基于Go 的多线程模块化爬虫框架设计与实现
2019-08-21刘国玺刘江徐海峰张雁吕丹桔
刘国玺,刘江,徐海峰,张雁,吕丹桔
(西南林业大学大数据与智能工程学院,昆明650224)
0 引言
随着大数据时代的到来,数据变得越来越重要[1]。在日常学习和科技研究中,往往需要大量数据支撑,然而数据获取并不是一件容易的事情。网络爬虫是人们最常用的一种获取网络数据的方式,网络爬虫是一个经过设计专门从万维网上下载网页并对网页进行分析的程序[2]。它将下载的网页和收集到的信息存储在本地用于研究和开发。网络爬虫的工作原理是从一个或若干初始网页的链接出发进而得到下一个链接队列的过程;伴随着网页的抓取又不断从抓取到的网页里抽取新的链接放入到链接队列中,直到爬虫程序满足系统中某一条件时停止[3]。爬虫脚本的实例多种多样,但基本流程都是请求HTML 页面、从页面中分析并保存需要的文本信息、URL 管理和下载静态资源。利用爬虫的有规律的特点,本文拟设计一个基于Go 的多线程模块化爬虫框架,能够提高网络爬虫的效率,可以在进行二次开发时,减少开发人员大量重复的代码编写,提高开发效率。
1 总体架构设计
基于模块化的思想,本文把爬虫业务抽象为三个大模块,即URL 管理、页面分析和文件下载。每个模块内部又抽象出一个或多个模块,每个模块只负责处理一项简单的事务,由一个或多个协程(goroutine)来负责执行,模块与模块之间采用专用数据通道(channel)传输数据[4]。此设计方案降低了模块间的耦合性,使多个模块可以方便地自由组合,协程也由原有的长途跋涉(处理一连串的事务)变为多个短跑运动(一个协程只负责反复执行单个任务),原来繁琐的线程变成了容易控制的协程,线程间通信也变得十分的轻松,并且可以通过设置不同步骤的协程数量来优化整体的效率。
总体架构主要分为:URL 管理器、页面分析器、文件下载器,如图1 所示(图中实线矩形表示一个操作,可设置独立的一个或多个协程负责执行,箭头表示协程间通信的专用数据通道)。
在图1 中,所有模块之间都是用通道连接,这些单向通道可视作接口。每个模块只负责处理传入通道的数据而不在乎是谁传入的。这样每个模块都有很强的封装性,模块间耦合性极大降低,模块的复用性和可替代性也极大增强。
1.1 URL管理器
在爬虫中如果遇到同一模板渲染,URL 虽有一定规律,但是有些部分无法通过脚本自动生成[5]。例如:http:www.xxx.com/xx?id=加一串随机无规则字符串,很难一次性锁定要爬取的所有页面所对应的URL。此时常用的办法就是建立匹配规则,定义一个或多个初始页面,每爬取一个页面都用匹配规则查找所有符合规则的链接,如此往复寻找就可以找到很多匹配的页面。URL 管理器主要由HTML 链接提取器和URL 分配器组成[6]。HTML 分配器可以解析通过数据通道传入的HTML 数据,提取并还原其中所有a 标签的链接,然后将链接传给URL 分配器。URL 分配器接收到URL 后,将URL 根据用户定义的匹配规则(匹配规则与页面分析器一一对应)分配给匹配的页面分析器。

