基于用户特征的协同过滤推荐算法①
2019-08-22蒋宗礼
蒋宗礼, 于 莉
(北京工业大学 信息学部,北京 100124)
互联网的快速发展和电子商务规模的不断扩大,导致信息过载情况日益严重[1]. 用户无法在大量的信息中快速找到自己喜欢的信息,因此推荐系统应运而生.推荐系统根据用户之前的行为信息发现其信息需求,从而将用户喜欢的信息进行推送[2]. 其中,协同过滤推荐算法是目前应用于各电商最广泛的个性化推荐算法.由于基于用户的协同过滤算法更能推送新颖的项目,因此得到更为广泛的应用[3]. 然而,基于用户的协同过滤算法仅考虑到用户间评分信息,很难保证推荐质量,因此,新用户的冷启动、数据稀疏性和推荐准确性依旧目前亟待解决的难题.
随着对推荐算法研究的深入,许多学者提出了新的相似性改进算法来改善传统协同过滤算法的不足.Liu[4]等基于随机游走技术,提出来一种用户之间非对称的相似性,来提高推荐性能,但这只是一个局部相似性指标,在信息过滤技术上仍有缺陷. Li[5]等提出了一种基于信任度的相似性算法,利用用户的直接信任来改善推荐算法中数据稀疏性问题. Ma[6]等提出了将用户评级和社会信任评级相结合的算法,并验证此混合算法能有效提高推荐性能,但不能改善矩阵稀疏性和冷启动问题. 陈颖[7]等提出了基于项目属性偏好挖掘的相似性算法,来缓解矩阵稀疏性. 董立岩[8]等提出一种将时间融入到评分矩阵中的算法,以提高推荐准确性.
上述这些研究只专注某一点来提高推荐效果,以用户项目评分矩阵为主要数据来源,却忽略了用户本身的属性特点,有很多局限性. 针对以上分析,本文提出一种基于用户特征的协同过滤推荐算法. 该算法结合属性特征、兴趣度、信任度和评分矩阵等信息来计算用户间综合相似性,进而产生推荐. 在利用评分矩阵的基础上,改进的相似性方法的主要贡献点如下:
(1) 结合属性特征. 属性特征是用户自身的特征信息,表明了用户的生活状态. 通过分析属性特征的相似性可以改善用户冷启动问题,并提高推荐准确性.
(2) 结合兴趣度. 兴趣度是推荐系统的推荐依据,若分析出用户的兴趣,则可大大的提高推荐准确性.
(3) 结合信任度. 信任度可以分为直接信任度和间接信任度,直接信任度可以提高推荐准确性,间接信任度可以填充评分矩阵,提高准确性的同时还能改善数据稀疏性.
1 传统的基于用户的协同过滤推荐算法
基于用户的协同过滤算法的理论是,如果不同用户对于某些项目具有相同的兴趣,那么他们对于其他的项目也有着相似的兴趣[9]. 该算法首先找出相似用户喜欢的项目,然后预测目标用户对目标项目的评分,最后将评分靠前的项目给用户做推荐.
1.1 用户-项目评分矩阵
对于m个用户n个项目的推荐问题,可以构建m×n的用户-项目评分矩阵R(m,n),如表1所示. 矩阵中第i行第j列的Ri,j表示用户i对项目j的评分.
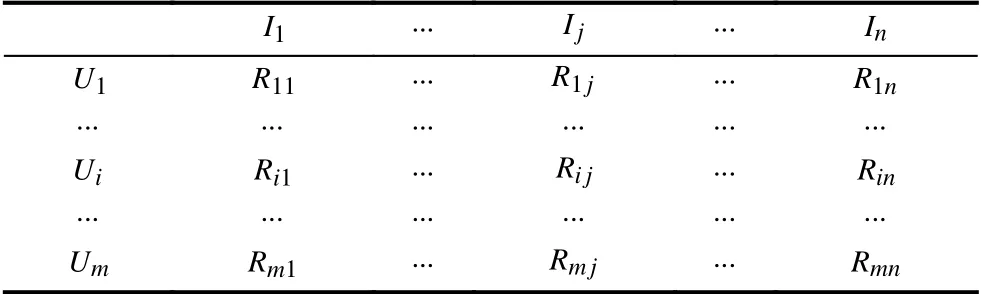
表1 用户-项目评分矩阵
1.2 相似性计算方法
(1) 余弦相似性. 用户的评分数据可以设为n 维向量,那么两用户之间的相似度可看成两用户的评分向量夹角的余弦值. 若用户对某个项目没有评分,则默认值为0.设两个用户x和用户y之间的评分向量分别为u和v,则x和y之间的余弦相似性sim(x,y)如式(1)所示.
