基于网络爬虫的电力故障信息检索引擎设计
2019-08-22杨峰林钰杰吴丽贤
杨峰, 林钰杰, 吴丽贤
(广东电网有限责任公司 佛山供电局, 佛山 528000)
0 引言
随着电网企业开始大规模的技术改革,以进一步创新管理模式的前提下,面对每天大量的电网故障设备信息,如何加强对电网故障信息的监控,保证监控人员能最快的找到故障信息,是当前电网企业思考和解决的重要问题。但是,目前针对电力企业故障信息的筛选,大部分还是以人工筛选为主。在少量的信息面前,人工筛选还能及时处理,但电网企业每天会面临几十万条,甚至上百万条的故障信息,则会极大的增加电力企业的工作量。因此,迫切需要一种能自动对电力企业故障信息进行自动提取和识别的方法,以提高当前故障信息识别的工作效率。本文则借助当前的网络爬虫技术,构建一个可用于电力企业故障信息进行自动识别的搜索引擎,并对该引擎进行详细的设计。
1 网络爬虫原理
所谓的网络爬虫,是将互联网看成是一个蜘蛛网,Spider就是在这张蜘蛛网上蜘蛛,在这个网上爬来爬去。网络爬虫就是通过网页的链接,进而找到目标网页。而在寻找过程中,通常是从某个网站的首页开始,在读取网页的URL地址后,找到某个网页,然后在根据这个链接,找到其他的网页。由此这样循环,直到将网站所有的网页抓取完。网络爬虫实现的具体流程如图1所示。
本系统构建的主要目的是实现对电力企业监控页面中故障信息的抓取,直接识别出其中的故障网页,进而将结果直接展示给广大的电力监控人员,以方便监控人员对故障信息的处理。因此,在本文中首先利用爬虫技术对网页信息进行抓取,在抓取后通过KMP字符串匹配算法完成对目标网页的匹配,最后通过JSON解析技术,将网页中的关键信息解析出来。具体思路如图2所示。
2 引擎检索设计
2.1 URL抽取
要实现对网页信息的提取,主要包含两个部分:一部分是静态网页,另一部分是动态网页。在静态网页的抽取中,本文则主要调用Crawl类中的Injector类完成URL地址的注入,然后通过Crawl类中的Generator类,完成对采集数据列表的创建,最后调用fetcher包中的fetcher类来完成对静态页面的采集。
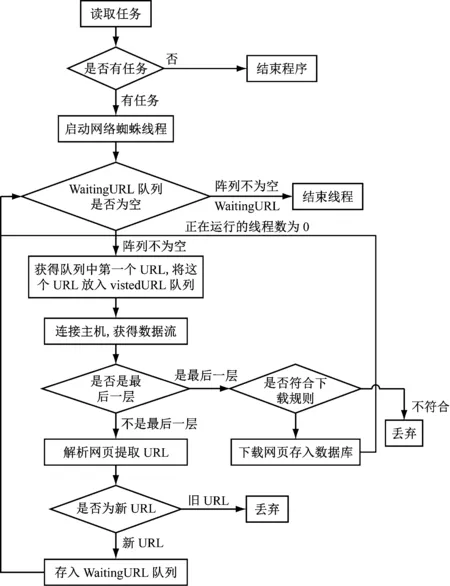
图1 网络爬虫基本原理

图2 本系统抓取思路
对动态网页的抓取,是当前网页解析的难点。动态页面抓取最为关键的是其页面状态的不确定性。在Java网页抓取过程中,页面会通过Ajax异步加载服务器的数据,然后通过Script来实现对页面布局的修改,从而展示数据。因此,在抓取的过程中,动态页面往往会有多个页面形态。爬虫抽取的页面,是在第一次通过HTTP访问请求后得到的HTML数据。因此,在本文中采用两部对网页信息进行抽取,一步是模拟页面脚本执行,进而得到执行后的静态页面信息;二步是在上述静态页面信息的基础上,按照静态页面抽取方法对URL进行抽取。具体实现则是通过HttpBase类完成。
2.2 KMP字符串匹配
1) KMP算法
KMP算法是一种用户模板与文本之间的匹配技术。KMP算法在开展文本过程工作时,其主要流程为:首先,以用户信息需求为前提,开展用户需求模型的构建工作;然后,借助文本流对用户需求文本进行搜索;最后,根据用户反馈对需求模型进行改进。具体KMP算法信息过滤模型如图3所示。
所谓的字符串匹配,是指在给定一组特定的字符串集合T,在主串S中找到集合T在其中的所有的出现,然后按照相似度算法,当相似度超过设定的中,则判定为两者匹配。在构建匹配规则的前提下,对字符串匹配度进行计算,如图4所示。

