机器学习在湍流模型构建中的应用进展
2019-08-21张伟伟朱林阳刘溢浪寇家庆
张伟伟,朱林阳,刘溢浪,寇家庆
(西北工业大学 航空学院,西安 710072)
0 引 言
湍流问题涉及到工程中的诸多领域,其重要性不言而喻。人们对于湍流的探索和研究也从未间断。快速畸变思想[1-2]和各种标度率的提出以及拟序结构[3]的演示促进了人们对湍流的认识。随着计算机的迅速发展以及粒子图像测速仪(PIV)的应用,人们对湍流的研究更加深入细致。我国的湍流研究在前辈学者的引领下起步很早[4],近些年也取得了可观的研究成果。佘振苏教授等[5]提出了基于结构系综理论(SED,Structural Ensemble Dynamics)的新模型(SED-SL),陈十一院士团队[6]提出了带约束的湍流大涡模拟方法,何国威院士等[7]综述了在欧拉与拉格朗日两种参考系下的各种时空关联模型,等等。经过前人的不断努力,人们对湍流的认识不断加深,但湍流的本质问题[8]以及在工程中的高效应用仍未得到很好的解决,湍流仍然是航空航天航海等领域工程成败的关键瓶颈之一。湍流的本质、湍流演变的物理规律,以及如何在工程中更好地应用湍流,一直是研究者们不断探索的研究方向。
湍流研究的数值计算方法可根据网格分辨尺度分为直接数值模拟(DNS)、大涡模拟(LES)和雷诺平均应力模型(RANS)。随着计算机性能的提升和并行算法的开发,DNS和LES越来越多地在学术界和工业界得到应用。但是,对于复杂的几何外形和高雷诺数流动而言,急剧增长的网格量很大程度上限制了这两种方法的应用范围,对于飞行器在飞行包线中的计算恐怕要到2030年才能实现[9]。相比之下,RANS模型虽然精度不及前两种方法,但其易用性和高效性使之在工程实践中得到广泛应用[10]。特别是在航空航天领域,流动的雷诺数普遍较高,湍流计算主要依赖于现有的RANS模型。
RANS模型大多基于涡黏假设,在附着流中容易取得较好的计算结果。对于分离流等复杂流动,雷诺应力与应变之间不再是简单的线性相关,其各向异性使得湍流的模型化变得明显困难[11],因此,RANS模型的计算结果往往偏差较大而不可靠。另一方面,模型中的经验性参数往往是依据某些特定的流动确定的,一定程度上也增加了模型的不确定度,继而影响模型的适用性。目前常用的RANS模型还是20世纪提出的,主要有Baldwin-Lomax(BL)模型[12]、k-ε模型[13]、k-ω模型[14]和Spalart-Allmaras(SA)模型[15]等。另外,可视具体工程问题采用SST模型[16]、k-ω2模型[17]、k-τ模型[18]以及一些修正的k-ε模型[19]等。与一阶矩封闭模式不同,雷诺应力输运模型(RSTM)是基于雷诺应力输运方程的二阶矩封闭模式[20]。该模型虽然精度较高,但计算效率和鲁棒性有待进一步提高,尚未在航空工程中广泛采用,许多CFD研究者也在致力于这一问题的改善。近年来,佘振苏等人[21-22]基于李群理论提出了解析的应力长函数表达式以描述壁湍流中的多层结构。从历史过程可以看出,RANS模型的发展已经到了平台期,难以取得新的突破来克服其固有的缺陷,湍流问题的求解亟待新思路、新方法的涌现。
实际上,针对复杂静/动力学系统模型化主要有两个途径。第一个是基于理论的模型架构,即根据物理问题的控制方程,建立理想的系统描述。这种模型通常需要研究者对物理过程有深刻的理解,并将其转化为数学模型,现行的湍流模型大都是采用这个途径。第二个则是数据驱动方法,即根据系统仿真或试验中的样本数据,直接构造黑箱或灰箱模型。近年来,随着计算机性能和精细化流动测试手段的发展,研究者逐步能够获得高精度、高时空分辨率的流场信息,或者直接通过开放的平台(如http://turbulence.pha.jhu.edu/)获取。如何高效地利用这些大数据,从中提取出关键信息,并指导流体力学的发展,已经成为研究者关注的焦点。作为处理和分析数据的主要手段,数据挖掘、统计学习和机器学习等技术,则为开展此类研究提供了重要基础。机器学习通过一些算法从数据中建立模型,使之具备一定的判断和预测能力。常用的算法有径向基神经网络(RBFNN)、随机森林(RF)、支持向量机(SVM)和神经网络(NNs)等。这些算法已广泛应用于语音和图像识别[23-24]、信号处理[25]以及降阶处理[26]等领域。