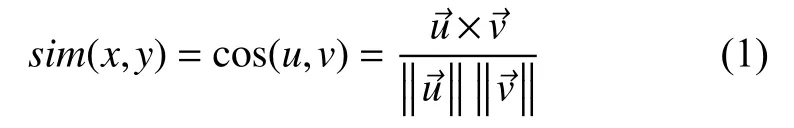
(2) 修正的余弦相似性. 综合考虑不同用户间评分的标准不一样的情况. 设Ruv表示用户u和用户v的共同评分集合,Ru表示用户u 的评分集合,表示用户u所有评分的均值,Rv表示用户v 的评分集合,表示用户v所有评分项的均值,则用户u和用户v的修正余弦相似性sim(u,v)如式(2)所示.
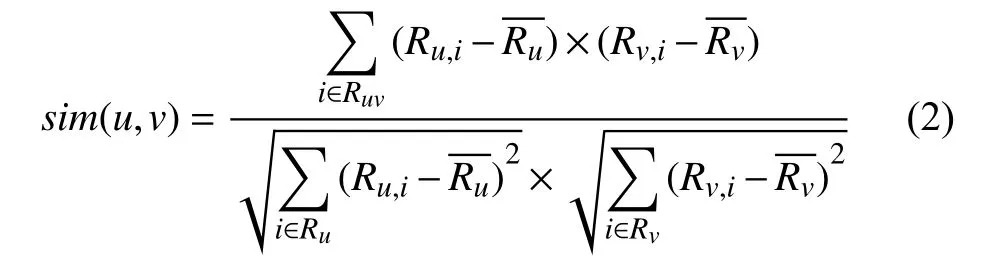
(3) 皮尔逊相关相似性. 设Ruv表示用户u和用户v的共同评分集合,Ru,i表示用户u对项目i的评分,Rv,i表示用户v对项目i 的评分,表示用户u所有评分的均值,表示用户所有v评分项的均值,则用户u和用户v的皮尔逊相关相似性sim(u,v)如式(3)所示.
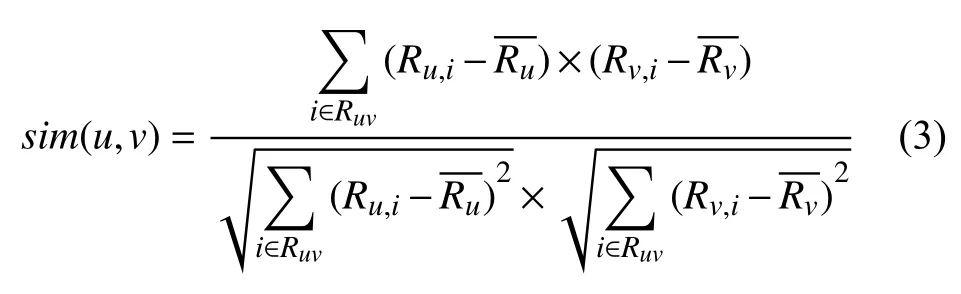
1.3 评分预测
一般在进行评分预测时选取K近邻的方法[10],即将相似度最高的前K个用户作为最近邻来进行评分预测. 设集合Nu为目标用户的邻居集合,Rv,i表示用户v对项目i的评分,则用户u对未评分项i的预测评分值Pu,i如式(4)所示.
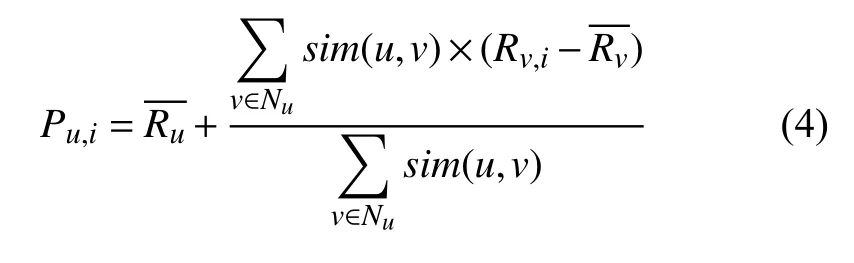
2 基于用户特征的协同过滤推荐算法
传统的基于用户的相似度计算方法一般只计算评分间相似性,却忽略了用户其他方面的相似性[10]. 本文的用户特征综合考虑用户属性、用户兴趣度、用户信任度和用户评分等因素,可以得到更加准确全面的相似度.