图1 系统主体架构
1.2 页面分析器
在网页爬取过程中请求和页面分析是必不可少的步骤。页面请求就是通过URL 获取对应的数据,一般是一个HTML 文件。页面分析就是提取页面请求所得到的东西中的有效数据的一个过程[7]。用户需求不同或者页面的变化都会导致分析步骤的不同,此步骤不能统一封装的,只能给开发者提供一个接口,通过执行开发者所传入的方法分析页面,解析出需要的数据。另外在Go 语言中方法可以像变量一样传递,开发者能快速上手。
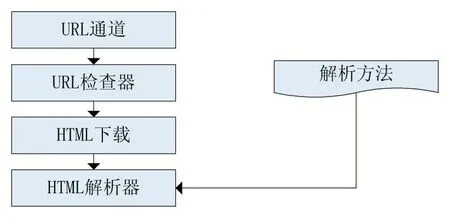
图2 页面分析器结构示意图
如图2 所示页面分析器主要由URL 检查器、HTML 下载器、HTML 解析器组成。每个页面分析器都由一个map 保存已经抓取过的URL,当有新的URL 通过URL 通道传入,URL 检查器都会检查这个URL 是否已经存在于map 中,避免重复抓取相同数据。如果没有重复,URL 检查器会把这个URL 传给HTML 下载器。HTML 下载器通过URL 下载相应的HTML 页面,然后传递给HTML 解析器。HTML 解析器执行用户传入的解析方法,解析HTML 数据并把页面对应的URL添加到已爬取URL 列表中。HTML 解析器是整个分析器的核心,同时也是整个系统的控制中心[8]。在解析方法中用户可以使用其他Go 语言的HTML 解析方式如goquery、正则匹配等解析HTML 获取自己需要的数据,也可以自己定义解析方式。同时也可以执行数据存储操作如把数据存储到数据库或者文本。HTML 解析器是控制中心是因为:使用URL 管理器,只需要把HTML或者URL 传给URL 解析器;下载文件,只需要把URL传递给初始化好的资源文件下载器。
页面分析器针对当前大多数网站使用视图模板,结构相似的网页对应一个页面分析器,根据本文设计方案不同页面分析器的主要区别就是传入的解析方法不同,用户根据自己需要抓取的网页和数据设计解析方法通过接口传入页面解析器执行,最终实现页面的解析。
1.3 资源文件下载器
网络爬虫的根本目的是获取需要的数据。这些数据大致可分为文本数据和静态资源数据两大类[7]。文本数据是指嵌套在页面中的数据,如某公司首页的文字说明、公司名称等。静态资源数据主要是音频文件、视频文件、图片文件等。文本数据的获取可以通过页面分析器实现,资源数据和页面一样也有指向文件的URL 地址[8]。静态资源文件的流程就是通过URL 解析下载资源,然后以某个文件名存储在硬盘中的某位置。将此过程封装为“一个下载器”,开发者只需提供存储路径、URL 等参数,根据硬件资源设置线程数就可以完成下载,不必考虑多线程等问题。
资源下载器的完成的任务就是:检查传入的URL,下载URL 对应文件并保存在用户指定的位置。
2 基于Go的多线程实现
前面提到本系统采用模块化设计,一个模块只负责处理单个简单的逻辑事务,每个模块可以由一个或多个独立的协程负责运作,这样一个协程也由原来的处理一连串的事务变为只负责反复执行单个任务。在一连串的事务处理中常常会因为某一步骤而导致线程阻塞,优化起来很难[9]。在本模型中只需优化阻塞的任务模型,甚至可以给阻塞任务多开几个协程,就可以使整个流程变得流畅。熟悉多线程编程的用户一定会发现这种模型的弊端:切换线程是有高性能代价的,这也是本系统选择用Go 语言实现的一个重要原因。在Go 中本文协程来取代线程,把协程看做线程的一种封装,一个四线程的CPU 最多可以同时执行四个线程操作[10]。在普通的多线程操作中需要频繁切换线程,在Go 中默认所有goroutine(协程)会在一个原生线程里运行。在同一个原生线程里,默认如果当前协程不发生阻塞,该协程就不会让出时间给其他同线程的协程。如果发生阻塞,线程会把CPU 时间让给其他协程而不切换线程,而切换和创建协程的性能代价远远低于线程的切换和创建,大大降低了频繁切换协程对性能的影响[11]。
文本有效实现了爬虫的多线程退出方法,在Go 语言中,建立了一个Waitgroup 实例,每添加一个任务调用一次Waitgroup.Add 方法;每执行完一次任务调用一次Waitgroup.Done 方法。当Waitgroup 实例中任务数量降到0 时就会结束所有协程。
3 实验结果分析
文本实现的爬虫软件测试环境如下:
操作系统:Win10 专业版;CPU:Intel i5 4700M;网络带宽:100MB。在此设计方案下进行页面爬取实验,实验结果如下:
(1)普通多线程爬虫

表1 普通多线程爬虫
(2)基于Go 的模块化爬虫

表2 基于Go 的模块化爬虫
在相同运行环境下,执行相同任务时,在爬取页面效率上,基于Go 的模块化爬虫比普通多线程爬虫有所提升。对于开发效率,基于Go 的多线程由于进行模块化封装比普通多线程在性能、开发和调试效率上都有很大提升,实验中,如表1 和表2 所示,编程所需时间由120min 降低为25min,开发效率明显提高。开发者在爬取其他网站时,只需要对页面解析方法进行设计,通过解析器接口传入解析器执行。基于本文设计的爬虫框架下,进行二次开发,不仅可以减少大量的代码编写,提高开发者效率;而且可以减少开发者在开发过程中的重复性工作,避免开发过程的反复。
4 结语
模块化爬虫设计,可以把复杂逻辑抽象成多个简单任务模块,采用协程和任务绑定的编程思路,不仅可以用在爬虫程序中,也可以用在其他一些结构化的事务处理中。本文设计了一个方案把爬虫基本流程进行模块化封装,为开发者提供一个可控的并且能够支持多线程的集页面请求、资源下载、URL 重复检查管理等基本功能的开发包,便于开发者使用以及避免开发过程中的反复造轮子。除此之外,基于Go 的模块化爬虫设计可以降低模块间耦合性,增强模块的复用性和可替代性。