流体力学研究者也已将这些方法成功用于各自领域的相关研究工作中,例如偏微分方程求解以及非线性动力学特征的模拟等。在湍流领域,国内外的专家学者也加快了机器学习方法在湍流建模中的应用步伐。早期的研究工作主要是探讨与湍流相关的变量之间的关系,采用的方法也较为简单[27-28]。实际上,正式采用数据驱动方法来改善或替代RANS模型的研究主要是近几年开展的[29]。逐渐地,研究者开始侧重于对RANS模型的改善以及更复杂机器学习方法的应用。Tracey等人[30]针对二维及三维流动,构建了替代SA模型中源项的神经网络模型。除了以RANS模型控制方程中的某些项作建模对象,研究者还针对修正系数分布或附加源项建立数据驱动模型并以此来改善原RANS模型的计算精度[31-33]。Wang等人[34]针对RANS模型和高分辨率数据之间雷诺应力偏差构建模型,提高了RANS模型的准确性。上述工作主要是利用机器学习方法来完善RANS模型,以获得更高的计算精度。Ling和Templeton等人[35]通过深度神经网络方法计算了雷诺应力的各向异性分量,并显示了二次流中的旋涡结构和波形壁中的分离现象。除了应用于RANS模型,数据驱动方法也已用于模型化LES中的湍流相关变量。Gamahara等人[36]针对亚格子应力张量的分量分别建立了人工神经网络模型。Maulik等人[37]采用人工网络模型预测了时空变化的湍流源项。Wang等人[38]用不同机器学习方法和特征研究了亚格子应力封闭。这些研究工作仅以高分辨率的数据作为驱动,一定程度上降低了模型封闭或湍流相关变量模型化的难度,证实了纯数据驱动的黑箱模型在湍流研究应用中的可行性。另一方面,一些研究者还将机器学习用于描述和量化传统模型计算结果的不确定度,对未来的建模工作具有很好的指导作用。目前主要的研究方向和建模流程可大致归结为图1所示。

图1 机器学习应用于湍流研究的主要研究方向及流程Fig.1 Main research direction and process of machine learning applied to turbulence study
机器学习在湍流研究中的快速发展在一定程度上也得益于诸多广泛使用的开源平台。目前,TensorFlow、Keras、Theano以及Matlab等平台为开展学习工作提供了有力支持。这些平台大都内嵌了多种学习框架供用户选用,如RBFNN、RF以及更复杂的深度神经网络(DNN)和卷积神经网络(CNN)等。同时,模型的超参数优化可采用随机梯度下降(SGD)、动量随机梯度下降(SGDM),以及Adam算法等实现。此外,基于CPU或GPU的并行算法缩短了湍流大数据的模型优化过程。这些开发平台的使用大大提高了研究者的工作效率,便于迅速开展并推进研究工作,而且,代码的通用性也有助于研究者之间的相互交流和探讨。
机器学习与湍流建模相结合的研究工作是流体力学领域新兴的研究方向。现有的研究成果有力地验证了其可行性,预示了机器学习在未来湍流模型应用中的积极前景[39]。与此同时,研究者也面临着诸多问题与挑战。一方面,现有的研究主要是基于DNS和LES计算的高分辨率数据,因此,选取的算例多是针对简单几何体的中低雷诺数流动问题,如平板和管流等。然而,工程中的高雷诺数湍流,如机翼和翼型绕流,则难以获取高分辨率数据,如何将机器学习应用于这一领域的湍流计算值得进一步探索。另一方面,模型的泛化能力和鲁棒性以及稳定性需要进一步提高。现有研究中,当预测数据与训练数据差别较大时或者几何外形发生变化时,模型的表现会不同程度地下降。