2.1 用户属性特征相似性建模
(1) 性别相似度. 如果用户之间的性别不同,那么对项目的偏好也会有很大的差异,比如女性用户选择项目时喜欢货比三家,更加侧重美观性,而男性用户却大多关注项目的可用性,因此本文提取性别来作为属性的一部分. 设用户u的性别为Su,用户v的性别为Sv,则用户u和用户v的性别相似度S(u,v)如式(5)所示.
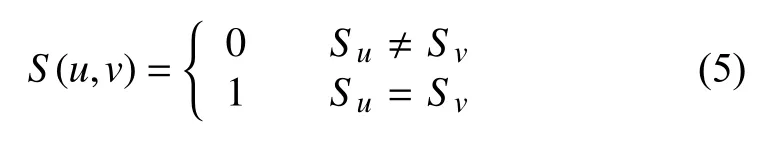
(2) 年龄相似度. 年龄不同的用户所处环境不同,看待问题的角度也不尽相同,因此对项目种类的喜欢也会各有千秋[11]. 设用户u的年龄为Au,用户v的年龄为Av,则用户u和用户v的年龄相似性A(u,v)如式(6)所示.
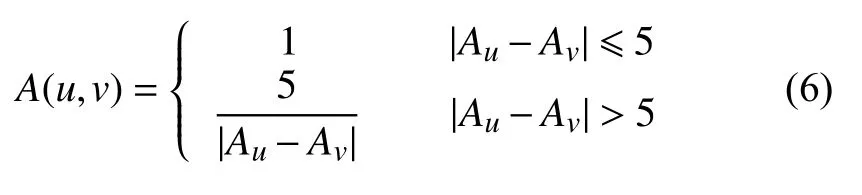
(3) 职业相似度. 将职业分类描述成一个树形结构,如图1中两个任意节点的长度设为1,用Height来表示总长度,职业a和职业b最近的父节点在职业树中的层数称为它的高度,记Ha,b. 用户u和用户v的职业分别用职业a和职业b表示,则职业相似性O(u,v)如式(7)所示.
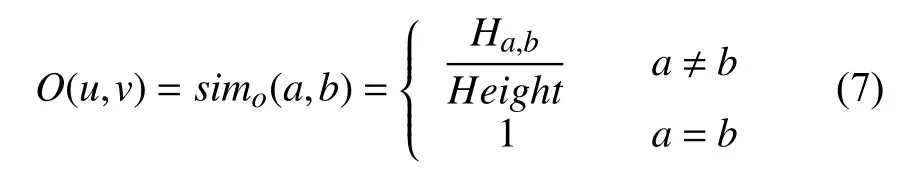
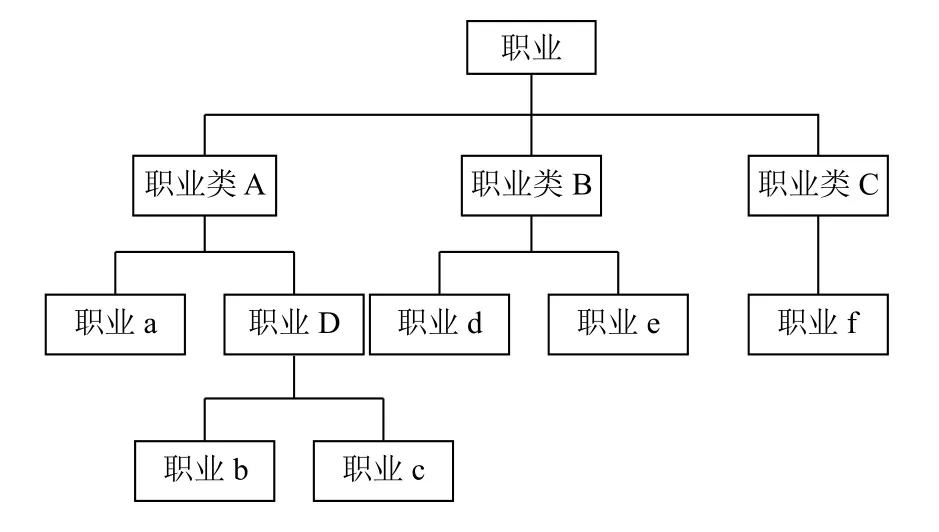
图1 职业树
(4)用户属性相似性. 将上述性别、年龄和职业三个属性综合起来,则用户u和用户v的属性相似度sima(u,v)如式(8)所示.
