基于自编码特征的语音增强声学特征提取*
2019-08-12任相赢耿彦章
张 涛,任相赢,刘 阳,耿彦章
天津大学 电气自动化与信息工程学院,天津 300072
1 引言
在现实环境中,感兴趣的语音通常会被背景噪声干扰,严重损害了语音的可懂度和质量,多种语音增强算法已被用于噪声抑制,主要分为基于信号处理的方法、基于统计模型的方法和基于深度学习的方法等[1]。语音增强已成为语音通话、电话会议、助听器设备和语音识别等领域的前端处理核心模块,语音增强可以很自然地表达为一个监督性学习问题,因此本文研究的重点是基于深度学习的语音增强。
典型的监督性语音增强系统通常通过监督性学习算法,例如深度神经网络(deep neural network,DNN),学习一个从带噪语音特征到分离目标(例如理想掩蔽或者增强语音的幅度谱)的映射函数,从监督性学习的角度来看,监督性语音增强主要涉及特征、模型和目标三方面的内容。模型主要分为浅层模型和深层模型,以DNN为代表的深度学习是深层模型的典型代表[2-5],目前已被广泛用于语音增强中;理想掩蔽、目标语音的幅度谱或对数幅度谱是监督性语音增强的常用目标[6-7]。本文以DNN作为学习模型,以理想浮值掩蔽(ideal ratio mask,IRM)作为训练目标,主要研究声学特征对于语音增强性能的影响。Wang和Chen等在文献[8-9]中系统地总结和分析了Gammatone滤波变换域特征,提出了一系列组合特征和多分辨率特征,语音增强后可懂度得到了较大提升,但是语音质量仍然较低,信噪比(signal noise ratio,SNR)取值仍然较小。SNR是一种衡量增强算法对噪声抑制能力的指标,SNR取值较小,意味着增强语音中仍然混合大量噪声。在保证增强语音可懂度基本不变的条件下,为了提高增强语音质量(用信噪比衡量),本文提出了一种声学自编码特征(auto-encoder feature,AEF),利用Group Lasso算法将AEF与听觉特征进行互补性和冗余性验证,进而将特征重新组合得到新的特征集,本文将该新的特征集称为综合特征(integrated features,IF)。将本文的综合特征与Wang的组合特征以及Chen的多分辨率特征分别作为DNN输入特征,比较语音增强性能。实验结果表明本文提出的基于AEF特征的综合特征在语音增强中取得了较好的性能。
本文在第2章介绍了几种常用听觉特征;第3章主要介绍了本文提出的自编码特征,以及利用Group Lasso算法进行特征选取得到的综合特征;第4章对本文提出的特征进行了性能评估;第5章对全文进行总结。
2 组合特征及多分辨率特征
语音增强被表达为一个学习问题,特征提取是至关重要的步骤,提取好的特征能够极大地提高语音增强性能。近年来,随着语音增强研究的发展,已有多种听觉特征被用于语音增强中,取得了较好的性能,下面是常用的几种听觉特征。
(1)AMS(amplitude modulation spectrogram)
为了计算AMS特征,首先对输入信号的包络进行半波整流,然后进行1/4抽样,抽样后得到的信号以128点帧长和40点的帧移进行分帧,汉明窗平滑预处理,256点的短时傅里叶变换(short-time Fourier transform,STFT)将预处理后的时域信号变换到频域,得到的幅度谱通过15个中心频率在15.6~400 Hz均匀分布的三角窗,得到15维的AMS特征。
(2)RASTA-PLP(relative spectral transform PLP)
RASTA-PLP特征是在 PLP(perceptual linear prediction)特征基础上引入RASTA滤波,PLP能够尽可能地消除说话人的差异而保留重要的共振峰结构,一般认为是与语音内容相关的特征。相对于PLP特征,RASTA-PLP对噪声更有鲁棒性,通常计算13维的RASTA-PLP特征。
(3)MFCC(Mel-frequency cepstral coefficient)
梅尔频率倒谱系数将频谱转化为基于Mel域的非线性频谱,充分考虑了人耳的听觉特性,没有前提假设,因此具有良好的识别性能和降噪性能。语音信号首先分帧加窗预处理,利用快速傅里叶变换(fast Fourier transformation,FFT)计算能量谱,将能量谱转换到梅尔域,在梅尔域内能量谱经三角带通滤波器后得到滤波输出,滤波输出经过离散余弦变换得到31维MFCC特征。
