属性约简结合GWO-SVC的乳腺恶性肿瘤数据诊断研究
2019-08-14周孟然刘卫勇陈焱焱来文豪闫鹏程
周孟然 卞 凯* 刘卫勇 陈焱焱 胡 锋 来文豪 闫鹏程
1(安徽理工大学电气与信息工程学院 安徽 淮南 232001)2(中国科学技术大学附属第一医院(安徽省立医院) 安徽 合肥 230001)3(合肥博谐电子科技有限公司 安徽 合肥 230088)
0 引 言
癌症是严重威胁人类身体健康的疾病之一,癌症的出现率与死亡率一直居高不下[1],这不但影响着人们的正常生活,而且高额的医疗费用还会给人们带来了巨大的经济负担,为此,越来越多的研究者开始致力于癌症的诊断与治疗方法的研究[2]。其中,乳腺癌的发病率仅次于肺癌,位于全球癌症发病率的第二位[3],对于恶性肿瘤能够做到早察觉、早诊断、提前医治,可有效避免癌症晚期由于癌细胞扩散和转移,而错过最佳的治疗时期,减少疾病和化疗所带来的痛苦。
传统的乳腺癌诊断方法主要是细针穿刺细胞法[4],通过观察所采集组织切片的异常细胞来判断癌变程度,这种方法需要有资深临床经验的专家进行操作,但可能会由于各种不确定性因素造成错误诊断的情况时有发生。近几年来,模式识别的机器学习、深度学习知识已广泛应用于癌症等医疗健康的诊断与发病预测[5],并取得了不少的研究成果。如周华平等[6]将分别改进视野范围和移动步长的鱼群算法对极限学习机进行优化,建立乳腺肿瘤数据学习模型,实现了乳腺肿瘤的快速识别。该方法虽然识别速度快,但选取的是所有特征,未能排除低关联性冗余特征及随机噪声的干扰。王平等[7]则利用改进的随机森林算法搭建乳腺肿瘤诊断模型对恶性肿瘤进行识别。该方法虽然解决了误差代价敏感的不平衡分类问题,但调参过程无法精确控制模型内部的运行。林俊等[8]将提取特征后的乳腺癌数据用BPSO搜索最优子集,支持向量机建模。该方法虽然达到了预期的识别精度,但耗时较长。
SVM-RFE是一种特征提取方法,它可以消除多特征属性中重要度低的变量信息,减少噪声的干扰,有利于训练模型的搭建。SVM-RFE已用于网络安全、精准农业、医学等领域的研究,如Sahran[9]将SVM-RFE嵌入过程与绝对余弦滤波方法相结合,对前列腺组织病理进行分级。王婷[10]利用SVM-RFE对钓鱼诈骗网站进行检测,预防网页攻击。陈辉煌[11]采用SVM-RFE对鲜茶叶的高光谱数据进行特征波段提取,实现了鲜茶叶分类与识别。
