基于主题模型的多关键词搜索加密方法
2019-08-27王文涛马永东王银款
王文涛, 马永东, 王银款
(1.东华大学 计算机科学与技术学院, 上海 201620; 2.上海航天控制技术研究所, 上海 201109)
0 引 言
目前,云存储的广泛应用给互联网用户提供了灵活的数据外包服务.但是,将数据外包给云服务器,数据拥有者则会失去对数据的绝对控制权,而云服务器可能也会受到数据泄漏及硬件故障等威胁[1].为了数据的安全,加密技术得到广泛使用:一方面,加密数据使数据得到了保护,但另一方面也给数据搜索带来了挑战.为了解决这个问题,研究人员提出了一系列相关解决方案[2-11].虽然这些方案提供了不同功能的搜索加密方案,但仍存在一定的局限性.首先,现有的可搜索加密方案中,大多数方案没有考虑到文本提取中关键词的重要性,都只是将关键词进行简单提取,并没有考虑不同关键词在文本中的重要性也是不同的.其次,部分方案仅考虑了关键词词频关系,没有考虑到不同主题下关键词的重要性也是不同的.基于此,本研究提出了提高检索效率的多关键词排序搜索方案:首先,给出了基于主题模型的关键词提取算法以增加检索的准确性,该算法基于文档关键词建立主题模型,得出文档主题;其次,利用TextRank算法[12-13]计算每个关键词在不同主题下的权重值,并根据文档主题分布,得到最终关键词权重排序,选出若干关键词作为文档的关键词;为了解决关键词同义关系,采用Stemming算法[14]获取关键词的词根,还可以查询具有相同词根的关键词.通过实验测试结果表明,本研究提出的方案比相关文献中现有的方案具有更高的效率.
1 基本概念
1.1 系统模型
本研究的模型系统基于文献[7]建立(见图1),主要分为3个主体:数据拥有者、搜索用户和云服务器.其中,数据拥有者首先将文档集合以加密的形式外包给云服务器,为了便于对密文进行搜索,在外包之前对文档进行关键词提取,并建立倒排索引,然后将倒排索引加密上传至云服务器.为了下载感兴趣的文件,搜索用户将感兴趣的查询关键词进行加密,并将加密查询发送给云服务器.云服务器通过计算加密查询和加密倒排索引之间的相关性结果来搜索加密文档,然后将前(top-k)个密文文档返回给搜索用户.最后,搜索用户使用密钥对密文文档进行解密.此过程中,云服务器不知道相关查询关键词的任何敏感信息或文档内容.
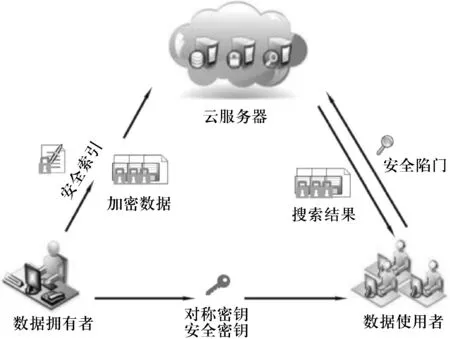
图1系统模型示意图
1.2 威胁模型
本研究同样利用文献[7]的威胁模型,即假设云服务器是“诚实且好奇的”,它会“诚实地”根据指定协议存储数据,但又对存储的数据“感兴趣”,并通过推断或分析来获取数据信息.同时,本模型主要针对两种不同攻击能力的威胁.
1)已知密文模型.该模型中,假设云服务器仅知道数据拥有者上传的加密文档集C和安全索引I.
2)已知背景模型.云服务器可以知道比已知密文模型更多的信息,例如陷门的相互关系和其他统计信息等.云服务器可以通过规模分析来推断关键词的特定信息,进而识别出查询中的关键词.
1.3 相关概念
在方案中,本研究应用如下相关概念:
1)隐含狄利克雷分布(Latent dirichlet allocation,LDA)主题模型.该模型是一种离散数据集上的完全生成概率模型[12],其思路是:假设数据集存在K个独立的隐含主题,在LDA主题模型中,每个文档d的关键词w通过文档主题分布θ(d)采样生成主题z,然后从以主题z为特征的关键词分布φ(z)中采样生成关键词w,其中φ(d)和φ(z)分别由狄利克雷分布α和β生成,则文档d中随机变量θ、z和w的联合分布为,
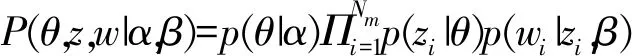
(1)
2)TextRank算法.该算法是一种无监督的机器学习算法,使用基于图的排序方法,其中每个单词表示顶点,而加权边表示顶点之间的相似度[13].TextRank算法完全基于单词出现频率,并且不需要任何先前的语法知识.
3)Stemming算法.该算法是语言规范化的过程,其中词的变体形式简化为通用形式[14].例如,词干分析器基于词干“search”识别“searchable”和“searched”,基于词干“fish”识别“fisher”和“fished”等.
2 具体方案
2.1 关键词提取算法
为区分文档中关键词之间的重要性,本研究提出了一种基于文本主题的关键词提取算法:先将传统的TextRank分解为不同主题下的多个TextRank,并根据TextRank算法获取不同主题下的关键词的权值;然后根据文档主题分布进一步提取关键词.算法主要包括:构建主题解析器以获取关键词与文档的主题;执行算法来提取关键词.
2.1.1 构建主题解析器.
本研究采用LDA主题模型算法从文档集中获取关键词主题,其能够获得每个关键词w的主题分布.关键词的主题分布将用于关键词提取,也用于整合不同主题下的关键词.
2.1.2 基于主题模型的关键词提取.
基于主题模型的关键词提取的流程包括三个部分.
1)根据文档中关键词之间的共现关系来构造关键词图.文档被看作一个关键词序列,而边的权重被设定为关键词之间在长度为K的滑动窗口中的共现数.G=(V,E)表示文档的图结构,其中,顶点表示为V={w1,w2,…,wn},边(wi,wj)表示从关键词wi到关键词wj的连接,边的权重表示为e(wi,wj),定点wi的出度表示O(wi)=∑j:wi→wje(wi,wj).
2)利用TextRank算法来计算不同主题下的关键词权重值.TextRank算法由PageRank算法改进而来,主要考虑关键词权重.在TextRank算法中,关键词wi的权重W(wi)表示为,