这在一定程度上是数据驱动方法本身固有的缺陷,另外,模型构建过程中的一些方面,如数据处理与特征构建、模型对象的选取以及约束性条件的施加也会影响模型的最终性能。模型与求解器的耦合需要额外地考虑模型的稳定性。一种耦合形式我们称之为“松耦合”,其过程是先通过RANS基模型与N-S求解器求解出初始流场和雷诺应力场,然后,所构建的机器学习湍流模型根据已获得的初始流场构建模型输入并展开预测。通过模型的预测值更新初始的雷诺应力,将改善的雷诺应力直接传递给求解器。另一种则与传统RANS模型相同,所构建的模型在从初始流场开始的每一迭代步都与求解器之间互相反馈,直至N-S方程求解器获得收敛解,我们称之为“紧耦合”,如图2所示。其中,稳定性问题在后者中表现得更明显。
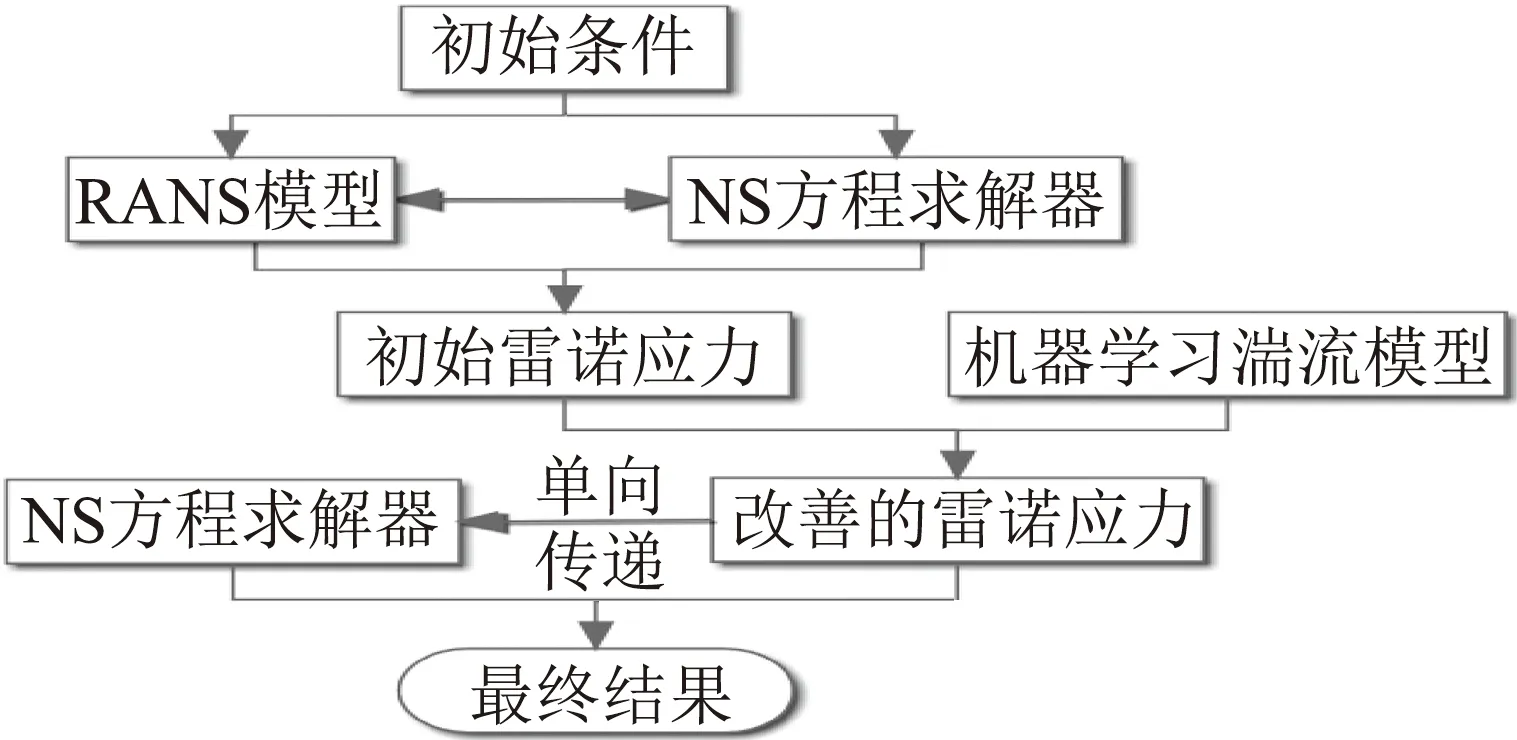
(a)松耦合

(b)紧耦合图2 机器学习湍流模型与CFD求解器的耦合Fig.2 Coupling of machine learning turbulence model with CFD solver
1 机器学习建模过程
基于机器学习方法的模型构建过程主要包含数据处理、特征选取以及模型框架的确定及参数优化等几个方面。针对每一方面,研究者又可以采取不同的方法,例如模型框架可选择网络模型或树模型,激活函数可选择tanh或ReLu等等。这些方面在不同程度上影响模型的性能。Ling等人[40]比较了不同的分类器在预测湍流模型不确定度中的应用,Zhang等人[41]比较了不同输入对结果的影响,等等。模型框架和参数优化方法的种类繁多,在分类和回归以及各自对应的特定问题中通用性较差,难以界定某种模型或方法的具体优劣性。但是无论采用什么方法,特征选择和数据处理都是研究者普遍面临的问题。
1.1 特征选择
特征选择主要是为了选出相关的和有用的特征,降低特征的冗余度,另外还有减少特征集,提高模型性能和数据理解等的作用。在实际应用中,过多的特征不仅会减缓学习过程甚至会干扰学习算法。需要注意的是,特征选择对不同机器学习算法的效果不同,有时反而可能会降低模型性能[40]。目前,常用的特征选择算法有滤过法,打包法和嵌入法[42],但在机器学习湍流研究中,这些算法的应用还较少。湍流的物理机理复杂,特征选择的难度较大,甚至被假定为最大的挑战[30]。研究者主要是根据物理知识或已有的控制方程和表达式进行经验性的选取和比较。由于不同研究的建模对象不同,研究者根据自身经验进行的特征选取往往通用性差且存在一定的偶然性。Ling等人[43]提出具有不变量属性的输入特征,并与不具备该属性的特征进行了对比。Wang等人[34]则进一步给出了特征的相对重要性。另外,由于不同的输出与流场变量的相关性不同,模型的输入特征也可予以区别选取[38]。特征选取过程中亦应考虑特征的数据分布范围,尽量保证每一特征的数据分布较为紧凑,避免输入特征和输出中出现极端异值。除此之外,为了避免不同特征间的量级差异,研究者可以对特征进行线性归一化或标准化等处理。
1.2 输入输出数据处理
训练数据可以从湍流数值计算结果中直接获得,也可以根据具体的建模需要间接求得。作为模型的定义域,训练数据所构成的数据空间从根本上决定了模型的性能,其重要性不可忽视。如果训练数据量不大,建模者可以将全部数据用来训练模型。但是对于网格量较大的DNS、LES以及高雷诺数算例,可利用的训练数据往往过多而冗余。如果不加以筛选,过多的样本会导致计算代价大而且训练过程周期长。为此,研究者大多在时间上采用快照,在空间上采用取截面的方法。这种方法虽然简单高效,但是没有摆脱网格划分的影响,也不能直接体现出对流场关键区域的侧重。另一种方法是根据训练数据间的相似性或欧式距离来剔除冗余的样本。这种方法弥补了前者的缺点,但是筛选过程会随着训练数据的增多而变得效率低下。研究者可依据具体问题结合着使用这两种方法。对于模型的输出,当预测算例中出现超出模型泛化能力的流动特性时,模型的某些输出值可能不满足物理规律的约束或者属于明显错误的异值。这些值降低了模型的精度和鲁棒性,因此,可以适当地进行后处理。例如,为了确定数值稳定性,Maulik等人[37]对模型输出作如下截断,
