,通过堆叠多个时间卷积层来构造TCN。为了便于训练深度TCN,通常的做法是将时间卷积层组织成块,并在块之间添加残差连接[32]。通过设置合适的滤波器大小和层数,yt+1可以依赖于整个历史交互作用。
模型的参数决定了最终预测的结果,因此参数的选取至关重要。TCN 作为神经网络的一种,调参占了很大一部分工作比例,而且训练一次TCN 需要很长的时间,因此如何正确地、快速地调参十分重要。本文使用TPOT 调参思想对TCN 调参,既保证了模型的最终预测效果,又减少了调参的工作量,从而缩短了整个模型训练的时间。TPOT 是一种优化机器学习模型和自动选择模型参数的工具[33],也是自动化机器学习(AML,automatic machine learning)的一种应用,能够自动执行机器学习问题中的重复步骤,从而节省时间。同时,TPOT 也是网格搜索的扩展,提供了如遗传算法这样的应用,可用来在某个配置中调节各个参数并达到最佳设置。
4 实验结果及分析
4.1 实验参数及数据集
本文使用Google 数据集检验ES-CTN 模型的有效性,该数据集记录了Google 云计算中心大量任务的提交、调度、更新、结束事件及CPU、内存、带宽等资源需求和使用记录,是云计算的重要研究资源。考虑到目前Kubernetes 主要是对CPU 和内存资源进行分配和调度,因此本文只对CPU 和内存资源进行研究。但是本文提出的模型并不局限于对CPU和内存资源的预测,也可以用于预测其他资源。
由于Google 数据集的数据量庞大,使数据处理工作量大、耗时长,本文先对数据集进行处理,提取和过滤数据后将其保存为CSV 文件,再将CSV文件读入Spyder 中进行实验。由于本文提出的ES-TCN 模型的预测结果是基于ES 和TCN 的预测结果的,对于寻找ES-TCN 模型的权重,可以通过遍历权重的方式实现。具体如下:设ES 的权重ω1初始值为1,因为ω1+ω2=1,则TCN的初始权重ω2为1-ω1=0,令ω1每次以步长为0.01 的递减方式进行迭代,计算ES-TCN 模型的MAE,最终从所有遍历的结果中取出最小的MAE 对应的迭代次数,从而得到权重ω1和ω2。本文的实验参数设置如表2 所示。

表2 实验参数
由于是对云资源时间序列进行预测,因此,要保证数据的准确性和完整性,数据必须按照一定的时间顺序排列,不能出现时间序列混乱的情况。本文使用的数据集缺失值较少,因此使用简单的均值插补法对缺失值进行处理。此外,本文还对数据进行了归一化处理。
4.2 预测性能对比
本文的研究工作是在ES 和TCN 模型的基础上进行的,并进行了适当的优化,因此,本文选取了ES 和TCN 这2 种模型与本文提出的ES-TCN模型进行对比。不同模型的部分比较结果分别如图1 和图2 所示。

图1 3 种模型的CPU 预测性能对比结果

图2 3 种模型的内存预测性能对比结果
虽然从图1 和图2 中可以看出ES-TCN 模型比其他2 种模型好,但图中展示的结果仍然不够明显。为了更清楚地看到结果,本文在实验时将console中的Graphics 设置成Qt5,通过Qt5 自带的放大功能对预测结果进行了细微比较,得到ES 模型在云资源规模较小时建模速度较快,且预测比较准确,但随着云资源规模的增大,预测精度迅速下降,不能很好地满足Kubernetes 资源使用量预测需求。这是因为ES 赋予远期较小、近期较大的比重,所以只能进行短期预测。TCN 模型虽然总体预测效果较好,但不稳定,这是因为虽然TCN 具有良好的非线性映射能力,但是它在预测时需要在内存中存储足够长的原始输入信息以保证能获取到历史信息,因此,TCN 的稳定性较差。本文提出的ES-TCN 模型虽然能比较好地追踪真实数据,预测效果也比较稳定,但是在波动变化较大时,预测误差比较明显,但与其他2 种模型相比,这个预测误差相对较小。这是因为本文提出的模型结合了ES 模型能自动识别数据模式的变化并对其进行调整,具有良好的适应性和TCN 使用因果卷积、空洞卷积可以进一步缩小误差的优点,同时采用TPOT 调参思想快速地为TCN 模型找到模型参数的最优组合,提高了预测模型的准确度和稳定性及泛化能力。
4.3 预测误差对比
为了进一步说明实验结果,本文选取了常用的4 种合适的度量标准:平均绝对误差(MAE,mean absolute error)、平均绝对百分比误差(MAPE,mean absolute percentage error)、均方根误差(RMSE,root mean square error)和平均绝对比例误差(MASE,mean absolute scaled error),用来对比模型性能。
由于MAE 的离差被绝对值化,不会出现正负相抵消的情况,因此MAE 能更好地反映预测误差的实际情况。MAE 的计算式为