GWO属于新型群智能优化算法,它主要用于优化函数和聚类等问题,以提高训练模型的性能,如Abdelshafy[12]采用混合PSO-GWO方法对可再生能源驱动的并网海水淡化装置进行优化设计。孙俊[13]将迭代保留信息变量法与GWO优化的支持向量回归模型相结合,用于检测番茄叶片的含水量。刘二辉[14]把改进的GWO算法用于小车的路径规划问题研究,实现了更优的路径自动引导机制。
本文采用SVM-RFE算法先对乳腺癌数据的属性进行特征提取和降维处理,减少了冗余特征及随机噪声的干扰。将GWO与SVC结合的GWO-SVC优化分类模型建模用于乳腺癌的预测诊断,识别精度高、模型简单,具有应用的可行性与实际推广价值。
1 算法介绍
1.1 SVM-RFE算法
SVM-RFE是由Isabelle Guyon等提出的数据特征提取降维方法[15]。SVM-RFE属于需要通过模型的性能进行评价特征优势的Wrapper法,RFE算法采取贪心原理先优先保留特征集合,利用SVM的最大间隔原理进行序列后向选择,根据分类器权值ω作为特征排序评判标准删选出保留大量重要度高的特征属性信息。
SVM-RFE消去低重要度特征属性的步骤如下:
(1) 输入训练样本数据A={α1,α2,…,αn}T及类别标签l={l1,l2,…,ln}T。
(2) 初始化特征属性集合W={W1,W2,…,Wn}及重新排序的特征属性集合W*={}。
(3) 用目前的SVM分类器对输入数据进行训练,获取特征属性的有关参量信息。
(4) 计算特征代价函数:
h(x)=-0.5ATI(-x)A+0.5ATI(x)
(1)
式中:I是一个具有元素lijK(xi,xj)的矩阵,I(-x)为消除x个特征后的矩阵,K表示的是xi与xj之间相关性的核函数。
(5) 根据权值向量ω作为特征重要度排序标准,重新排序特征属性集合。获得特征属性排序集合:
(6) 根据SVM分类器训练好的分类精度大小对最终特征属性进行选取,得到消除后的特征属性集合:
1.2 GWO-SVC算法
灰狼优化(Grey Wolf Optimization, GWO)是由Mirjalili等于2014年提出的一种先进的启发式群智能优化算法[16],主要是仿照灰狼社会等级制度及其捕食行为方式所研究出的算法[17]。在训练模型搭建的过程中,用灰狼优化算法优化支持向量分类(support vector classification, SVC)算法的惩罚系数c和核函数参数g,改变模型性能,得到比较理想的分类准确率。
