基于图标相似性分析的恶意代码检测方法
2019-08-27杨萍赵冰舒辉
杨萍 赵冰 舒辉

摘 要:据统计,在大量的恶意代码中,有相当大的一部分属于诱骗型的恶意代码,它们通常使用与常用软件相似的图标来伪装自己,通过诱骗点击达到传播和攻击的目的。针对这类诱骗型的恶意代码,鉴于传统的基于代码和行为特征的恶意代码检测方法存在的效率低、代价高等问题,提出了一种新的恶意代码检测方法。首先,提取可移植的执行体(PE)文件图标资源信息并利用图像哈希算法进行图标相似性分析;然后,提取PE文件导入表信息并利用模糊哈希算法进行行为相似性分析;最后,采用聚类和局部敏感哈希的算法进行图标匹配,设计并实现了一个轻量级的恶意代码快速检测工具。实验结果表明,该工具对恶意代码具有很好的检测效果。
关键词:图标相似性;哈希算法;导入表比对;局部敏感哈希;恶意代码检测
中图分类号: TP309
文献标志码:A
Abstract: According to statistics, a large part of large amount of malicious codes belong to deceptive malicious codes. They usually use icons which are similar to those icons commonly used softwares to disguise themselves and deceive users to click to achieve the purpose of communication and attack. Aiming at solving the problems of low efficiency and high cost of traditional malicious code detection methods based on code and behavior characteristics on the deceptive malicious codes, a new malicious code detection method was proposed. Firstly, Portable Executable (PE) file icon resource information was extracted and icon similarity analysis was performed by image hash algorithm. Then, the PE file import table information was extracted and a fuzzy hash algorithm was used for behavior similarity analysis. Finally, clustering and local sensitive hash algorithms were adopted to realize icon matching, designing and implementing a lightweight and rapid malicious code detection tool. The experimental results show that the designed tool has a good detection effect on malicious code.
Key words: icon similarity; hash algorithm; import table comparison; local sensitive hash; malicious code detection
0 引言
随着互联网的迅猛发展,娱乐、办公等应用软件不断增长的同时,也出现了许多恶意代码,这些恶意代码在互联网上传播十分迅速,且危害性极大。比如,勒索病毒是一种近年来愈发流行的恶意代码,这些病毒会加密锁定被感染的计算机上的用户资源和资产,要求受害者支付赎金后才提供解密服务,否则相关资源将永远无法恢复。据统计,在大量的恶意代码中,有相当大的一部分属于诱骗型的恶意代码,其通常使用与WORD等常用软件相似的图标来简单地伪装自己,进而诱骗用户去点击。在点击运行之后,此类恶意代码则进行一系列的窃密、勒索等操作,使用户的信息资产面临严重的风险。因此,开展基于图标相似性分析的恶意代码检测方法的研究,对于恶意代码的检测工作具有重要的现实意义。