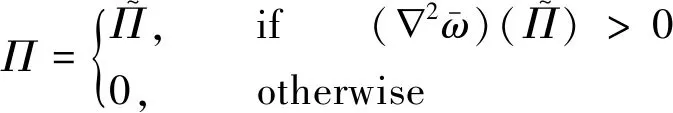
(1)
Ling等人[35]对模型预测的各向异性值进行如下约束,
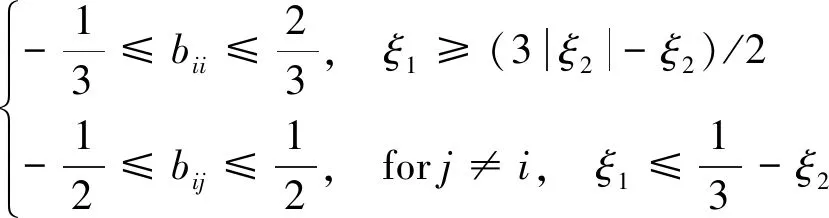
(2)
1.3 模型框架
机器学习方法的多样以及相对应的超参数极大地丰富了模型框架的选择性。主要的模型框架及其在湍流中的不同应用如表1所示。这些模型框架都能够用于构建复杂的非线性映射关系,研究者可根据具体问题具体选择。模型的超参数可通过不断调整和对比结果来确定,也可借鉴于某些超参数优化算法,如Spearmint、Hyperopt等等。在超参数的优化过程中,除了考虑模型在训练集上的精度外,亦应考虑其在验证集或后验测试中的表现。

表1 主要的模型框架及应用Table 1 Main model framework and appliance
2 机器学习在湍流模型中的应用
经过近几年的努力,机器学习方法在湍流研究中的应用得以迅速发展。在应用范围上,目前已开展了平板、管流及翼型等几何体的剪切湍流以及分离流、二次流等复杂流动现象的建模工作。在应用程度上,机器学习不仅用来构建流场变量之间的复杂映射关系,还直接应用于雷诺应力的计算。特别地,根据模型作用可将现有的研究工作大致分为三类:模型的不确定度分析,改善湍流模型,以及替代湍流模型。
2.1 湍流模型的不确定度分析
与真实的物理解或高分辨率结构相比,模型的计算结果往往存在一定的不确定度,其主要来源于NS方程的系综平均计算、模型封闭函数形式、雷诺应力表达式和模型经验参数等。在具体应用中,由于模型之间的封闭形式和经验参数等不同,对不同流动的不确定度也难以把握。对于模型参数和模型形式导致的不确定度,可以采用灵敏度分析、概率分析以及贝叶斯方法等加以量化[47-53]。近年来,机器学习方法开始逐渐被应用于模型的不确定度分析。构建RANS模型参数与参数对应的偏差之间的数据驱动模型,通过计算模型的最小值来确定RANS模型的最优参数有利于提高精度[54]。模型研究者可以通过构建分类器来预测流场中RANS模型的不确定区域,进一步地还可以针对模型所确定的不确定区域采用更好的计算方法[40,55-56]。Singh等人[57]结合流场反演和贝叶斯方法来量化RANS模型的不确定度。更多关于RANS模型或LES的不确定度分析可参考文献综述[58]。
2.2 改善湍流模型
RANS模型由于存在结构和参数上的不确定度,计算精度及适用范围会受到不同程度的限制。对于某些存在激波-边界层干扰的流动或分离流,RANS模型的计算结果往往存在一定的偏差甚至不准确,因此,研究者希望根据高分辨率数据来减小RANS模型计算的偏差,或者使之能够用于分离流的计算。这种采用机器学习方法来改善RANS模型的研究思路大致可分为两类:一种是通过改变模型的控制方程形式,如乘以修正系数或给方程增加源项;另一种是在RANS模型基础上构造偏差函数,然后将RANS模型和偏差函数的计算结果叠加,作为最终的雷诺应力值。
前者主要是针对基于涡黏假设的一方程或两方程RANS模型。研究者首先根据实验结果或高分辨率数据反演计算出引入的修正系数或增加的源项,然后以此作为输出,构建出数据驱动的模型并将其与求解器耦合,流程图如图3所示。譬如,Singh等人[44]通过修正SA模型中的生成项来改变控制方程形式,使得修正后的模型能够用于分离流的计算并取得与实验更相符的计算结果。SA模型的原方程为:
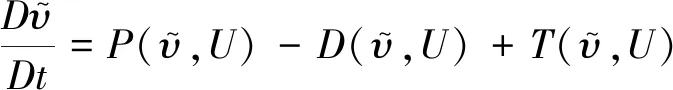
(3)
引入空间变量β(x)作为生成项的修正系数,方程变为:
