一种改进的混合多因子推荐算法
2019-08-12夏景明周刚谈玲李冲
夏景明 周刚 谈玲 李冲
摘 要: 在新闻网站、电子书城等应用中,为了提高计算用户间的相似性,在传统基于用户协同过滤和基于内容的混合推荐的基础上,引入人口统计信息和专家信任等因子,对混合推荐算法进行改进。最后,通过GroupLens提供的数据集对算法进行验证,与传统基于用户和基于项目的协同过滤算法相比,文中所提算法在准确率上有显著的提高。
关键词: 算法改进; 个性化推荐; 内容推荐; 协同过滤; 算法验证; 混合推荐
中图分类号: TN911.1?34; TP183 文献标识码: A 文章编号: 1004?373X(2019)15?0101?05
An improved hybrid multi?factor recommendation algorithm
XIA Jingming1, ZHOU Gang1, TAN Ling2, LI Chong1
(1. School of Electronic & Information Engineering, Nanjing University of Information Science and Technology, Nanjing 210044, China;
2. School of Computer and Software, Nanjing University of Information Science and Technology, Nanjing 210044, China)
Abstract: In news websites, e?book malls and other applications, in order to improve the similarity between computing users, the demographic information and expert trust factors are introduced on the basis of the traditional user?based collaborative filtering and content?based mixed recommendations. The hybrid recommendation algorithm is improved. The algorithm is verified by means of the dataset provided by GroupLens. In comparison with traditional user?based and project?based collaborative filtering algorithms, the accuracy of the algorithm has been significantly improved.
Keywords: algorithm improvement; personalized recommendation; content recommendation; collaborative filtering; algorithm verification; mixed recommendation
0 引 言
在实现基于内容推荐和协同过滤推荐的混合推荐算法时,存在数据稀疏性问题,如果用户评分矩阵非常稀疏,在计算用户相似性时将会遇到困难,如果单依靠传统常见评级的推荐算法来确定用户之间的相似性,任何一个都存在一定的误差。所以,影响协同过滤技术的准确性是一个主要问题。在对用户进行预测的过程中,用户会得到推荐那些以前没有评价过的商品,但是这些商品在他的小社区已经得到了用户的正面评价,只依靠他的社区近邻的小概率点击是不准确的。同时,由于没有考虑到用户的年龄、性别、职业、地理位置等人口统计信息以及专家意见,在预测准确度上存在偏差。因此,本文在基于内容和协作推荐算法的基础上,引入人口统计信息[1]和专家意见等因子[2]来提高预测评分的准确性。
