基于GIHCMAC神经网络的建筑电负荷预测方法①
2019-08-22吴盼红段培永丁绪东尹春杰姬晓娃
吴盼红, 段培永, 丁绪东, 尹春杰, 姬晓娃, 邱 钟
1(山东建筑大学 信息与电气工程学院,济南 250101)
2(山东省智能建筑技术重点实验室,济南 250101)
3(山东师范大学 信息科学与工程学院,济南 250358)
建筑作为能源消耗的主要领域,在2015年消耗总量高达8.57亿吨标准煤,占全国能源消费总量的19.93%,其中公共建筑能耗占建筑总能耗的34%[1]. 由于社会经济的发展,公共建筑数量不断增加,促使建筑能耗占全国总能耗的比例也越来越大. 目前,随着我国节能政策的实施,构建快速、准确的建筑电负荷预测模型,合理分配能源显得十分重要.
近年来,国内外学者对建筑电能耗预测方法进行了广泛的研究,主要包括回归预测法、神经网络法和支持向量机等. 李婉华等建立基于时间序列的随机森林用电负荷预测模型,降低了预测误差[2]; 黎祚等使用k-means聚类、BP或RBF结合的方法建立负荷预测模型[3,4],上述两种方法均取得较好结果,但其方法需获得大量建筑能耗数据. Chae等采用人工神经网络建立短期建筑能耗预测模型,可提前预测一天的用电量及日常高峰用电量[5],但其易陷入局部最优;王义军等采用PSO-SVM神经网络模型预测短期电力负荷,提高了预测精度,但结果易受核函数的影响[6]. 李明海等研究了一种基于GM-BP神经网络的预测模型预测校园能耗,预测精度和拟合性有所提高,但模型训练时间较长且收敛性不足[7]; Zhang Y等研究了一种基于PSO-RBF神经网络的建筑能耗预测模型,提高了预测精度,但其需要的训练样本较多,运算量大[8].
基于聚类的超闭球小脑模型关节控制器HCMAC(Hyperball Cerebellar Model Articulation Controller)神经网络是在CMAC神经网络的基础上学习而来的[9],具有局部泛化能力强,模型结构简单,收敛速度快,易于软硬件实现等优点. 将其应用于建筑电负荷预测的关键在于聚类中心即网络节点的获取,现有聚类算法采用的终止条件以及模糊聚类方法,可能导致聚类结果不能到达最优结果. 因此,文章采用遗传算法(Genetic Algorithm,GA)与蚁群聚类算法(Ant Colony Clustering Algo-rithm,ACCA)相结合的方法来确定聚类中心以及聚类数目,建立基于遗传算法与蚁群聚类算法的超闭球小脑模型关节控制器GIHCMAC(Genetic Algorithm Ant Colony Clustering Algorithm based IHCMAC)神经网络预测模型,实现办公建筑电负荷的准确预测.
