基于Apache Spark 机器学习的生态安全格局构建方法
2019-08-27袁少雄宫清华尹小玲黄光庆罗新权
袁少雄,陈 军,宫清华,尹小玲,刘 通,王 钧,黄光庆,*,罗新权
1 广州地理研究所,广东省地理空间信息技术与应用公共实验室,广州 510070 2 广东省生态环境技术研究所,广东省农业环境综合治理重点实验室, 广州 510650
区域生态安全格局的构建涉及了重要阈值设定、有效性评价、多尺度关联、生态过程耦合等系列复杂的分析研究[1- 2],通过对关键性的点、线、局部(面)或其他空间组合规划设计,从而保护和恢复生物多样性、维持生态系统结构和过程的完整性、实现对区域生态环境问题有效控制和持续改善[3- 4]。生态安全格局的构建主要有基于源地识别和生态阻力面分析构建法[5- 7]、基于生态系统服务供需分析构建法[8- 12]、基于景观结构优化和风险分析规划法[13- 14]和基于人类生存安全和理想人居环境目标的多因素叠加分析规划法[15]等。不管采用哪一种方法,其前提均是假设生态安全格局与该区域生境中的各个环境因子是相互关联的,通过对环境因子不同层次、不同深度的分析,进一步对其生态安全格局进行规划,然而却少有学者直接对生态安全格局与环境因子之间的关系进行分析研究。
大数据是大量、高速、多变的信息资产,它需要新型的处理方式去促成更强的决策能力、洞察力与最优化处理[16]。Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,支持机器学习[17]。机器学习使用统计技术为计算机系统提供利用数据“学习”的能力,而不需要明确编程[18- 19]。在城市规划方面,机器学习被用以检测城市环境变化的本质[20]、城市建筑的识别[21- 22]、城市用地分类[23- 25]、模拟城市扩张[26- 29]等。但目前利用机器学习算法构建生态安全格局的尝试还相对较少。
基于大数据的机器学习,通常是不问为什么,而只是检测模式模型[30]。本文拟利用大数据处理框架SPARK机器学习对生态安全格局与环境因子之间的关系进行模拟分析,构建通用模型用以预测生态安全格局的分布情况,从而简化繁琐的分析过程、减少阈值设定中主观因素的影响、提升生态安全格局规划的效率、拓展生态安全格局研究途径。本文假设已实施的广东省佛山市高明区、三水区和顺德区的生态安全格局规划是符合当地实际情况的科学合理的方案。通过搭建Apache Spark处理框架,利用其机器学习库中的逻辑斯蒂回归对已有方案中的生态安全格局数据与其环境因子(岩性、土壤质地、土壤类型、用地类型、植被归一化指数、海拔、坡度、阴阳坡向、曲率、断层距离、道路距离、河流距离、建设用地距离、年均降雨量、年均气温、年均风速、人口密度)之间相互关系进行学习与训练,检测两者的关系模型,进而利用该模型预测其他区域的生态安全格局。
