基于Bisecting K-means聚类算法的南京地区社区空间分布研究
2019-08-19
(1.东南大学经济管理学院 江苏 南京 210000;2.东南大学经济管理学院 江苏 南京 210000)
一、引言
城市服务业的合理选址可以有效满足城市社区居民的多样化需求,提高客户对公司的满意度。但是,由于社区居民位置分布广,需求层次不同等因素,难以对目标服务群体进行划分,使得城市服务业合理选址难以实现。近年来,学者们大多利用聚类分析来解决目标服务群体划分问题。Everitt等(2011)认为聚类分析包括一系列将多元数据分类为子组的方法,可以帮助揭示任何结构或模式的特征。A.Joy Christy等(2018)为了细分客户,提出对公司事务数据进行RFM分析,然后利用传统的K均值和模糊C均值算法对事务数据进行聚类。而在当前大数据环境下,为了解决传统聚类研究中耗时费力的数据采集问题,学者们开始利用数据挖掘技术从多种渠道获取数据。徐晓宇等(2019)利用爬虫技术获取大众点评平台的北京地区数据,引入聚类算法对于餐饮业的地理聚集特征进行了分析。
本文以南京地区为研究对象,从互联网平台获取了居民社区位置、房价信息等大量数据,通过改进的K-means算法对南京地区社区进行聚类,利用聚类结果对南京地区社区空间分布进行了分析。
二、数据源
本文以南京地区为研究对象,利用网络爬虫技术获取安居客上的社区数据,包括社区名称、经纬度、详细地址、平均房价等属性信息。数据获取时间为2019年4月1-30日,原始数据共计2231个社区。首先对数据进行预处理,删除了部分有问题的数据,确保数据的有效性。然后采用空间坐标转换技术将其经纬度转换为百度坐标,最终筛选出2165个小区用于本文研究。
三、研究方法
当前,在处理较大数据对象时大多使用经典K-means聚类算法。因为其可伸缩性和有效性比较好,而且结构简单易于实现。但是由于南京地区的社区数量多、空间分布复杂,而K-means算法容易受到簇数及初始聚类中心位置的影响。因此,为了使聚类结果更加合理,本文采用Bisecting K-means算法对社区数据进行处理。
Yu Zhuang等(2016)认为Bisecting K-means是对K-means算法在聚类质量和效率上的改进。其基本思想是:将所有点作为一个簇,将该簇一分为二,再选择一个合适的簇划分为两个簇,不断重复,直到簇的数目等于目标簇数k。相对于原始K-means算法相比,这种方法可以确保得到全局最优解。