GWO寻优SVC参数的步骤如下:
(1) 由可行域X={x1,x2,…,xn}生成父代灰狼、突变灰狼和子代灰狼三种规模相同的原始群体。
(2) 初始化原始狼群的位置,获取种群中灰狼个体的适应度η,狼群个体位置由惩罚系数c和核函数参数g组成。
(3) 搜索父代灰狼排名顺序前三位的个体,不断更新灰狼捕食猎物时所处位置,可由如下公式计算:
Q(t+1)=[(Qα-K1|Q-H1Xα|)+(Qβ-K2|Q-
H2Xβ|)+(Qγ-K3|Q-H3Qγ|)]/3
(4)
式中:Qα、Qβ、Qγ表示为灰狼所在位置,K1、K2、K3、H1、H2、H3表示为比例系数。
(4) 更新参数Z、V、a的值:
Z=2l2
(5)
V=2cl1-c
(6)
(7)
(5) 输出的全局最优位置即为SVC中的c和g的最优值,如果没有达到迭代次数,则返回步骤(3)。
(6) 利用优化后的c、g建立SVC模型进行分类。
2 数据获取
2.1 病例数据获取
为了验证本文所叙述方法的有效性与可行性,采用UCI数据库中威斯康辛大学569个病例的乳腺癌数据集,其中有357个良性肿瘤病例、212个恶性肿瘤病例。本研究工作选取560个病例作为研究对象,其中有350个良性病例、210个恶性病例,该数据前两条属性为病例编号和诊断结果,第3~12条属性特征为乳腺肿瘤病灶组织的细胞核显微图像的量化特征,分别是半径大小、纹理、周长、面积、平滑程度、密实度、凹度、凹点数、对称性、分形维数,其他各属性依次是量化特征的平均值、标准差、最坏值。仿真实验针对后30条特征属性,诊断结果作为标签进行,最后可以根据细胞核显微图像的量化特征诊断乳腺癌肿瘤是良性或者是恶性的。
2.2 训练集与测试集选取
按4∶1的比例把乳腺癌数据集560个病例随机划分成训练集和测试集,采用顺序划分法,随机选取448个病例样本作为训练集(良性病例280个、恶性病例168个),剩余112个病例样本作为测试集(良性病例70个、恶性病例42个)。仿真测试将采用划分好的训练集和测试集进行数据建模实验。实验所用电脑的硬件条件为英特尔酷睿i7处理器,4 GB内存,Win7系统,在软件MATLAB R2016b环境下利用算法对数据进行仿真测试,支持向量机选择libsvm-mat-3.0工具包运行。
3 实验结果分析
3.1 SVM-RFE次要属性约简