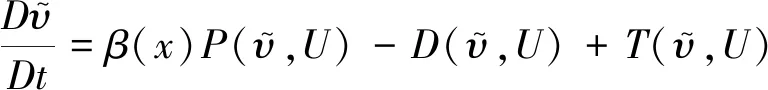
(4)
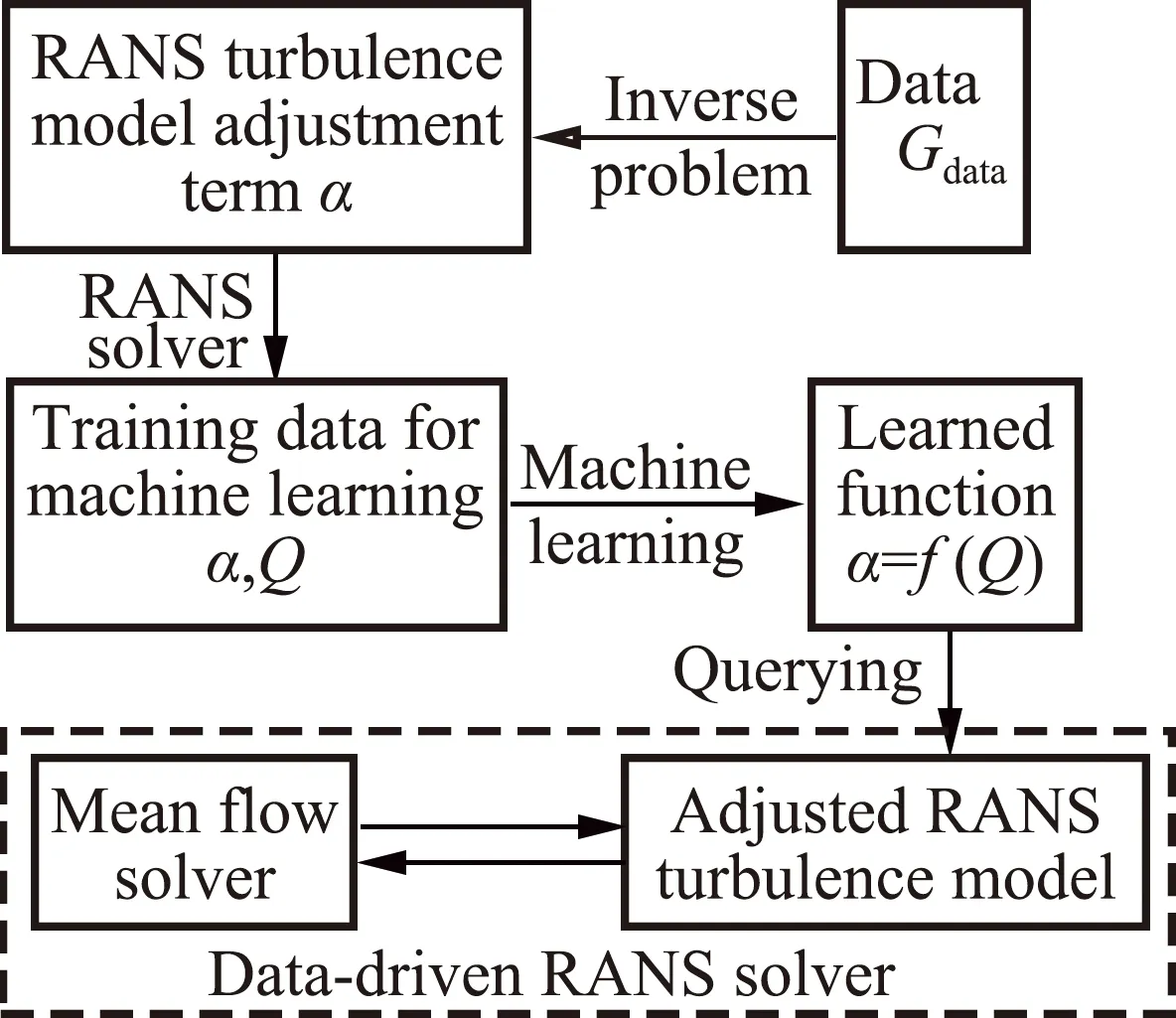
图3 数据驱动的RANS求解器的构建过程[31]Fig.3 Process for building a data-driven RANS solver[31]
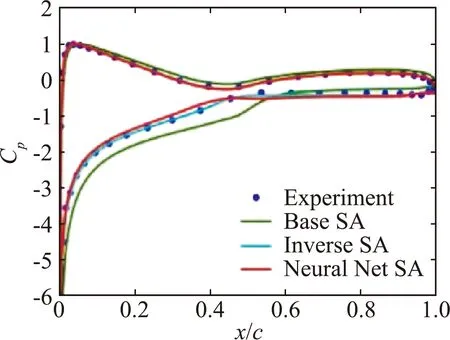
通过实验结果对RANS模型的结果进行优化,利用伴随方法对场反演后得到β(x),然后基于机器学习方法建立流场变量与β(x)之间的映射。所构建的模型具有很好的迁移性,并保证了原模型的收敛性,在不同程度上改善了原模型的计算结果。其中,14°攻角下S809翼型算例的压力对比如图4所示。
相似的研究工作还分别围绕k方程的生成项和转捩模型的源项或汇项等展开[31]。
第二种研究思路不改变控制方程形式,而是对模型计算后的结果加以修正。
τij=τij,RANS+Δτij,Model
(5)
由于基于涡黏假设的RANS模型不能准确地计算各向异性的雷诺应力,因此对二次流和分离流等流动现象的计算偏差较大。Xiao等人[34,59-60]针对RANS模型计算结果和高分辨率数据之间的差异进行建模以修正原模型的计算结果(图5)。在采用数据驱动方法的基础上,研究者强调了雷诺应力的物理约束,提出了“基于物理的机器学习”概念。当训练模型与预测模型相同时,模型能够明显改善RANS模型的计算结果,如图6所示。但是,即便是基于相似的流动现象(分离流),对于几何模型发生变化的区域(周期山的收缩段),修正模型甚至恶化了原RANS模型的计算结果,如图7所示。
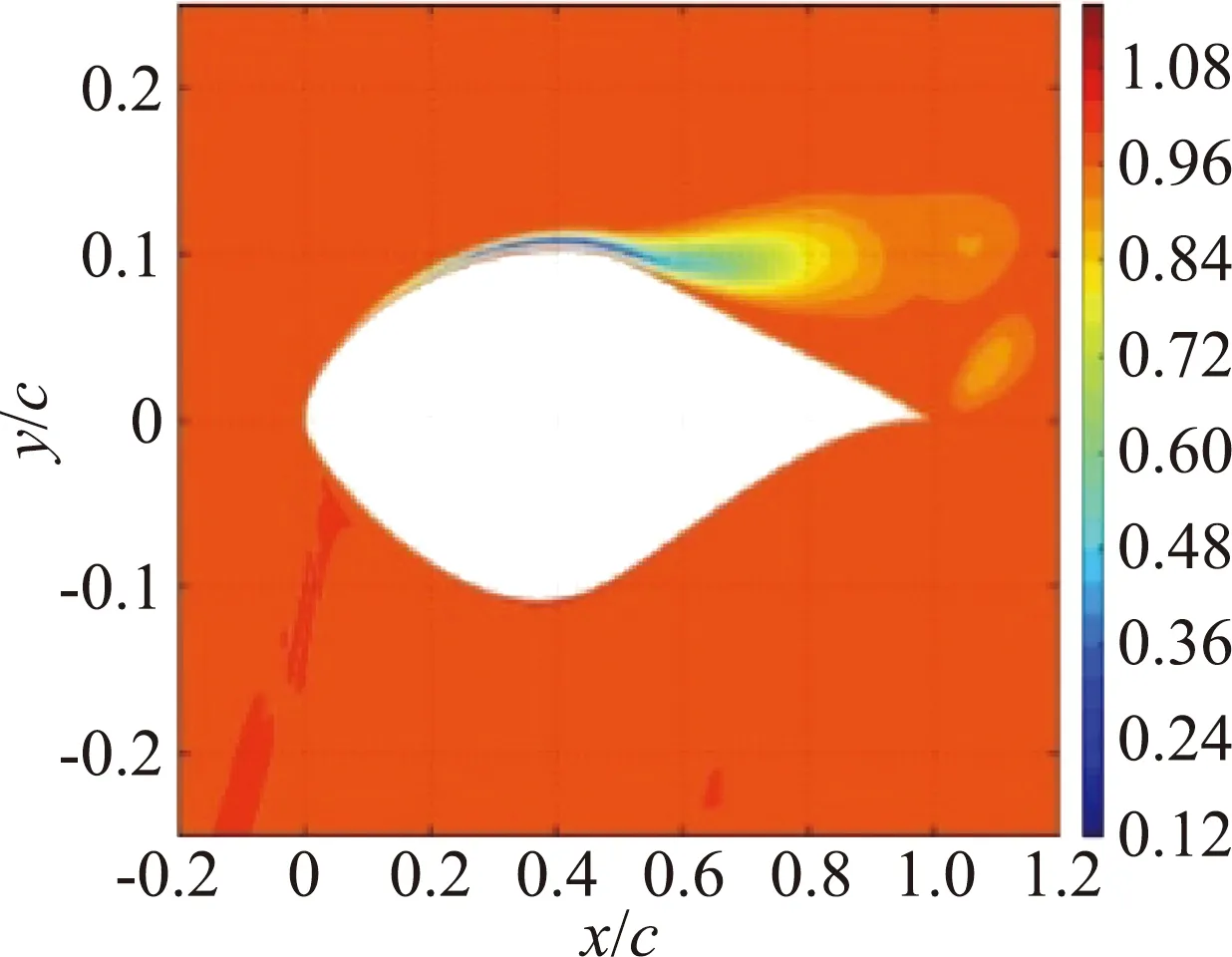
(a)反演求得的β场
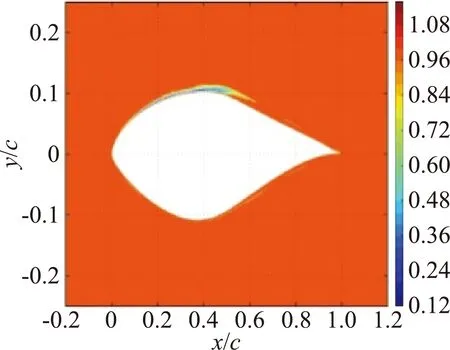
(b)神经网络预测的β场
(c)不同计算结果的对比
图4 S809 翼型在α=14°和Re=2×106时的模型预测结果对比[44]
Fig.4 Comparison of inverse and NN-augmented predictions (using data-set P)for S809 airfoil atα=14°andRe=2×106[44]
图5 湍流预测建模的基于物理信息的机器学习(PIML)框架[59]Fig.5 Proposed physics-informed machine learning (PIML)framework for predictive turbulence modeling[59]
改善原湍流模型以提高其精度的建模思想首先肯定了RANS模型的借鉴意义,本质上是给模型的控制方程增加了一个源项或修正项。基于此而建立的模型我们称之为修正模型。这种修正模型确实在一定程度上提高了原模型的精度,但同时也增加了额外的计算量,降低了整体的计算效率。另一方面,修正模型是针对某个特定的RANS模型所构建的,然而,不同的RANS模型存在不同的不确定度。因此,所构建的模型一般只适于某个特定的RANS模型,这会在很大程度上限制修正模型的使用范围。
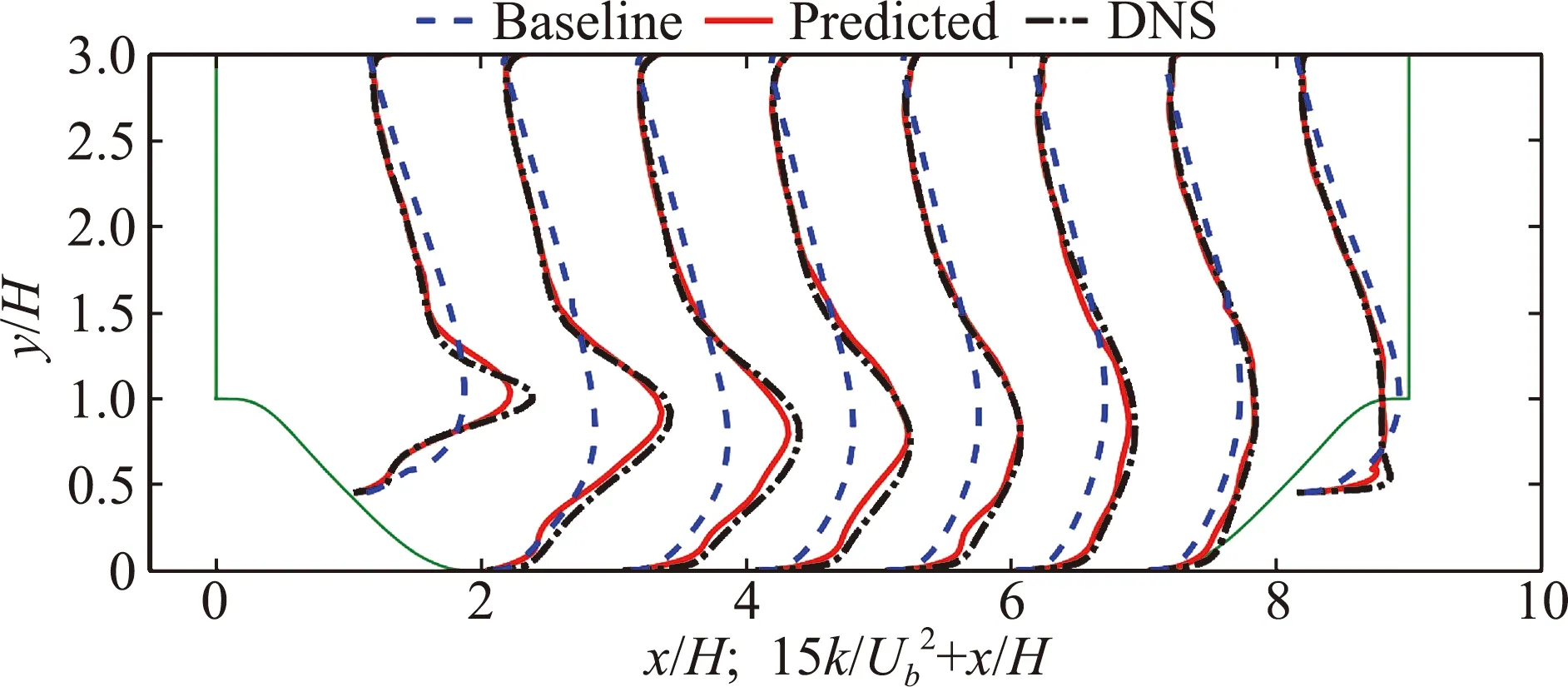
图6 湍流基模型,DNS和PIML预测的湍动能的轮廓对比图(用周期山作训练数据)[34]Fig.6 Profiles of turbulence kinetic energy corresponding to baseline,PIML-predicted and DNS results (flows over periodic hills as training database)[34]
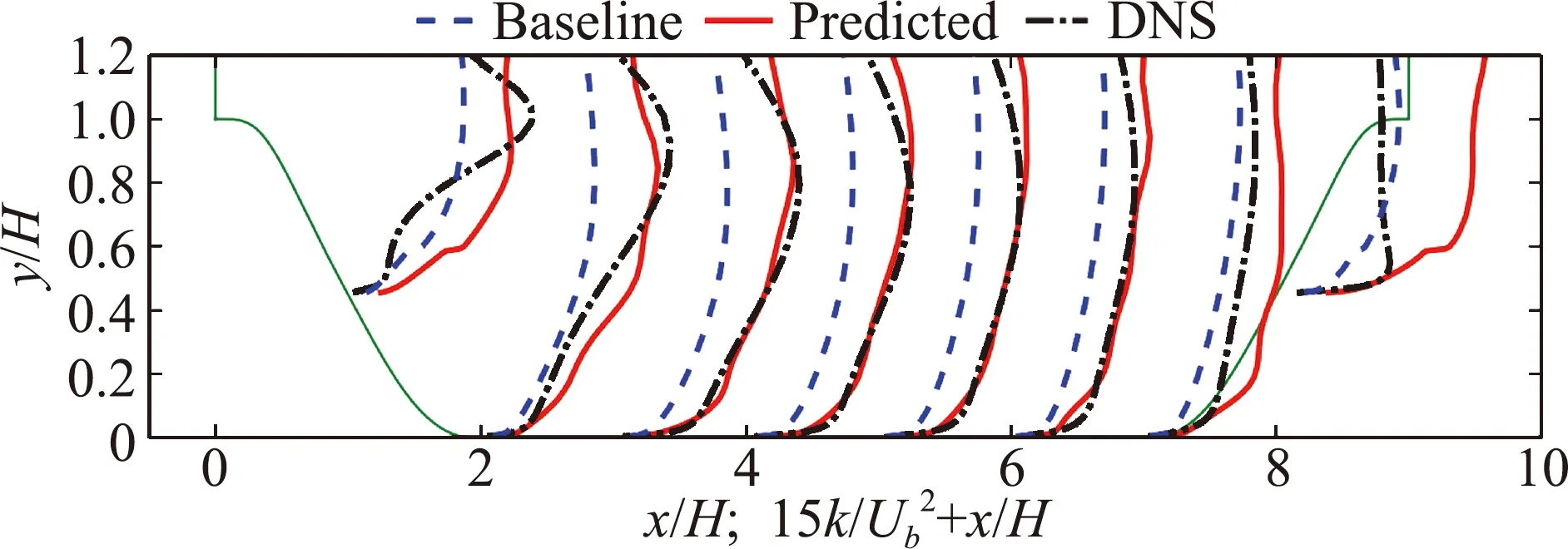