如果一直让预测值远大于真实值会造成实际的资源利用率很低,使分配的资源大量闲置。因此,引入MAPE 来避免发生预测值无限大于真实值的情况,从而避免资源浪费。MAPE 的计算式为
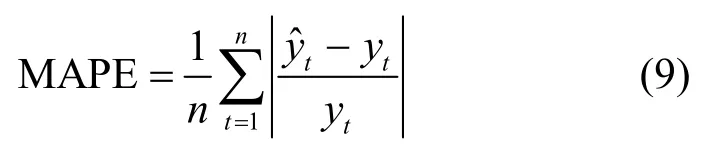
RMSE 代表预测值和观察值的样本标准差,主要用来聚集预测误差的大小,通常在不同的时间下,以一个量值来表现其预测的能力。RMSE 的计算式为
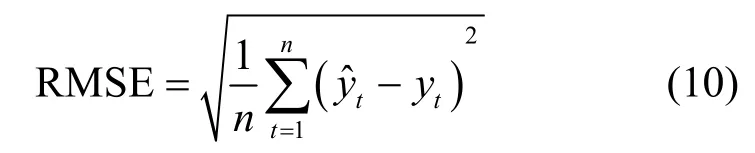
MASE 是针对所有值定义的归一化统计量,并且同等地对误差进行加权,因此它是用于比较不同预测模型质量的一个很好的指标。MASE 的计算式为