1 研究方法
1.1 模型简介
1.1.1逻辑回归模型
逻辑回归(Logistic Regression,下称LR),在机器学习中既可以用来回归,亦可以用来分类,由于算法的简单和高效,在实际中应用非常广泛。其作为二分类模型,对因变量数据假设要求不高[31],是统计学习中的经典分类方法。本文中利用Apache Spark的机器学习库(MLlib)中的Logistic Regression模型(下称Spark-LR),计算生态安全格局构建中各环境变量的权值向量,以构建生态安全格局通用模型。
对于环境变量中的分类变量,如岩性、土壤质地、土壤类型、土地利用、坡向、阴阳坡和曲率分类后的离散变量等,需要使用哑变量(dummy variable)[32]。因为分类变量的各类之间不存在大小等级关系,它们之间的差距无法准确衡量,需要将原来的多分类变量转化为多个哑变量,每个哑变量只代表某两个级别或若干级别之间的差别,才能使回归的结果有明确而合理的意义,哑变量代表的是等级间的比较结果[32]。
1.1.2模型的参数设置
在Apache Spark机器学习库中,逻辑回归模型的主要参数包括数据(本文为含生态安全格局样点及建设用地点的SVM格式数据)、训练数据与测试数据比例(部分用以模型训练,部分用以模型精度测试)、逻辑回归最大迭代次数(较小的值将导致更高的精度与更多的迭代的成本)、正则化参数(值>=0,应设置合适的值以防止过度拟合或欠拟合)、Elastic Net混合参数(设置0,惩罚为L2范数;设置1,为L1范数;设置0—1之间,惩罚为L1和L2组合)。本文设置训练数据与测试数据比例为0.75∶0.25,其他参数经过多次反复模拟后选择最佳拟合精度参数组合(更理想的状态下可做蒙特卡洛模拟,以测试模型的稳健性)。
1.1.3生态安全格局分布图计算
在没有分类变量的情况下,逻辑回归模型计算的权值向量,可以直接用在arcgis栅格计算工具中,公式如下:
(1)
式中,R为目标栅格,Vi为第i个变量,Ci为第i个变量对应的权值向量。
本文采用了多个分类变量,LR模型对各分类变量的哑变量进行权值向量计算,在GIS中对单个分类变量栅格计算需要按各亚变量分别进行权值向量计算赋值,方法是按栅格值与对应的权值向量相乘,得到相应栅格的新值,利用栅格计算的Con语句对分类变量栅格进行赋值运算,公式如下:
vR=Con(iR=v1,nv1,Con(iR=v2,nv2,Con(…)))
(2)
式中,vR为分类变量目标栅格,iR为分类变量栅格,v1、v2为分类变量栅格值,nv1、nv2为新的变量栅格值,新的变量栅格值是该分类变量原栅格值与权值向量的积。所有的分类变量目标栅格计算出来后,利用公式1计算目标栅格R。按以下公式计算生态安全格局可能性分布图:
(3)