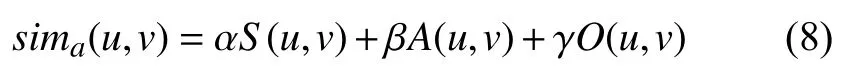
其中,α、β、γ为各个属性的权重系数,分别影响性别、年龄和职业在用户属性相似度上所起的作用. 其中,α、β、γ∈[0,1],且α+β+γ=1,不同的推荐系统,可以动态调整其值以达到不同的推荐效果.
融合用户属性相似度sima(u,v)与传统的皮尔逊相似度sim(u,v),得到用户属性综合相似度simp(u,v)如式(9)所示,其中,ξ为调整属性综合相似度的系数,ξ∈[0,1].
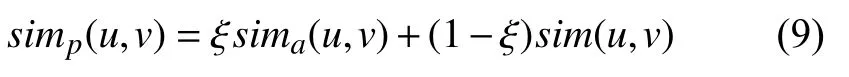
2.2 用户兴趣特征相似性建模
传统的基于用户的相似度计算方法一般只计算评分间相似性,没有考虑到用户对某类项目的喜好. 若两个用户间评分项目属性比较相近,则两个用户间也可认为具有较高的相似性,因此考虑到用户兴趣特征的相似性构建方法如下面的模型.
把用户对某种项目属性的喜好当作用户的兴趣特征,那么用户对某种项目的评价数目越多,则对这种项目的兴趣度就越大[12]. 设NIu,i表示用户u对i类项目的评价总数,NIu表示用户已评价的项目总数,那么用户u对某种项目的兴趣度Iu,i如式(10)所示.

通过得到用户对每个种类项目的兴趣度,则可计算出用户之间的兴趣相似度. 设用户u的兴趣度用集合Iu=(Iu,1,Iu,2,···,Iu,i)表示,Iuv表示用户u和用户v共同评分的项目种类数,表示用户u对所有项目种类的平均用户兴趣度,基于式(3),任意两个用户间的兴趣相似度simI(u,v)如式(11)所示.
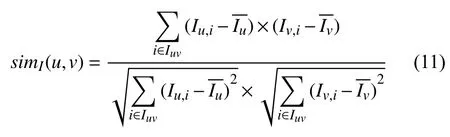
最后将用户兴趣相似度simI(u,v)与用户属性综合相似度simp(u,v)通过式(12)来计算属性兴趣相似度simz(u,v),其中,动态调整δ以达到不同的推荐效果,δ∈[0,1].
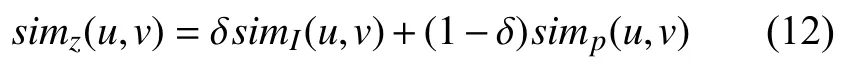
2.3 用户信任度相似性建模
信任度是指在为用户做项目做推荐时,其他用户的参考程度,对一个用户越信任,其参考程度越大. 考虑到用户间分为有共同评分和没有共同评分两种情况,则将信任度分为直接信任度和间接信任度. 直接信任度表示有直接关联的用户相似性,间接信任度表示没有直接关联却可能存在关联的用户相似性[13].
在用户项目评分矩阵中,若两用户间有共同评分则矩阵中评分值不为0,若没有共同评分则矩阵中评分值为0.在引入间接信任度的概念后,若两用户间没有共同评分,且间接信任度值不为0,则可以填充评分矩阵,在一定程度上缓解了矩阵稀疏性问题.
(1) 直接信任度
在一个用户为另一个用户推荐的项目中,可以把被推荐用户满意的项目的比例作为初始信任度.
根据式(4)的预测机制,可得到用户u为用户v在第i 个项目上的预测评分值,设表示目标用户v对已经评论项目的平均评分,表示目标用户u对已经评论项目的平均评分,Ru,i表示用户u对第i个目标项目的评分,其中sim(u,v)使用式(3),则预测评分公式Pu,v,i如式(13)所示.
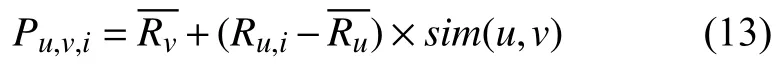
如果用户u 预测用户v对于第i个项目的评分值Pu,v,i与用户v的真实评分Rv,i比较,得到的差值绝对值小于ε,则认为推荐成功. 为了提高推荐精度,在此设定ε=0.1,如式(14)所示.
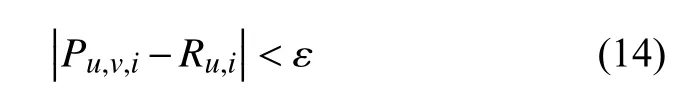
用公式Correct(u,v,i)表示用户u对用户v关于项目i是否预测成功,如式(15)所示.