SVM模型的默认初始惩罚系数c取值为2,核函数参数g取值为1,核函数类型选择径向基(RBF)核函数。为了避免特征属性数据值的差异过大,对训练速率和结果的影响,将数据按比例归一化到[0,1]区间范围内。现采用SVM-RFE 算法将560个病例(良性350例、恶性370例)数据进行次要属性约简工作,如图1所示,横坐标为属性条数,纵坐标为权值大小。该统计图依据SVM-RFE算法的训练结果展现了乳腺癌数据30条属性特征的权重ω大小,充分反映出乳腺癌各条属性之间的重要程度存在着明显差异。可以清楚看到第22条属性的权值最大,达到4.87,重要程度较高的区域主要集中在第21至25条属性范围和28、29条属性,值都达到2.5以上,说明细胞核显微图像量化特征部分标准差及最坏值涵盖了数据的大量重要信息。而第17至19条属性和第26条属性的权值都在0.1以下,则这些属性特征重要程度很低。由不同属性的权值大小按从大到小排序的方式可得到新的重要度属性排序为{22,21,23,25,28,29,24,2,8,11,1,3,4,7,27,13,10,14,16,15,6,9,5,20,30,12,17,18,19,26}。
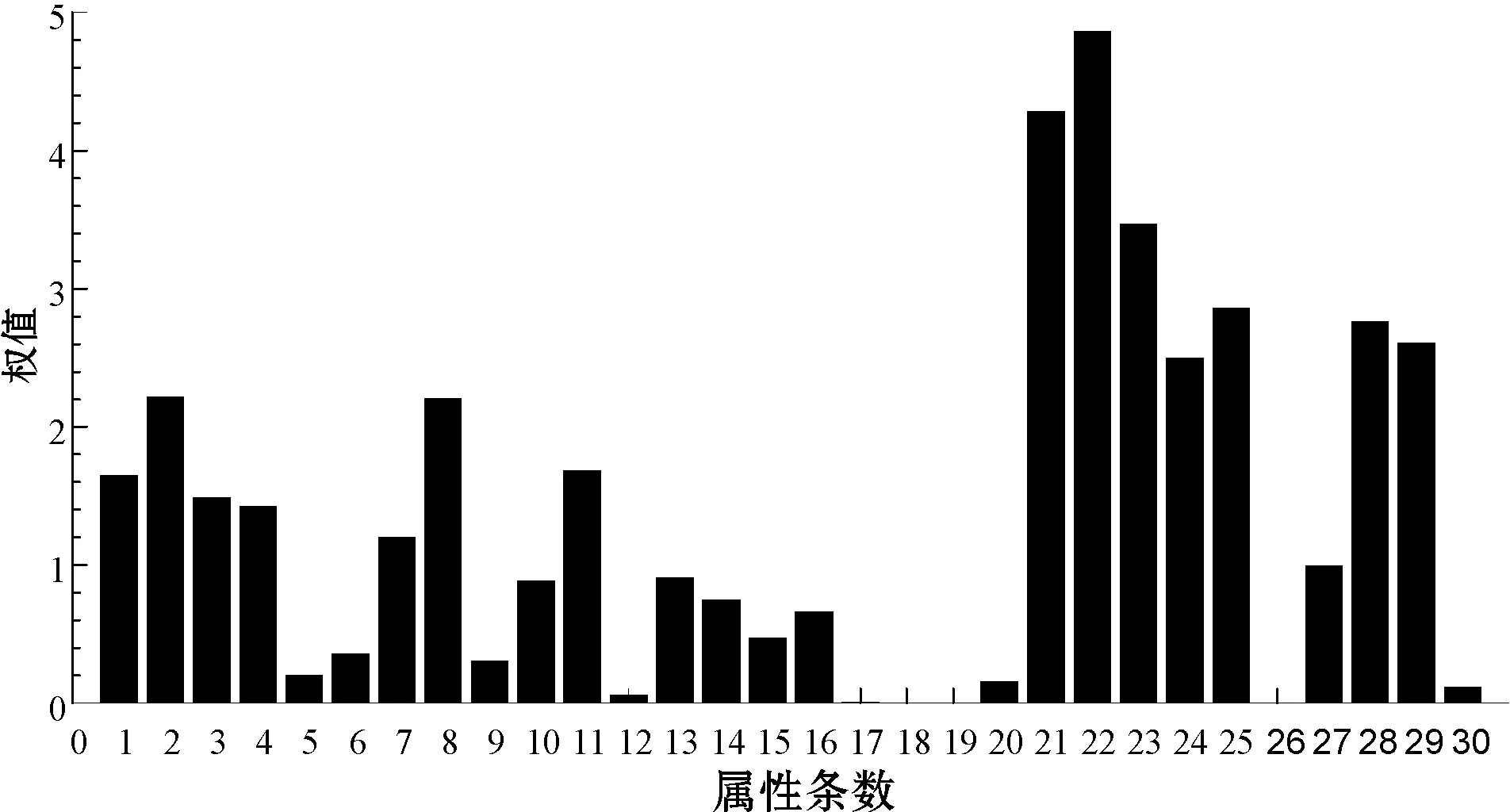
图1 权值条形统计图
因为第一条属性为最后一个被消去的属性,也是最重要的属性,所以要以特征排序中第一条属性特征为基准,每次按一条属性特征的量依次增加和扩展,组成不同属性的特征集合。特征属性与分类准确率关系如图2所示,横坐标为属性条数,纵坐标为支持向量机分类准确率。当选择的属性集合从1条增广到4条特征时,训练集和测试集的准确率迅速增加且增幅很大。再由4条扩展到6条属性特征时,训练集和测试集的准确率发生轻微下降的现象。最后当由6条属性特征扩展到18条属性特征时,训练集和测试集的准确率达到最大值,后面属性特征的准确率都开始慢慢趋于稳定。
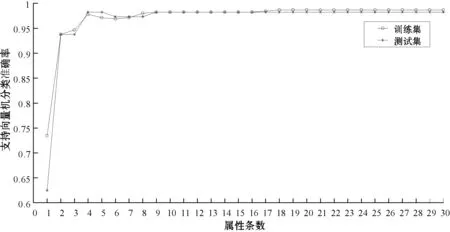
图2 特征属性与分类准确率关系
观察到前18条属性特征的分类准确率结果值整体呈上升趋势,当训练集的准确率在嵌套特征属性集合为{22,21,23,25,28,29,24,2,8}时首次增长到最大值98.21%,其中有8个病例误判,而测试集的准确率在属性集合选择为{22,21,23}时,首次达到最大值98.21%,其中有2个病例误判,之后在选择属性集合为{22,21,23,25,28,29,24,2,8,11,1,3,4,7,27,13,10,14}时,测试集准确率第二次达到最大值98.21%。