式中,P为生态安全格局可能性分布图,b为LR模型截距。
1.1.4模型精度
应用受试者工作特征曲线(Receiver operating characteristic curve,ROC)分析法对预测的结果进行精度检验。Spark-LR模型运行后自动计算出AUC值(即ROC曲线下面的面积)。AUC值取值范围为0.5—1,越接近1说明预测的结果越好,其模型预测的结果就越准确。AUC值为0.50—0.60(失败),0.60—0.70(较差),0.70—0.80(一般),0.80—0.90(好),0.90—1.00(非常好)[33]。
1.2 研究区域
1.2.1模型构建
采用佛山市高明区、三水区和顺德区作为模型构建的基础数据。数据主要为2009年广东省佛山市高明区生态安全格局[15]、2011年佛山市三水区生态安全格局、2014年佛山市顺德区生态安全格局(图1A,下称“三区生态安全格局”)等规划的成果。
在GIS中根据三区生态安全格局的范围随机生成2923个数据点,提取每个数据点所在位置的生态安全格局属性(图1B),以保障生态安全格局(Guaranteed security pattern, GSP)、缓冲生态安全格局(Buffered security pattern, BSP)和最优生态安全格局(Optimal security pattern, OSP)等3个等级安全格局数据作为事件(即需要保护的生态资源)发生值(取值1),以建设用地作为事件不发生值(取值0)。每类再分别提取环境变量属性,形成GSP、BSP和OSP 3个二维数值矩阵。将数值矩阵转换为SVM格式数据,在Apache Spark平台中分别利用三类数据构建相应模型GSPM、BSPM和OSPM。

图1 广东省佛山市高明区、三水区、顺德区生态安全格局规划(A)及样点分布图(B)Fig.1 Ecological security pattern plans (A) and sample distribution (B) of Gaoming district, Sanshui district and Shunde district, Foshan, Guangdong
1.2.2模型应用
模型应用以广东省作为研究区域,分别利用GSPM、BSPM和OSPM预测广东省全省生态安全格局,分析3个模型之间、预测结果与已有规划之间以及预测结果与常规GIS叠加方法的结果之间的差异。
1.3 环境变量
1.3.1变量选择
目前关于利用机器学习的方式探讨生态安全格局构建的研究较少,可参考的文献不多,本文的变量选择以地质灾害安全格局[15]、生物保护安全格局等相关环境变量作为参考,采用岩性(E01)、土壤质地(E02)、土壤类型(E03)、用地类型(E04)、植被归一化指数(E05)、海拔(E06)、坡度(E07)、阴阳坡向(E08)、曲率(E09)、断层距离(E10)、道路距离(E11)、河流距离(E12)、建设用地距离(E13)、年均降雨量(E14)、年均气温(E15)、年均风速(E16)、人口密度(E17)等17个变量作为生态安全格局预测的环境变量,所有变量均处理成120米分辨率栅格数据。