(2)
其中,d表示范围在0~1间的阻尼系数.
式(2)表示每个节点有d的概率跳转到该顶点,有(1-d)的概率跳转到其他顶点.(1-d)表示随机跳转,若值为常数1,则表示顶点wj等可能地跳转到其他顶点.而本研究所提出的基于主题的关键词提取算法视随机跳转不是等可能的,这是因为在不同主题下,关键词的TextRank权重可能会更加偏好于对应的主题.因此,对于特定主题,本研究提出了改进的TextRank算法,设置随机跳转概率为特定主题偏好值Pz(wk),其中∑wk∈wPz(wk)=1.此时,与主题密切相关的关键词将赋予更大的权值.主题z中,特定主题的关键词wi的权重表示为,
W(wi)=(1-d)Pz(wk)+
(3)
3)通过文档主题分布,对不同主题下的关键词进行整合排序,并选出权重值最高的若干关键词作为文档关键词.
2.2 多关键词搜索方案
本研究在文献[7]的基础上提出了改进的基于主题模型的多关键词排序搜索方案,其关键函数介绍如下:
1)KeyExtend(F).给定文档集F,对文档集进行分词,并使用Porter词干算法将具有相同词根的关键词表示为同一形式,利用关键词提取算法选出文档关键词w,并构成关键词集合W={w1,w2,…,wn};然后,将关键词集合转换成(n+u+1)维的文档倒排索引向量I,其中对应维上的值为关键词权重W,u是插入的虚拟关键词的数量,(n+u+1)维设置为1.
2)KeyGen(n).数据所有者随机生成安全密钥SK(M1,M2,S),其中,M1,M2∈R(n+u+1)×(n+u+1)为可逆矩阵,S∈{0,1}n+u+1为一个向量.

4)BuildIndexTree(I).在搜索过程中,云服务器必须搜索数据集的每个文档索引,如果数据集非常大,则检索效率会很低.本研究采用Xia等[15]提出的平衡二叉树来构建索引结构.在索引结构构建过程中,首先将索引生成树的叶子节点,然后根据这些叶子节点生成树的中间节点平衡二叉树,具体如图2所示.

图2平衡二叉树结构示意图
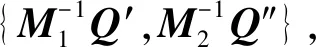
6)Query(I,Q).根据构建的索引树,云服务器计算索引向量和安全陷门的内积来获得最终的查询相关性结果,
Ri=Il·Q
=I′Q′+I″Q″
=(Ii,εi,1)(xQ,x,y)
(4)
最后,返回相关性结果前(top-k)的加密文档给搜索用户,用户根据密钥对密文文档进行解密.
3 安全性分析
3.1 数据安全性
在将数据集外包到云服务器之前,本研究采用了AES对称加密算法[16]对数据集进行加密.由于AES对称加密算法是安全的,因此数据的安全性得到了保证.
3.2 陷门不可连接性
虽然云服务器无法恢复查询关键词的内容,但是陷门的可连接性可能导致隐私泄露.例如,如果陷门是确定性的,攻击者可以通过多次搜索相同的关键词来推断出关键词之间的关系.对此,本研究通过在向量分割过程中引入随机数的方法,使得即使对于相同的查询也会生成不同的加密查询向量,此外,可以分别将随机数εi引入到索引向量中及将随机数x和y引入到查询向量中,最终的查询结果也会不同,由此来实现陷门的不可连接性.
3.3 关键词安全性

4 性能分析
在实验测试中,本研究提出的方法在AMD5 CPU 2.0 GHz的Windows 10操作系统上应用Java语言得以实现.同时,本研究还评估了本方法的性能.测试选取的真实数据集为Enron email dataset[17],其包含150个用户的数据.
4.1 准确性和隐私性

(5)

4.2 搜索效率
搜索时间在文档集中的变化趋势如图4所示.由图4(a)可知,文档数量的变化并没有对本方案产生较大影响,但随着文档数量的增加,Cao方案的搜索时间呈线性趋势.图4(b)表示搜索时间随查询关键词不同而变化的趋势图.无论查询关键词包含多少关键词,它们都在同个字典中,查询时间不会随着查询关键词数量的增加而增加.但是,同Cao方案相比,本方案采用了平衡二叉树的索引结构,因此具有更高的搜索效率.