恶意代码[1]也称为恶意软件,是指运行在计算机上,使系统按照攻击者意愿执行任务的一组指令。传统的恶意代码分析方法[2-3]主要分为静态分析方法和动态分析方法。静态分析方法是指在不执行程序的情况下,对程序进行反汇编、反编译等,然后再进行分析,分析方法主要有静态源代码分析、静态反汇编分析、反编译分析;动态分析方法是指利用程序调试工具对恶意代码进行跟踪,观察恶意代码执行过程,剖析恶意代码的工作机理并验证静态分析结果,分析方法主要有系统调用行为分析方法和启发式扫描技术。但是,传统的基于代码和行为特征的恶意代码检测方法往往需要经过繁琐的步骤,耗费大量的时间才能达到较好的效果。
本文主要针对此类诱骗型的恶意代码展开研究,鉴于传统的基于代码和行为特征的恶意代码检测方法所存在的效率低、代价高等问题,提出了一种新的恶意代码检测方法,在图标资源相似性分析和导入表相似性分析的恶意代码检测方法结合的基礎上,采用聚类和局部敏感哈希的算法进行图标匹配,设计并实现了一个轻量级的恶意代码快速检测工具。
1 相关工作
近年来,在恶意代码检测领域提出了一种基于图标相似性分析的新思路。Silva等[4]提出了一种利用机器学习的方法,从图标中提取信息来提高检测恶意代码检测的精度。该方法包括两个步骤:1)提取图标特征使用汇总统计(Summary Statistics) [5]、方向梯度直方图(Histogram Of Gradient, HOG)[6]和一个卷积自动编码器[7];2)根据提取的图标特征对图标进行聚类。通过机器学习的方法对公开的数据进行了大量的实验,实验结果表明该方法可以显著地提高恶意软件预测模型的有效性。实验表明,在预测模型中使用图标簇时,平均精度增加了10%,但并未给出一种有效的行为分析方法。文献[8]提出了一种基于应用程序图标的移动终端恶意代码检测方法及系统,具体步骤是:首先,对应用程序的安装包进行分析,将该应用程序的图标提取出;然后,从该应用程序代码文件中提取系统应用程序编程接口 (Application Programming Interface, API)函数,将该应用程序的图标与应用图标功能规则库相对应,从而检索到与此图标对应的功能规则,将该应用程序调用的API函数与该图标对应的功能规则相比对,如果一致,则为正常的应用程序,否则为恶意的应用程序。但是,该项技术尚不成熟,并未得到普及。该思路的创新点在于从图标出发,利用了恶意代码使用与正常软件相似的图标来伪装自己的这一特征,进行恶意代码检测,极大地提高了恶意代码检测效率和精度。然而,现阶段基于图标相似性分析的恶意代码检测相关研究成果较少,无论是研究的深度还是广度都有待于进一步提升。
本文主要采用了图像哈希算法进行图标相似性比对。目前,图像的匹配算法[9]主要包括三类:基于灰度相关的匹配方法[10]、基于特征的匹配方法[11]和基于模型的匹配方法[12]。随着互联网上图片的泛滥,一种快速和有效的图像匹配技术显得愈发重要。在20世纪90年代末,图像哈希[13]技术诞生了。该方法广泛应用于“以图识图”的图像检索技术中,且国内外许多搜索引擎都使用了这项技术,如Google、百度等。另外,在行为相似性比对方面,采用模糊哈希[14-15]的方法进行导入表比对。它是一种快速、准确、实用的行为分析方法,目前在恶意代码检测方面取得了很好的效果。与传统的基于代码和行为特征的方法相比,模糊哈希效率更高,它能快速地发现两个可移植的执行体 (Portable Executable, PE)文件的相似关系并计算其相似度;与传统的单纯API序列比较的方法相比,模糊哈希算法更为精确,它是计算两个序列之间的相似度,某一位的改变都能给出一个准确的数值。随着检测工具常规图标库的不断扩大,为了避免图标的逐一比对,采用聚类[16]和局部敏感哈希[17]结合的算法对常用图标库进行分类、管理来提高图标匹配速度和检测工具的效率。