1.3.2数据来源及分类变量处理
岩性数据来源于中国国家地质资料数据中心(http://geodata.ngac.cn/)广东省1∶50万地质图。该变量为分类变量,以各地层的终止年代作为分类依据,各分类的属性如表1。
土壤质地与土壤类型数据来源于中国广东省生态环境与土壤研究所广东省数字土壤V2.0(http://digital.soil.cn/),数据精度为1∶100万。两者都为分类变量,土壤质地分类见表2,土壤类型分类见表3。
用地类型数据是利用GIS对Landsat7数据(2015—2016年度,原始精度为30 m,数据来源于中国科学院计算机网络信息中心地理空间数据云平台http://www.gscloud.cn)进行监督分类,将土地利用类型分为林地、园地、草地、耕地、湿地、建设用地、其他用地和水域(表4)。
NDVI数据来源于中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn)250 m植被指数16天合成产品。
海拔数据为数据来源于中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn)30 m分辨率数字高程数据,坡度、坡向、平面曲率数据由DEM经过空间分析获得。阴阳坡向由坡向按平面、阳坡、阴坡进行重分类后获得(表5)。平面曲率分为凹、平、凸三类(表6)。

表1 岩性分类及属性
E,环境变量 Environmental variables

表2 土壤质地分类及属性
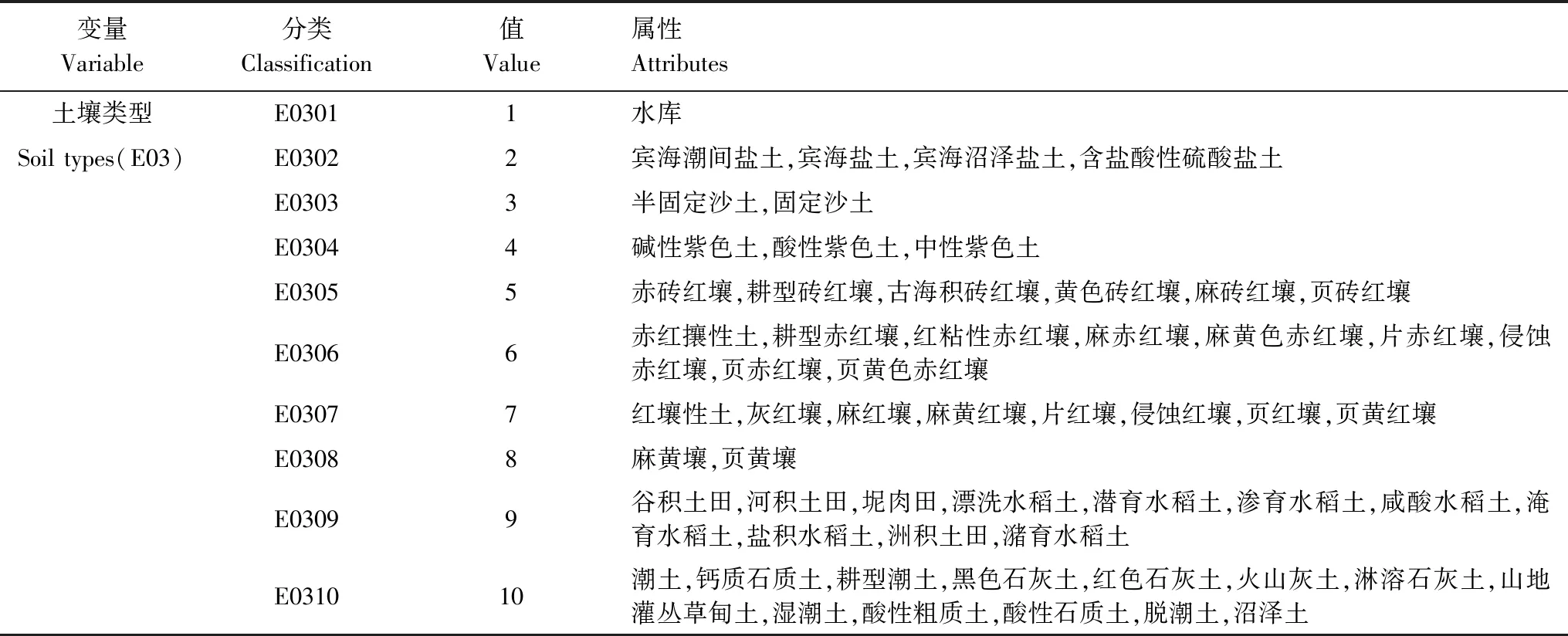
表3 土壤类型及属性
断层数据来源于中国国家地质资料数据中心(如前地质数据源,1∶50万),广东省道路及河流数据来源于自有数据(精度1∶100万),建设用地数据为用地类型数据中的一类。利用GIS欧氏距离工具计算各距离因子,获得断层距离、道路距离、河流距离和建设用地距离。

表4 用地类型及属性
年均降雨量、年均气温、年均风速由广东省气象局多年气象数据通过GIS的Kriging插值生成(分辨率:120 m)。人口密度来源于欧洲人类居住区任务(http://ghsl.jrc.ec.europa.eu/,分辨率:250 m)。
1.4 构建流程
Spark-LR模型生态安全格局构建流程见图2。
2 结果分析