图3准确性和隐私性
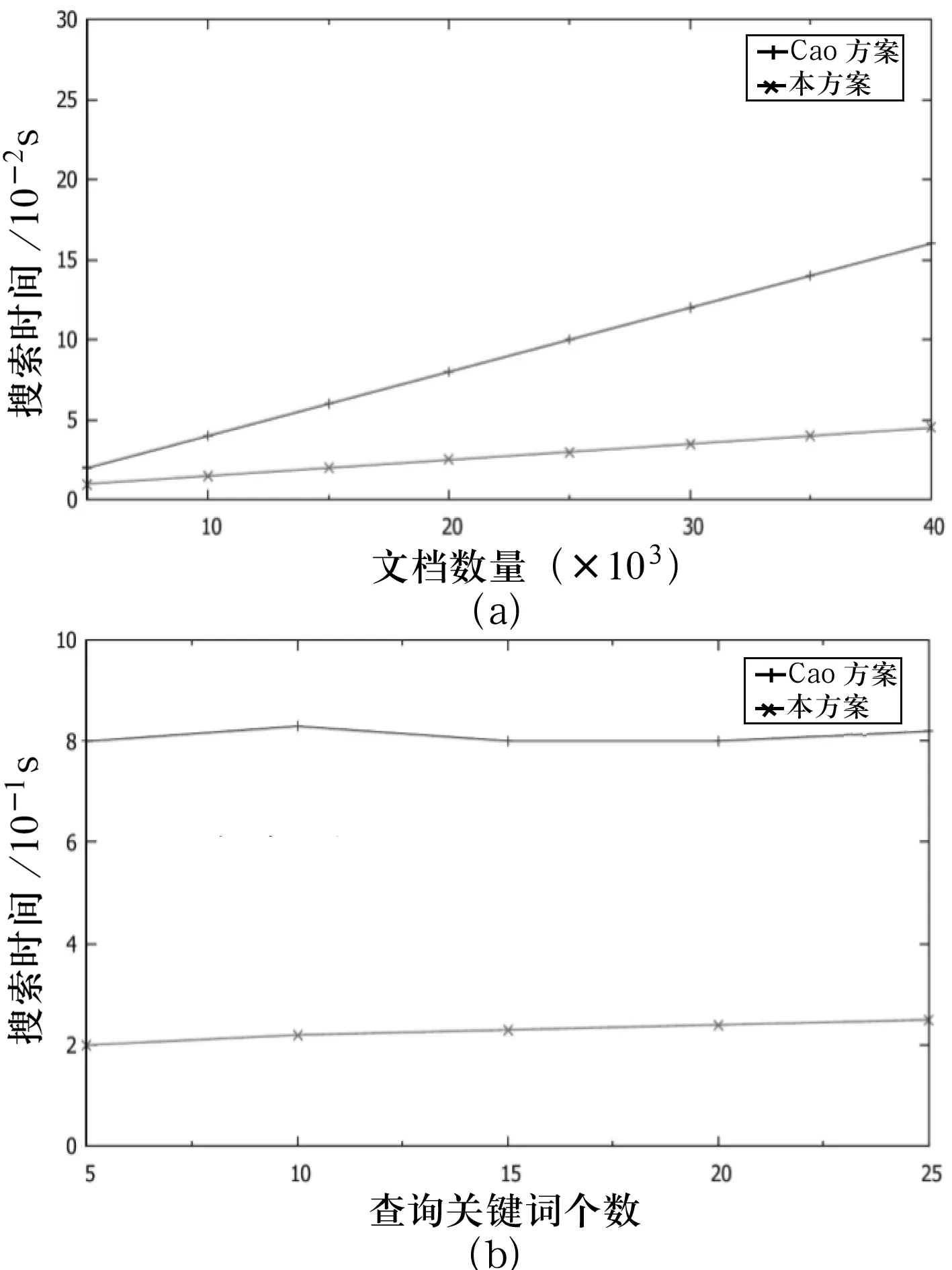
图4搜索效率
5 结 语
本研究提出了一种安全、高效的多关键词排序搜索方案,设计了基于主题的关键词提取算法,即将文档关键词赋予不同的权重,在不失隐私性的情况下,提高了查询结果的准确性.同时,本研究通过实验测试证明了本方案的安全性和有效性.下一步的工作将通过考虑搜索关键词的语义关系来进一步提高搜索的准确性.