因此,本文的主要工作包括:1)解析PE文件结构,从PE文件中提取图标资源和导入表信息;2)研究各种图像相似性比对算法的原理与特点,通过设计并进行实验,选取dhash(difference hashing)算法作为本文图标相似性比对的算法;3)采用基于内容分割的模糊哈希算法对两个PE文件的导入表信息进行相似性比对;4)设计并实现了一个轻量级的恶意代码检测工具,该工具由样本信息提取模块、常规信息库和恶意代码检测模块构成,并通过对样例的测试与分析,验证了该工具的有效性。
2 基于图标相似性分析的恶意代码检测方法
本文旨在设计并实现一种轻量级的恶意代码快速识别工具。因此,首先通过实验验证,选取dhash算法作为本文的图标相似性比对算法,其次,采用模糊哈希算法对提取的导入表信息进行比对。
2.1 总体思路
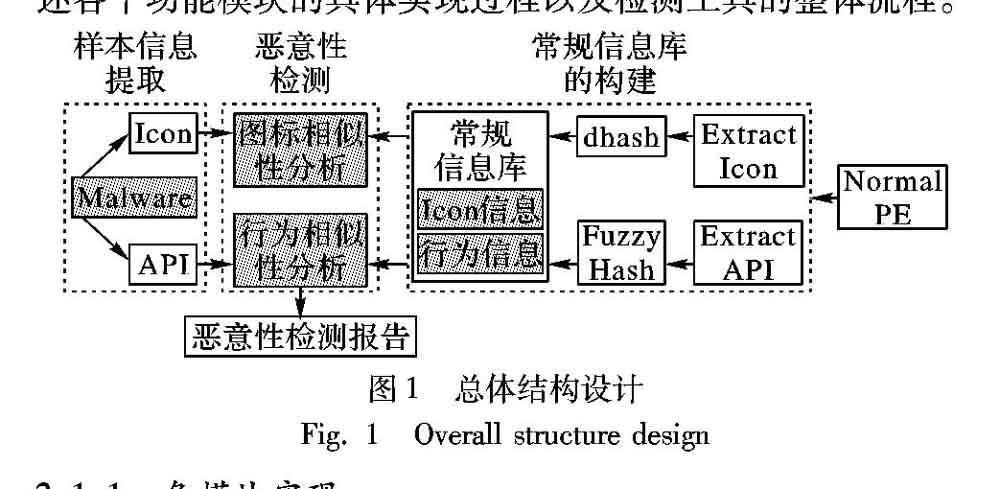
检测工具的总体设计思路如图1所示,从总体上包含三大模块:样本信息提取模块、常规信息库的构建,以及恶意性检测模块。整个检测工具采用python语言实现,下面分别阐述各个功能模块的具体实现过程以及检测工具的整体流程。
2.1.1 各模块实现
样本信息提取模块对传入的待测样本进行PE结构解析,提取出其图标资源信息与导入表中的API函数信息,作为下一步恶意性检测的信息输入。在实现过程中,本文采用python的第三方模块Pefile对PE结构进行解析,在此基础上提取出所需信息。图标资源的提取过程封装为ExtractIcon类,导入表信息的提取直接封装为GetPEIAT函数。
常规信息库是指图标dhash特征值与API模糊哈希特征值所构成的库,是恶意性检测的信息参照。具体构建流程如下:1)收集Windows平台下常用软件的可执行程序,包括WORD.exe、QQ.exe和Chrome.exe等,其中WORD等应用程序的图标在恶意代码中应用极为广泛,对普通用户而言具有极强的诱骗性。2)对10万个常规软件,首先进行图标资源信息和导入表API信息的提取,提取的方式与样本信息提取模块的功能设计相同。3)利用dhash计算各图标资源的图标哈希值,利用模糊哈希算法计算各导入表API的模糊哈希值,并按照〈文件名称,图标哈希值,导入表模糊哈希值〉的结构组织成信息库,常规信息库采用简单的文本方式存储。
图标资源的哈希值计算在PE文件解析的基础上,采用python的第三方模塊imagehash完成,imagehash提供了ahash(average hashing)、dhash、whash(wavelet hashing)等多种哈希函数功能接口,能够快速地完成所需功能。导入表的提取以PE文件解析为基础,提取出导入表信息存为文本文件后,采用python第三方模块ssdeep,通过其接口函数ssdeep.hash_from_file(file_path)能够直接完成对特定文件的模糊哈希计算。
恶意性检测模块以常规信息库为依据,对输入的待测样本信息分别进行图标相似性分析和行为相似性分析,并输出对样本恶意性的判定结果。
2.1.2 整体流程
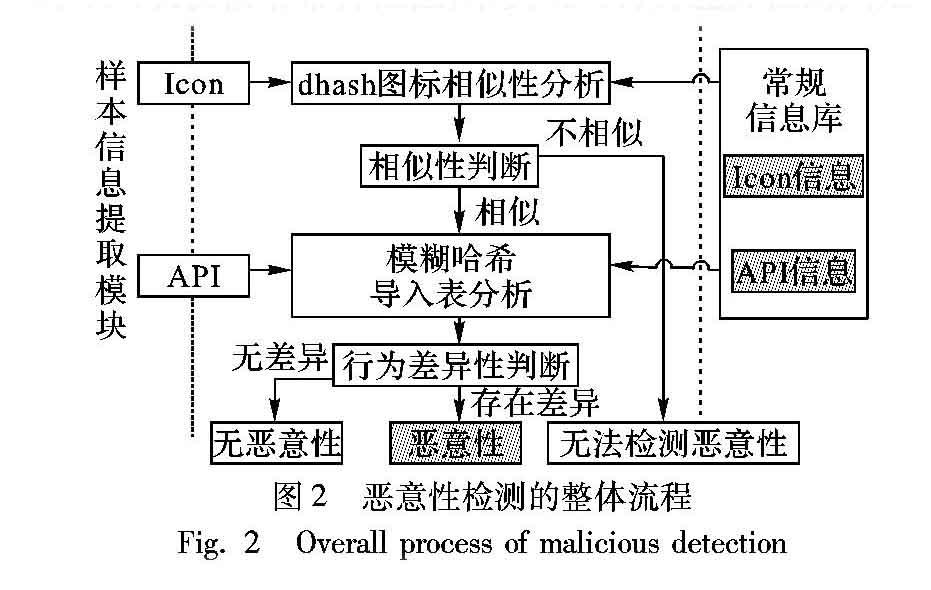
恶意性检测的整体流程如图2所示。
对提取的样本图标信息进行dhash相似性分析,从常规信息库中检索是否存在与之相似的常规软件,相似性判定的方式为比较两个dhash数值间的汉明距离。本文中汉明距离的阈值IconHashThreshold设定为10,即在汉明距离小于等于10条件下,两个图标是相似的,汉明距离超过10则认为两个图标是不相似的。
当判定样本图标与常规信息库中某个常规软件的图标不相似时,则认为无法检测该样本的恶意性;如果存在相似性,则进一步进行导入表相似性分析,通过比较样本与该常规软件的导入表模糊哈希特征值,来实现对行为差异性的判定。
2.2 主要方法
2.2.1 图标相似性比对方法