本研究中GSPM的平均AUC值达到90.58%,模型精度非常好;BSPM的平均AUC值为86.49%,模型精度较好;而OSPM平均AUC值71.11%,模型精度一般。由于GSP、BSP和OSP在本质都是“生态资源(生态用地)”,三者之间只是景观破碎化程度的高低,资源集中程度高低的区别,因此本文仅给出模型精度高的GSPM结果供参考。

表5 阴阳坡向属性
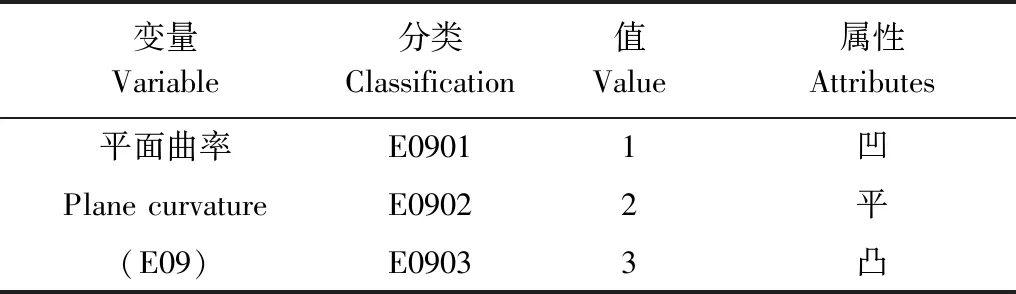
表6 平面曲率属性
2.1 GSPM变量权值与精度
Spark-LR的结果显示,基于GSP数值矩阵的训练模型,偏置向量b为0.5235±0.0079,各变量对应的分类及其权值向量见表7。

表7 GSPM变量、亚变量及相应权值向量

图2 Spark-LR模型生态安全格局构建流程Fig.2 Spark-LR model ecological security pattern construction processE:环境变量 Environmental variables;SVM:支持向量机 Support vector machine;LR:逻辑斯蒂回归 Logistic regression;ROC:受试者工作特征曲线 Receiver operating characteristic curve

图3 GSPM预测精度Fig.3 GSPM prediction accuracyAUC:ROC曲线下面的面积Area under the curve of ROC
GSPM的平均AUC值为0.9058(图3),说明模型拟合的精度非常好,预测准确性高。
2.2 GSPM预测结果
利用公式1、2、3对GSPM的主要变量及相应权值在GIS里进行计算,得到GSPM预测的广东省生态安全格局概率分布图4。结果显示珠江三角洲地区、韩江流域下游地区是基本保障生态安全格局可能性最低的区域,亦是广东省人类活动最活跃、城市建设最强烈的区域。而南岭的各向余脉、青云山脉、莲花山脉及云雾山脉是基本保障安全格局可能性最高的区域,是广东省生态系统最重要的源和关键点,是广东省生态安全格局的“核心区”,保障这些区域的生态系统的完整性,是维护广东省生态安全的基本低线。
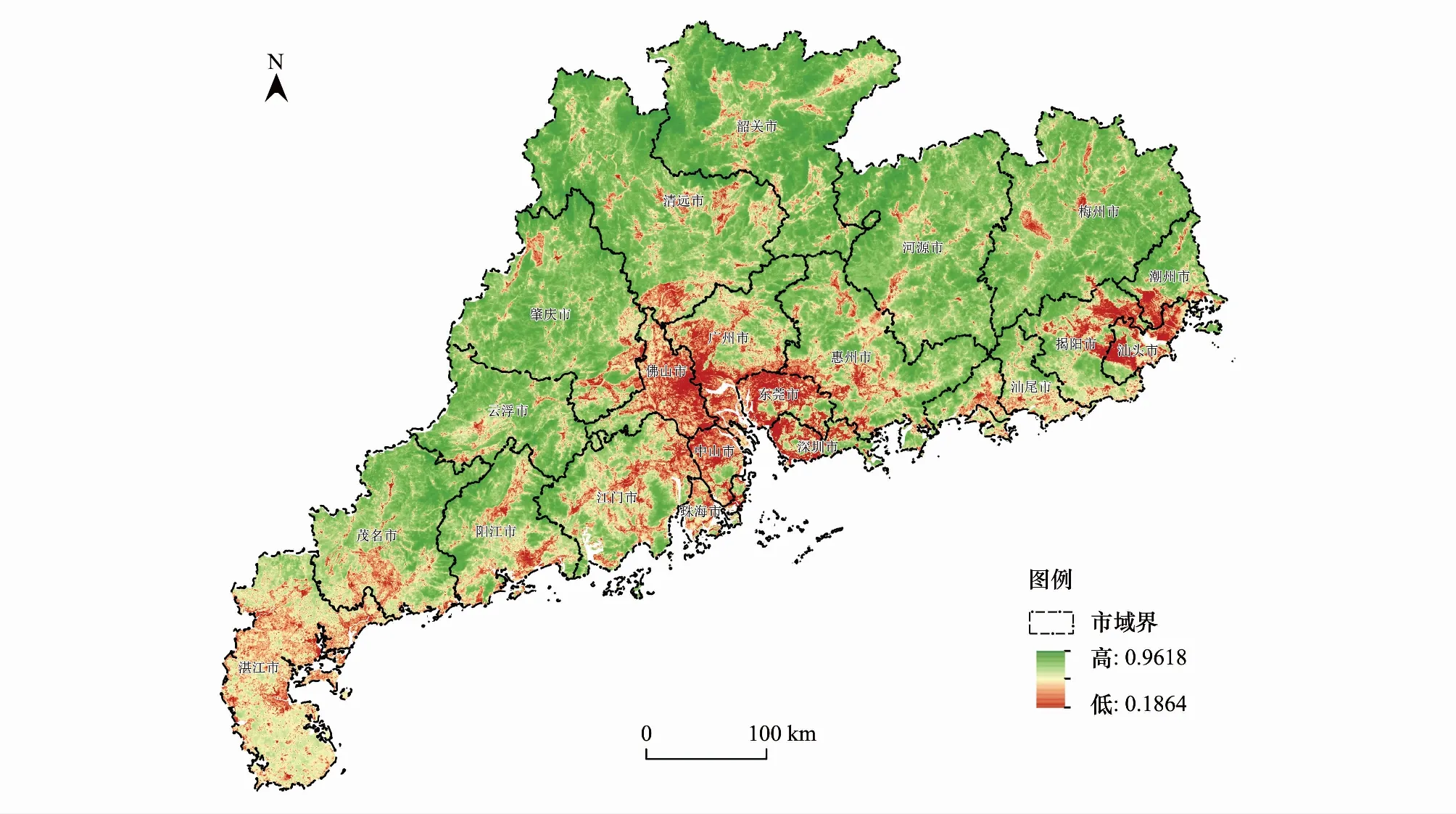
图4 GSPM广东省生态安全格局概率分布图Fig.4 Probability distribution of ecological security pattern of GSPM in Guangdong Province
2.3 GSPM、BSPM和OSPM的异同
GSP、BSP和OSP本质上都包含有生态系统中较重要的生态斑块,在景观水平生态过程中起着关键性的作用,是物种扩散和维持的主要区域,是同一个类型中不同的3个层次。三者的区别在于,GSP是生态系统功能维持、生物多样性保护的关键区域,是生态系统服务功能最强的区域;而BSP则次之;OSP内的景观破碎化程度较高,区域内物种的扩散有较高的阻力,是社会与自然交融度较高的区域。景观一致性高的GSP,其数据的一致性高,相应模型预测的精度也高,而BSP和OSP数据的离散度逐渐增高,模型的精度也因此而降低。