1 基于GIHCMAC的建筑电负荷预测
1.1 基本原理
1.1.1 IHCMAC神经网络
IHCMAC神经网络[10]输入空间的量化不再使用等网格划分的传统方法,而是采用模糊C均值聚类算法(FCM)[11],降低了高维数据处理的复杂性. 首先对输入进行归一化处理得到m维的输入空间=[0,n]1×[0,n]2×···×[0,n]m,然后用FCM聚类算法对输入空间x¯进行聚类,得到L个聚类中心值,即网络节点p=[p1,p2,···,pL],每个节点都是一个m维向量pi=[pi1,pi2,···,pim],i=1,2,···,L. 定义一个中心为xk,半径为的超闭球,当超闭球内的节点被激活时,IHCMAC神经网络可由式(1)表示为:
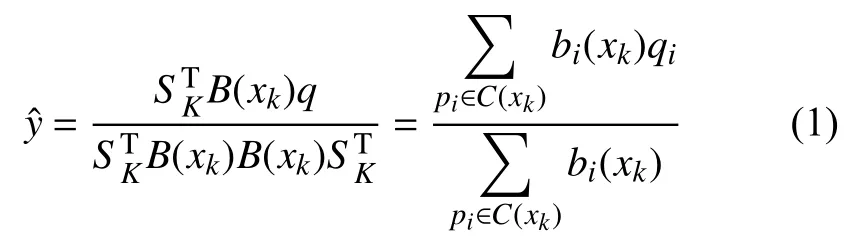
权值训练算法采用改进的C-L算法,由式(2)表示为:
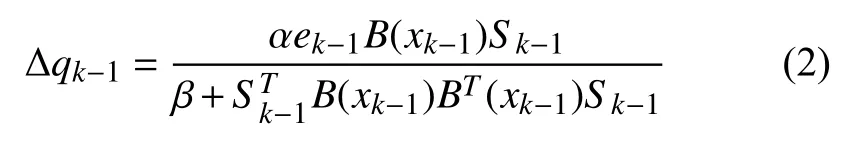
式中,α,β为常数; ek-1为估计误差,当0<α<2、β>0时,算法收敛,对于不同样本,只需局部调整权系数即可[11].
1.1.2 蚁群聚类算法
蚁群算法[12]是1991年由意大利学者DorGIo M提出的一种模仿蚂蚁群体行为的仿生优化算法,2004年Shelokar将蚁群算法运用于聚类分析中,提出基于蚁群觅食原理的聚类算法(Ant Colony Clustering Algorithm,ACCA)[13]. 蚂蚁觅食时会释放随时间推移而挥发的信息素,当某一路径上走过的蚂蚁数量越多,该路径上的信息素强度就会增加,从而吸引更多的蚂蚁,这一过程也称为正反馈. 通过这种正反馈机制,蚂蚁最终可以找到从蚁穴到食物源的最短路径[14]. 蚁群算法就是利用这种原理来求解最优解的.
1.1.3 遗传算法改进蚁群聚类
IHCMAC神经网络算法采用FCM聚类的方式确定网络节点,虽然解决了高维数据处理过程中的维数灾难问题,但不能反映输入数据的整体特征. 聚类终止条件是人为确定的,并且由聚类准则函数收敛速度判断聚类数目的缺陷,增加了运算量,而且对训练模型的精度有着较大的影响.
蚁群聚类算法虽然可以较好的弥补IHCMAC算法的缺陷,但其依赖于初始聚类中心的选择,且易陷入局部最优的问题,使聚类效果不够理想,直接影响了预测模型的学习精度. 遗传算法是一种比较常用的随机搜索算法,能在很大程度上减少陷入局部最优的情况. 因此,文章采用遗传算法改进蚁群聚类[15,16],首先,蚁群算法快速地完成初始路径的选择,得到各个样本到其对应的聚类中心的总偏离误差F,作为遗传算法的初始种群进行全局搜索,得到最佳聚类中心. 具体步骤如下:
(1) 初始化. 设定各参数σ、α、β,蚁群数A,聚类数K,最大迭代次数t_max,阈值P0,变异率pls.
(2) 构造每只蚂蚁的解,计算转移概率P. 若P>P0,则将样本Xi分配到类mk中; 否则,将样本Xi随机分配到类mk中.
(3) 根据式(4)和式(3)计算新的k个聚类中心和适应度值F,同时更新信息素矩阵.

式中,mj为聚类中心,J为该聚类中所有数据对象的个数,i=1,2,…,n位样本数据个数,j=1,2,…,k为聚类数目.
(4) 比较A只蚂蚁求的目标函数值的大小,选出最小的记为此次迭代的最优值,确定最佳路径.
(5) 根据最佳路径产生n维随机数组rp,若rp(i)≤pls,则对最佳路径进行变异,产生新的聚类中心,并计算新路径下的适应度值F_temp. 若F_temp<F,则新路径为最佳路径; 否则转步骤(3).