设Pu表示用户u为用户v推荐的项目集合,可得到用户v对用户u的初始信任度T0(u,v)如式(16)所示.
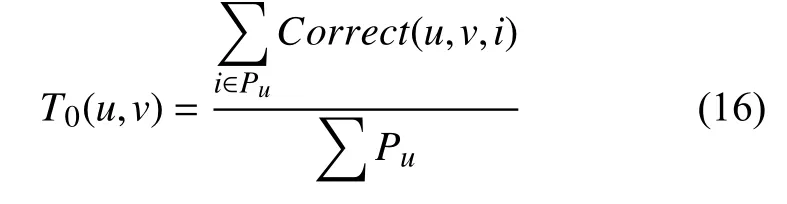
以上是通过对项目的预测获取的隐式直接信任度,下面分析会影响直接信任度的显式因素. 若两个用户对某一个项目的评分都是1,由于评分范围为1至5,则可说明这两个用户对这个项目都不感兴趣,而根据协同过滤算法,由于这两个用户的评分一致,会判定有很高的相似性,事实上只能说明这两个用户不喜欢的项目一致,并不能说明喜欢的项目一致.
所以在此问题背景下,再引入兴趣度阈值R,若两用户u和用户v共同的项目评分值大于等于阈值R,说明用户u和用户v对这些项目都感兴趣. 若Iuv≥R存在的比例越大,说明用户的兴趣越相似. 由于评分区间为1至5,为提高推荐质量,在此设定阈值R=3.5. 定义兴趣信任度如式(17)所示.
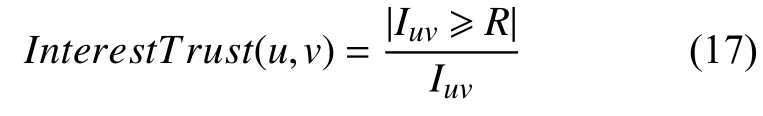
其中,Iuv表示用户u和用户v共同评分的项目数,|Iuv≥R|表示用户u和v共同评分大于R的项目个数.
综合考虑用户的初始信任度和用户的兴趣信任度,可得用户u和用户v的直接信任度公式如式(18)所示.
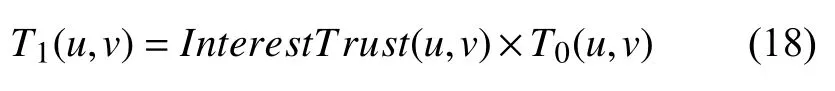
根据上述方法计算出用户间的直接信任度,建立信任度矩阵T1.
(2) 间接信任度
为了改善矩阵稀疏性,将没有直接信任度的用户连接起来,需要用到信任度传递. 设用户u和用户v没有直接信任度,但用户u和用户u1有直接信任度,用户u1和用户v有直接信任度,那么就可以说用户u和用户v通过用户u1建立了间接信任关系.
根据小世界思想[13],则信任从用户u到用户v的路经长度超不过6,由于信任传递路经越长,得到的信任值越低,因此设传递中的长度衰减因子θ如式(19)所示,其中阈值H≤6,当前路径传递长度为N.
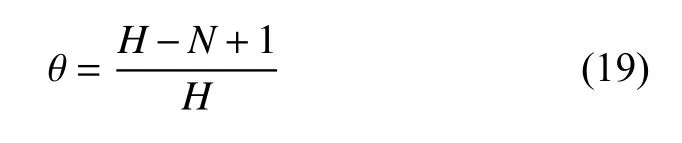
在一条信任路径中,会出现许多用户之间不同大小值的信任度. 根据短板理论,信任度最小的那段传递会拉低整条传递路线的值,因此将信任度传递中最小的信任度作为整条路径上信任度的重要因素. 若两个用户间的信任度为负数,则是不信任的,因此可以终止此条路径上的信任传递. 设µ为信任度阈值,则用户u对用户v 的间接信任度T2(u,v)如式(20)所示,其中k1,···,km表示中间信任度传递的用户.
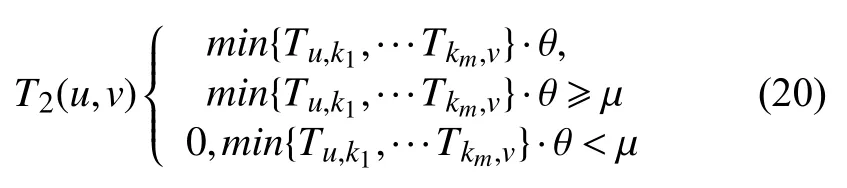
将间接信任度T2填充到直接信任度T1矩阵中,构建用户信任度矩阵T(u,v).