图3 KMP算法信息过滤模型

图4 关键词匹配
假设图4中上下红色部分的字符串匹配度表示为dw≥α,那么我们就判定两字符串高度匹配。其中α表示为字符串匹配度阈值。
2.3 方法具体应用
以配网台账管理检索为例。传统的方法是在问题数据库中,通过《站线变户一致性-功能位置馈线一致性-生产与GIS一致》表中看到全路径“禅城供电局->城区供电所->百花变电站->701百花甲线”,然后人工逐个路径点击进去到最后一个低压断路器的设备,再去查看台账。具体如图5所示。

图5 配网台账查看
在本文中,则利用java的jsoup页面解析技术和数据抓取技术来实现不需要人工点击直接打开台账。具体步骤为:
首先,台账浏览的url为:
http://10.150.22.1/web/top/workbench/app.ac?appCode=equipment_distribution&appName=配网设备台账管理&tSession= 1539777699084# menuId= 6EEC715F334B42A2A1F2106E401CA036&url=/web/lcam/fwms/equipment/deviceNavi/distribution/tree
使用F12网络分析功能,点击项依次为禅城供电局->城区供电所->百花变电站->701百花甲线,得到每一步点击的请求标头和响应正文。
其次,使用java的“HttpBase”包获取url地址,公式为:http://10.150.22.1/web/lcam/fwms/equipment/deviceNavi/distribution/tree/api/tree-child/"+"030610000000641"+"/6/0"
第三,利用KMP算法进行字符串匹配“701百花甲线”,使用jsoup解析提取出[{"title": "701百花甲线",”key": "357000000033201"中的357000000033201
解析结果:
http://10.150.22.1/web/lcam/fwms/equipment/deviceNavi/distribution/feeder/"+"357000000033201"
3 数据库搭建
要实现上述引擎的设计,实现对电力企业故障信息的提取,首先要对数据进行集成。对此在本文中,结合广东省营销系统、省电力营销系统的数据,采用ETL处理方法对系统数据进行构建。该框架如图6所示。

图6 数据源集成ETL框架
该数据源框架充分考虑电力企业中产生的海量数据,通过Hadoop框架对电力数据进行集成处理。
通过图6看出,在该ETL数据集成中,主要是通过服务器端完成。在通过对不同网页信息的抽取后,通过统一数据源信息管理模块,实现对抽取数据的管理。
4 系统实现
4.1 开发环境搭建
在完成系统的引擎搭建和数据搭建之后,还需要一个交互界面,才能实现对电力故障信息的搜索。对此,本文对用户界面的开发环境进行搭建。具体采用Eclipse3.1+My SQL5.0+Tomcat5.5 的开发思路。其中,Eclipse开发工具具有良好的开放性,并且支持多种插件的安装和工具包的导入。是 Java语言开发很好的选择平台。后面构建 web 应用程序界面时需安装Tomcat Plugin V3 插件。
此外,本系统的开发还需要有开源蜘蛛程序包 Heritrix1.12.1和全文检索工具包 Lucene2.0 的支持。
4.2 具体检索结果展示
通过在检索首页的关键词检索,得到检索后的URL,然后点击,直接进入到经过匹配检索后的结果界面。以上述应用的检索结果为例,具体如图7所示。

图7 检索搜索结果
5 总结
通过上述的设计可以看出,本文采用的网络爬虫技术对网页信息的抓取,具有准确性高,同时抓取定位效率高的特点。而本文在设计中,最大的亮点在于在匹配过程中,对传统的KMP算法进行了改进,以此大大提高了字符串匹配的准确度。同时引入ETL抽取工具,建立有效数据库,进而为电力故障信息的快速提取提供了新的参考。