(6) 若满足结束条件t>t_max,则输出全局最优解;否则迭代次数t=t+1,转步骤(2).
文章采用遗传算法优化蚁群聚类算法,改进了IHCMAC算法中确定神经网络节点的方式,最终得到GIHCMAC (GA ACCA Improvement Hyperball CMAC)神经网络算法.
1.2 模型构建
以位于潍坊市某一办公建筑为研究对象,获取实测数据. 每5 min采集一次,采集2018年10月8日到14日一周的用电数据,共2016组作为训练数据,分为1008组学习样本和1008组测试样本,其中2018年10月8日8:00-11:00的数据如表1所示. 模型的输入为前两个时刻的数据Pt-2,Pt-1,输出为Pt. 模型的流程图如图1所示,将输入数据进行归一化和滑动平均滤波处理,利用遗传算法优化蚁群聚类算法来确定网络节点,构建GIHCMAC神经网络预测模型,最后输出模型误差值及建筑电负荷预测值.
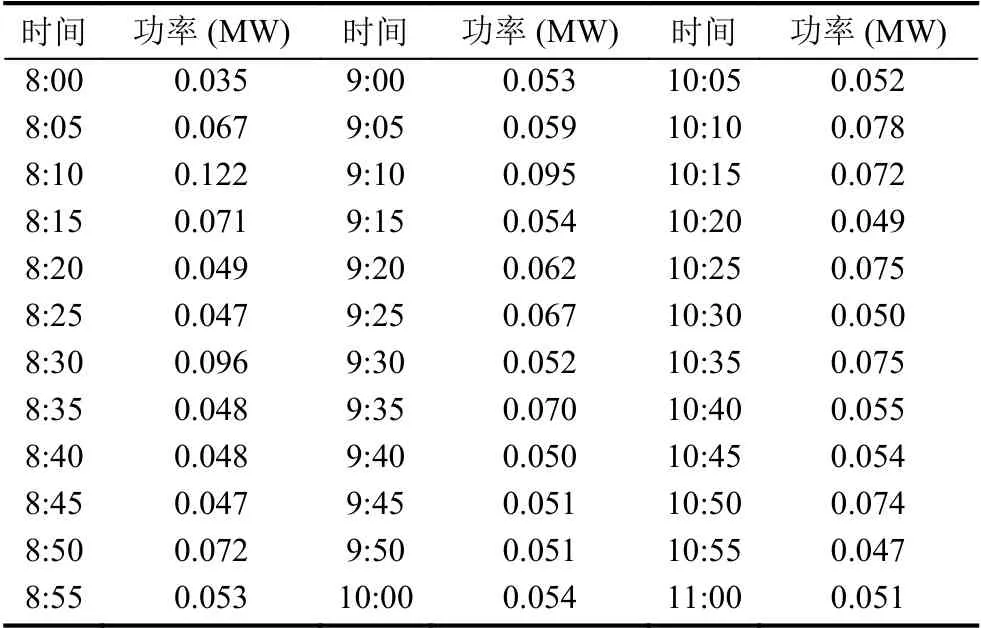
表1 样本部分数据
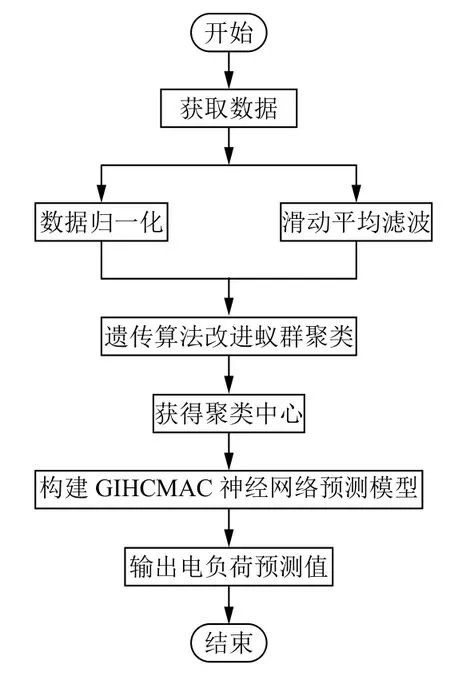
图1 GIHCMAC神经网络建筑负荷预测流
2 实验仿真
2.1 数据处理
2.1.1 数据滤波去噪
实际数据在采集过程中,会因为受到外界其它因素的影响产生干扰数据. 因此需要对数据进行滤波处理,去除噪声. 滑动平均滤波法原理简单,通常去噪效果比较好[17]. 设原始数据序列为fi(i=1,2,…,N),N为样本数,在固定窗口M中,每采集一个新数据放入序列列尾,则丢掉原始数据序列列首的一个旧数据,并进行平均运算,得到新的滤波数据,其一般表达式为:
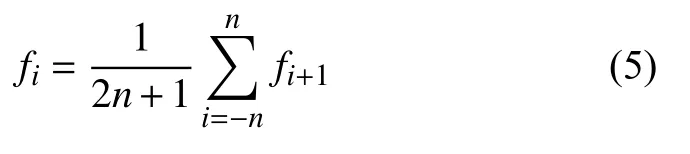
式中,i=n+1,n+2,…,N-n,M=2n+1.
2.1.2 数据归一化
在进行建筑能耗预测仿真之前,需要将所有数据进行归一化处理,即把所有建筑能耗数据都转化为[-1,1]之间的数值,使所有数据都在统一的尺度内,防止不同数量级引发建模病态问题.