图7 湍流基模型,DNS和PIML预测的湍动能的轮廓对比图(用波形管道和弯曲后向台阶作训练数据)[34]Fig.7 Profiles of turbulence kinetic energy corresponding to baseline,PIML-predicted and DNS results (flows over wavy channels and curved backward facing step as training database)[34]
2.3 替代湍流模型
与构建修正模型的思想不同,替代湍流模型的出发点是希望直接从数据中找出流场变量与湍流之间映射关系。基于此而建立的模型我们称之为替代模型。Ling等人[35]基于Pope推导的基张量和不变量构建了雷诺应力各向异性的张量基神经网络模型(TBNN),如图8所示。其中,雷诺应力各向异性张量b可由基张量T线性表达为[61]:
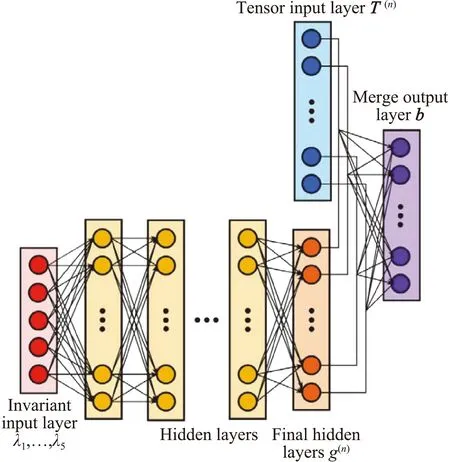
图8 张量基神经网络架构示意图[35]Fig.8 Schematic of tensor basis neural network architectures[35]
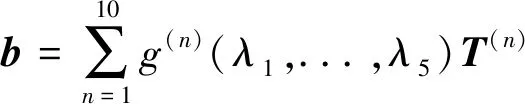
(6)
基张量与不变量的表达式分别如下,
T(1)=S
T(2)=SR-RS
T(5)=RS2-S2R
T(7)=RSR2-R2SR
T(8)=SRS2-S2RS
T(10)=RS2R2-R2S2R
(7)
λ1=Tr(S2),λ2=Tr(R2),λ3=Tr(S3),
λ4=Tr(R2S),λ5=Tr(R2S2)
(8)
其中,I表示单位阵,Tr表示迹,S表示平均应变率张量,R表示平均旋转张量。
该模型能够预测出管流中的角涡和波形壁面的流动分离(图9),这一点是涡黏模型无法实现的。然而,TBNN与求解器之间进行迭代收敛的可行性还有待进一步验证。
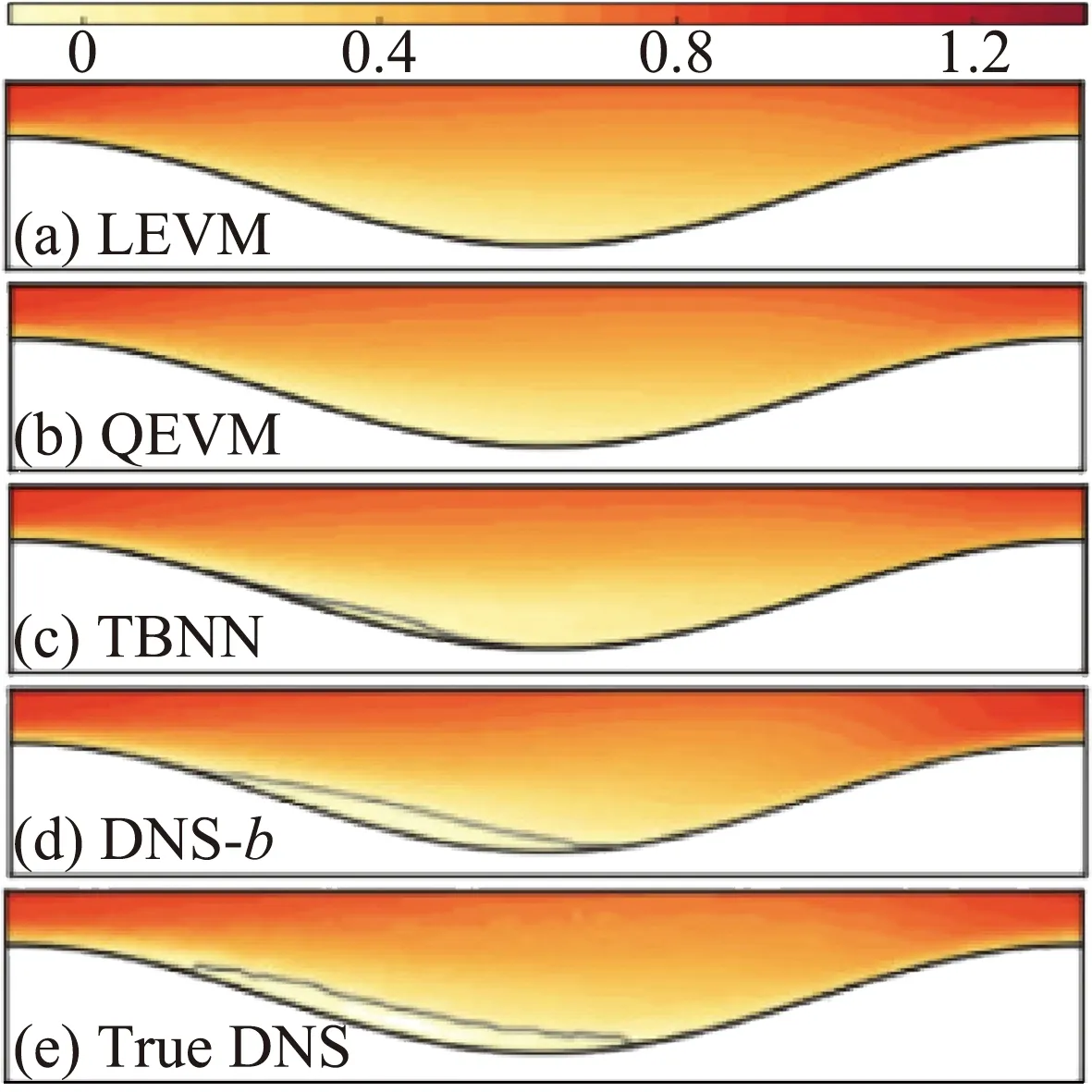
图9 波形壁测试算例中的流向速度云图(分离区用灰线描绘)[35]Fig.9 Contours of streamwise velocity normalized by bulk velocity in the wavy wall test case,zoomed into the near-wall region[35],(separated regions outlined in grey)
Zhu等人[46]探讨了直接构建纯数据驱动的湍流黑箱代数模型,并实现了与求解器之间的耦合计算(图10)。研究结果表明,基于NACA0012翼型的三个亚声速状态算例,所构建的模型可以实现与SA模型相当的精度和更高的计算效率,并对计算状态(图11)和几何外形(图12)具备一定的泛化能力,验证了替代模型的可行性。与修正模型不同,替代模型的性能对最终摩擦阻力的计算结果起决定作用,而且对求解器的收敛性也有重要影响。换言之,模型构建过程对模型输出的精度和光滑性以及模型的稳定性都有很高要求。对于回归问题,损失函数决定了量级大的值比量级小的值容易取得更高的拟合精度,然而,边界层内(尤其是高雷诺数时)的剧烈变化容易导致湍流变量的明显的尺度效应。因此,替代模型很难在整个的训练数据空间中都保证较高的精度。模型性能欠佳的“边缘区域”容易出现异值,继而影响模型输出的光滑性。此外,将所构建的模型嵌入求解器后,模型预测在迭代过程中会存在一定程度的不稳定,残差在下降过程中出现震荡,如图13所示。
纯数据驱动的建模工作亦在二维及三维亚格子应力的模型封闭中开展。Sarghini等人[62]用神经网络方法提高了LES中亚格子应力的计算效率。针对时空变化的湍流源项Π,Maulik等人[37]构建了人工神经网络的亚格子模型,与之相关的涡量-流函数控制方程为:
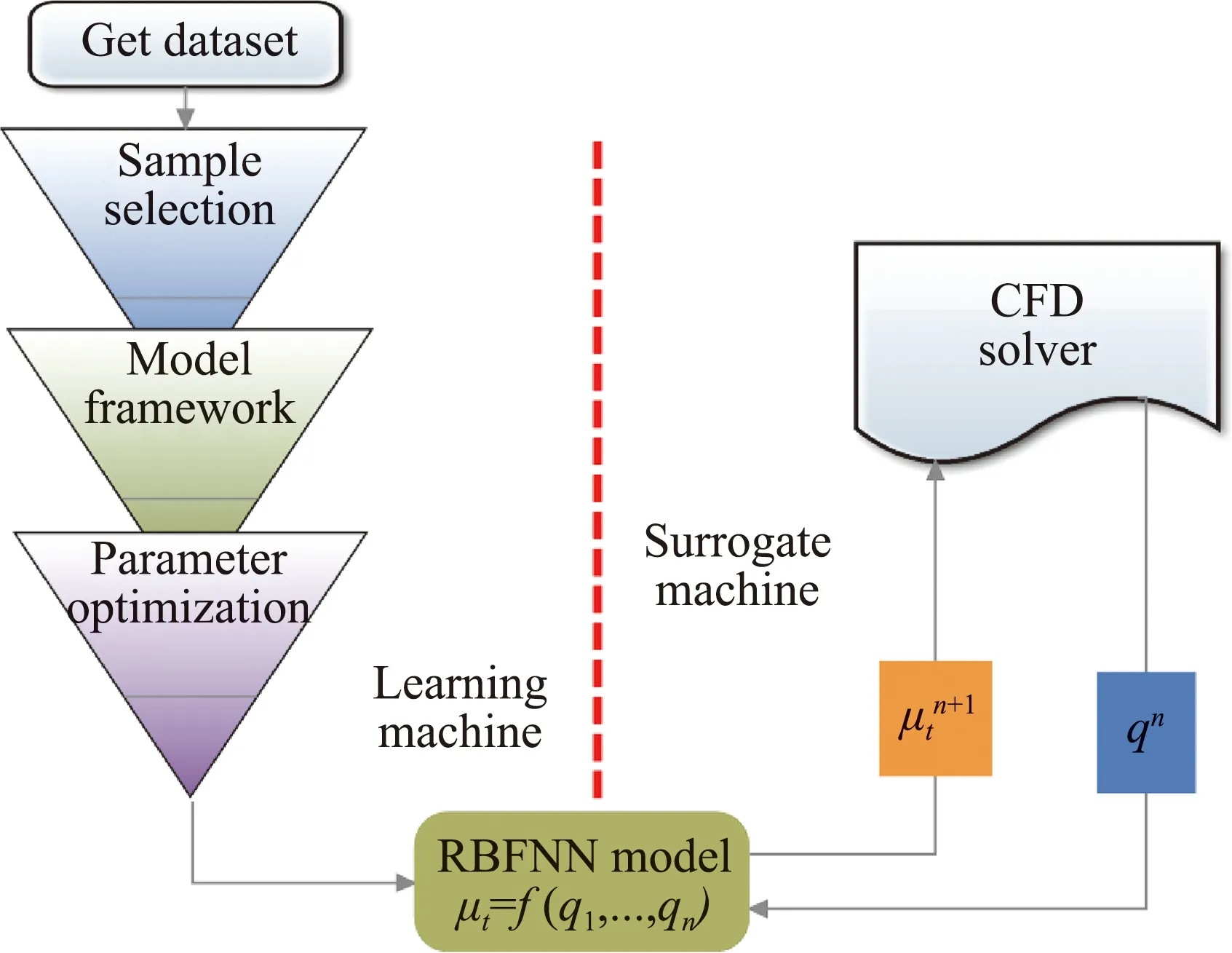