从提高预测精度角度来看,特征提取就是要选择特征子集来增加分类精度,或者在不降低分类精度的条件下降低特征集维数的过程[18]。因此,最高预测精度对应的最小特征子集,即为该特征排序的最优特征子集,并根据奥卡姆剃刀原则(使训练模型不太复杂)[19],最终选取包含18条属性的集合作为SVM-RFE所约简出的最优特征子集,较全部属性减少了12个。
3.2 GWO-SVC模型的搭建
利用上述SVM-RFE所约简出的18条属性特征乳腺癌数据作为输入,诊断结果作为标签,搭建GWO-SVC模型,分析乳腺癌诊断判别结果。GWO中的初始狼群数量设为10,最大迭代次数设为20代,惩罚系数c和核函数参数g搜索区间为[0,100]。最后CV意义下的最佳交叉验证精度为89.28%,训练集的分类结果如图3所示,诊断类别标号0代表良性,1代表恶性,训练集分类准确率为99.33%,3个病例识别错误。测试集的分类结果如图4所示,可以看出测试集仅有一个病例识别错误,为第73个病人,测试集分类准确率高达99.11%,表明该方法很好地适用于乳腺恶性肿瘤识别检测。
图3 训练集分类结果图
图4 测试集分类结果图
为了验证GWO-SVC模型结合RFE-SVM算法用于乳腺肿瘤诊断的识别精度与诊断效果,本文将与特征提取18条属性的未优化支持向量机分类结果进行纵向对比,与布谷鸟(CS)、人工蜂群(ABC)、萤火虫(FA)、粒子群(PSO)、遗传算法(GA)这几种群智能算法优化的支持向量机分类结果进行横向对比,利用MATLAB R2016b软件对UCI数据集中乳腺癌数据提取18条属性后的数据进行算法仿真测试。为了保证条件统一,初始种群数量都设置为10,迭代次数都设置为20。数据未归一化的对比分类结果如表1所示,虽然各建模方法训练集的准确率达到100%,但是测试集的准确率很低,平均准确率仅有63.01%,因为乳腺肿瘤显微图像半径大小、纹理、周长、面积,这4个量化特征数据值都远大于其他量化特征值,造成训练时间增大,也导致最终无法收敛,识别精度不高。
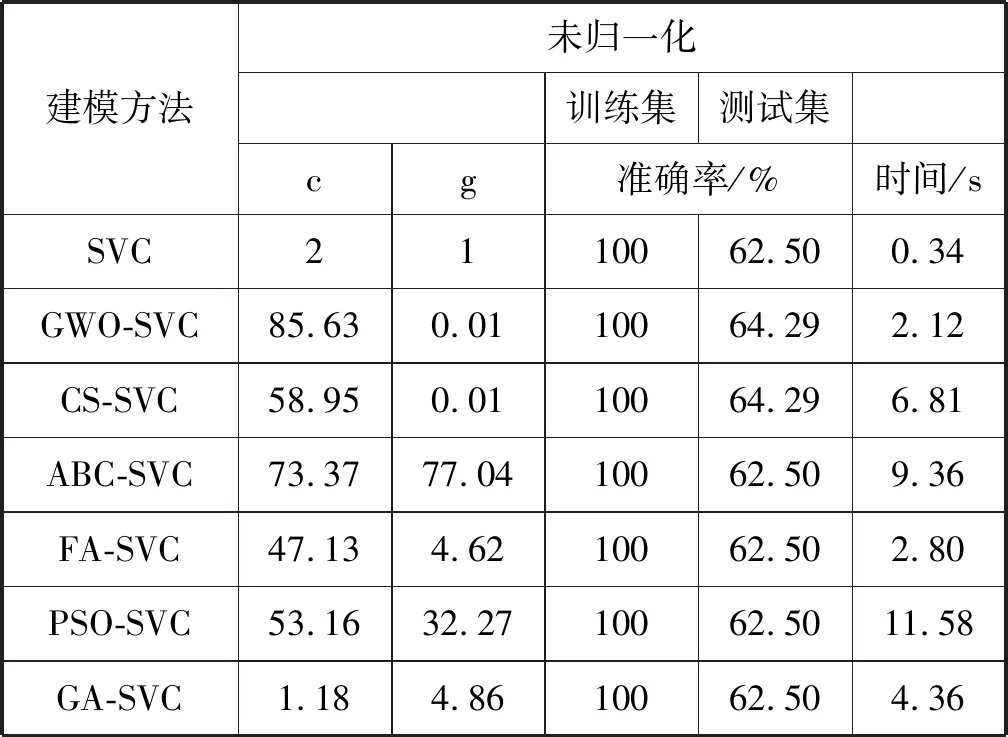
表1 未归一化的对比分类结果
