中文语境下的口令分析方法
2019-08-27曾剑平陈其乐吴承荣方熙
曾剑平 陈其乐 吴承荣 方熙
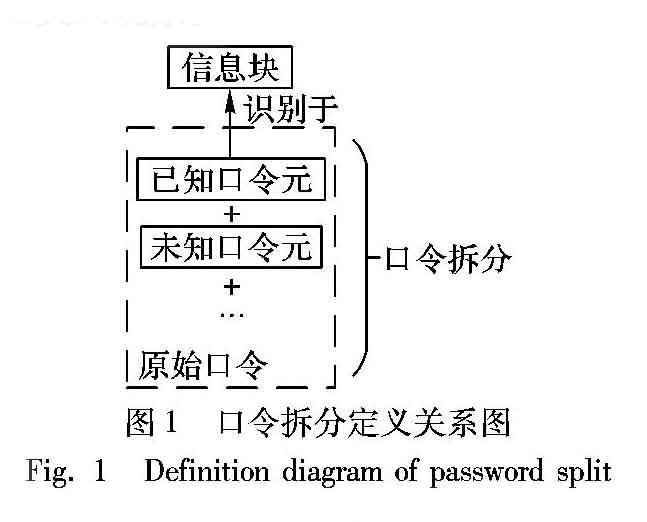

摘 要:针对目前口令语义分析挖掘主要针对英文口令,且局限于常见的单词或姓氏等口令单元的问题,在中文语境下,利用古诗、成语建立模式库,使用口令字符串的数据分析技术,提出了一种基于已知口令元的中文语境口令分析方法。首先,识别出已知口令元;然后,将其视作单个口令自由度;最后,计算给定攻击成功率下的自由度攻击成本,得出口令安全性的量化数值。设计实验对大量明文口令进行量化分析之后,可知在使用中文语境的口令中,80%的用户口令不具有高安全性,能够被字典攻击轻易攻破。
关键词:口令分析;口令安全性;已知口令元;口令自由度;中文语境
中图分类号: TP309.2
文献标志码:A
Abstract: Concerning the problem that the current research on password semantics is mainly based on English datasets and restricted to some units like common words or surnames, by using data analysis technology based on password strings, a Chinese context password analysis method based on known-password elements was proposed with the pattern library based on Chinese poems and idioms in Chinese context. Firstly, the known-password element was identified. Then, it was considered as a single password degree of freedom. Finally, the freedom attack cost within a given attack success rate was calculated and the quantitative security of password was obtained. After quantitative analysis of large amounts of plaintext passwords by designed experiments, it is concluded that 80% of user passwords are low secure and can be easily broken by dictionary attacks in Chinese context.
Key words: password analysis; password security; known-password element; password degree of freedom; Chinese context
0 引言
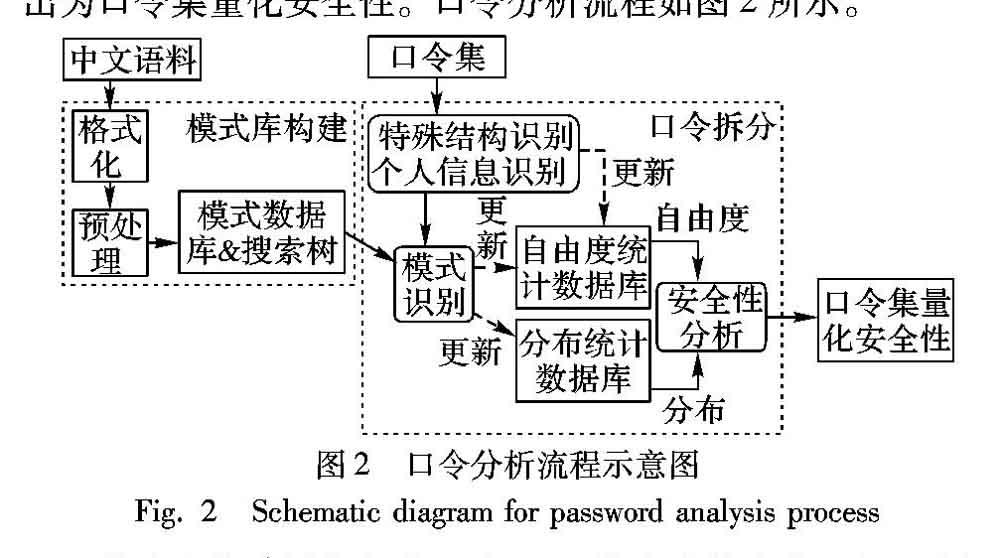