ahash[18],即平均哈希算法。一张图片包含高频和低频的部分,对处理后的灰度图像计算平均值。phash(perception hashing)[18],即感知哈希算法。phash算法利用的是离散余弦变换(Discrete Cosine Transform, DCT)。ahash算法太过严格,比较适合搜索缩略图,在实际图像比对中不如phash算法精确。dhash[18],即差异哈希算法。dhash算法在相邻像素之间起作用,并在比较左侧和右侧两个像素的亮度后对整个图像进行采样。此算法的具体步骤是:首先,将图片缩小为9×8,72个像素值;其次,将其转化为灰度图,将缩放后的图片转换为256阶灰度;然后,计算平均值,再计算每一行中左右两个像素的差值,每行8个,共8行生成64个值;随后,得到信息指纹,如果左边的像素比右边的像素亮,则记为1,否则为0;最后,计算两张图片形成指纹的汉明距离,即可得知它们相似度。whash[18],即小波散列哈希算法。whash将phash的DCT替换为离散小波变换 (Discrete Wavelet Transform, DWT)。DWT是在傅里叶变换的基础上发展起来的,它是一种空间或时间和频率之间的局部变换,通过放大、缩小和移动等变换可对所得数据进行多尺度的细节分析,所以能够从数据中提取有效信息。
2.2.2 行为相似性比对方法
在行为相似性比对中,采用模糊哈希的方法。模糊哈希算法是一种简单、快速的行为分析方法,已被广泛用于以简单识别为目的的领域。一般的哈希算法具有精确匹配的特性,无法判断内容稍有不同的同类文件,这对于恶意代码检测是非常不利的。模糊哈希算法与模糊逻辑搜索很像,它可以寻找相似但不完全相同的文件,即所谓的同源性文件。模糊哈希的原理是先对文件进行分块,计算每一块的哈希值,然后将得到的一系列的哈希值利用比较函数与其他哈希值进行比较,来确定相似程度,因此,仅仅某一部分变化了只会导致某一或几个分块的哈希值发生变化,而其他分块的哈希值不发生变化。模糊哈希的算法的主要步骤:首先,使用一个弱哈希计算文件的局部内容,在特定条件下对文件进行分析;其次,使用一个强哈希对文件每片计算哈希值;然后,将这些值连接起来,与分片一起构成一个模糊哈希值;最后,使用一个字符串相似性比对算法判断两个模糊哈希值的相似度。
在本文中,利用模糊哈希的方法快速比对导入表的相似度,具体实现方法是先将PE文件的导入表信息提取出来,再将导入表信息按首字母排序后生成两个文本文件,计算两个文本文件的模糊哈希值,最后利用ssdeep提供的compare函數计算匹配度,即两个PE文件导入表的相似度。为验证此方法的有效性,实验设计如下:
但是,在实际情况中,进行行为相似性比对时会遇到诸多问题。面对一些特殊情况的样本,如一些压缩自解压文件,压缩后会表现出来一些压缩软件的图标,对于这类样本,本工具可能存在误判问题。设计了如下实验,将pycharm、QQ、Wechat、WORD通过WinRAR创建它们的自解压文件,如图5所示。常规信息库如表4所示,将它们作为测试样本输入工具进行测试,测试结果为四个自解压文件均具有恶意性。自解压过程使得四个文件的导入表信息完全相同,如表5所示。这也引出了一个新的问题,对于一些自解压文件或者加壳的文件,在检测前需要对样本进行预处理如脱壳使之成为普通样本,然后进行检测,这也是下一步工作研究的内容之一。表6为QQ.sfx样本的检测过程信息。
大多数软件都存在不同版本的现象,比如当对使用WORD图标的软件进行检测时,即使该软件是正常软件,但由于其版本与常规信息库中的WORD版本不一致,因而导致误判。由于不同版本的正常软件行为存在差异,于是进行如下研究。以下是对WORD各版本进行导入表提取,观察API函数调用情况并采用模糊哈希计算相似度。实验结果表明,以上各种版本WORD.exe的导入表API在内容与数量上均差异不大,这也意味着两者在功能、行为上很相似。但是,不同版本WORD导入表信息所计算出模糊哈希值的相似度并不高,如表7所示。于是,针对正常软件多版本的引起的误判问题,本文采取以下解决方案。首先,在常规信息库的收集过程中,尽可能收集同一软件的多个版本。然后,在图标相似性达到要求的情况下,进行导入表相似性比对,只要与其中一个版本的导入表相似度达到60,就认为该输入软件为正常软件;如果与所有版本的导入表相似低于60,则认为该软件为恶意软件。
2.3 基于LSH的图标相似性匹配算法
2.3.1 算法基本思想
随着检测工具图标库的不断扩大,每当检测恶意样本时,如果将图标与图标库的所有图标进行逐一比对,效率非常低。LSH(Locality Sensitive Hashing)实现了快速地从海量的高维数据集合中找到与某个数据最相似的一个数据或多个数据,是一种针对海量高维数据的快速最近邻查找算法,非常适合对种类繁多且海量的图标进行相似性比对。为了提高检测工具的效率,采用K-means算法[19]对图标进行聚类[17],形成一个高维向量作为一个dhash值的描述,然后利用局部敏感哈希算法进行索引查询,实现对检测工具图标库进行分类、管理,从而提高图标的匹配速度,进而提高检测工具的检测效率。