3个模型都可预测类似的广东省生态安全格局,但分布范围不一样的。将预测结果分别利用Nature breaks(jenks)[34]方式重新分类进行对比,可以发现:GSPM预测结果中保障安全格局占比达50.56%(图5),而BSPM和OSPM中该类分别占42.40%和34.63%;GSPM预测结果中缓冲安全格局占比为25.21%,而BSPM和OSPM中该类分别占了31.64%和35.61%。
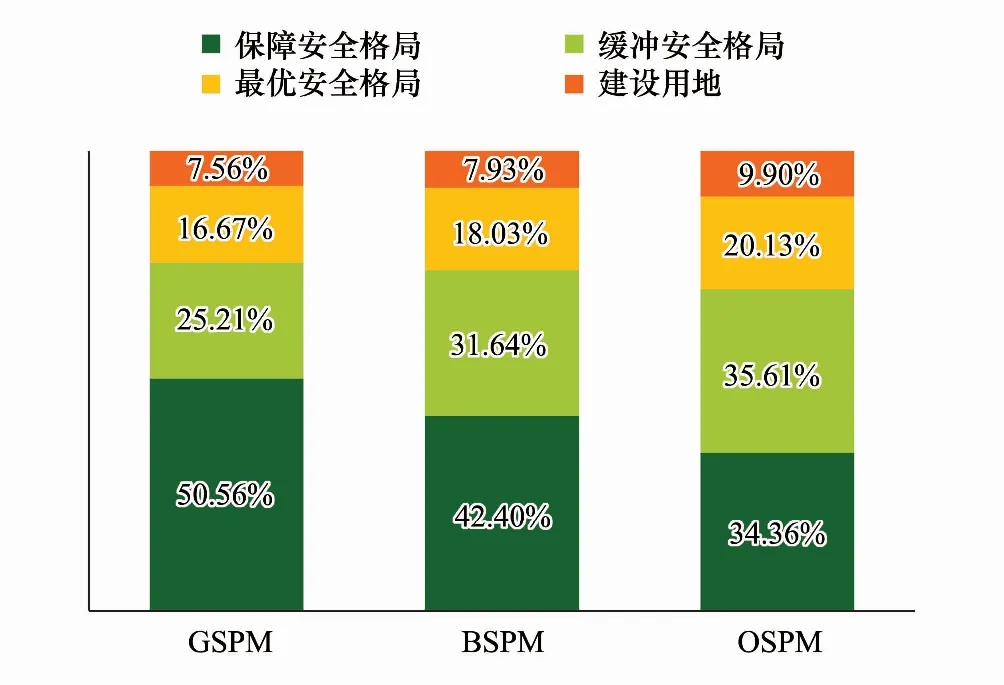
图5 GSPM、BSPM和OSPM预测结果概率区分布对比 Fig.5 Comparison of probability distributions of GSPM, BSPM, and OSPM predictionsGSPM:保障生态安全格局模型 Guaranteed security pattern model;BSPM:缓冲生态安全格局Buffered security pattern model;OSPM:最优生态安全格局 Optimal security pattern model
2.4 预测结果与已有规划的异同
Spark-LR模型的主要数据来源是佛山市高明区、三水区和顺德区三区的生态安全格局已有规划。GSPM预测的高明区生态安全格局总体上与已有规划同区域的情况类似(图6)。在已有规划中,高明区东部区域缓冲安全格局占有较大比例,但在预测结果中,则是最优安全格局占了较大比例。预测结果中,三水区的保障生态安全格局仅少量分布在北部山区较小的范围内,与已有规划差距较大,而顺德区的预测结果没有保障生态安全格局分布,亦跟已有规划不一致。
但与佛山市三区的生态安全格局对比,模型预测的广东省生态安全格局区域尺度更大,其栅格数据在三级格局的区分中将以最优的自然断点作为依据,因此预测结果中基本特征与全省特征相似的高明区与已有规划会更接近。而如果将预测结果中三水区或顺德区的数据单独切分出来,利用自然断点法进行分类,其结果与已有规划也会更加接近(图7)。因此,在不同区域尺度上,生态安全格局的分布是不同的。将模型预测的结果缩小到区县尺度,其与已有规划亦同样是类似的。
图7B箭头指向处实际为水域,已有规划非常注意水域的保护,将其划为保障生态安全格局(图7A),但是在模型预测中水域的重要性并没有体现出来(图7C),图8已有规划中高明河两边的保障型生态用地,在预测结果中同样没有体现出来,这说明水域的重要性被模型忽略了。原因可能是随机生成的样点中,位于水域部分的保障生态安全格局样点太少,以至于模型认为河流在生态安全格局中的比重较低。