(4)GF(Gammatone feature)
GF特征是语音信号通过Gammatone听觉滤波器得到的,对每一个Gammatone滤波输出按照100 Hz的采样频率进行采样,最后对采样进行立方根幅度压缩得到GF特征,一般提取64维的GF特征。
(5)MRCG(multi-resolution cochleagram)
GF特征只考虑了语音的局部信息,忽视了全局信息。为了补偿这一缺点,把握语音信息的整体性和时空结构,Chen等提出MRCG特征,具体计算过程如下:
①给定输入信号,经64通道的Gammatone滤波器组获取子带信号,每一子带信号以20 ms帧长10 ms帧移进行分帧,逐帧计算听觉谱(Cochleagram)[9],对每个时频单元取对数运算得到CG1;
②同样的,每一子带信号以200 ms帧长10 ms帧移进行分帧,计算CG2;
③使用11×11的方形窗对CG1进行平滑处理,得到CG3,其中方形窗的长11代表时间帧,方形窗的宽11代表频率通带;
④类似CG3,方形窗尺寸取23×23对CG1进行平滑得到CG4;
⑤组合CG1、CG2、CG3、CG4即得到MRCG特征,对于每一特定时间帧,MRCG特征是64×4维的向量。
针对上述各个特征之间的不同特性,Wang等利用Group Lasso的特征选择方法得到AMS+RASTAPLP+MFCC的最优组合特征[8],这个组合特征在多种测试条件下取得了稳定的语音增强性能,而且显著优于单个的特征。在低信噪比条件下,相对于Wang的组合特征,Chen等提出的MRCG特征[9]也表现出了很好的性能,逐渐取代AMS+RASTA-PLP+MFCC的组合特征成为语音增强常用的特征之一。
3AEF特征及Group Lasso算法
3.1 AEF特征
自编码器(auto-encoder,AE)是一种无监督学习算法,主要用于数据降维和特征提取。文献[10]中将AE成功地应用于图像像素数据降维,文献[11]中将AE用于语音频谱二进制编码进行特征提取。因为AE输出层与输入层特征数据相同,不需要人为计算目标标签,同时能直接把大量的语音数据放到AE输入层,让数据自己说话,AE自动从数据中学习语音声学特征,因此本文利用AE对带噪语音时域PCM(pulse code modulation)数据进行特征提取,获取编码(code)层数据,code层数据即为自编码特征,简写为AEF。
3.1.1 AE的结构
AE自编码器的架构如图1所示,主要由五部分组成:输入层(Input)、神经网络编码器(NN encoder)、编码(Code)、神经网络解码器(NN decoder)和输出层(Output)。
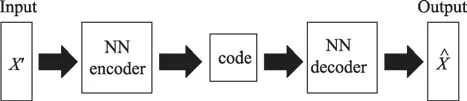
Fig.1 Architecture diagram ofAE图1 AE架构图
输入层用来输入高维的带噪语音时域PCM数据,NN encoder通过非线性变换提取输入层数据特征,得到code层数据,即AEF特征。同样,NN decoder通过非线性变换将code层数据重构得到输出层数据。AE输入层和输出层具有相同的节点数,在训练时AE输入层与输出层特征均为带噪语音时域PCM数据。AE训练的目标是最小化网络输出的重构语音PCM数据与网络输入带噪语音PCM数据之间的误差。
3.1.2 AE的训练
在对AE进行训练时,如果Encoder和Decoder两个网络内部的权重随机初始化,当初始化权重较大时,AE的训练常常陷入局部最优;当初始化的权重较小时,在前面的隐藏层的梯度就非常小,很难训练具有很多隐藏层的AE[12]。为了有效地训练AE,学习带噪语音PCM数据的一个深度生成模型,分为预训练(pre-training)和微调(fine-tuning)两个过程[10,13]。
在进行pre-training时,首先学习一个称为高斯-伯努利受限玻尔兹曼机(restricted Boltzmann machine,RBM)的无向图模型。该高斯-伯努利RBM是层间全连接,层内无连接的,由带独立高斯噪声的实值变量构成的显元和二值隐元组成,显元服从高斯分布,隐元服从二值分布也就是伯努利分布,即:

式中,vi和hj分别表示显元和隐元的取值,N(μ,σ2)为均值μ,方差σ2的高斯分布。1表示神经元激活状态;0表示神经元抑制状态。高斯-伯努利RBM能量函数(energy function)为:
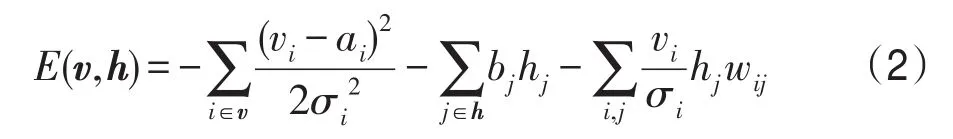
式中,v和h分别代表显元与隐元的状态,ai、bj表示其偏置,σi为显元的标准差,wij是vi、hj间的权重。此时,全概率分布为:

式中,Z被称为配分函数(partition function),表达式为:

根据表达式(3)可得到高斯-伯努利RBM关于v的分布p(v),即p(v,h)的边缘分布,定义RBM的似然函数为p(v),表达式为:
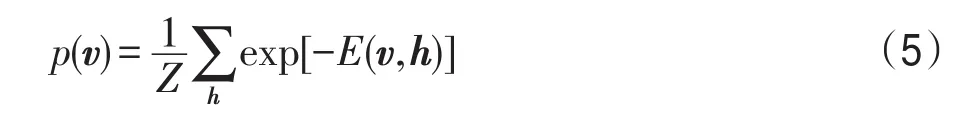
由于RBM中隐元之间的激活条件是独立的,则第j个隐元的激活函数为:

式中,σ(x)=sigmoid(x)=[1+exp(-x)]-1为罗杰斯特函数。同理,第i个显元的激活函数为:

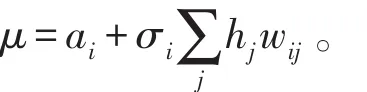
训练一个RBM的任务就是求出RBM的参数值,即θ={wij,ai,bj},通过最大化RBM在含有T样本的训练集上的对数似然函数,学习可以得到参数θ,即:

为了获得最优的参数θ*,通常使用随机梯度上升法通过计算lgp(vt|θ)对模型各个参数的偏导数,从而求出L(θ)的最大值。假设给定一个输入数据样本v0,则对于RBM模型的θ中的某一参数计算偏导数可得:
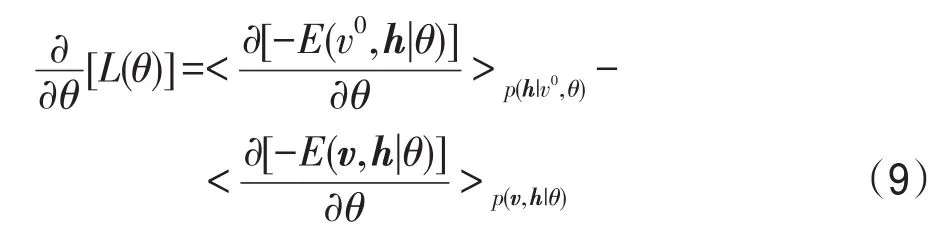
式中,<∙>p表示关于概率p的数学期望。第一项中p(h|v0,θ)是显元为v0时隐层的概率分布,容易计算得到,由式(3)可知第二项中p(v,h|θ)由于Z的存在而难以计算,通常利用对比散度算法(contrastive divergence,CD)[12]来获取近似值。最终可得RBM的各个参数增量为:

式中,ε表示学习率,根据上述算法求得RBM的每个参数增量后,更新各个参数,即可得到一个训练好的RBM。
充分训练完第1个高斯-伯努利RBM后,固定高斯-伯努利RBM的参数大小,根据其显元输入数据计算隐元状态,并将隐元状态作为第2个伯努利-伯努利RBM的显元输入数据。伯努利-伯努利RBM与高斯-伯努利RBM相比,区别是显元与隐元均为随机二值神经元,并且式(2)和式(7)将分别变为式(13)和式(14),两种类型的RBM有着相同的CD算法进行参数更新。