表格(有表名)
表7 不同版本WORD的模糊哈希相似度
Tab. 7 Fuzzy hash similarity of different versions of WORD
版本2012201420152016
2012100715441
2014—1005841
2015——10047
2016———100
定义1 局部敏感哈希[18]。将一族hash函数H={h:S→U}称为是(r1,r2,p1,p2)敏感的,如果对于任意H中的函数h,满足以下两个条件:
1)如果d(O1,O2) 2)如果d(O1,O2)>r2,那么Pr[h(O1)=h(O2)]≤p2。 其中:O1,O2∈S,表示两个具有多维属性的数据对象;d(O1,O2)为两个对象的相异程度。 2.3.2 算法主要步骤 首先,计算10万个图标dhash特征值,随后,选取合适的LSH hash函数将每一个dhash特征值映射到Hash table,Hash table的尺度受图标数量、种类的影响。该算法在本文中大致实现过程如图6所示。 图片 图6 Hash table构造过程 Fig. 6 Process of generating Hash table LSH针对不同的距离度量空间需要不同的算法,主要包括了Hamming距离、Euclidean距离、Jaccard 系数、余弦相似度。在本文中,拟选用P-stable hash[20]的算法。 首先,构造p-stable分布LSH函数族,提出了如下hash函数族: ha,b(v)=(a·v+b)/r 式中:b∈(0,r),是一个随机数;r是直线的分段长度;hash函数族的函数是依据a、b的不同建立的。选取合适的r值,能够使得ρ=ln(1/p1)ln(1/p2)尽可能地小,r的取值要根据实际情况设定。具体依据为:先确定r1、r2的取值,然后选择合适的r,使得p1、p2都达到要求。 其次,构造hash table。按照减少漏报率[19]和误报率[20]提供的算法,进行hash table的构造。 先设计两个hash函数:H1、H2,将一个由k个数组成的整数向量映射到hash table的某一个位上,其中size是hash table的长度。 H1(x1,x2,…,xk)=((∑ki=1rixi)mod C)mod size H2 (x1, x2 ,…,xk )=(∑ki=1r′ixi)mod C H1:Zk→{0,1,2,…,C}。C=232-5,是一个大素数。这两个函数具体的算法如下,其中,ri、r′i 是两个随机整数。H2计算的结果成为一个数据向量的“指纹”,它是由数据向量的k个hash值计算得到的,而H1相当于是数据向量的指纹在hash table中的索引。 首先,將一个dhash的描述经过LSH函数变换,LSH函数为随机选取L组函数组gi(·),每个函数组都由k个随机选取的函数{g1(·),g2(·),…,gL(·)}构成,其中L个函数组之间不一定是一样的。然后,形成一个整型向量(x1,x2,…,xk),通过H1、H2变换得到索引信息,现在这L组函数分别对数据处理,只要有一组完全相等,就认为两条数据是相近的。此算法运用到检测工具的具体查询过程如图7所示。 3 实验与结果分析 3.1 实验设置 为验证本文工具对于欺骗性的恶意代码具有很好的检测效果,本文设计了三个实验:1)输入疑似正常图标的恶意样本11364个,对检测工具进行测试;2)输入疑似正常图标的恶意样本1136个和正常软件1136个,对检测工具进行测试;3)输入与实验2相同的样本集,对不分析图标信息仅采用模糊哈希进行行为检测的方法进行测试。本文实验的环境为Windows 7 x64旗舰版、Python2.7 (32b),使用Pefile的版本为2017.11.5,Imagehash版本为4.0,Ssdeep的版本为2.14.1。本文选取不同的样本集进行实验,结合常规信息库中的10万条记录,输入到恶意代码检测工具中,对实验结果进行统计分析,然后对具体样例进行分析,证明了本文可以有效实现对图标资源的匹配和导入表的匹配,在此基础上实现对可执行程序恶意性的判定。 