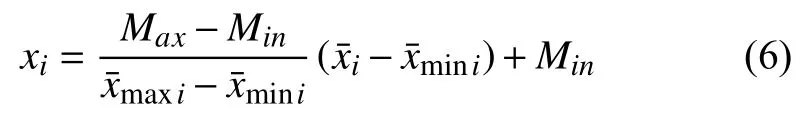
2.2 性能指标
以MATLAB R2014a为实验平台对模型进行仿真,编写IHCMAC[18]、KHCMAC[19]、IKHCMAC[20]及文中建立的GIHCMAC神经网络模型程序,以均方根误差RMSE作为训练模型的评价指标,泛化误差GMSE作为测试模型的评价指标,分别由式(7)、式(8)表示为:
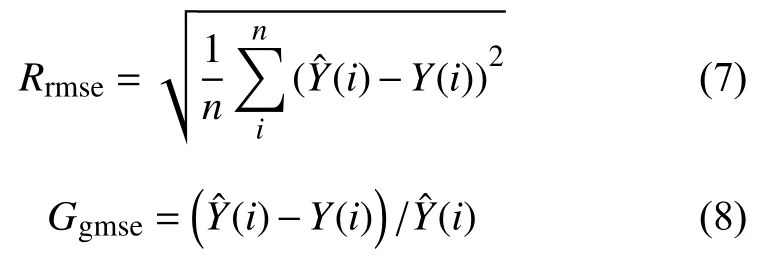
2.3 数据分析
根据上述仿真实验,通过聚类得到神经网络节点150个,用学习样本对三种预测模型进行训练,实验参数设定:蚁群规模A=100,最大迭代次数t_max=100,σ=0.7,α=0.5,β=0.2,P0=0.9,pls=0.1. 表2列出了4种模型的性能评价参数,图2为四种模型的学习误差与泛化误差曲线图,图3为建筑电负荷400组数据实际值与预测值的对比曲线图. 根据仿真结果表明,IHCMAC神经网络模型的迭代次数为25次,较KHCMAC神经网络模型和IKHCMAC神经网络模型收敛速度较快;而GIHCMAC神经网络模型因在蚁群聚类算法的基础上加入了局部寻优阈值pls (变异率),减少运算次数,加快了收敛速度,所以其迭代次数降为9,较IHCMAC神经网络模型降低了64%. IHCMAC模型的训练误差为0.0092,较小于KHCMAC、IKHCMAC两种模型的训练误差,而GIHCAMC模型的训练误差为0.0053,较IHCMAC模型降低了42.39%,其具有更好的学习精度. IHCMAC模型的泛化误差为0.0022,较小于KHCMAC、IKHCMAC两种模型的泛化误差,而GIHCMAC模型的泛化误差为0.0015,较IHCMAC模型降低了31.82%,其泛化能力更强. KHCMAC模型的迭代时间为3.75 s,低于其它三种模型. GIHCMAC模型的迭代时间为5.16 s,虽然后者的迭代时间略大于前者,但是后者的误差较小,证明在保证预测精度的前提下其实时性相对较 好. 由表3可以看出基于遗传算法改进的蚁群聚类的聚类效果方面优于蚁群聚类算法.
