基于强化协作博弈方法的双车道混合交通流特性
2019-08-06郭静秋方守恩曲小波王亦兵刘洋泽西
郭静秋, 方守恩, 曲小波, 王亦兵, 刘洋泽西
(1.同济大学 道路与交通工程教育部重点实验室,上海 201804; 2. 查尔姆斯理工大学 建筑与土木工程系,查尔姆斯 41296; 3.浙江大学 建筑工程学院,浙江 杭州 310058)
智能网联车(connected and automated vehicle, CAV)是近年来道路交通领域革命性的发展方向,有望从微观行驶行为层面改善传统交通流特性[1].自适应巡航控制(adaptive cruise control,ACC)和协同自适应巡航控制(cooperative adaptive cruise control,CACC)是CAV技术发展的重要阶段.然而,在未来相当长的时间里,CAV的市场渗透率将逐步增长,CAV将与普通车辆(regular vehicle, RV)长期共享有限的道路资源.CAV环境下的交通调控和资源整合优化是一项极具挑战的课题.Chen等人在研究自动驾驶车辆换道决策模型时,通过层次分析法和逼近最优解的排序思想,对普通的换道决策进行多属性赋值,从而实现车辆换道安全和效率的平衡约束[2].Talebpour等人在车联网环境下提出了一种基于博弈论的车辆换道决策模型[3].Meng等人在此基础上,结合结构平衡理论,构建了滚动时域控制的博弈换道决策模型[4].他们认为车辆换道决策问题可分解为换道价值和换道安全两个子问题,并在应用博弈论对车辆间影响、换道安全和驾驶效率综合考虑后给出换道决策.
然而,国内外学者在混合交通流特性研究方面还处于起步阶段.一方面,相比于RV,CAV具有更小的反应延迟时间,在行驶过程中与前车保持更小的车头时距,借此可以提升行驶速度;另一方面,CAV具备与周围同类型车辆相互通信的能力,这一能力可以使得CAV在换道操作过程中获得更多信息,有助于生成并执行更加灵活、智能的决策.因此,CAV有可能对提升道路通行能力发挥积极效能[2-8].此外,自动驾驶汽车可能会降低能源消耗和尾气排放,对低碳出行也有一定的推动作用[9].
目前,国内外对智能网联环境下的宏微观混合交通流特性以仿真研究为主.宏观方面主要依靠不同的车队车辆间距、车辆换道策略分析混合交通流宏观特性[6, 10].然而,由于宏观模型通常在该问题上进行了大量的假设,容易使得分析结果与实际条件产生较大的差异.采用均衡交通流模型的文献多数基于流密曲线.微观行为分析是研究此问题的主流途径[11-12].通过考虑混合交通流的离散性,分解CAV及RV不同的跟驰及换道行为来进行仿真演化,并反应混合交通流的整体宏观特性.元胞自动机(cellular automata model, CA)是一种经典的中(微)观交通研究基础模型,它能够通过制定简单的演化规则来有效地模拟并复现微观交通的非线性特征,从而被大量地作为基础模型并应用于各种特殊环境下的微观交通流研究[13-18].然而,由于CAV与RV是两种不同的智能体,传统的CA固定规则无法很好地描述CAV的智慧跟驰及换道行为,因此难以揭示出逼近真实的混合交通流特性.到目前为止,嵌入CAV智能性的混合交通流的仿真研究依然缺乏.
近年来,以强化学习为代表的人工智能领域迅速兴起,并在自然语言处理、图像识别等方面取得重大突破[19-20].强化学习是智能体以从环境状态中得到累积奖励值为目标而进行动作选择的映射学习[21-23].不同于元胞自动机规则化的行为选择,强化学习通过试错过程来进行最优行为策略映射.Q学习是一种流行的免模型强化学习方法,通过值迭代的方式逼近马尔科夫决策过程中的最优策略,可以很好地体现CAV驾驶行为的不确定性及智能性.尤其在CAV以车群行驶时,映射空间复杂,强化学习方法仍然可以在动作空间上进行无监督模式映射.
鉴于此,考虑一种结合元胞自动机及强化学习的多智能体混合交通流仿真模式.对于RV,在CA强规则行为方式上加入Gipps跟驰模型进行更细致的改进[24-26];对于CAV,一方面为突出其驾驶行为的不确定性,另一方面为呈现其具备的更高的智能水平,因此通过基于改进Q学习来训练不同周围环境下的CAV,以此训练形成CAV的非线性动态驾驶特性.在此基础上对混合交通流的宏观特性进行分析,并对该特性产生的影响进行总结.
1 研究背景
1.1 RV演化模式
传统的NaSch元胞自动机模型遵循线性跟驰思想,认为驾驶员对速度的反应不会反应在跟驰距离上[27].之后的学者们对NaSch进行改进,揭示了非线性跟驰模型更能合理地反应真实交通状况[28-30].Gipps提出的安全距离模型是一种常见的非线性跟驰模型,该模型认为车辆速度由当前理想速度、最大加速度和安全制动距离决定.考虑将Gipps模型引入CA,即无论前方车辆是否为CAV,dsafe,n表示第n辆普通车与前车在任何时刻都应保持的最小安全跟驰间距.极限情况如图1所示.此时,
dsafe,n=xn-1(t)-xn(t)-l=μ·vn(t)+
(1)
式中:xn-1(t)、xn(t)分别表示t时刻前方第n-1车辆与本车位置;l为车辆n的长度;μ为驾驶员反应时间;vn-1(t)、vn(t)分别表示前方n-1车辆与该车在t时刻的速度;b表示车辆n的最大减速度.设lcell表示单元元胞长度,则在CA模型中车辆n在t时刻的最小安全跟驰间距dsafe,n(t)应为

dsafe,n(t)=dsafe,n(t)lcell·lcell
(2)
RV在跟驰过程dsafe,n中根据调整下一时间步的车速来避免与前车发生追尾,即存在安全跟驰速度vsafe,n(t+1)如下:

vsafe,n(t+1)=min({vn(t)+2.5aμlcell[1-vn(t)vmax]·0.025+vn(t)vmax}/lcell,

(μb+(μb)2-b{2[xn-1-xn-l]-μvn(t)-2vn-1(t)2bn-1(t)+bn-1(t-1)})/lcell)
(3)
式中,a为车辆最大加速度,vmax为车辆最大行驶速度,bn-1(t)表示前车在t时刻的减速度值.