最后将用户信任度矩阵T(u,v)与属性兴趣相似度simz(u,v)结合得到用户特征相似度simw(u,v)如式(21)所示.
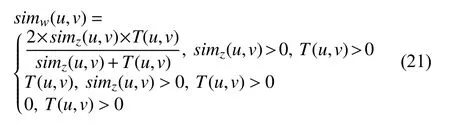
2.4 产生推荐
得到用户特征相似度simw(u,v)之后,选取相似度最高的前N个用户,然后预测目标用户对目标项目的评分,预测评分公式Pu,i如式(22)所示.
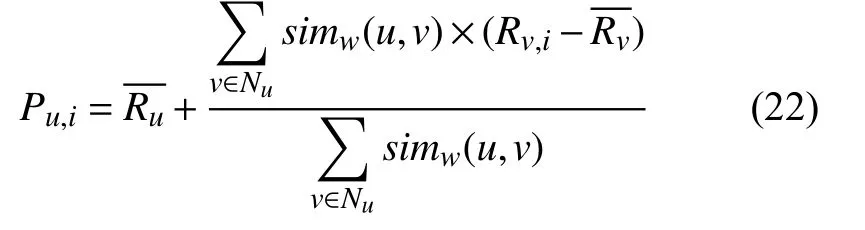
其中,Pu,i表示目标用户u对第i个项目的预测评分,Nu表示生成的top-N 个邻居集合,表示目标用户u对已评项目的平均评分,表示用户v对所有已评项目的平均分,Rv,i表示用户v对第i个项目的评分,simw(u,v)表示用户特征相似度. 通过上述预测评分公式从大到小排序选取最靠前的N 个项目作为目标用户u的top-N个推荐集.
3 实验结果与分析
3.1 实验数据集
为了验证改进算法的有效性,本实验选取Movie Lens站点中的数据集作为实验数据,它是由美国Group Lens研究小组所建立[14-16]. 这里采用了MovieLens的100 k数据集,它是由943个用户对1682部电影的将近100 000个评分所构成,其中每一个用户都至少要对20部电影进行了评分,评分区间为1到5. 最终实验根据数据集按80%/20%的比例随机分为训练数据集与测试数据集进行分析比较.
3.2 评价标准
本文实验采用平均绝对误差(MAE)[17]作为评价标准. MAE越小表明预测越准确、推荐的精度越高.MAE的计算方法如式(23)所示[18].
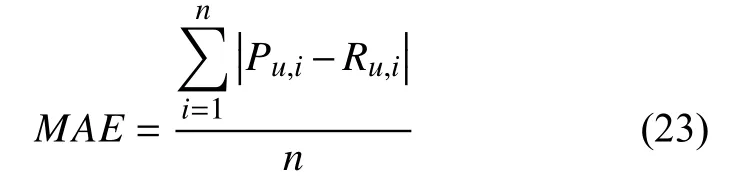
3.3 实验结果与分析
实验1. 确定调参的最近邻个数
为了选取合适的最近邻个数以在调参的时候达到较好的推荐结果,本实验对不同近邻个数的MAE值做分析. 首先选取传统的协同过滤推荐算法,设定最近邻用户的取值区间为[5,50],增量为5,然后计算MAE,实验结果如图2所示.
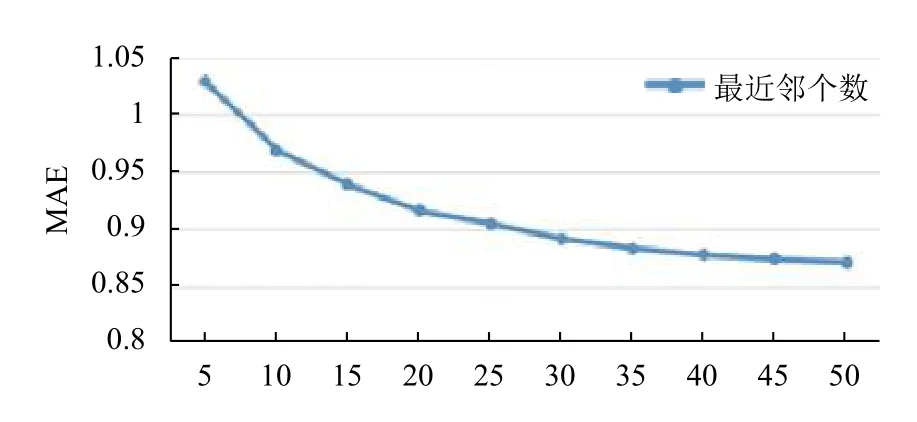
图2 最近邻个数的MAE值
由图2可知,最近邻用户数的不断增加,MAE值会逐渐降低,当最近邻用户的值为30时,MAE趋于平稳,这时的效果比较好,因此在后面的调参中选取最近邻用户为30.