四、结果与分析
(一)社区聚类中心空间分布特征
本文使用轮廓系数来确定最佳k值,从图1聚类簇数效果图可以看出,聚类簇数在达到30个簇之后,轮廓系数的增量就很小,因此选择簇数K值为30比较合理。利用Bisecting K-means算法对南京地区社区进行聚类,由图2可以看出,聚类中心主要集中在鼓楼区、建邺区、玄武区、栖霞区、雨花台区、秦淮区及浦口区,呈圈层式分布,由主城区向外密集程度逐渐减弱。

图1 聚类簇数效果图
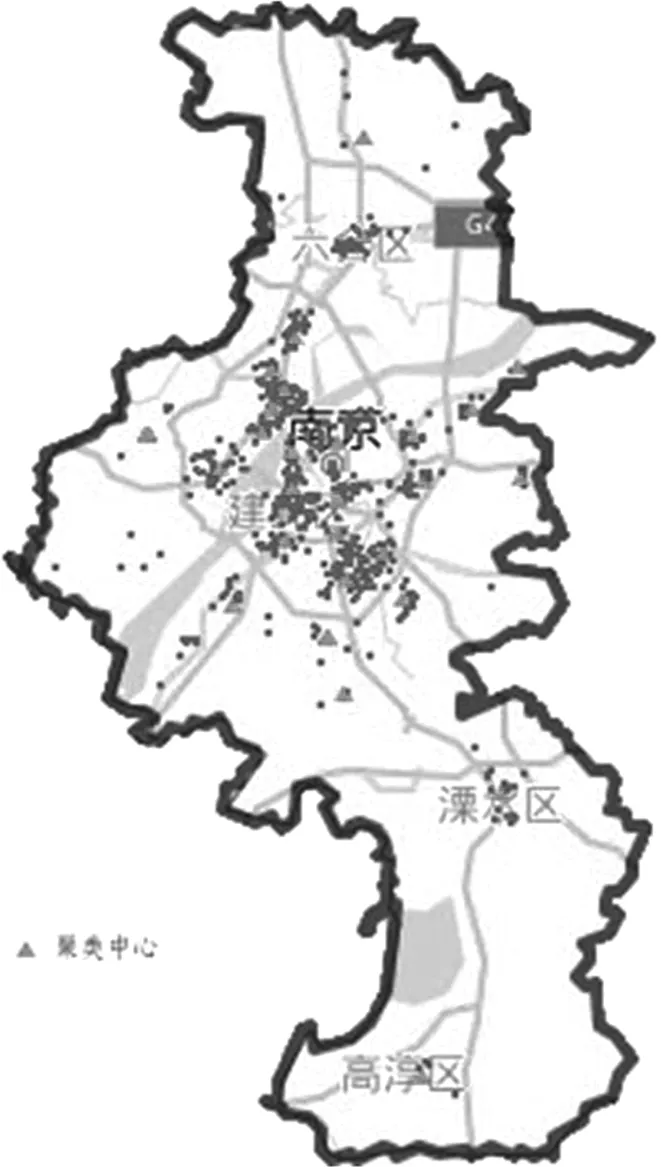
图2 聚类结果图
总体来看,南京地区社区整体分布不均衡,大多数聚类中心都处于南京的主城区附近,其他地区聚类中心较少且分散,同时沿交通线扩散。据官方统计资料,南京地区2018年鼓楼区常住人口密度为2.64万人/km2;秦淮区常住人口密度为1.04万人/km2;玄武区常住人口密度为0.63万人/km2;而溧水区常住人口密度最小为0.04万人/km2。将社区聚类中心的空间分布与每个城区的居民人口密度分布进行比较,发现两者基本一致。主要差别在于浦口区的社区较密集而其人口密度较低,原因是其社区主要聚集在沿河地区,在空间分布上符合围绕主城区进行布局的格局。
(二)社区消费等级空间分布特征
经统计发现,安居客上社区平均房价集中在3000~100000元区间内。社区的平均房价一定程度上能够代表该社区的消费等级,本文将社区平均房价划分为3个等级,代表社区居民消费的三个等级:社区平均房价45000元以上的为高消费等级社区;15000~45000元的为中消费等级社区;0~15000元的为低消费等级社区。社区平均房价热力图如下图所示,颜色越深表示社区越聚集。高消费等级社区共计263个,如图3-1所示。高消费等级社区主要聚集在河西地区。中消费等级社区共计1862家,由图3-2可看出,中消费等级社区数量明显增多,而且呈现围绕主城区的分布特征。低消费等级社区共计209家,由图3-3可看到,集聚地更多更分散,基本覆盖南京地区所有行政区,且表现出了沿交通线扩展的集聚特征。

图3-1 高消费等级社区
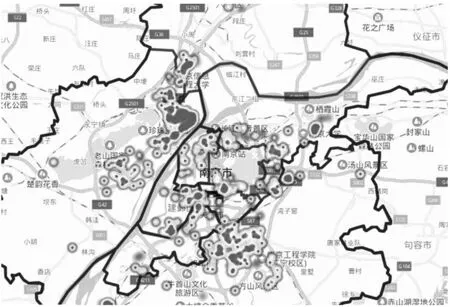
图3-2 中消费等级社区
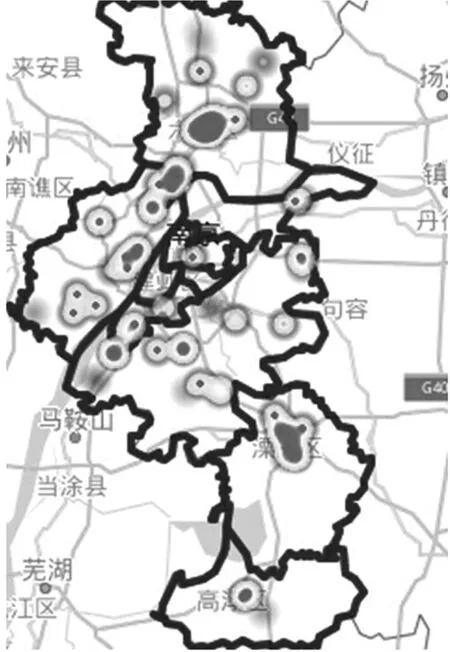
图3-3 低消费等级社区