3.2 实验过程与结果 3.2.1 实验1 为验证检测工具对真恶意代码是否具有很好的检测效果,对海量的恶意代码样本作预处理,筛选出具有此类特征的恶意代码作为测试样本。由于实验规模太小,因此,本文增加了恶意代码样本的数量,在VirusShare网站上下载了十万个恶意代码,从中筛选出疑似正常图标的恶意样本11364个,并在相同的测试环境下,输入检测工具进行测试,测试结果如表8所示。 3.2.2 实验2 为了进一步说明检测工具的有效性,设计了实验2,输入1136个疑似正常图标的恶意样本,以及从360宝库中收集的1136个正常软件,并对恶意样本和正常软件作标记加以区分,在相同的测试环境下,输入检测工具进行测试,测试结果如表9所示,类别结果如表10所示 3.2.3 实验3 为验证利用图标与行为分析相结合的方法进行恶意代码检测,比仅对行为信息进行分析的方法具有更好的检测效果,设计实验3,与实验2进行对比,输入与实验2相同的样本集,对不利用图标信息仅采用模糊哈希进行行为检测的方法进行测试,测试结果如表11所示,类别结果如表12所示。 3.3 样例分析 以上对三个实验结果的统计分析,说明该工具总体上已实现基本功能,下面对实验1中的样例进一步分析。 例如,样本1的检测过程信息如表13所示。首先,通过图标相似性比对,发现该样本与常规信息库中LEViewer.exe和WinRAR.exe存在图标匹配,其汉明距离分别为9和0。然后,进一步通过导入表模糊哈希匹配发现其匹配度均为0,说明该样本与正常可执行程序的导入表差别极大,因此判定为存在恶意性。 在检测结果中,有1643个样本没有从常规信息库中匹配出图标信息,这主要由两方面因素决定:其一,常规信息库中的记录数量。各种不同正常应用程序收集得越多,测试样本图标匹配的成功率就越高。其二,图标哈希阈值IconHashThreshold的取值。显然当IconHashThreshold的取值越大,对于各种不同变换的图标匹配成功度越高,但另一方面也可能会导致无关图标的匹配。通过实验与分析,验证了本文工具可以有效实现对图标资源的匹配和导入表的匹配,在此基础上实现了对可执行程序恶意性的判定。常规信息库中收集的正常程序信息数量、图标哈希阈值和导入表模糊哈希阈值等因素,对检测效果具有重要影响。下一步工作可以进一步收集更多的正常程序,丰富常规信息库,进而提高检测工具的能力。 在采用聚类和LSH算法后,将常规信息库中10万条记录分成50个分类,每个分类包括2000条记录。将使用了此算法后的测试结果与未使用此算法比较,发现准确率明显提高,匹配时间缩短,效率提高。但是针对此算法的实验,数据集不够全面,评价指标不够科学,难以可靠地表明此算法的有效性,因此有待进一步深入研究。 4 结语 首先,本文介绍了恶意代码检测技术的研究背景及研究意义,对恶意代码种类、分析和检测方法进行了概述,介绍了国内外在基于图标资源相似性分析的恶意代码检测方面的研究现状;然后,介绍了工具的总体结构设计,以及两种主要方法——图标相似性比对方法和模糊哈希的行为相似性的快速比较方法;最后,设计了三个实验对工具进行测试,并对实验结果进行统计分析。从实验结果可以看出,本文主要有以下两个方面创新:1)从图标入手进行恶意代码检测,大幅度缩小了检测开销,提高了检测效率;2)采用图像哈希进行图标相似性比对,采用模糊哈希进行行为相似性比对,设计并实现了一个轻量级的恶意代码快速检测工具。 目前的研究还存在许多待解决的问题:1)该工具只能对一般情况的恶意软件进行快速检测,面对一些特殊情况的样本,如一些压缩自解压文件,压缩后会表现出来一些压缩软件的图标,仍然存在误判问题;2)常规信息库需要大量的不同版本的正常软件,下一步工作将采用机器学习的方法对常规信息库的正常软件进行训练,进而提高比对的精度。由于本文从图标入手,旨在实现一种轻量级的快速恶意代码检测工具,因此该工具针对的对象是欺骗型恶意代码,对于一般的恶意代码不具有很好的检测效果,而且能达到相对较好的预处理效果,若此类恶意软件采用与正常软件高度类似的API表现,则仍然需要进一步复杂的行为分析。 参考文献 (References) [1] 徐婵.基于行为的恶意软件自动分类方法的研究[D].湘潭:湘潭大学,2014:7-9.