上述4 种度量标准中,yt是真实值,是预测值,n是时间序列长度,而且这4 种度量标准的值越接近0,表明真实值与预测值之间的误差越小,预测模型的性能越好。3 种预测模型的性能对比统计结果如图3 所示。为了方便比较,首先对CPU和内存这2 种资源进行了归一化处理。
此外,本文还将提出的 ES-TCN 模型与ARIMA、RNN、LSTM 进行了对比实验,实验结果表明,与ARIMA 模型相比,ES-TCN 模型不需要进行复杂的数据预处理;与RNN 模型相比,ES-TCN模型避免了RNN 中经常出现的梯度爆炸或梯度消失问题;与LSTM 模型相比,ES-TCN 模型可以进行大规模并行处理,网络训练和验证的时间都会变短,因此计算成本更低。
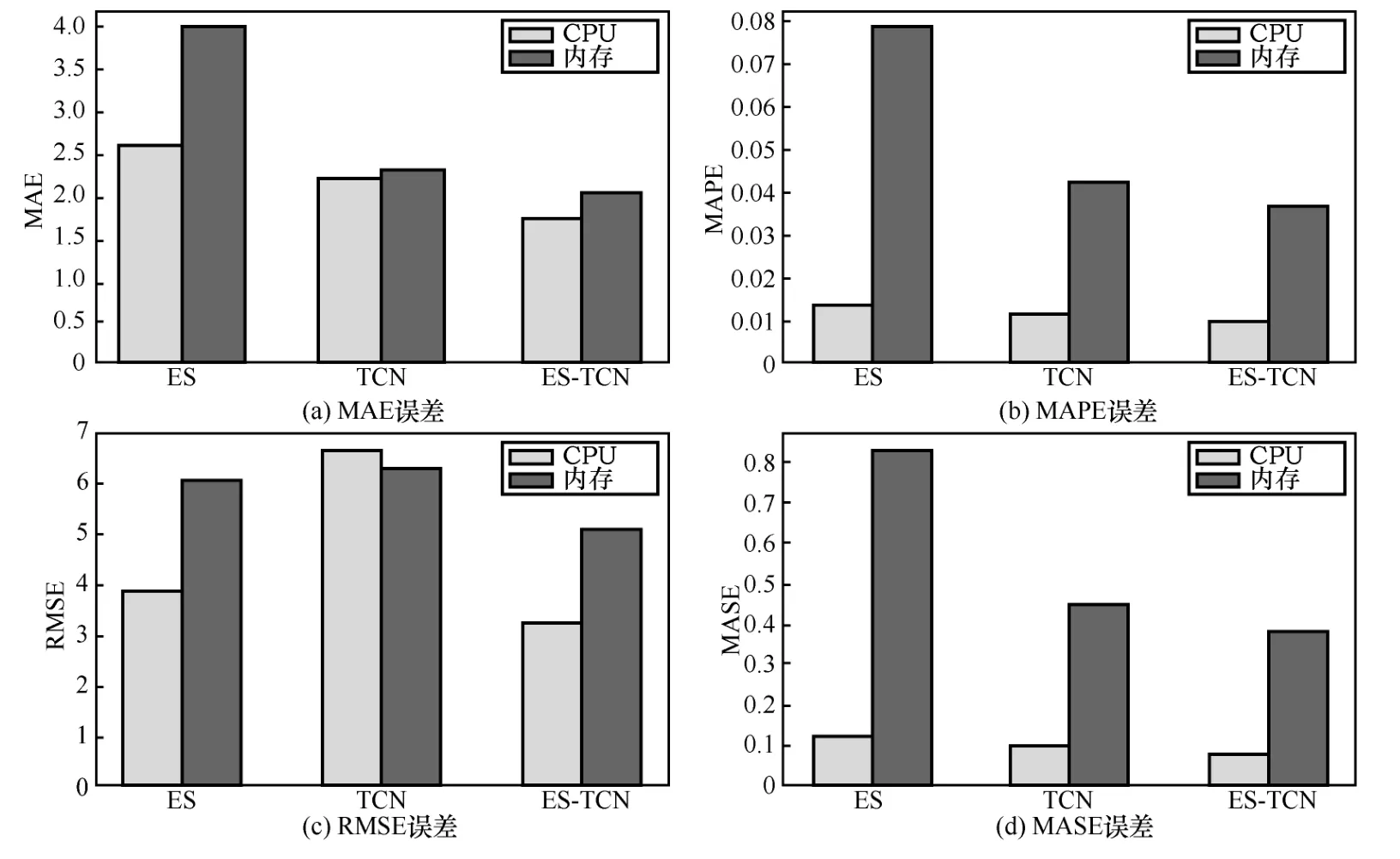
图3 3 种预测模型的性能对比统计结果
5 结束语
本文提出了一种新的云资源时间序列预测模型用来对部署在Kubernetes 上的应用未来的资源(CPU 和内存)使用量进行预测,该模型结合了ES和TCN,不仅提高了模型的泛化能力,还提高了模型的预测精度和稳定性。采用TPOT 调参思想对参数进行优化,快速地为TCN 模型找到模型参数的最优组合,在节省了模型训练时间、大大减少了工作量的同时,进一步提高了模型的预测性能。
为了验证本文提出的模型的预测效果,选取了Google 云计算中心数据集的CPU 和内存资源,并与2 种单一预测模型以及其他模型进行了对比实验。同时,使用4 种常用的标准指标用于比较模型的性能。实验结果表明,与其他模型相比,本文提出的模型具有更高的预测精度、稳定性和泛化能力,进一步完善了Kubernetes,能够有效提高资源利用率,有利于容器资源的按需规划。