总体来看,不同消费等级社区的空间分布特征存在明显差异。南京地区中低消费等级社区数量占总数的绝大部分,而高消费等级社区数量则较少,且多集中在河西地区附近。随着等级降低,社区的集聚特性呈现出边缘化分散的特点,且更易受交通便捷性的影响。
(三)影响因素分析
根据南京地区社区聚类中心和消费等级的空间分布可以将社区分为以下四种情况:(1)不仅密集而且消费等级高,以河西地区的社区为代表;(2)分布虽十分密集,但其消费等级却并不高,以浦口和江宁副城区等地社区为代表;(3)消费等级高却分布稀疏,以玄武区和秦淮区等地社区为代表;(4)消费等级低而且较为分散,以六合和高淳等地社区为代表。通过对比社区位置和区位特征,发现产生这种差异性主要是因为城市布局和居民个体属性的影响。
河西地区是南京地区传统的富人区,而且位于南京市城区的中心地区,靠近南京最繁华的商业区,导致大量的高收入人群聚集。所以,以河西地区社区为代表的社区表现出了高密度、高消费的特征。
江宁区、浦口区等地因为工业区而汇聚了大量的外来就业人口,而大量的外来就业人口导致了社区的聚集,房价处于中等水平,符合实际消费等级。所以,以浦口和江宁副城区等地社区为代表的社区表现出了高密度、低消费的特征。
主城东部以玄武区和秦淮区等地社区为代表,表现出低密度、高消费的属性。其原因在于城东地区科研院所与高科技园区的布局。南京主城东部外围的环钟山风景区一带的大片区域存在大量的高校和科研院所,而居住在周边的居民大多是高收入高学历人群。
以六合和高淳等地社区为代表,特征是低密度、低消费。因为其大多位于城中村地区或者偏远郊区,经济发展水平较低,居民收入不高。
五、结论
本文通过数据挖掘技术获取南京地区的社区信息,并通过Bisecting K-means聚类算法对其进行聚类。从其空间分布密集程度和消费等级方面对其蕴含的地理特征进行了分析。研究发现:
(1)南京地区社区呈现不均衡分布情况,聚类中心大多靠近主城区,其他地区聚类中心较少且分散,而且沿交通线扩展。同时,社区聚类中心空间分布受区域人口密度和交通便捷性影响很大。
(2)南京地区社区消费能力呈现出等级体系特征,其空间分布特点是:高消费等级社区少,主要在河西地区,城东地区分布较为稀疏,但都表现出小范围内规模聚集。中低消费等级社区集聚区多且分散,并受交通便利性的影响。
(3)影响南京地区社区聚类中心和消费等级空间分布的因素主要是城市布局和居民个体属性两个方面。其中,城市布局是主要因素,而居民本身的属性则是次要因素。