在已有规划中,规划者有意保护高明河两岸一定范围内的区域,但是GSPM预测的该区域则是建设用地,与城市扩张的实际情况相比,城市建设用地似乎是与模型预测结果更加切合(图8箭头指示位置)。考虑已有规划的时限问题,我们不能就此说明GSPM比已有规划能更准确地表达某一区域的生态安全格局,但是由此可以看到模型对城市扩张的分布区域预测具有一定优势。

图6 已有规划与Spark-LR模型预测生态安全格局对比Fig.6 ESP Comparison of existing plans and Spark-LR model prediction results
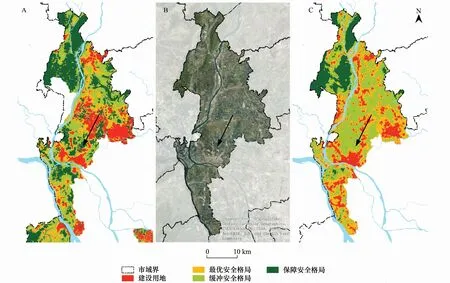
图7 三水区已有规划与Spark-LR模型预测生态安全格局对比Fig.7 ESP comparison of existing plan and Spark-LR model prediction results in Sanshui districtA. 佛山三水区安全格局已有规划;B. 2016年遥感影像;C. Spark-LR模型预测结果,Nature breaks(jenks)分类
2.5 预测结果与GIS叠加法的异同
将Spark-LR预测结果与GIS叠加分析法进行对比(结果均采用Nature breaks(jenks)分类),可以发现两个结果中的生态安全格局有一定的相似性(图9),各类安全格局的分布都与广东省地形比较切合,广东省各大主要山脉是保障安全格局分布区,而珠江三角洲、韩江下游和雷州半岛等沿海地区是最优安全格局分布区。然而两种结果中保障、缓冲、最优安全格局的分布面积却明显不同,常规方法的结果中广东省保障及缓冲生态安全格局比例分别为27.09%和34.03%,而Spark-LR预测的结果中相应的比例分别为50.56%和25.21%。尽管我们不能因此断定Spark-LR模型预测结果在规划上的准确性,但不难发现机器学习预测的结果可能更加切合生态资源保护和人类社会长期发展需求,而GIS叠加结果或许需要进一步优化才能作为规划结果。

图8 已有规划及预测生态安全格局在高明河两岸与城市扩张实际情况对比Fig.8 ESP comparison of existing plan, Spark-LR prediction results and actual urban expansion on the two sides of Gaoming RiverA.已有规划;B.2016年遥感影像;C.预测结果

图9 GIS叠加分析与Spark-LR预测生态安全格局对比Fig.9 Comparison of GIS overlay Analysis and Spark-LR prediction ESP