基于协同过滤的推荐算法[3?4]是通过用户与数据项之间的特殊关系,系统给出一个推荐物品列表。基于内容的推荐算法[5?6],考虑了属性信息和文本的内容,因此系统会给出一个满足用户需求的推荐项目列表。人口统计信息考虑了用户的性别、年龄、职业、薪资等因数,在计算用户间的相似性起到一定程度的补充作用。专家意见相比普通用户有着更好的合理性,提高了预测结果的置信度。结合以上方法的优点,本文设计一种混合的推荐算法,相比单一的基于内容推荐或者基于协同过滤的推荐在准确率上存在明显的优势。
1 混合推荐系统
在当今的推荐系统中,基于内容推荐和协同过滤在推荐系统应用中有着很重的比例,两者各有优点,但是在单独使用时,存在很多限制,同时,由于没有考虑人口统计信息和专家意见,在计算准确度上存在一定的误差。混合推荐作为两种或更多种方法的组合,已经提出克服传统推荐方法的主要限制并改进所提供的推荐质量[7]。
混合推荐算法类型如下:
集成类型:通过调整不同的推荐算法,将不同类型的算法组合成一个整体。
流式型:建议过程被分成几个子过程,依次使用各种推荐算法生成最终的推荐列表。
并联型:核心思想是利用几种混合机制将推荐项目混合在一起的算法[8]。
三种并联混合算法描述如下[9]:
1) 并联混合:在呈现给用户的阶段,几种方法的结果混合在一起。因此,在这种情况下,用户[u]和项目[i]的推荐结果是一个推荐数组,每个推荐数组对应[n]个推荐结果,对应公式如下:
2) 权重混合:固定线性方程用于连接两个独立推荐算法结果列表。由于权重方案是静态的,因此必须指定方程,推荐结果和相对权重定义如下:
3) 切换混合:切换混合算法存在几个推荐人,选择最相似的一个推荐人产生的推荐。对于[k]个推荐系统的情况,用户[u]和项目[i]描述如下:
2 一种改进的用户多因子混合推荐算法
2.1 算法策略
在计算两个用户相似度时,传统的协同过滤算法没有考虑专家意见、人口统计信息等间接因素,因此最终预测分数可能会有一些偏差。本文针对这些缺点进行改进,在对待普通用户时,首先计算用户兴趣[10]的分布矩阵,完成用户间兴趣相似度计算。然后结合人口统计信息,进一步提高用户间的相似度计算,完成预测分数。对待专家意见,由于在某个领域,专家评分矩阵相比普通用户评分矩阵更加合理,借鉴专家意见可以提高推荐置信度。
在提出建议时,首先,找到与用户[u]相似的资源聚合,使用[K]维向量来表示用户偏好,计算用户兴趣相似度并更新用户兴趣的分布矩阵,经过多次操作,用户兴趣趋于稳定,计算用户间的兴趣相似性[11],找到基于兴趣相似近邻集合[Ulist]。然后,在兴趣相似近邻集合[Ulist]的基础上,基于普通用户间的人口统计信息,计算人口统计信息的相似性,找到最终的近邻集合[Unear],完成普通用户预测分数。其次,根据专家的评分矩阵计算用户[u]和专家[e]之间的相似度,找到最终的近邻结合[Ue],计算目标用户[u]和近邻专家[e]之间的相似度,进行预测评分。最后,基于协同过滤的推荐算法计算目标用户对项目的评分,由普通用户近邻评分和专家近邻评分的线性组合完成预测,最终的预测评分由基于内容和协作加权取得。
2.2 算法描述
由于资源类别的数量远远少于资源数量,因此将所有兴趣资源转变为用户兴趣类别,从而减少计算量。例如,图书商城的资源包括期刊、专著、报纸和其他类型的财产,包括能源、计算机、建筑、机械、文学和其他属性。根据项目类别表示用户的兴趣,这是基于用户?项目评级矩阵和项目类别属性特征建立用户类别属性矩阵,从而获得每个用户的兴趣[12]。
根据项目类别表示用户兴趣,即基于用户?项目评分矩阵和项目类别属性特征建立用户类别属性矩阵,从而获得各个类别的兴趣。该分配可以按照下面的PM矩阵进行描述:
3 算法验证
在本节中,将改进的混合算法与传统的协同过滤算法和基于内容的算法进行比较,并且对得到的实验结果进行分析。