表2为归一化到[0,1]区间的对比分类结果表,可以看到虽然ABC算法能使训练集分类准确率达到100%,但测试集分类准确率要小于GWO和CS,且训练时间较长。GWO和CS算法在测试集建模中准确率最高,都仅有一个病例识别错误,模型的预测性能得到提升,但GWO-SVC模型的训练时间要明显快于CS-SVC。综合分类准确率和时间来看,最终的GWO-SVC模型用于乳腺肿瘤的诊断是可靠且有效的。通过比较表2和表3可以看出,经过[0,1]归一化后数据所建立模型在训练速度及精度上都有所提高。
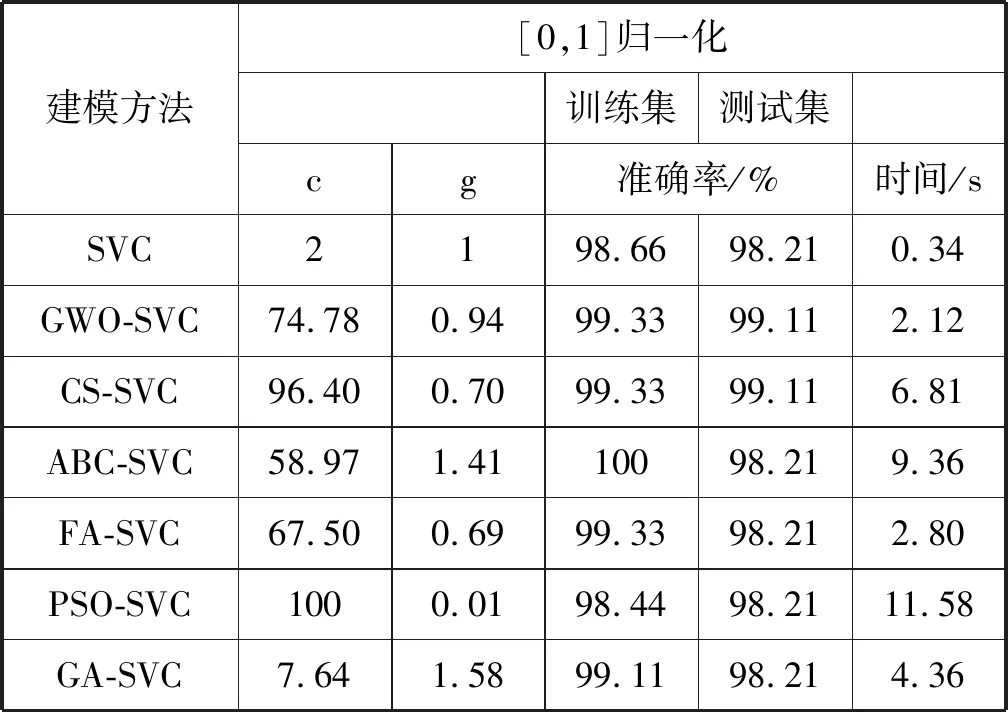
表2 归一化的对比分类结果
良好的泛化性能可保证训练模型的可靠性,本文所用算法如果对于不同数据集都能取得良好的分类效果,则可体现出该算法有较强的适应能力与泛化性能。现采用UCI数据库中的106个乳腺样本的电阻抗特性数据进行算法泛化性能的验证,样本分为病变组织和正常组织,随机划分成80个训练集(正常40个、病变40个)和26个测试集(正常12个、病变14个),使用MATLAB R2016b软件将划分好的样本先进行SVM-RFE属性约简,再利用GWO-SVC建模(统一采用[0,1]归一化处理),与未经优化的SVC对比分类结果如表3所示。不管是训练集还是测试集的准确率都高于普通SVC,训练集准确率提升了18.75%,全部分类正确,测试集准确率提升了11.53%,仅一个样本错分,耗时仅需约0.79 s,满足癌症诊断的分类精度和时间,而未经参数优化的SVC分类准确率都不高,可能发生了欠拟合。
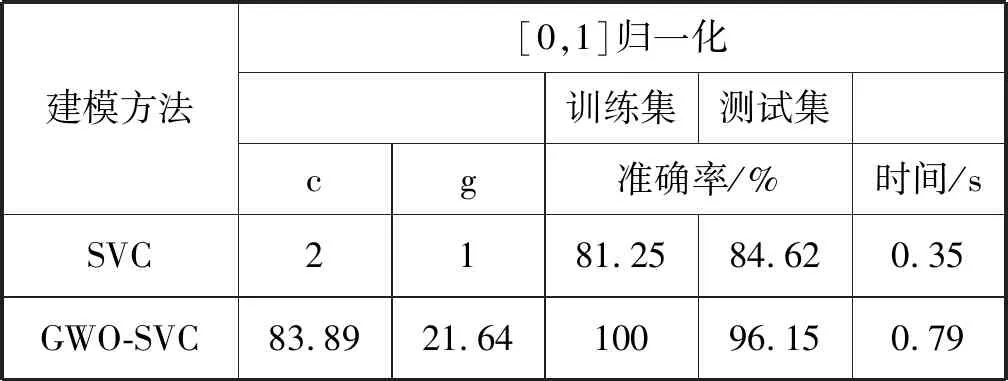
表3 对比分类结果
4 结 语
本文先通过SVM-RFE对乳腺癌数据集的30条属性进行重要特征提取,并结合GWO-SVC算法建立乳腺肿瘤诊断模型,最后对比不同种建模方法下分类结果不难发现:
(1) 利用SVM-RFE法所约简出18条属性就可以代表30条属性信息的重要特征,排除了次要属性数据干扰,简化了模型的复杂程度,增强了学习效率。
(2) 在训练过程中,GWO优化的c、g参数用于SVC的乳腺肿瘤诊断建模不仅拥有很高的识别精度,避免过拟合及欠拟合的发生,还保证了高精度下的快速诊断,节省了时间。归一化后的数据摆脱了样本数据差异过大的影响,加快了最优解速度,提高了分类精度。
(3) GWO-SVC模型适应能力、可靠性强,泛化性能和鲁棒性好,不仅适用于乳腺肿瘤的恶性识别,还适用于乳腺病变组织等其他癌症疾病的识别。
(4) SVM-RFE结合GWO-SVC算法应用于乳腺肿瘤诊断是可行的,使恶性肿瘤做到早发现、早诊断、早治疗,对于癌症能取得良好的医治效果。