(XU C. Research on automatic classification method of behavior-based malware [D]. Xiangtan: Xiangtan University, 2014: 7-9.) [2] 王毅,唐勇,卢泽新,等.恶意代码聚类中的特征选取研究[J].信息网络安全,2016,16(9):64-68.(WANG Y, TANG Y, LU Z X, et al. Research on features selection in malicious clustering [J]. Netinfo Security, 2016, 16(9): 64-68.) [3] 蔡林,陈铁明.Android移动恶意代码检测的研究概述与展望[J].信息网络安全,2016,16(9):218-222.(CAI L, CHEN T M. Research review and outlook on Android mobile malware detection [J]. Netinfo Security, 2016, 16(9): 218-222.) [4] SILVA P, AKHAVAN-MASOULEH S, LI L. Improving malware detection accuracy by extracting icon information [C]// MIPR 2018: Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval. Piscataway, NJ: IEEE, 2018: 408-411. [5] 王文,芮国胜,王晓东,等.图像多尺度统计模型综述[J].中国图象图形学报,2007,12(6):961-969.(WANG W, RUI G S, WANG X D, et al. A review of multiscale statistical image models [J]. Journal of Image and Graphics, 2007, 12(6): 961-969.) [6] 傅红普,邹北骥.方向梯度直方图及其扩展[J].计算机工程,2013,39(5):212-217.(FU H P, ZOU B W. Histogram of oriented gradient and its extension [J]. Computer Engineering, 2013, 39(5): 212-217.) [7] 张定会,江平,单俊涛.卷积码的神经网络编码方法[J].数据通信,2011(4):33-34,39.(ZHANG D H, JIANG P, SHAN J T. Neural network coding method for convolutional codes [J]. Data Communications, 2011(4): 33-34, 39.) [8] 潘宣辰,肖新光.基于应用图标的移动终端恶意代码检测方法及系统:CN 103902906 A[P].2014-07-02.(PAN X C, XIAO X G. Mobile terminal malicious code detection method and system based on application icon: CN 103902906 A [P]. 2014-07-02.) [9] 王立新,刘彤宇,李阳.SSDA图像匹配算法的研究及实现[J].光电技术应用,2005,20(3):53-55.(WANG L X, LIU T Y, LI Y. Research and implementation of SSDA [J]. Electro-Optic Technology Application, 2005, 20(3): 53-55.) [10] 李強,张钹.一种基于图像灰度的快速匹配算法[J].软件学报,2006,17(2):216-222.(LI Q, ZHANG B. A fast matching algorithm based on image gray value [J]. Journal of Software, 2006, 17(2): 216-222.) [11] 陈磊.