当所有RBM完成pre-training后组合形成深信度网络(deep belief net,DBN),如图2(a)所示,在分开的方框中展示了这两个RBM,RBM2的隐元二值状态就是AEF特征,经过进一步的fine-tuning可以实现提取特征时更小的失真。

Fig.2 Diagram of pre-training and fine-tuning aboutAE图2 AE预训练和微调示意图
在进行fine-tuning时,首先展开(unroll)DBN,利用它的权重矩阵来创建一个AE深度网络,如图2(b)所示。AE底层(lower layers)的encoder使用权重矩阵编码输入层数据得到AEF特征,AE上层(upper layers)的decoder使用转置权重矩阵解码AEF特征得到输出层数据,这个AE利用误差反向传播更新参数,使得输出数据尽可能等于输入数据。因此,AEF特征可以看作输入层数据的一种良好特征表示。
3.2 特征组合:Group Lasso算法
不同的声学特征描述了语音信号的不同性质,研究表明多个特征的恰当组合可能导致基于监督学习的语音增强具有更好的性能[8]。常用的特征组合方式主要有三种:(1)从已有的特征中直接排列组合选出最优的组合特征,但是该种方式的复杂度与特征的数量成指数函数关系,因此当特征数量较大时,很难实现最优特征的选取;(2)进行无监督的特征变换,例如主成分分析(principal components analysis,PCA)[14];(3)进行有监督的特征变换,例如线性判别分析(linear discriminant analysis,LDA)。但是无论是无监督的特征变换还是有监督的特征变换,变换之后很难确切知道具体哪些特征类型对语音增强效果起到了互补(complementary)作用。此处互补作用是指每种特征类型提供了互补信息来提高语音增强性能,并且比任一单独的特征效果更好。因为Group Lasso算法能快速地选取特征,同时确切地知道具体哪些特征类型对语音增强起到了重要的互补作用,所以正如文献[8],本文采用Group Lasso算法来选取互补特征。Group Lasso解决了下面的优化问题:
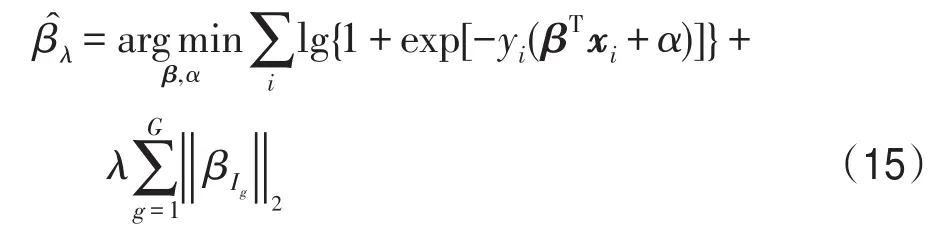
式中,最小化的第一项表示分类误差,第二项是正则项,xi是以语音帧为基本单元的输入特征向量;yi是对应输入xi的标签,取值为{-1,1};α表示截距;β是用来明确互补特征群组的响应参数;Ig表示第g个特征群组的索引;G表示输入特征类型的数量;‖∙‖2表示二范数;λ是正则化参数,控制群组的稀疏性。为了验证不同特征的互补性和冗余性进而得到综合特征,语音帧的多个特征被串联在一起形成一个长的特征向量,该长的特征向量作为Group Lasso算法逻辑回归的输入数据,训练标签yi通过理想二值掩蔽(ideal binary mask,IBM)计算得到,IBM计算如式(16)所示。当某特征的逻辑回归参数的模为0时,该特征与其他的特征之间互补性小,冗余性大,因此不被选取作为综合特征;当某特征的逻辑回归参数的模大于0时,该特征与其他的特征之间互补性大,冗余性小,因此被选取作为综合特征之一。

式中,t表示时间;f表示频率;RSN(t,f)表示在时刻t、频率f处的局部信噪比;Lc表示局部标准(local criterion,LC),通常取值比带噪信号混合信噪比小5 dB。
3.3 基于AEF特征的综合特征语音增强流程
利用综合特征进行语音增强主要分为训练和增强两个阶段,具体的流程如图3所示。

