基于多层次特征的跨场景服装检索
2019-08-15李宗民边玲燕刘玉杰
李宗民,边玲燕,刘玉杰
(中国石油大学(华东)计算机与通信工程学院,山东青岛266580)
0 引 言
随着互联网软硬件技术的不断进步,网购成为人们生活中不可或缺的一部分,而服装网购是其中最热门的一个应用。服装属性识别[1-2]、服装推荐[3-5]和跨场景服装检索[6-9]等研究正受到广泛关注。不同场景的服装图像存在显著差异,使得跨场景服装检索非常具有挑战性。在日常生活中拍摄的用户服装图像往往背景复杂,人体姿态、拍摄光线和角度也十分多变。而商家服装图像一般都在特定的环境下由专业人员拍摄的,背景纯净,姿态专业。由此可见,不同场景下的服装图像表现出了不同的特性,如何从跨场景服装图像的公共特征和域特定特征中提取更有表述力的描述子很具挑战性。
传统单一域的图像检索方法无法对双域的特定特征进行建模。HUANG等[10]提出的DRAN和YANG等[11]提出的MSAE分别为每个场景域创建2个完全独立的深度学习分支,以学习2种场景域的差异,但无法捕获2个域共享的公共特征。改进的Siamese网络[6]共享2个Inception-6分支的权重,有助于学习底层公共特征,但原有的对比损失函数将视觉差异性大的负样本和视觉差异性小的负样本同等对待,这种处理方法可能导致网络过拟合和不良范化。
为解决这一问题,本文提出了一种基于类别约束的增强对比损失函数,并设计了相应的三分支网络。通过三分支网络,可将服装图像中的物品特征转换为2个潜在空间,即公共类别空间和特定场景域空间。在场景域空间网络,用类别信息约束传统对比损失函数,增大对类间负样本对的惩罚以减轻过拟合。实验表明,在基准数据集上,该算法的检索精度明显优于其他算法。
本文提出的框架由三部分构成,图1给出了基本流程说明。本文的主要工作总结如下:

图1 网络结构Fig.1 Network structure
1)提出了一种新的跨场景服装检索网络框架。该网络框架融合了场景域空间和类别空间。
2)提出了一种新的增强对比损失函数。通过附加的类别信息约束传统对比损失函数,防止过拟合。
1 相关工作
1.1 服装图像检索
近年来,服装图像检索[2,6-9,12]得到了广泛的研究。LIU等[8]首次提出跨场景服装检索的理念,用人体姿态估计人体区域,然后通过两步稀疏化编码实现跨场景服装检索。KALANTIDIS等[13]提出了一种新的区域表示方法,该方法使用二值空间掩膜,约束人体姿态,估计人体区域,以此来削弱背景的影响。KIAPOUR等[6]提出跨场景服装精确检索的概念,目的是在购物网站中找到完全相同的商品。在解决服装检索问题时,通过对服装区域检测的方法可以很好地缩小2个场景域之间的差异,然而,如果服装区域检测错误,该错误将被传播到判别模型中。此外,这些单一域服装检索方法无法对跨场景服装检索问题中场景域的特定特征进行建模。
基于2个完全独立分支的双属性感知排序网络(DARN)[10],分别对不同场景域进行特征学习,其检索特征表示由语义属性学习驱动。DARN网络实验表明,高层语义信息学习是提高检索精度的关键因素[10]。WANG等[12]提出了增强对比损失函数的Siamese网络和多任务网络微调方案。LIU等[2]提出的DeepFashion Net网络通过联合预测服装属性和关键点来学习服装特征,并将该网络应用于深度时尚数据集的跨场景服装检索子任务,其主要缺点是对于关键点和服装属性的训练需要大量数据。JI等[9]提出的YNET共享底层网络,分别为每个域创建不同的深度学习分支来建模域特定特征。但是公共分支位于网络底层,学习到的特征只体现了底层的图像细节,未考虑高层语义信息。相较单一网络,多分支网络进一步提高了跨场景服装检索的精度。