图10 构建学习器和代理器的流程图[46](q和μt分别表示输入特征和涡黏)Fig.10 Flow chart for building the learning machine and surrogate machine[46],(q and μt mean the input features and eddy viscosity,respectively)
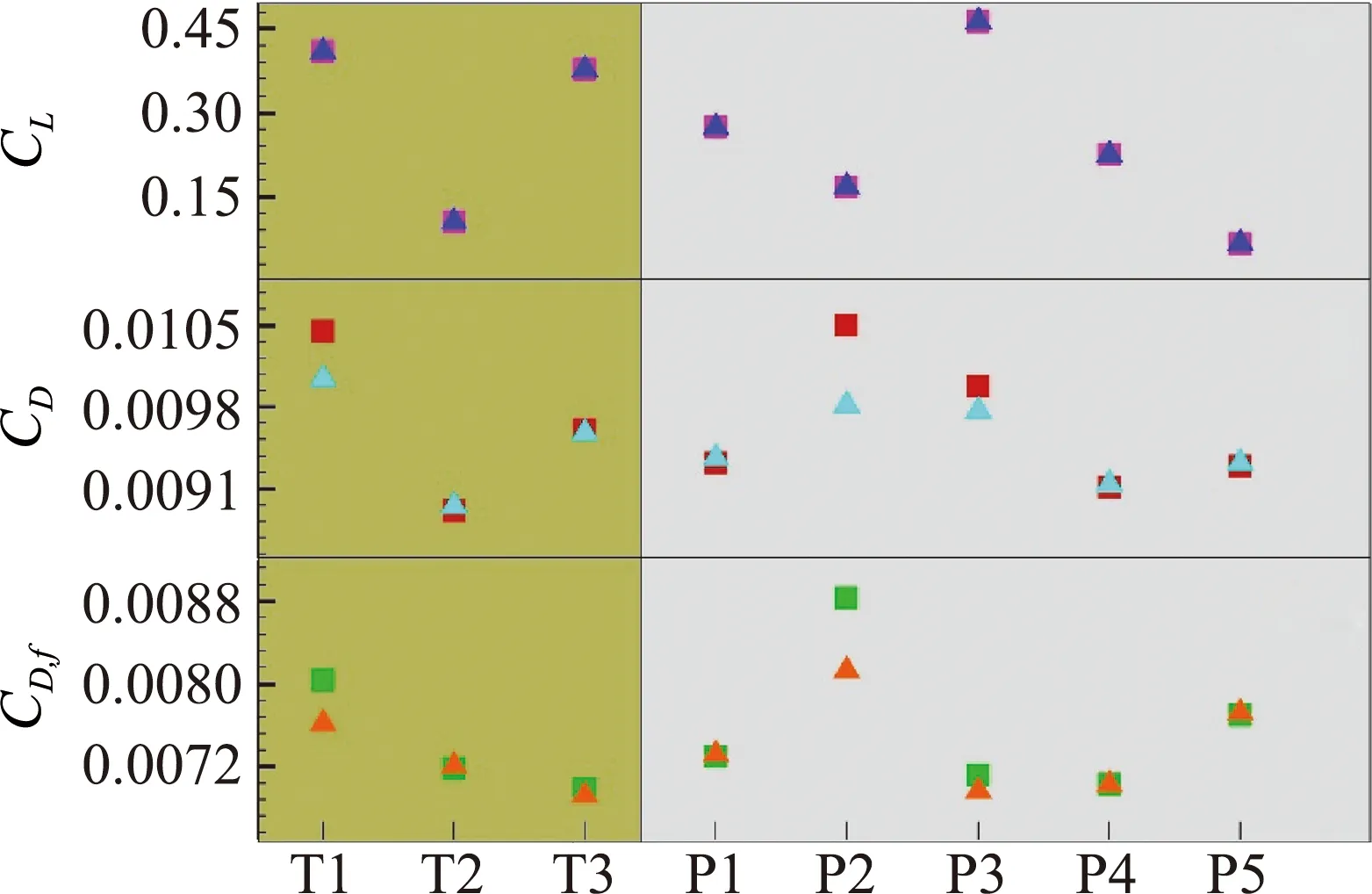
图11 训练和预测算例中SA (方框)和RBFNN (三角形)计算的力系数结果对比[46]Fig.11 Comparison of the force coefficient calculated by SA (square)and RBFNN (delta)for both training and predicting cases[46]
(a)NACA0014 翼型
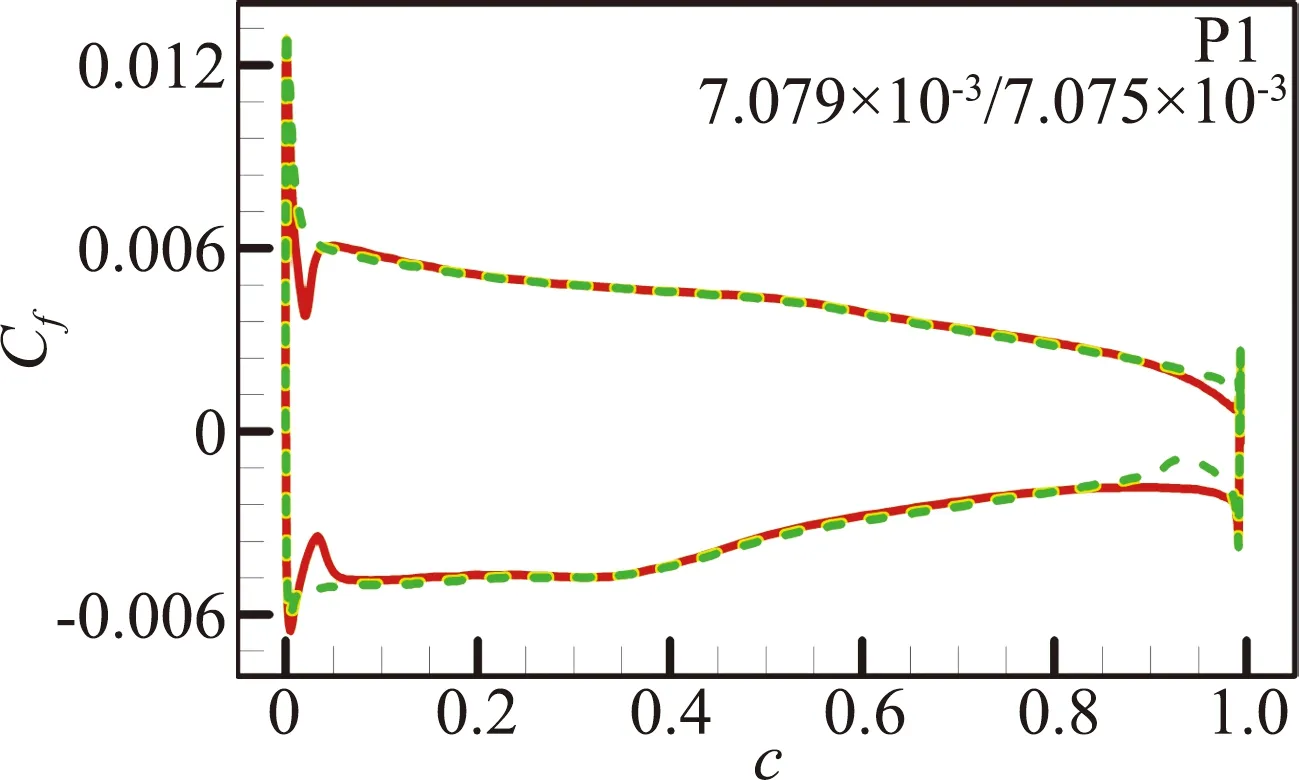
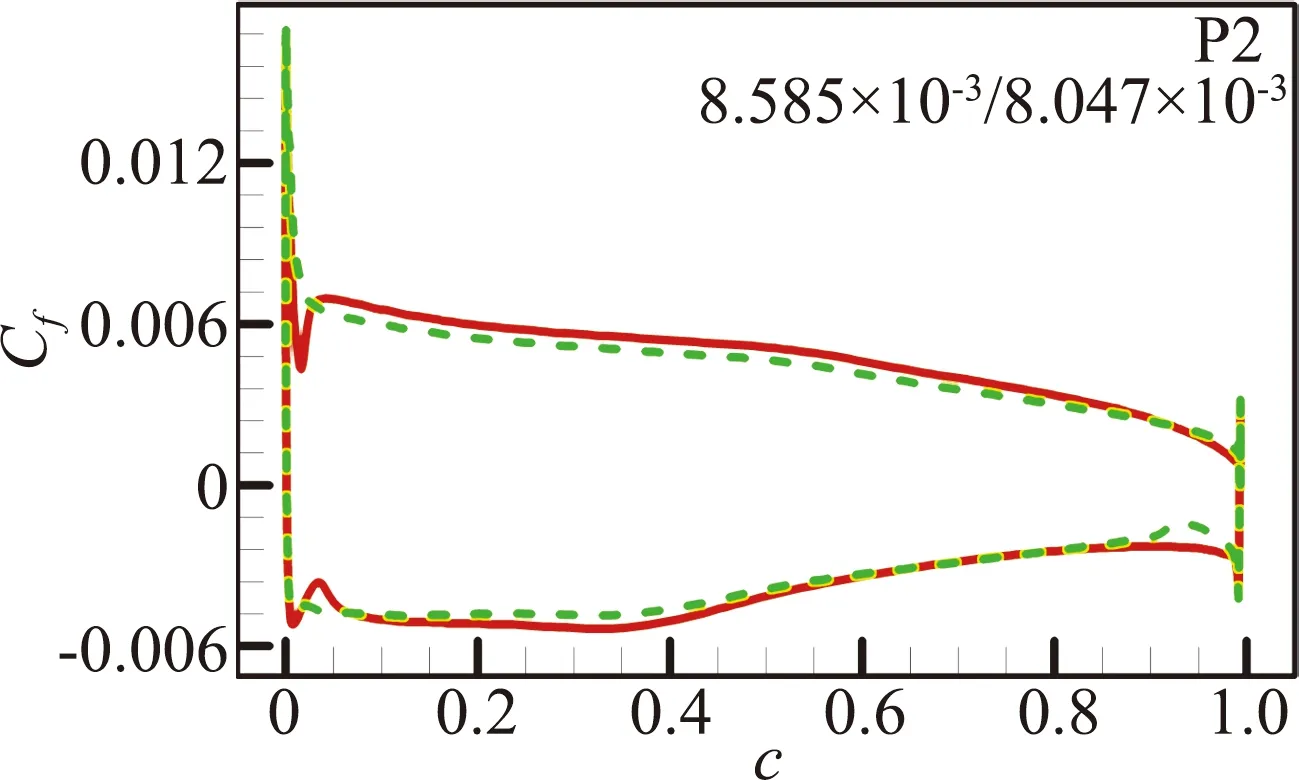
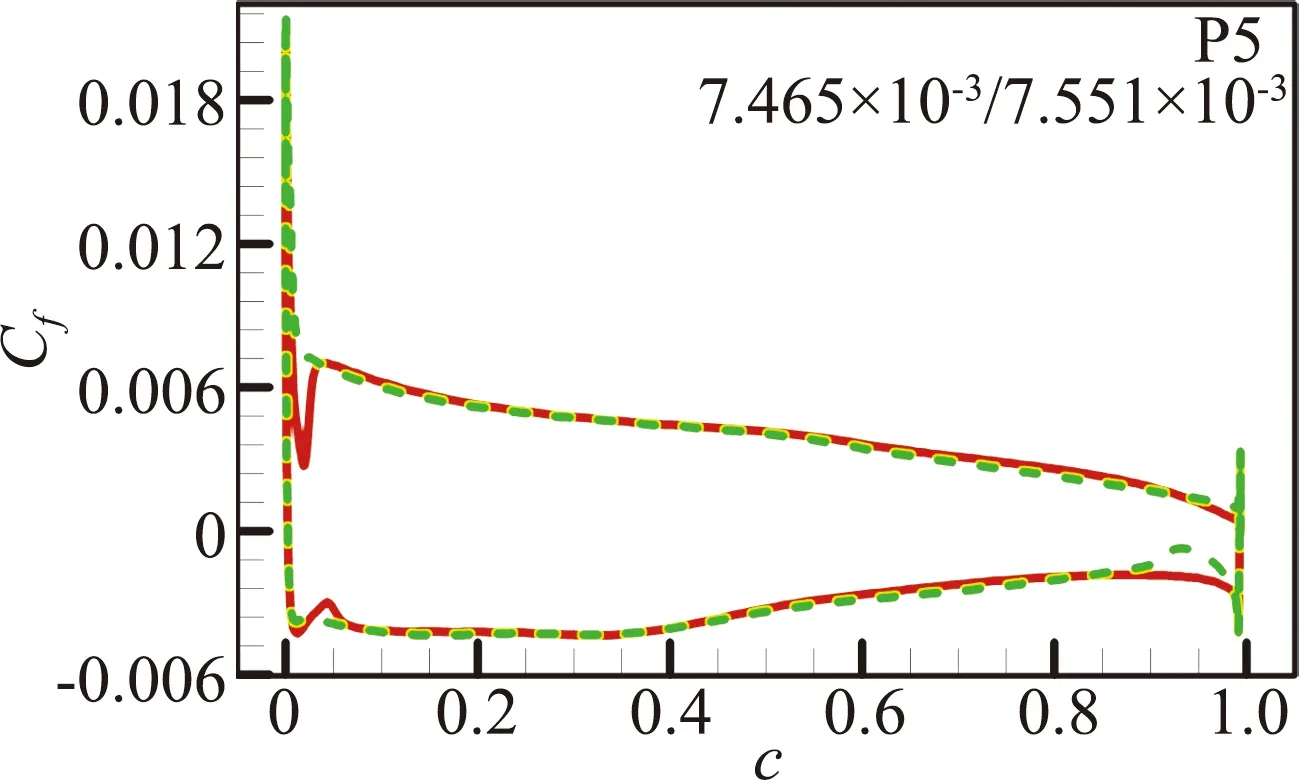
(b)RAE2822翼型
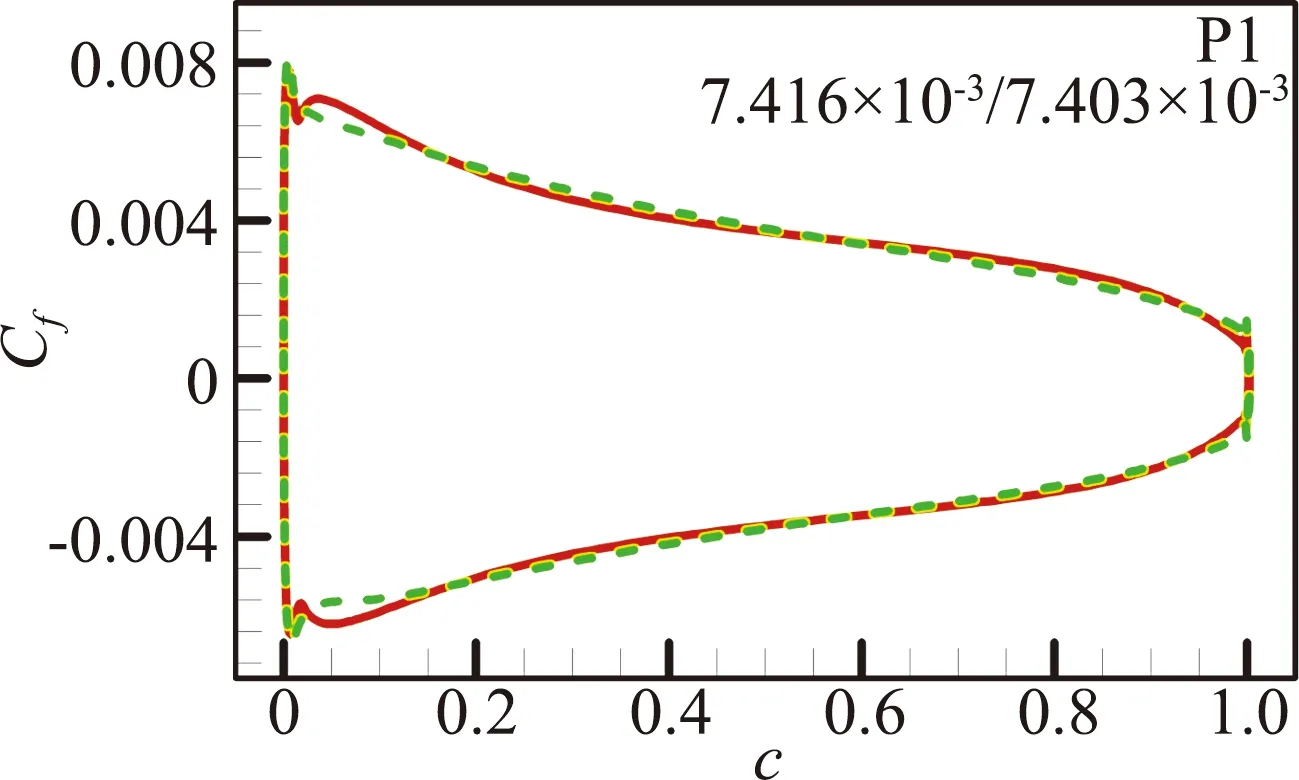
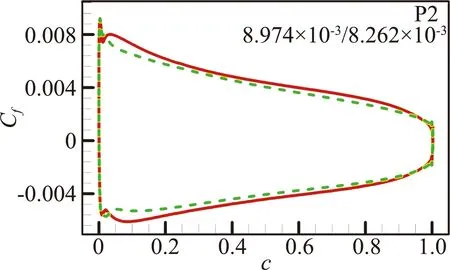
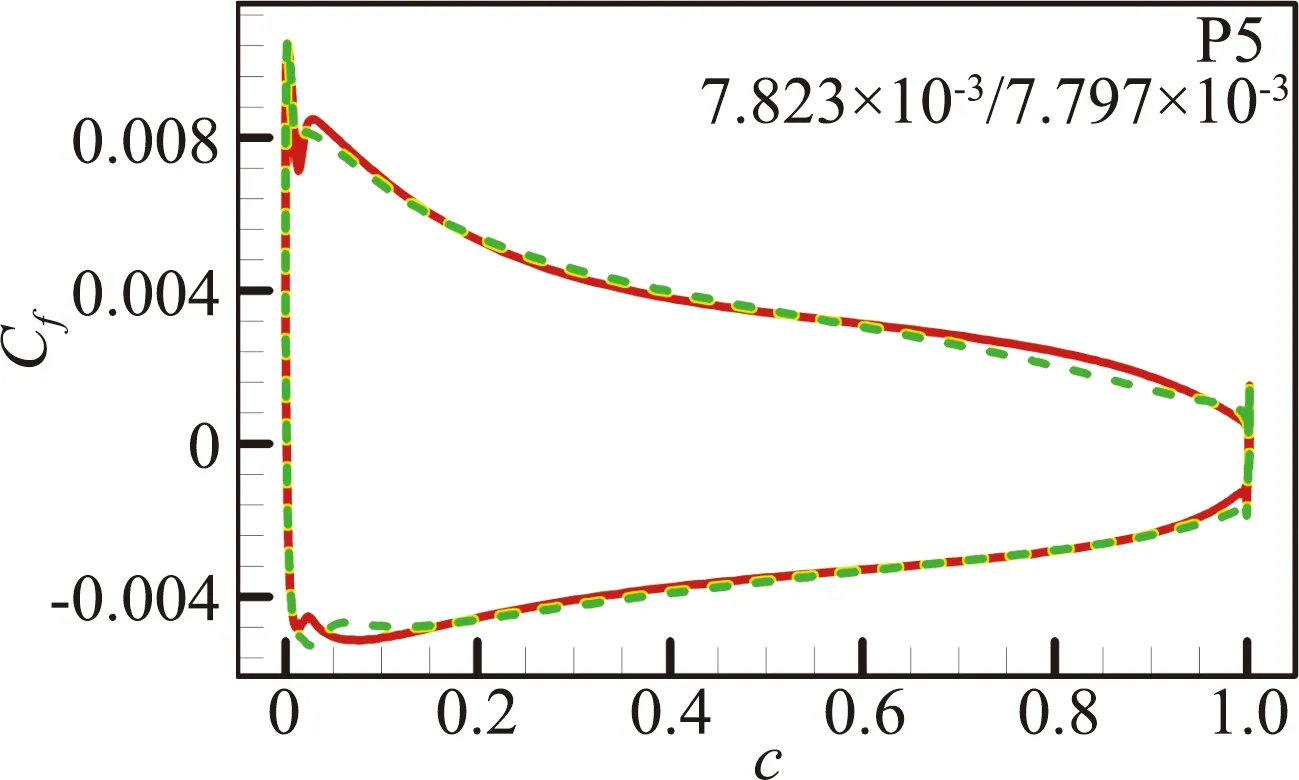
图12 预测算例P1、P2和P5的摩擦阻力系数分布对比[46](图中数据表示SA/RBFNN计算的摩擦阻力系数CD,f)
Fig.12 Predictions for NACA0014 and RAE2822 airfoil at P1,P2 and P5 cases[46].(the data inside areCD,fvalues calculated by SA/RBFNN model)
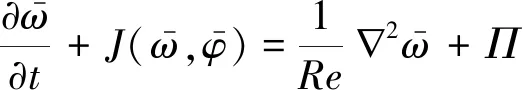
(9)
除了将模型与Smagorinsky和Leith模型对比外,Maulik等还进一步研究了不同输入特征和邻居网格信息以及后验信息对模型性能和模型架构选择的影响,指出超参数优化过程中需要后验信息的耦合。针对槽道湍流,Gamahara等人[36]采用人工神经网络对亚格子应力的每一分量分别建立模型并对比了不同输入特征的结果,缺点是模型容易受到滤过尺度的限制。Wang等人[38]用随机森林和人工神经网络基于不同输入特征研究了大涡模拟中亚格子应力的数据驱动封闭,并对构建的模型与Smagorinsky模型(SM)和动态Smagorinsky模型(DSM)以及其他方法计算的结果进行了比较,如图14所示。
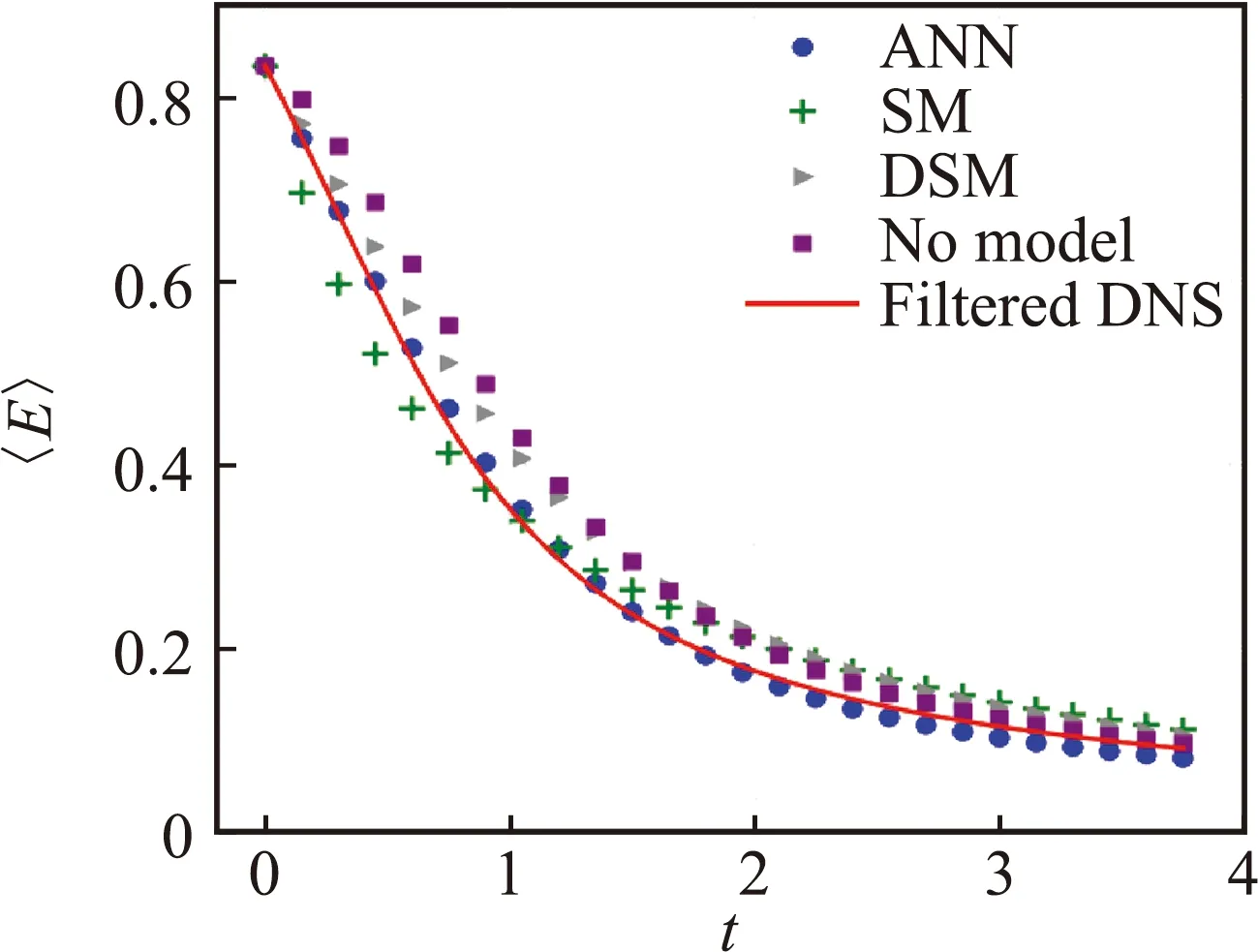
(a)动能
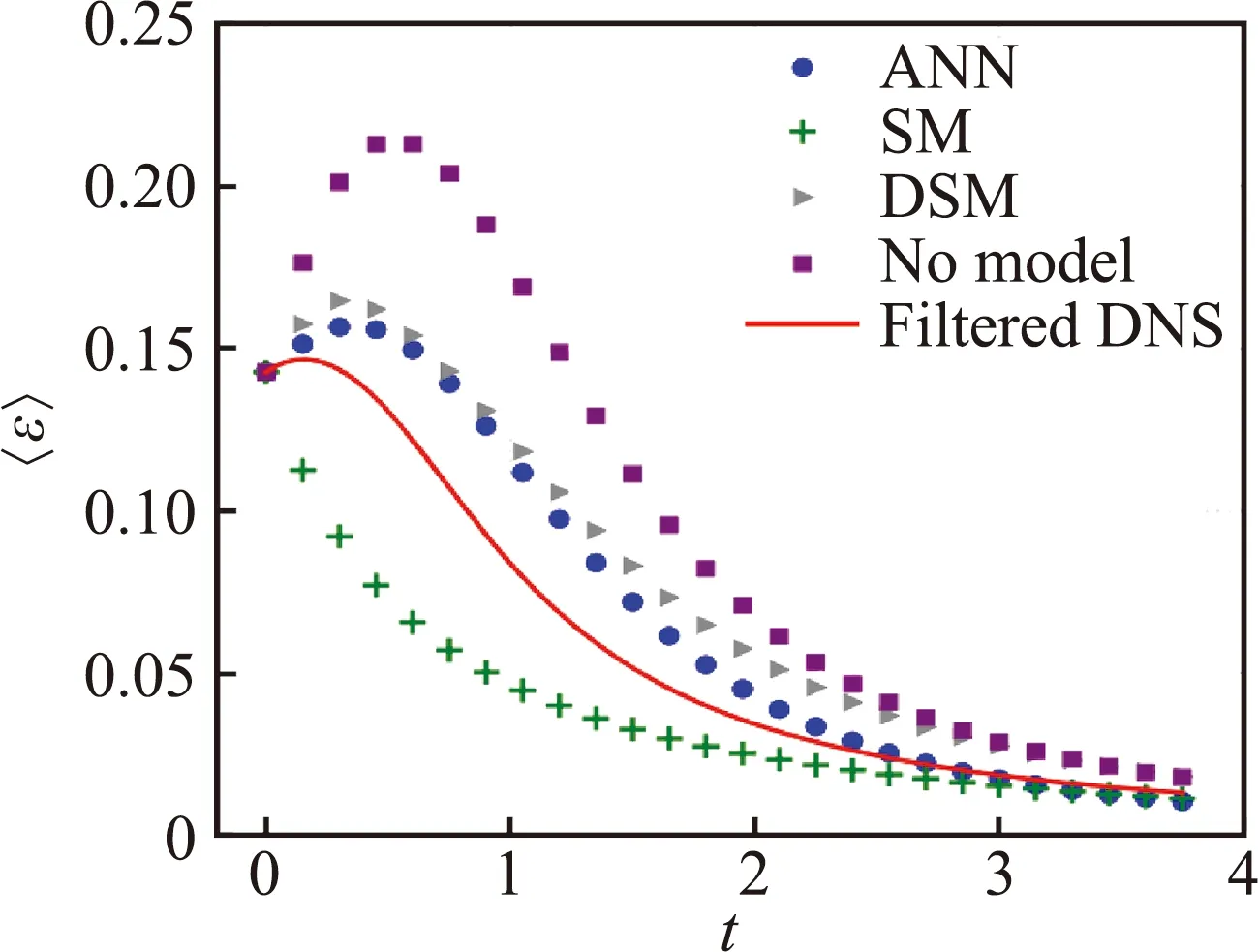
(b)耗散率图14 不同计算方法之间可分辨的动能和耗散率的时间演化图[38]Fig.14 Temporal evolution of resolved kinetic energy and dissipation by different simulations[38]
2.4 模型的鲁棒性与稳定性
模型训练过程中,建模者都希望实现更高的模型精度,然而,单纯地追求精度的提高往往是以损失鲁棒性为代价的[63]。由于存在过拟合的风险,训练阶段较低的损失函数对应的模型框架或模型参数并不意味着较高的预测能力,因此,可以在损失函数中引入L1或L2范数约束,或者采用Dropout等方法。此外,模型选择时也可以耦合后验分析或者进行交叉验证[35,37]。如果需要将所构建的模型与求解器耦合,则在模型构建过程中必须要考虑到模型的稳定性。单纯的基于数据的训练与预测完全忽略了模型偏差对流场的影响。事实上,对于显式地改变雷诺应力或亚格子应力的模型,任何微小的模型扰动都有可能被累积放大为速度场中明显偏差,而对于改变RANS模型控制方程中某一项表达式的修正模型,稳定性问题并不明显[45,64]。Wu等人[64-65]提出了衡量模型条件的方法,将雷诺应力分解为线性和非线性部分并分别建模以增强模型的稳定性。针对这一方面的研究工作还有待进一步的探索和完善。