Fig.3 Framework of speech enhancement based on IF图3 基于综合特征的语音增强框图
在训练阶段,首先对纯净语音和噪声信号分别进行短时傅里叶变换(short-time Fourier transform,STFT)得到幅度谱,根据式(17)计算得到理想浮值掩蔽(ideal ratio mask,IRM),IRM作为DNN语音增强系统的目标标签。将带噪语音时域PCM数据训练集分帧、加窗后输入到AE,得到AEF特征,将AEF与听觉特征串联得到逻辑回归的输入特征向量。利用Group Lasso算法提取综合特征,随后将综合特征作为DNN语音增强系统的输入特征,对DNN通过梯度下降法进行有监督训练。

式中,|S(ω)|2和|N(ω)|2分别表示纯净语音和噪声的能量。
在增强阶段,将测试的带噪语音时域PCM数据分帧、加窗后输入到AE,提取得到AEF特征,同样利用Group Lasso算法提取得到综合特征,将从测试集提取得到的综合特征作为训练好的DNN语音增强系统的输入特征,经DNN网络的前馈传播,得到输出目标标签估计。带噪语音信号经Gammatone滤波器组后得滤波输出,在每个子带内带噪信号的能量利用估计的目标标签加权,将所有通带的加权响应求和来合成语音波形[15],得到最终增强语音。
4 方法性能评估
4.1 实验数据
从TIMIT标准语料库[16]中随机选取600条语句作为训练纯净语音,实验中噪声来自Noisex-92标准噪声库,Factory、F16、White和Pink四种噪声作为训练噪声,所有的纯净语音和噪声都利用Matlab的Resample函数采样到16 kHz,每类噪声时长大约为4 min,从噪声序列的前2 min内随机裁剪与纯净语音信号等长的噪声序列,分别以混合信噪比-5 dB,-2 dB,0 dB和2 dB将纯净语音与噪声混合得到训练集带噪信号。语音信号分帧时帧长为320点,帧移为160点,窗函数为汉明窗。AE中的encoder隐藏层数设为4层,即设encoder中含有4个RBM,第1个RBM为高斯-伯努利RBM,后面的RBM为伯努利-伯努利RBM,每个RBM隐元数量分别为700、400、300和200,RBM的预训练迭代次数为20次,预训练学习率为0.005,微调的学习率设为0.01。DNN语音增强系统隐藏层数设为4层,每层1 024个节点,学习率设为0.01。
从TIMIT标准语料库剩余语句中随机选取120条语句作为测试纯净语音,实验中噪声仍然选用Noisex-92标准库中的Factory、F16、White和Pink四种噪声。但是为了测试算法的泛化能力,从噪声序列的后2 min内随机裁剪与纯净语音信号等长的噪声序列,仍以-5 dB,-2 dB,0 dB和2 dB混合信噪比与纯净语音进行混合,将混合好的带噪信号作为网络的测试集。
4.2 对比方法及评价指标
本文主要研究声学特征对语音增强性能的影响,因此固定DNN作为学习模型,IRM作为训练目标,将不同的声学特征作为DNN语音增强系统的输入特征进行实验。对比实验中采用语音对数幅度谱作为DNN语音增强系统的输入特征的方法,简写为Logabs-DNN;Wang等[8]提出的组合互补特征(complementary features,CF)作为DNN语音增强系统的输入特征的方法,简写为CF-DNN;Chen等[9]提出的多分辨率特征MRCG作为DNN语音增强系统的输入特征的方法,简写为MRCG-DNN;以及本文提出的综合特征作为DNN语音增强系统的输入特征的方法,简写为IF-DNN;本文提出的综合特征是基于时域的自编码特征获取的,为了验证算法的有效性,本文同时将基于频域自编码特征的综合特征作为DNN语音增强系统的输入特征作为对比,简写为IF_F-DNN。为了验证算法的可行性,同时与谱减法(spectral subtraction,SS)、维纳滤波法(Wiener filtering,WF)、基于对数最小均方误差(LogMMSE)的统计模型法等传统方法[1],以及文献[7]中提出的深度降噪自动编码器(deep denoising AutoEncoder,DDAE)语音增强方法进行对比实验,其中DDAE模型有5个隐藏层,每个隐藏层500个神经元,预训练和微调的学习率都设为0.01。