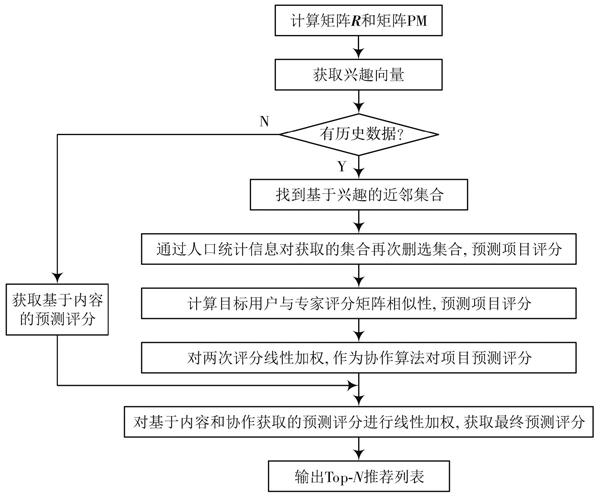
图1 混合算法流程图
3.1 评价指标
统计准确性度量标准是通过将预测评级直接与实际用户评级进行比较来评估推荐技术的准确性。MAE(平均绝对误差)通常用作统计精度度量。它是推荐偏离用户特定值的一种度量,计算如下:
为了验证实用性和可靠性,使用centOS6.8系统,用Python2.7进行算法实现。在实验中,把数据集分成80%的训练集和20%的測试集。在实验过程中,根据用户对训练集中记录的访问来计算一组建议,如果推荐一组资源出现在访问记录的测试集中,则生成一个正确的推荐。
3.2 参数设置
影响混合算法推荐效果的参数有三个:第一个参数[a]是在计算普通用户之间的相似度时根据普通用户间的兴趣度和人口统计信息的因数进行取值,参数大小取值范围为[0.1,0.9];第二个参数[α]是在基于普通用户的预测分数的基础上,借鉴专家评分矩阵,两个预测评分进行线性加权,参数大小取值范围为[0.1,0.9];第三个参数[β]是对基于内容的推荐和基于用户的协同推荐进行线性加权,加权后得到最终的预测分数,参数大小取值范围为[0.1,0.9]。
试验中,选择的近邻个数[N]分别为20,40,60,80,100,120和140。在本实验中,不断组合三个参数值的大小,使得混合算法的推荐效果最优,并与传统的协同过滤等算法进行比较。
3.3 数据集
本试验中使用了GroupLens数据集,该数据集总共有900个用户对1 563本书进行评论,总评论数量达到了110 000条,其中,每位用户评论了20本书,其分数由1~5构成,这些数据构成本实验使用的参考数据集。
3.4 实验结果
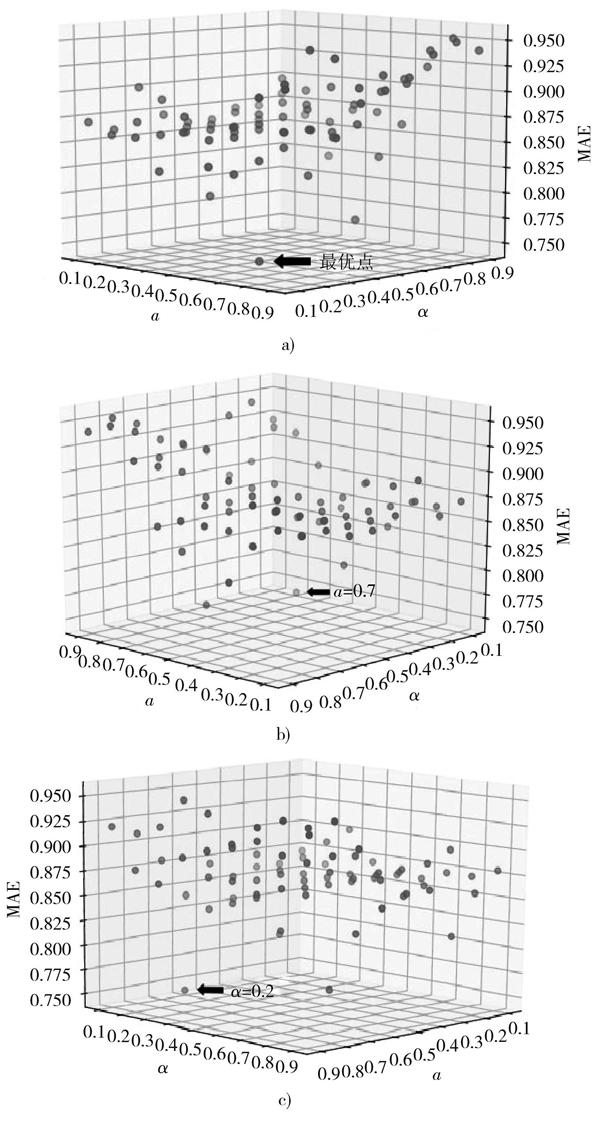
首先,[a]和[α]取值范围为[0.1,0.9],依次代入式(9)、式(13)中,使得在普通用户兴趣度稳定下基于人口统计信息和专家建议的协同算法对目标用户的物品打分的预测值与真实值之间的[MAE]最小,结果如图2所示。
图2 基于人口统计和专家评分的协同推荐MAE值
由图2可知,当[a]取值为0.7,[α]取值为0.2时,在普通用户兴趣度稳定下基于人口统计信息和专家建议的协同算法下目标用户对物品打分的预测值与真实值之间的[MAE]最小。
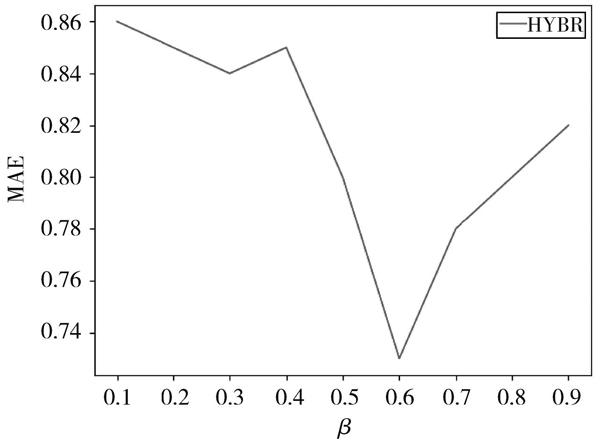
最后,由式(14)可知混合推荐结果加权系数 [β]取值范围为[0.1,0.9],进行MAE测试,实验结果如图3所示。
由图3可知,当[β]取值为0.6时,使得MAE值最小,结合内容推荐和协同过滤推荐效果达到最优。
图3 混合推荐算法MAE值
为验证所提方法的有效性,与传统的协同过滤推荐算法相比,用户数逐渐增加,计算推荐算法的MAE实验结果如图4所示,当近邻数为120,参数[(a,α,β)=(0.7,0.2,0.6)]时,混合推荐算法产生的推荐效果最佳。
图4 三种算法效果对比

4 结 论
本文提出一种在内容与协作基础上融入人口统计信息和专家意见的混合推荐算法。该混合推荐算法使用历史信息的用户评级来生成用户兴趣并产生最近邻集合,再参考人口统计信息和专家意见生成有效最近邻组进行预测评分,最终根据内容推荐和协作推荐的预测评分产生最终的预测评分,生成目标用户的推荐列表。实验结果表明,在计算预测评分上,与传统基于用户和基于项目的协作算法相比,有效地提高了预测评分的准确性。
参考文献
[1] DAI Y, YE H, GONG S. Personalized recommendation algorithm using user demography information [C]// 2009 Second International Workshop on Knowledge Discovery and Data Mining. Moscow: [s.n.], 2009: 100?103.