3 总结与展望
将数据驱动方法应用于湍流计算的研究工作在近几年得到了飞速发展。一方面,机器学习新方法的涌现为研究者提供了更多的技术手段,有利于更复杂关系的实现。另一方面,所构建的模型逐渐从湍流变量间的简单函数映射关系演变为直接的雷诺应力计算,在RANS和LES的湍流计算中起到越来越重要的作用。现有的研究成果显示了这一研究方向的广阔前景和发展潜力,给研究者以开拓新局面的鼓舞和振奋。与此同时,研究过程中也同样暴露出许多问题与挑战。首先,由于模型是数据驱动的,因此,模型的性能在本质上是由所选取的训练数据决定的,模型往往在那些与训练数据差异较大的预测数据中表现较差。这就要求研究者谨慎地选取模型构建对象和方法以尽量提高模型的泛化能力。第二,受数据集的分布和损失函数等的影响,模型对整个数据集的性能也不尽相同。对于那些位于模型性能欠佳区域的数据,计算结果往往出现异值,继而影响模型的光滑性和鲁棒性。即便基于相同的训练数据,采用不同的机器学习方法所构建的模型也会有不同的鲁棒性。模型的异值会在一定程度上降低收敛性,如果出现在流场中的关键区域也会降低求解精度,所以应尤其注意模型在流场关键区域的性能。第三,样本特征的构建和选取是影响模型性能的重要因素。湍流的复杂和无序造成了样本构建和选取的困难。研究者借助于特征选取算法的同时,也需要对湍流本身有深刻的物理见解,特别地,应根据流场中的不同流动特性有针对性地构建和选择模型的输入特征。目前,系统的针对湍流机器学习的特征选取的研究还相对较少。
在现有工作积累的经验基础上,机器学习在未来的湍流模型化中必将扮演着更加重要的角色。研究者在未来的研究工作中需要关注以下几点:
1)湍流建模输入特征的提取与优化。单纯地依靠海量数据作为直接输入,通过简单增加神经网络模型的深度和宽度来构建复杂映射关系并不是一种好的建模策略。如何对输入数据进行特征提取,特别是结合前人在湍流理论中已经取得的物理规律和经验,如选择不变量、利用各种标度率、量纲分析方法等,精简输入信息、简化网络模型的维度和复杂性,从而实现模型的紧凑性和泛化能力的提升。当然,也可以借鉴人工智能方法开展输入信息的特征构建与提取,如Featuretools等。
2)湍流模型与N-S方程耦合求解过程中的稳定性与收敛性。随着机器学习在湍流模型化中的作用越来越明显,模型的输出结果对速度场的影响也越大。一方面,机器学习方法所构建的模型本身就有可能出现局部峰值和光滑性差的输出值,降低计算精度。另一方面,模型训练大多是基于某些时刻或流场中某些位置的数据进行的,模型难以包含流场在迭代过程中的全部信息。当模型参与求解器的每一步迭代时,模型的扰动会导致N-S方程求解的流场扰动,继而反馈为模型的输入偏差。这种反馈会造成迭代过程的发散,即使对于单向耦合策略也有可能造成求解过程的失稳。如果模型的稳定性较差,特别是在非线性很强的高雷诺数及大分离等复杂流动中,模型的误差随着迭代过程的累积容易在速度场中被放大,导致N-S方程求解器的最终计算结果变差。特别是采用高维深度学习网络,所带来的局部极值对耦合过程的稳定性和收敛性都带来了不利影响。
3)N-S方程和湍流模型耦合求解过程中的多平衡态问题。基于收敛状态的计算结果构建的模型在耦合求解器后有时还会出现多态解的问题。由于N-S方程和湍流的非线性和复杂性,模型的计算结果也会受初始条件等的影响,将训练后的模型嵌入N-S求解器后,最终的计算结果有可能会收敛为其它平衡态的解。关于模型与求解器的耦合问题值得进一步研究。