3 结论与讨论
1)利用大数据处理框架Apache Spark中的Logistic Regression机器学习模型,通过对现有规划中生态安全格局里保障生态安全格局(GSP)、缓冲生态安全格局(BSP)和最优生态安全格局(OSP)数据与岩性、土壤质地、土壤类型、用地类型、植被归一化指数、海拔、坡度、阴阳坡向、曲率、断层距离、道路距离、河流距离、建设用地距离、年均降雨量、年均气温、年均风速、人口密度等环境变量之间关系的训练学习,可以得到相应的回归模型,利用该模型在GIS中对环境变量的回归重构,可以预测出其他区域的生态安全格局分布情况。
2)保障生态安全格局模型(GSPM)预测精度达到90.58%,模型拟合的精度非常好,对生态安全格局的预测准确性高;以Nature breaks (jenks)方式重新分类之后,得到的保障安全格局高概率区比例高达50.56%,在实际应用中,有一定的参考价值。而缓冲安全格局模型和最优安全格局模型的预测精度分别只有86.49%和71.11%,前者的保障安全格局高概率区比例为42.40%,后者的只有34.36%。
3)对区域尺度进行划分后,Spark-LR对生态安全格局的预测结果与已有规划成果非常接近,但是模型容易受到样点分布均衡性的影响;模型预测与GIS叠加分析的生态安全格局有一定的相似性,但预测的结果更加切合生态资源保护和人类社会长期发展需求,而GIS叠加结果则需要进一步优化才能作为规划结果。
4)Spark-LR机器学习模型对生态安全格局中城市扩张的分布区域预测具有一定的客观优势。
机器学习的研究不仅是人工智能研究的重要问题,而且已成为计算机科学与技术的核心问题之一[35]。我们尝试利用大数据计算框架Apache Spark下的机器学习对生态安全格局进行了模拟分析,向地理人工智能(GEOAI)探出了一小步,同时也遇到许多值得我们进一步探讨的问题。GIS本身与大数据是密不可分的,国内外都有学者在研究空间大数据的分析处理[36],但如何用大数据平台的机器学习自动构建生态安全格局仍需要进一步探索。机器学习在生态安全格局构建过程中环境变量选择,是模型是否准确的关键问题之一,模型中到底该选择哪些变量值得深入探讨。虽然Logistic Regression模型是较常用的模型,但是在Spark-LR中,正则化参数和ElasticNet混合参数的设置都会影响到模型的精度,如何设置调优模型亦有一定的探讨空间。关于大数据机器学习与生态安全格局构建及其相关领域的结合,仍有较多的未知领域,随着大数据的发展及我国对生态环境更进一步的重视,机器学习与生态系统服务、生物多样性保护、生态环境规划、城市空间优化等领域的结合将会有更多契机。
致谢:广东省气象局灾害中心刘尉博士帮助气象数据分析,华南理工大学建筑学院袁奇峰老师对研究提供帮助,特此致谢。
