基于改进Q-learning的移动机器人路径规划应用研究
2019-08-06彭玲玲刘凯
文/彭玲玲 刘凯
关键字:移动机器人;路径规划;Q-learning算法;栅格法
引言
机器学习是研究如何使用机器来模拟人类学习活动的一门学科,包括监督学习、非监督学习和强化学习三类,近几年随着机器学习的发展,各类型移动机器人的应用也进入了高速发展期,它们可以完成一些人类无法完成或完成效率低耗时长的任务。在移动机器人的研究领域中,有效避障并路径规划[1]是一个很关键的问题,国内外在这个问题上有很多方法可以借鉴,主要包括:人工势场法、基于路径编码的遗传算法[2]、基于学习训练的神经网络和强化学习方法[3~4]、A*[6]等等。Watikins提出的Q-learning算法进行移动机器人的路径规划应用研究较为广泛,其特点是无需环境的先验知识,移动机器人与复杂的动态环境建立起一种交互关系,环境返给机器人一个当前的回报,机器人则根据回报评估所采取的动作,其收敛的条件是对每个可能的状态和动作都进行多次的尝试,并最终学到最优策略,即根据准则在未知环境中找到一条从起始点到目标点的最优或次优路径。
本文的研究内容是针对Q-learning的一些缺点进行改进,并将改进的算法运用于移动机器人的路径规划,相关研究大多停留在理论的层面,缺少对实际问题与背景的解决方法。首先,本文介绍强化学习的原理与Q-learning算法基本原理,然后对移动机器人路径规划问题进行抽象建模,并对该问题应用改进的算法,使其在短时间内以最优路径进行规划,验证算法的高效性,对结果进行相关分析。
1.强化学习
1.1 强化学习原理
经典的强化学习基于马尔科夫决策过程(Markov decisions process,MDP),强化学习是指从环境状态到动作映射的学习,使动作从环境中获得的奖励最大,从而使目标的值函数最大,其学习框架如图1。

图1 强化学习基本框架
1.2 Q-learning算法
移动机器人在路径规划的t时刻,可在有限的动作集合中,选取某个动作at,并将这个动作作用于环境中,环境接受该动作并进行状态st到st+1的转移,同时得到奖励值R。Q学习就是采用状态-动作对即Q(s,a)迭代方式来获得最优策略,所以其值函数Q更新的公式为:

2.基于改进的Q-learning算法的移动机器人路径规划
2.1 环境模型
本文将采用基于python的栅格地图进行环境空间的构建,定义一个20×20的栅格环境,在编写过程中,10表示可通行点,0表示障碍物,7表示起点,5表示终点,所以白色部分为机器人可行驶点,黑色部分为障碍物,黄色是起点,红色是终点如图2。

图2 对障碍物抽象化的栅格地图
2.2 改进Q-learning算法
由于Q-learning算法仅使移动机器人进行了一步的探索,其搜索范围有限,根据已获取的环境信息,移动机器人可以进行更深度的搜索。因此,本文将对原始Q-learning算法值函数的更新函数进行改进,加入深度学习因子为下两步的Q值,促使移动机器人更早的预见障碍或者终点,尽早的更新值函数Q。改进后的值函数更新规则为:

此处引入ω的作用是保证Q值的收敛,更新的学习规则利用深度学习因子ω对第一步获得的回报和第二步获得的回报进行权衡,规定ω>0.5是由于移动机器人的动作是周围环境决定的,从而可以保证第一步的回报权重较大,不会出现因第二步无障碍而忽略第一步障碍的情况。而当ω=1则为值函数的取值规则仅由第一步决定,即为原始的Q-learning算法更新。
2.3 动作空间的表示
本文的仿真实验将会把移动机器人抽象为一个质点,以移动机器人为中心,定义移动机器人可执行的四个动作空间为:A={上,下,左,右}。行动策略选择 ε-greedy策略,其含义是选择动作值最大的动作即贪婪动作的概率为而其他非贪婪动作的概率为等概率这种策略可以均衡利用与探索,采用最大的动作值为利用,其他非最优的动作值有平等概率继续探索。
2.4 奖惩函数
对移动机器人进行最优路径规划具有导向性的奖惩函数,是环境给移动机器人的立即反馈,也是对移动机器人上一步执行动作的好坏评价。机器人每移动一个栅格,将会得到-1的惩罚值,直到到达终点,机器人将得到最大的奖励值200,如果碰到障碍物,就会得到最大惩罚值-50,整个过程中,机器人也会选择奖励值高的动作,这样可以促使机器人更快到达终点,使最终得到的总奖励值最大。
3.实验结果与分析
本文将对有障碍物的同一环境下的移动机器人进行最优路=0.6,0.7,0.8,0.9。
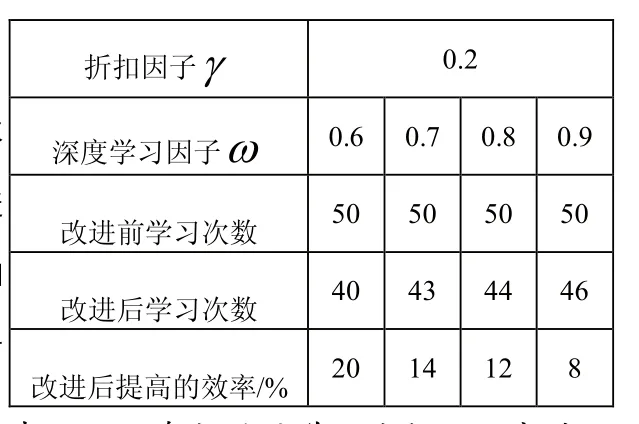
表1 不同参数时的学习次数及效率对比

图3 最终的学习结果
4.结束语
本文提出了一种基于栅格法建立的地图环境模型,对Q-learning算法进行改进,加入深度学习因子,使机器人在有不规则复杂障碍物的环境里能够更快更早地发现终点,及时更新Q值。通过原始Q-learning算法与改进后的算法对静态障碍物环境下的移动机器人进行最优路径规划的结果对比,可以证明改进后的算法收敛速度会加快。但本文只针对静态障碍物的环境进行复杂路径规划,对于更复杂的动态障碍物环境的移动机器人路径规划,还需要进一步的研究。