实验2. 调整用户属性参数
根据式(8),α、β、γ分别表示用户属性中性别、年龄和职业的权重,通过调整其不同值以达到较好的推荐状态. 根据α+β+γ=1,设定α、β、γ的取值区间为[0,1],增量为0.1,然后计算不同权重对应的MAE值. 如图3所示,横坐标为权重α的取值.
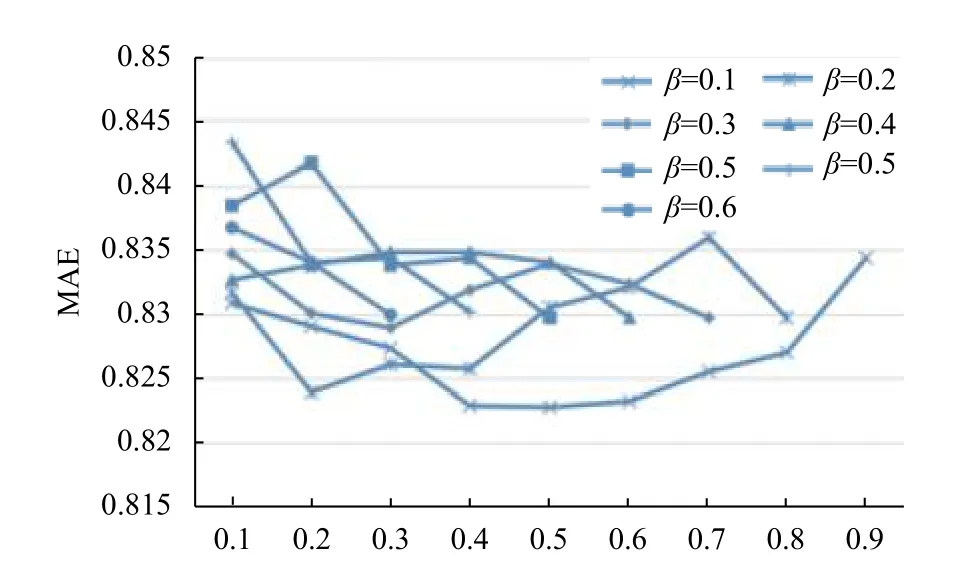
图3 用户属性系数对应的MAE值
由图3可知,当α=0.5,β=0.1,γ=0.4时,取得的平均绝对误差(MAE)比其他值都要小,因此设定α=0.5,β=0.1,γ=0.4为用户各属性的权重系数.
实验3. 用户属性与皮尔逊相似度的调参
将用户属性相似度与皮尔逊相似度相融合得到用户属性综合相似度simp(u,v). 设权重系数ξ∈[0,1],增量为0.1,然后计算不同权重对应的MAE. 如图4所示,横坐标为权重ξ的取值.
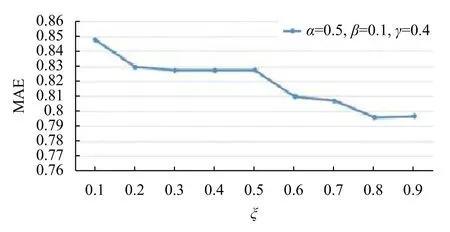
图4 系数对应的MAE值
由图4可知,当ξ=0.8时,用户属性综合相似度取得的MAE比其他值都要小,因此设定ξ=0.8为用户属性的权重系数.
实验4. 融合兴趣相似度与用户属性相似度
将兴趣相似度和用户属性综合相似度融合得到属性兴趣相似度simz(u,v). 设权重系数δ∈[0,1],增量为0.1,然后计算不同权重对应的MAE. 如图5所示,横坐标为权重δ的取值.