连续的CNN层代表了图像的抽象程度,最后一层包含了图像的抽象描述子,对规模、图像位置、视角、遮挡上的变化具有鲁棒性。然而,这些描述子并不擅长视觉相似性的估计,因为相似性是2个抽象的高级概念(短袖与其他短袖更匹配,而非牛仔外套)以及低级细节(条纹短袖与条纹短袖匹配,条纹间隔相似的短袖比过宽或过窄的条纹短袖更匹配)的函数。目标检测网络忽略了细节信息(其目的是识别短袖,不管它是条纹还是格子)。换句话说,目标识别网络关注的是该类别中所有对象所共有的特征,忽略了对相似度估计非常重要的细节信息。降低了它作为相似性估计器的有效性。
本文借鉴DARN网络[10]中联合服装属性约束特征学习的思路,用新的框架来学习更具判别力的服装特征描述子。
1.2 图像深度度量学习
随着深度卷积神经网络在特征表示中的广泛应用,基于深度模型的相似性学习方法越来越受到关注。深度度量学习是指训练神经网络将图像投影到度量空间中进行相似性度量。HUANG等[10]提出了一种双重属性感知排序网络(DARN),用于跨场景服装特征学习。WU等[14]提出了一种用于图像检索的深度相似性学习方法,即在线多模态深度相似学习(OMDSL)算法。三元组损失[15]通过计算正对和负对之间的相对距离来实现相似性检索,但是采用相对距离来度量相似性极易出现类内差异性大、类间差异性小的问题。基于Siamese网络的对比损失[16]是度量学习中应用最广泛的配对损失。该网络由一对具有共享权重的CNN组成,需要一对图像作为输入。真值标签表示图像对相似或不相似。不同于三元组损失的相对距离,通过计算绝对距离解决本文试图解决的相似性问题而不是训练目标检测,然后利用网络进行相似性评估。传统对比损失函数将视觉差异性大的负样本和视觉差异性小的负样本同等对待,这种处理方法同样会导致类内差异性大、类间差异性小的问题。另外,由于被训练为对2幅图像是否相似进行的二进制决策(是/否),因此,无法捕捉到细粒度相似性。受文献[10]启发,笔者用Siamese网络取代完全独立的网络分支结构,联合高层语义信息和场景域分支网络,采用新的对比损失函数来解决跨场景服装检索问题。
2 基于多层次特征及类别约束的跨场景服装检索方法
图1所示为本文算法的整体框架图。本节首先对整体框架进行详细阐述,然后在场景域空间学习中描述本文提出的增强对比损失函数,最后阐述网络的训练细节。
2.1 方法概述
网络学习框架由类别空间和场景域空间两部分组成,如图1所示。与单一Siamese[16]不同,它由3个子网络构成,包括1个提取场景域特定特征的双路网络以及2个提取线上类别公共特征和线下类别公共特征的单路网络。
在训练期间,将线上线下服装p,q分别送入类别空间学习网络,同时将训练服装对
2.2 类别空间学习
细节信息对于相似度估计至关重要,忽略细节信息会降低相似性估计器的有效性。然而,简单的抽象特征描述子并不擅长视觉相似性的估计,因为相似性是2个抽象的高层语义信息和低级细节的函数。跨场景服装检索必须在多个层次上对图像特征进行评估。受文献[10]的启发,本文联合服装类别得到更具有判别力的服装特征描述子—三分支网络。