在现今的信息系统中,用户身份鉴别是不可缺少的一个环节。以电子支付、社交网络等个性化应用服务为例,此类服务最常使用“用户名+口令”的方式鉴别登录用户的身份。由于口令鉴别具有易于实现、易于使用的特点,在绝大多数网络环境中,口令都作为最主要的,甚至是唯一的鉴别方式出现。显而易见,用户的口令安全直接决定了个人信息的安全。考虑到常人的思维方式以及记忆方式,用户自主设置的口令往往是一个或多个元素的组合,可能包括姓名、生日、家庭信息、容易记忆的特殊字符串等。对此,已有较多基于大样本量的口令挖掘研究,这些研究主要集中在两个方向:其一是在大样本的明文口令库基础上,分析口令中各类元素的出现频率及关联度,并加入到口令字典中实施攻击;其二是在社工库的基础上,分析并寻找用户口令中出现的各类个人信息的占比,并尝试进行撞库攻击。攻击者还可以采用更激进的攻击方式,在已知部分信息的基础上,对口令元素进行重新组合,并加入前缀、后缀等,从而提高攻击成功率。目前的研究针对口令中姓氏、常见词汇的使用情况进行了较多统计分析,这些研究成果有助于更好地评估口令的安全性[1-2]。但是,这些研究大都以英文口令集为主,同时也缺乏更深入的口令语义,只针对一些常见的口令组成单元。且对于中文语境下的大样本明文口令的研究主要分析口令元素的出现频率为主,仅给出口令粗略的安全性评估,并未对口令的安全性作出量化分析。因此本文希望对中文口令进行安全性量化分析。本文的研究在中文上下文中分析一些具备语义的字符串元素,针对古诗、成语等常见语料中的口令元素使用情况,对这些口令元素特性和出现频率进行深度分析,给出了中文语境下口令的安全性进行量化分析的方法,在口令语义单元统计分析中使用了大数据分析的方法。
1 相关工作
1.1 口令组成特征
在口令分布特征分析中,以前学术界普遍认为口令满足均匀分布,而Wang等[3]指出口令是满足Zipf分布的,在去掉低频次口令后,利用高频次口令进行Zipf分布拟合,通过KS(Kolmogorov-Smirnov)检验,证明了口令频次呈多项式下降,满足Zipf分布,口令中的大部分都是高频和低频口令。
在英文语境口令的研究中,Brown等[4]将口令分为四种主要来源:个人信息(包含家庭成员相关信息)、个人兴趣爱好、联想和无意义串。其中,个人信息和兴趣爱好来源的口令占了总体的80%。Florencio等[5]对eBay、Yahoo和amazon等各网站的6~13位用户口令进行分析,得出英文语境下纯小写字母口令的比例始终大于60%,和口令长度无明显关系。其中,纯数字口令比例随口令长度增加而降低,混合口令比例随口令长度增加而升高。
在针对中文使用习惯的口令研究中,Li等[6]对CSDN、天涯、178等网站泄露的口令库进行了分析,给出了中文环境下口令的元素特征,包括纯字母数字的口令比例特征、口令输入方式特征等。同时研究得出,中文环境下大约有5%的口令包含拼音(全拼)元素,其中大部分包含姓氏。根据大量规则优化字典,添加了20000个特征串之后,猜测成功率提升了34%。郭奕东等[7]提出了一种基于属性特征的口令挖掘分析方法,在使用Apriori算法对中文社区CSDN的共642万条口令进行分析后,得出数字型口令元素中有15.68%的口令包含生日、24.27%的口令包含简单数字、3.25%的口令包含手机,用户更倾向于使用这三類信息作为口令元素。字母型口令元素中有21.88%的口令包含百家姓、2.97%的口令包含简单英文姓名、7.92%的口令包含简单单词,百家姓的使用频率较高。此外,用户的口令长度集中在7~11位,容易被攻击者进行基于社会工程学的字典攻击。高强等[8]将口令按照特征进行拆分,尝试识别QQ号、手机号、日期、身份证号,使用k-gram算法进行口令元素出现特征的预测,得出了千万条口令数据的高频组合形式。刘功申等[9]通过对大量真实口令数据的分析,得出接近40%的相同账号用户在不同网站注册时采用了相同的口令,且大部分用户使用非常简单的字符串作为口令,如123456、111111等。日期、手机号、姓名、英语单词是最常出现的包含用户信息的口令元素。