关于评价指标,采用短时目标可懂度(short-time objective intelligibility,STOI)[17]、语音质量感知评估(perceptual evaluation of speech quality,PESQ)以及信噪比SNR来分别评估增强语音的可懂度、感知效果和语音质量[18-19]。其中,STOI主要用来测量语音可懂度,度量纯净语音与增强语音短时时间包络之间的相关性,这一参数指标与人主观对语音可懂度评分高度相关,其取值范围为0~1,取值越大,可懂度越高。PESQ是一种能够评价语音主观试听效果的客观计算方法,PESQ的取值范围为-0.5~4.5,得分越高说明语音感知效果更好。SNR是衡量增强算法对噪声抑制能力的指标,一般来说,SNR值越大,混在信号里的噪声越少,语音质量越高。
4.3 实验结果及分析
将带噪语音信号的AMS、RASTA-PLP、MFCC、GF和AEF特征串联组成一个长的向量,Group Lasso算法对该长向量逻辑回归处理后,每种特征类型对应的逻辑回归响应参数如图4所示,横坐标表示多个不同类型特征向量,纵坐标表示逻辑回归响应参数的值。由图可知每种特征的响应参数模值都大于0,因此不同特征之间互补性大,冗余性小,将最终的综合特征设定为AMS+RASTA-PLP+MFCC+GF+AEF,即为本文提出的IF综合特征。
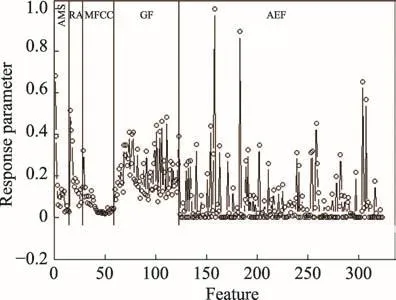
Fig.4 Logical regression response parameter values of Group Lasso图4 Group Lasso逻辑回归响应参数值
表1列举了在-2 dB混合信噪比Factory噪声环境下,9种声学特征分别作为DNN语音增强系统输入特征时,120条测试集语音增强后STOI、PESQ和SNR的平均取值,表格中加粗数字表示每列的最大取值。由此可知,在上述测试情况下,利用相同的学习模型和训练目标,与其他的声学特征相比,本文提出的IF特征在语音增强中3个评价指标都取得了更好的效果。
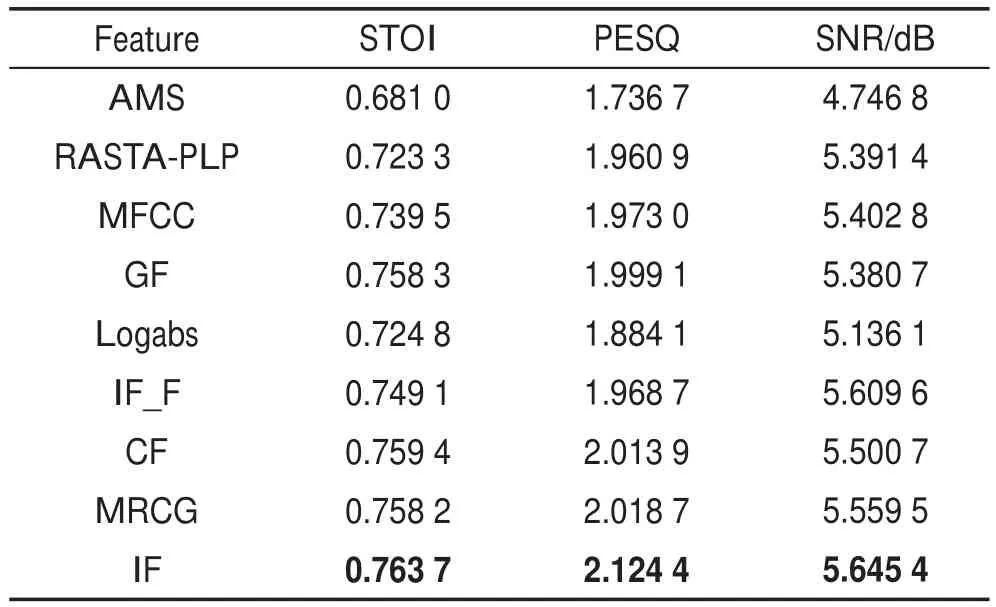
Table 1 Evaluation indexes scores of 9 acoustic features after enhancement of speech表1 9种声学特征语音增强后评价指标值
表2列举了在4种不同信噪比下,9种语音增强算法对于Factory噪声环境下,120条测试集语音增强后STOI、PESQ和SNR测量均值,其中表格中加粗数字表示每列的最大取值。由此可知,本文提出的IF-DNN方法,在不同的混合信噪比情况下,与谱减法、维纳滤波、LogMMSE等传统方法以及Logabs-DNN和基于DDAE的深度学习方法相比,3个评价指标性能都得到了较大提升。基于DDAE的方法,主要目的是提高语音的可懂度,虽然SNR的取值较小,但是增强语音的可懂度明显优于传统的方法。IF_F-DNN方法在高信噪比的情况下效果较好,但是在低信噪比情况下,尤其在-5 dB极低信噪比下,性能非常差,然而本文的IF-DNN方法在4种不同信噪比下评价指标值都要优于IF_F-DNN。CF组合特征、MRCG多分辨率特征和IF综合特征分别作为DNN语音增强系统输入特征时,在相同混合信噪比情况下,STOI和PESQ两个指标各自的得分相差不大;在4种不同混合信噪比下,CF-DNN、MRCG-DNN和IF-DNN的STOI平均得分分别为0.770 0、0.768 1和0.770 8,PESQ平均得分分别为2.073 1、2.080 8和2.092 0,就平均而言,IF特征表现得更好。对于SNR评价指标来说,本文提出的IF综合特征作为DNN语音增强系统输入特征的方法,在不同信噪比情况下,语音增强后SNR取值明显大于CF组合特征和MRCG多分辨率特征的方法,其中与CF组合特征相比,SNR平均提高了0.115 dB;与MRCG多分辨率特征相比,SNR平均提高了0.135 dB,因此利用IF综合特征作为DNN语音增强系统的输入特征时,噪声抑制效果更好,增强语音中残留噪声更少,语音质量更高。