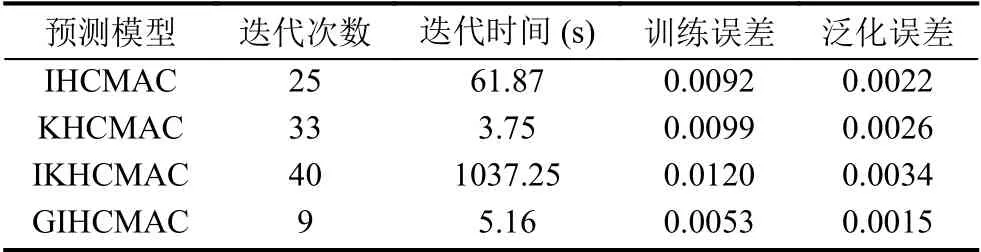
表2 4种模型性能参数
3 结论
文章针对蚁群聚类算法与遗传算法的特点,将两者相结合,弥补蚁群聚类算法易陷入局部最优的缺陷,实现对IHCMAC神经网络节点选择的优化,建立基于GIHCMAC神经网络的办公建筑电负荷预测模型. 通过此模型,得知前两个时刻的电负荷值,则可以预测得到后一时刻的电负荷值. 实验表明,该算法与IHCMAC神经网络方法、KHCMAC神经网络方法、IKHCMAC神经网络方法相比,收敛速度快,学习精度高,泛化能力强.
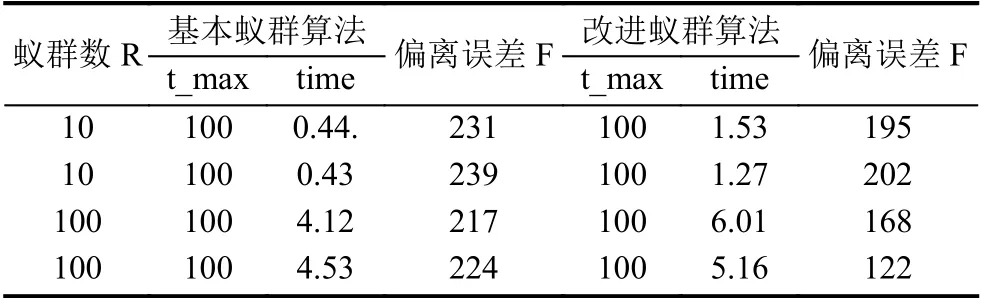
表3 改进前后聚类效果对比
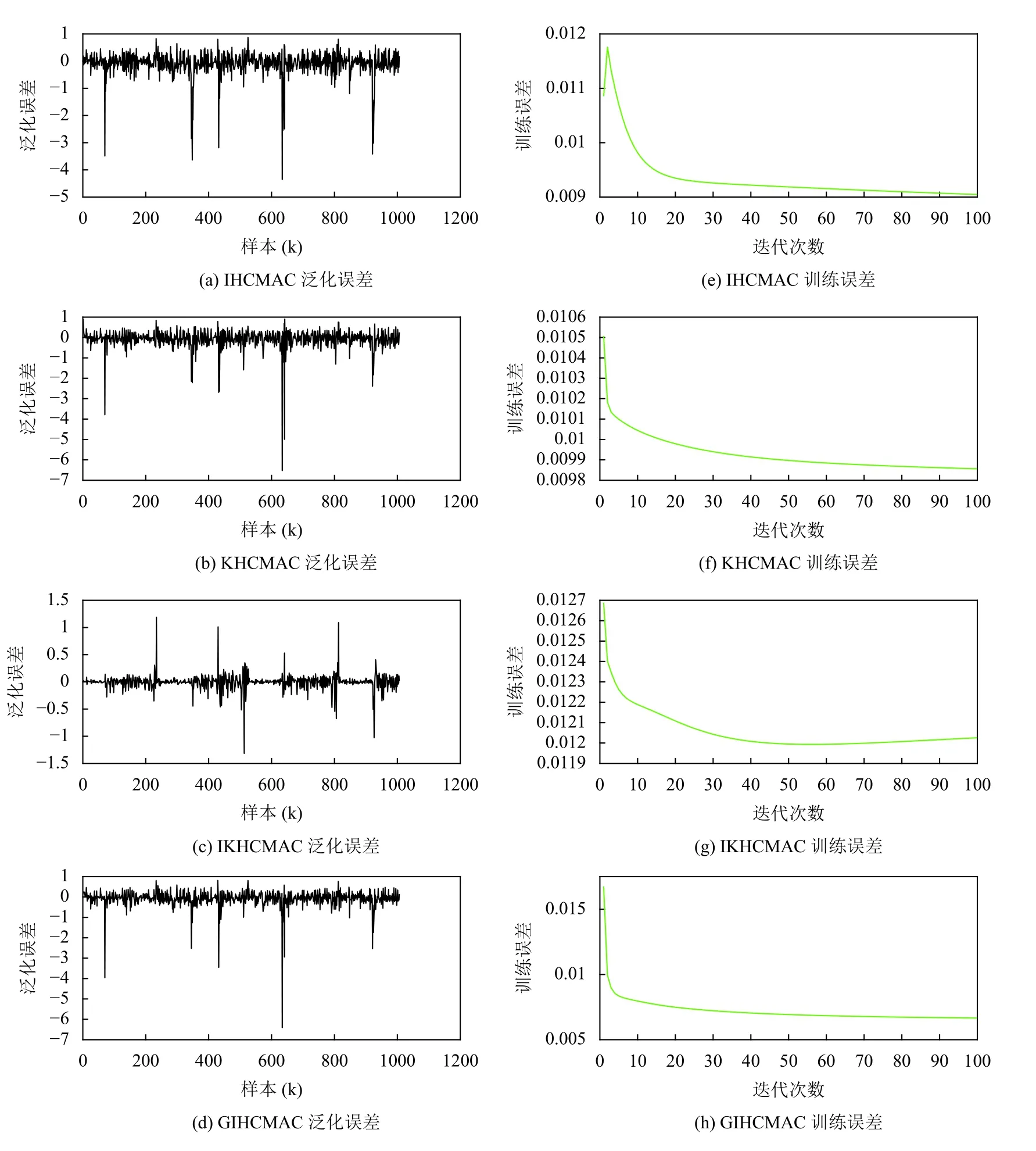
图2 4种模型的学习误差与泛化误差曲线
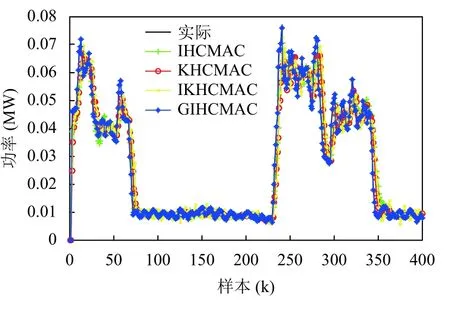
图3 实际电负荷与模型预测值对比曲线