使用基于AlexNet的CNN模型[18]。该模型在120万ImageNet[19]数据集上进行了预训练,用于提取常规视觉特征,服装类别作为训练监督信息。用DeepFashion数据集对该模型进行微调,使其更符合本文所研究的问题。提取fc7层的特征作为类别特征,定义为fci。模型输出11维类别所属的概率向量,按照概率值大小确定所属类别并将其分别定义为类别Cpi、Cqi。如果Cpi和Cqi为同一类服装产品,则 C=1,否则 C=0。
2.3 场景域空间学习

图2 类别空间网络结构Fig.2 Category space network structure
图2 展示了场景域空间网络的细节。为了提取不同场景域的特征描述子,本文借鉴Siamese网络[17]模型(细节见图2),提出了一种鲁棒性更高的对比损失函数。每个分支采用AlexNet[18]参考模型。在每个分支顶部是3个全连接层(fc6、fc7和fc8),输入为前一层的输出。考虑到网络最后一层(fc8)是为原始训练数据集中的类别数设计的,故本文将其删除并使用fc7层作为特征表示。该网络共有60M参数,7层深。其中Xp和Xq分别表示线上服装和线下服装,如果Xp和Xq为同一服装产品,则Y=1,否则Y=0。W表示网络的共享参数向量。GW(Xp)和GW(Xq)为Xp和Xq映射到低维空间中的2点。EW(Xp,Xq)相似性度量定义如下:

在训练过程中,成对的图像被送到共享权重的2个子网络中(见图2)。每个子网络生成一个特征向量,将这2个特征向量放入对比损失函数,则传统损失函数可定义为
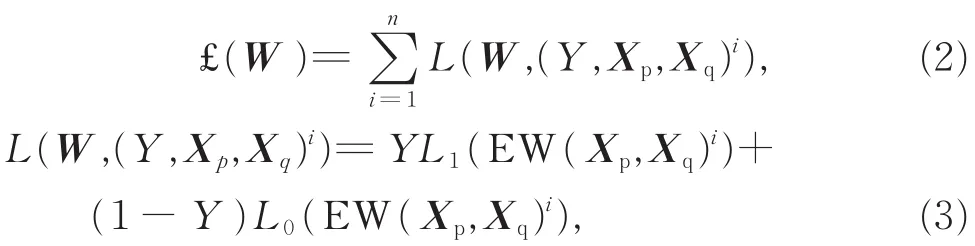
其中(Y,Xp,Xq)i表示第i个样本,Y表示产品配对标签(1或 0),C表示类别配对标签(1或 0),L1和 L0表示正样本对和负样本对的部分损失函数,n表示训练样本的数量。
一般情况下,类内负样本对的视觉差异性往往小于类间负样本对甚至是部分正样本对,通过传统对比损失函数进行计算,易导致类内负样本差异过小。已知训练图像对按是否为相同产品进行划分,得到的正样本对一定来自于相同类别,来自不同类别的产品一定是负样本对。那么,传统对比损失函数就可以通过类别信息加以约束。增强对比损失函数定义如下:

与式(3)相同,本文提出的增强对比损失函数也是成对输入的。但本文使用了3种不同类型的服装对,正样本对(a)、(b),类内负样本对(a)、(c)以及类间负样本对(a)、(d)(参见图3)。类间负样本对包含2个来自不同类别的负样本,一般更容易区分,有助于对训练网络进行粒度区分。类内负样本对包含2个来自相同类别的负样本,一般不容易区分,有助于对训练网络进行细粒度划分。这种扩展背后的主要原因是现实世界中同类别的不同产品往往存在很大的视觉相似性。这样的样本对在原始对比损失函数中易导致过拟合。在增强对比损失函数中通过max(m2,EW(Xp,Xq)i)有效限制了此样本对的L值。卷积网络经过端到端的训练后,将fc7层提取的特征作为匹配特征,定义为FMi。

图3 不同类型的服装对Fig 3 Different types of clothing pairs
2.4 网络训练细节