Table 2 Evaluation indexes scores of 9 enhancement methods for different SNR表2 9种增强方法在不同信噪比下评价指标值
表3列举了在4种不同噪声类型下,8种语音增强算法对于-2 dB混合信噪比环境下带噪测试集语音增强后的SNR测量均值,单位为dB,表格中加粗数字仍然表示每列的最大取值。在不同的噪声类型情况下,与其他的7种方法相比,本文提出的IF综合特征作为DNN语音增强系统输入层特征时,增强语音的SNR指标最好,与CF组合特征相比,SNR平均提高了0.149 dB;与MRCG多分辨率特征相比,SNR平均提高了0.141 dB。同时也可以发现,上述提到的8种方法,对White噪声类型降噪效果最好,就IF-DNN语音增强系统来说,测试集带噪语音信号的混合信噪比为-2 dB,语音增强后信噪比变为8.990 5 dB,信噪比提高了10.990 5 dB,这主要是因为White是平稳高斯白噪声,分布律不随时间或者位置变化,模型经过训练集的训练,非常好地学习到了White的特性,因此在利用测试集测试时,效果比在其他非平稳噪声情况下更好。

Table 3 SNR scores of 8 enhancement methods for different noise表3 8种增强方法在不同噪声下信噪比取值 dB
5 结束语
本文提出了一种新的声学特征用于语音增强任务,利用AE提取带噪信号的AEF自编码特征,通过Group Lasso特征选取方法将特征重新组合得到综合特征,随后将综合特征作为DNN语音增强系统的输入进行语音增强,通过对不同混合信噪比和不同噪声类型进行的仿真实验表明,与组合特征、MRCG多分辨率特征相比,本文提出的综合特征用于语音增强后语音质量得到了较大提升,SNR指标取得了更好的性能。虽然本文主要研究的语音质量得到了提升,但是可懂度并没有得到明显提高,未来需要对现有的算法进一步改进,尽量做到增强语音的可懂度、感知效果和语音质量都得到较大提升。