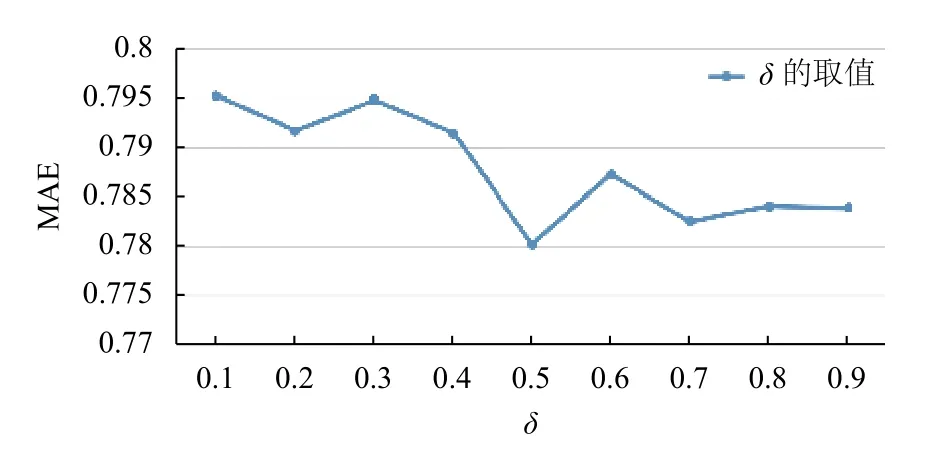
图5 兴趣相似度系数对应的MAE值
由图5可知,当δ=0.5时,属性兴趣相似度取得的MAE比其他值都要小,因此设定δ=0.5为属性兴趣相似度的权重系数.
实验5. 确定信任度传递的阈值
如果在两用户间信任度很低时再进行信任度传递,会造成推荐结果的失真. 对于这种情况,本文设定信任度阈值为µ∈[0,1],增量为0.1,然后计算不同阈值µ对应的MAE. 如图6所示,横坐标为权重µ的取值.
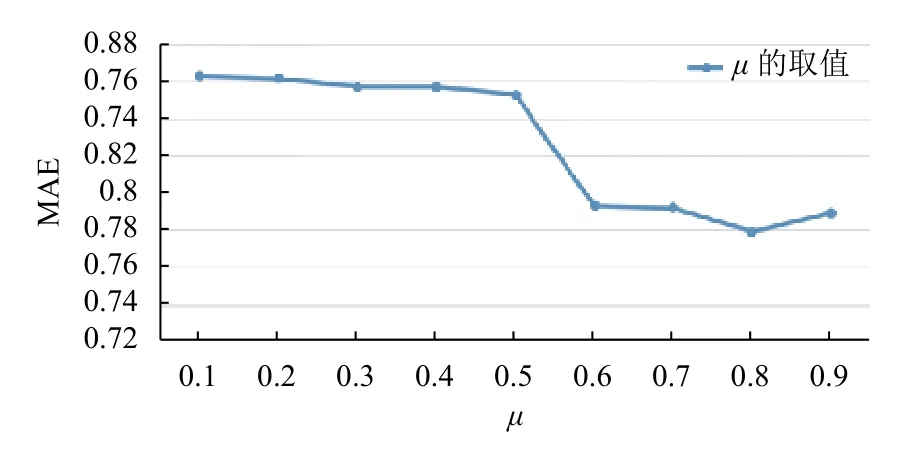
图6 信任度阈值µ对应的MAE值
由图6可知,当阈值µ=0.8时,间接信任相似度取得的MAE比其他值都要小,因此当µ=0.8时进行信任度的传递.
实验6 不同推荐算法的对比实验
本实验选取传统的基于余弦相似性的协同过滤算法(UCB-CF)、基于皮尔逊相似性的协同过滤算法(UPB-CF)、文献[11]提出的用户特征的协同过滤算法和本文提出的基于用户特征的协同过滤算法做对比,四种方法的最近邻用户取值区间均为[5,50],增量为5,则MAE的结果如图7所示.
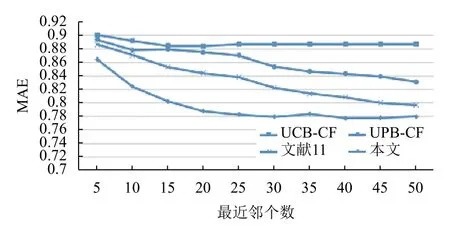
图7 MAE值比较
由图7可知,当用户最近邻个数在[5,50]之间变化时,四种推荐算法的MAE都逐渐下降,但本文提出的基于用户特征的协同过滤算法在融合用户属性、兴趣度和信任度之后,得到的平均绝对误差都比其他三种算法要小,推荐质量要好.
4 结论与展望
通过分析传统协同过滤算法的问题,本文综合考虑提出了一种融合用户属性、用户兴趣度和信任度的基于用户特征的协同过滤推荐算法. 通过分析对比实验证明,本文提出的算法在一定程度上能改善新用户的冷启动、数据稀疏性和推荐准确性等问题,有效的提高了推荐质量. 接下来的工作还要研究用户兴趣随时间变化对兴趣度的影响,此外,如何获取信任模型中更好的传递规则也是需要继续深入研究的课题.