评估实验[20]发现,为了有效训练所提出的网络,在学习之前,m值应为训练图像对特征之间的平均欧氏距离的2倍。在实验过程中,笔者用不同的m值进行试验,最终选择效果较好时的值m=30。在培训的第1阶段,从服装类别中挑选出11大类,并将其分别标记为正样本对、类间负样本对、类内负样本对。利用正样本对和类间负样本对训练了一个初始粗粒度的相似性度量网络。首先,将学习率设为0.001,动量为0.9,训练20 000次,然后,将学习率降至0.000 1,再训练15 000次。在第2阶段,用正样本对和类内负样本对对每个类别上的学习度量网络进行微调(学习速率为0.000 1),以产生细粒度的相似性度量。2个学习阶段,均使用相应的验证集来监测停止训练的时间。
3 实验和分析
为了验证本文算法的有效性,在真实数据集上与基准算法进行了对比实验。
3.1 数据集
实验部分采用DeepFashion数据集。该数据集包含超过80万张图像,其中包括类别、服装属性、关键点以及跨场景的图像对等标记信息。本文不研究关键点信息,因为它超出了本文的范围。此外,实验只使用DeepFashion数据集中针对跨场景服装检索问题的子数据集Consumer-to-shopClothes Retrieval Benchmark,每个商品id对应的文件夹中包含一张卖家秀和几张匹配的买家秀。用商品类别来命名每个商品id所属的文件夹。为了学习类别信息,本文利用已有信息生成服装图像的类别标签。去除损坏的图像,得到193 950幅用户图像和45 381幅商品图像,分布在23个类的33 881种商品的id文件夹,本文选择了11种与产品图片的上衣服装相关的类别标签。对此数据集采用了相似的分区方法(见表 1)。
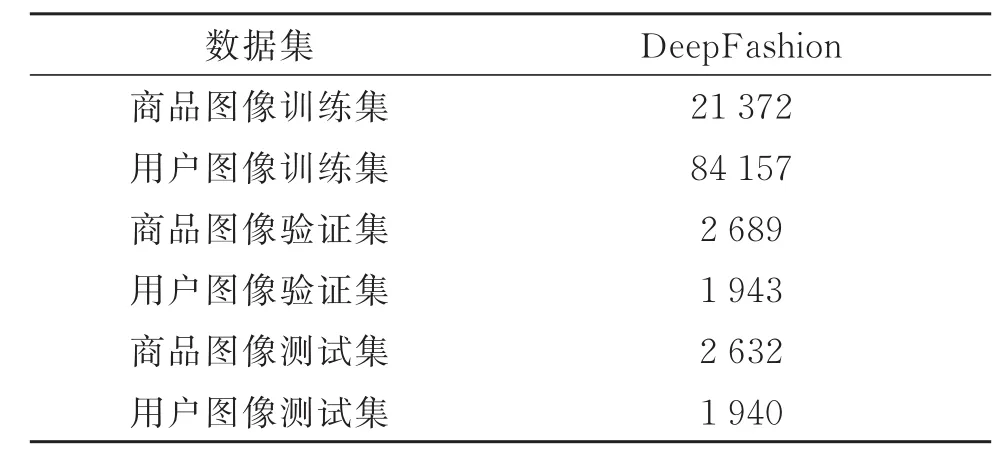
表1 数据集划分Table1 Dataset partition
3.2 基准方法
(1)AlexNet,在 WTBI框架[6]中采用 AlexNet网络FC6全连接层特征(4 096维)作为特征表达。网络在ImageNet的一个子集上进行预训练,然后提取用户服装图像和商城服装图像的特征。
(2)Contrastive,该方法基于 Siamese网络,采用传统对比损失函数[21]。在DeepFashion数据集的跨场景服装检索子集上进行训练,然后利用视觉特征计算不同场景服装图像的距离。
(3)DARN网络框架[10]有2个完全独立的嵌套NIN的网络分支,分别用于商品服装图像和用户服装图像,与Siamese网络共享底层。在DARN[10]网络顶层的全连接层用于类别和属性预测,训练损失是预测损失和三元组损失的加权组合。通过串联卷积层和全连接层的特征,利用特征向量计算三元组损失函数,调整卷积层的形状,再利用ImageNet上NIN的预训练参数,使之与原NIN模型[22]相同。
(4)FashionNet网络结构[2]以VGG-16为基础,所有图像通过同一组卷积层传递。顶层分支部分用于处理不同的任务,包括属性预测和关键点预测,而不是处理不同场景域。换言之,不同场景域的服装图像通过同一卷积层进行特征提取。由于受内存限制,本文沿用文献[7]中的处理方法,用VGGCNNN-S[23]取代DeepFashion使用的VGG-16模型[24]。同时,由于对服装关键点的研究超出了本文范围,因此去除了关键点预测子分支和属性预测分支。
3.3 评价指标
用top-k精度评估检索性能,定义如下:

其中,Q为查询总数,q指查询的用户服装图像;如果在返回的top-k排序列表中至少有1幅与q匹配的服装图像,则为命中,(q,K)=1;否则认为没有命中,(q,K)=0。对于大多数查询来说,在DeepFashion数据集中只有1个匹配的数据库图像。
3.4 实验结果和分析