图像配准中基于特征提取和匹配的方法研究[D].长春:吉林大学,2016:1-2.(CHEN L. Research of image registration based on feature extraction and matching method [D]. Changchun: Jilin University, 2016: 1-2.) [12] 杨薇.基于模型的圖像变形及应用[D].无锡:江南大学,2013:32-44.(YANG W. Research on the technology and application of image deformation based on the model [D]. Wuxi: Jiangnan University, 2013: 32-44.) [13] 曾勇.图像感知哈希算法及应用[D].杭州:浙江理工大学,2012:3-9.(ZENG Y. Image perceptual hashing algorithm and application [D]. Hangzhou: Zhejiang Sci-Tech University, 2012: 3-9.) [14] 肖梓航,李柏松,肖新光.基于模糊哈希算法的恶意代码检测系统及方法:CN 102811213A[P].2012-12-05.(XIAO Z H, LI B S, XIAO X G. Malicious code detection system and method based on fuzzy hash algorithm: CN 102811213A [P]. 2012-12-05.) [15] 吴悠漾,孟祥兆,田颖.基于模糊哈希的恶意代码检测[J].信息系统工程,2017(1):62.(WU Y Y, MENG X Z, TIAN Y. Malicious code detection based on fuzzy hash [J]. China CIO News, 2017(1): 62.) [16] 伍育红.聚类算法综述[J].计算机科学,2015,42(S1):491-499.(WU Y H. General overview on clustering algorithms [J]. Computer Science, 2015, 42(S1): 491-499.) [17] 史世泽.局部敏感哈希算法的研究[D].西安:西安电子科技大学,2013:5-9.(SHI S Z. Research on the locality sensitive hashing [D]. Xian: Xidian University, 2013: 5-9.) [18] 叶卫国,韩水华.基于内容的图像Hash算法及其性能评估[J].东南大学学报(自然科学版),2007,37(S1):109-113.(YE W G, HAN S H. Performance evaluation for content-based image authentication [J]. Journal of Southeast University (Natural Science Edition), 2007, 37(S1): 109-113.) [19] 乔端瑞.基于K-means算法及层次聚类算法的研究与应用[D].长春:吉林大学,2016:5-17.(QIAO D R. Research and application based on K-means algorithm and hierarchical clustering algorithm [D]. Changchun: Jilin University, 2016: 5-17.) [20] DATAR M, IMMORLICA N, INDYK P, et al. Locality-sensitive hashing scheme based on p-stable distributions [C]// SCG 2004: Proceedings of the 2004 Twentieth Annual Symposium on Computational Geometry. New York: ACM, 2004: 253-262.