[2] 高发展,黄梦醒,张婷婷. 综合用户特征及专家信任的协作过滤推荐算法[J].计算机科学,2017,44(2):103?106.
GAO Fazhan, HUANG Mengxing, ZHANG Tingting. Collabo?rative filtering recommendation algorithm based on user characteristics and expert opinions [J]. Computer science, 2017, 44(2): 103?106.
[3] WU Q, HUANG M, MU Y. A collaborative filtering algorithm based on user similarity and trust [C]// 2017 14th Conference on Web Information Systems and Applications (WISA). Liuzhou, Guangxi Province, China: [s.n.], 2017: 263?266.
[4] WANG X, WANG C. Recommendation system of e?commerce based on improved collaborative filtering algorithm[C]// 2017 8th IEEE International Conference on Software Engineering and Service Science. Beijing: IEEE, 2017: 332?335.
[5] PAL A, PARHI P, AGGARWAL M. An improved content based collaborative filtering algorithm for movie recommendations [C]// Proceedings of 2017 Tenth International Conference on Contemporary Computing. Noida: [s.n.], 2017: 1?3.
[6] MATHEW P, KURIAKOSE B, HEGDE V. Book recommendation system through content based and collaborative filtering method [C]// 2016 International Conference on Data Mining and Advanced Computing. Ernakulam: [s.n.], 2016: 47?52.
[7] 高虎明,赵凤跃.一种融合协同过滤和内容过滤的混合推荐方法[J].现代图书情报技术,2015(6):20?26.
GAO Huming, ZHAO Fengyue. A hybrid recommendation method combining collaborative filtering and content filtering [J]. New technology of library and information service, 2015(6): 20?26.
[8] 肖斌,徐佳庆,张宇洋.基于协同过滤算法的个性化图书推荐系统研究[J].电脑知识与技术,2016,12(27):155?158.
XIAO Bin, XU Jiaqing, ZHANG Yuyang. Research on perso?nalized book recommendation system based on collaborative filtering algorithm [J]. Computer knowledge and technology, 2016, 12(27): 155?158.
[9] REDDY Raj. Million books digital library project: research issues in data mining and text mining [D]. Pittsburgh: Carnegie Mellon University, 2006.
[10] 全海金,邱玉辉,李瑞.基于用户行为及语义相关实时更新用户兴趣的推荐系统[J].計算机科学,2005(3):76?78.
QUAN Haijin, QIU Yuhui, LI Rui. The recommender system with real?time updated user interests based on user behaviors and similar semantic [J]. Computer science, 2005(3): 76?78.
[11] 杨秀萍.融合用户评分和属性相似度的协同过滤推荐算法[J].计算机与现代化,2017(7):16?19.
YANG Xiuping. Collaborative filtering recommendation algorithm based on user score and user attributes similarity [J]. Computer and modernization, 2017(7): 16?19.
[12] YANG W, CUI X, LIU J, et al. Users interests?based movie recommendation in heterogeneous network [C]// 2015 International Conference on Identification, Information, and Know?ledge in the Internet of Things. Beijing: [s.n.], 2015: 74?77.
[13] 焦东俊.基于用户人口统计与专家信任的协同过滤算法[J].计算机工程与科学,2015,37(1):179?183.
JIAO Dongjun. Collaborative filtering algorithm based on user demographics and expert opinions [J]. Computer engineering &science, 2015, 37(1): 179?183.
[14] WANG B, TAO Z, HU J. Improving the diversity of user?based Top?N recommendation by cloud model [C]// 2010 5th International Conference on Computer Science & Education. Hefei: [s.n.], 2010: 1323?1327.