实验在64位 Windows7操作系统,TiTan X和980 Ti,128 G内存环境下进行,算法采用Python和Matlab混合编程实现。将商品服装图像和用户服装图像作为输入,并以相应的top-k精度作为比较依据。
在上身服装图像上提取特征检索,实验中子网络均采用AlexNet结构,将4 096维的类别特征FCi和匹配特征FMi级联作为服装描述子。图4和表2为基准方法和本文方法在DeepFashion子数据集上的top-k精度对比,可知,在4种基线方法中,单一域网络结构且不考虑高层语义信息的AlexNet效果最差(P@20=0.150)。 FashionNet(P@20=0.239)以及DARN(P@20=0.239)的表现比单一Siamese网络(P@20=0.150)要好,这是因为均采用了分支结构并且添加了高层语义信息。FashionNet的效果要优于DARN,这与DeepFashion中的实验结果一致,其分支结构虽未用于域特定特征,但通过多任务训练提高了检索精度。在对比试验中,未采用关键点和服装属性数据,这也导致本文方法(P@20=0.481)要优于 FashionNet(P@20=0.431)。可以看出,在使用较少监督信息的情况下,本文方法的性能优于4个基准方法,结果与预期一致。通过结合高层语义信息和多分支网络,本文方法可以学习到更有表述力的服装特征描述子。
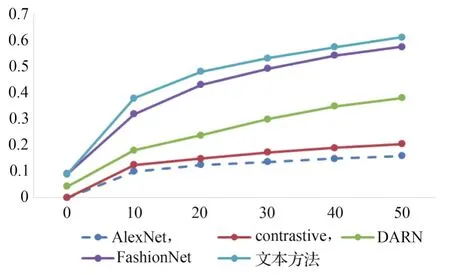
图4 跨场景服装检索top-k精度的比较Fig 4 Comparison of top-k accuracy of cross-scenario clothing retrieval
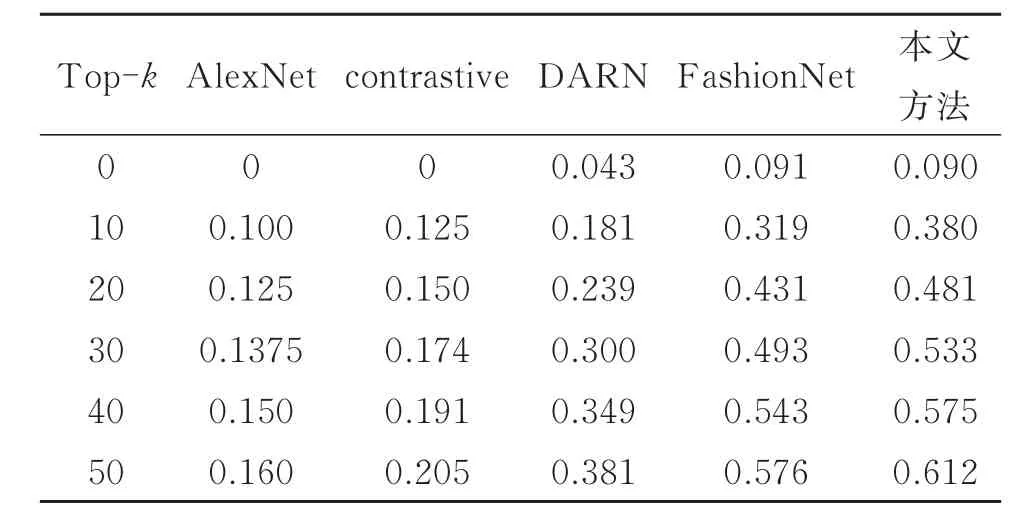
表2 跨场景服装检索top-k精度Table 2 Top-k accuracy of cross-scenario clothing retrieval
为了更好地理解任务和特征提取模型,分析了一些样例并进行查询。图5显示了top-3查询匹配结果,黑框表示查询图像,绿框表示匹配正确的查询结果。首先,查询结果图像(即第2~4列中的商品服装图像)与查询图像(即第1列中的用户服装图像)背景差异十分明显。因此,采用单独的网络分支分别提取特定特征是很有必要的。其次,部分商品图像,如第2、3组查询得到的商品图像也带有嘈杂的背景。因此,有必要引入额外信息,如类别信息,来提高模型的判别能力。

图5 部分服装图像检索结果Fig.5 Retrieval results of some clothing image
图6 展示了本文模型在top-3列表匹配失败的查询案例,虚线右侧表示查询对应的真值图像。可以看出,此类查询图像往往存在遮挡(第1组)、变形(第2组)或光线不足(第3组)的情况。同时,失败情况均为在类内查询的错误,这也从侧面表明,基于类别约束的检索方法是有效的。

图6 部分检索结果失败样例Fig.6 Some failed retrieval results of clothing image
4 结 论
针对大规模跨场景服装检索问题,提出了一种基于高层公共特征约束域特定特征的相似性度量算法。主要思想是利用类别信息约束传统对比损失函数,降低过拟合,提高特征的表述力,并且提出三分支网络结构融合域特定特征和高层语义公共特征。实验表明,本文算法具有明显的改善效果。今后将尝试更新模型以进一步提高查询准确率和效率。