图1 安全跟驰间距示意
1.2 基本更新规则
普通车RV依照CA模型的通用规则框架按序进行t→t+1更新.每一规则均对应了特定的车辆操作.
(1)换道规则.换道行为是车辆在多车道环境下常见的驾驶操作.基于文献[31]中的换道规则,考虑当车辆n在式(4)~式(6)环境时会以一定的概率pchange进行换道操作,即
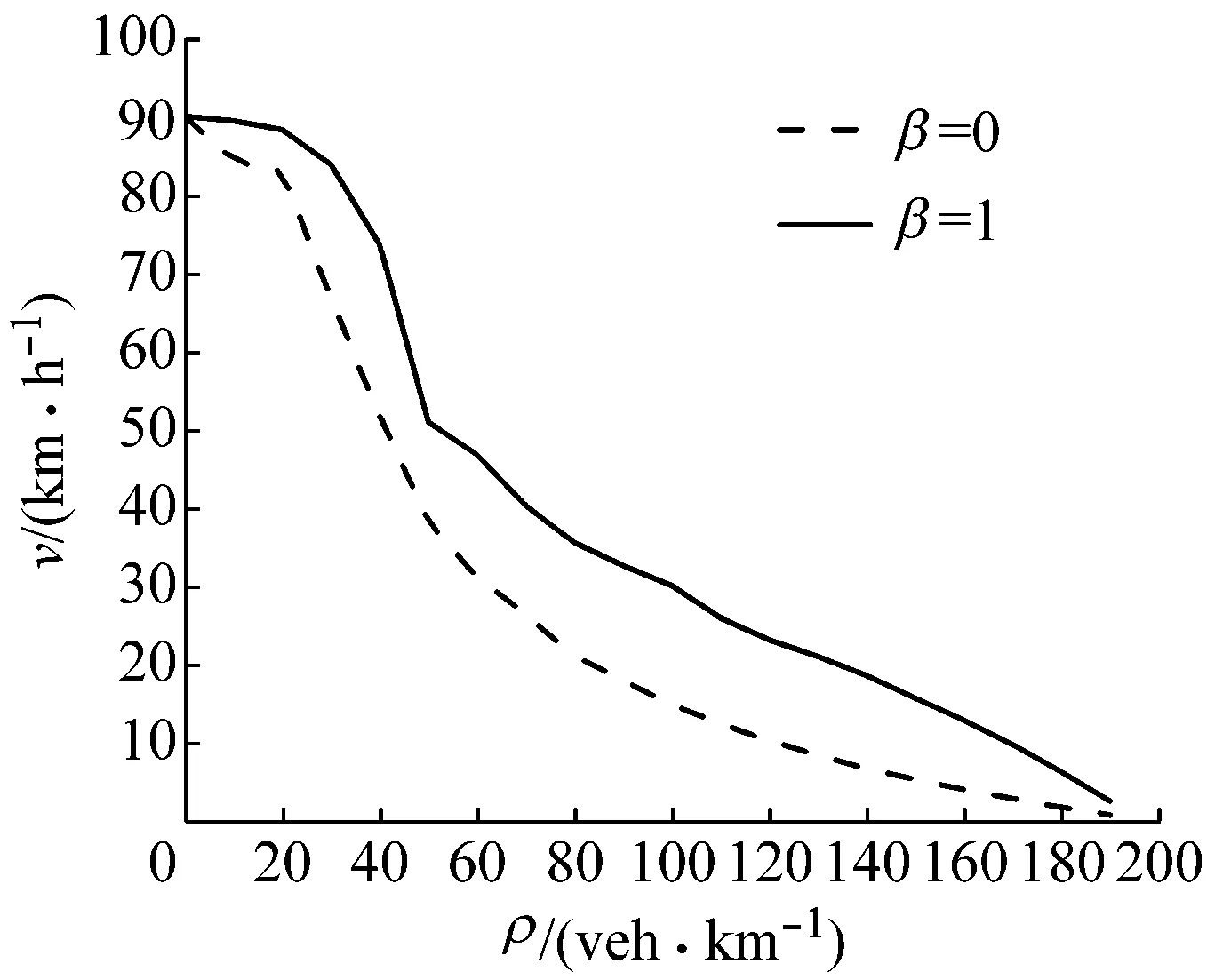
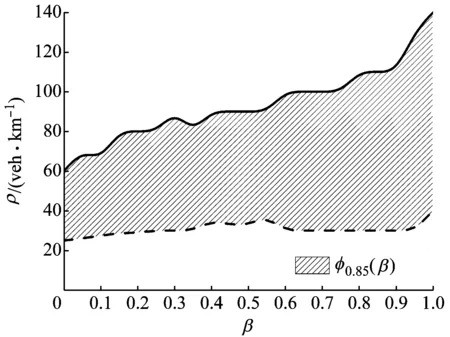
dn (4) dn,other>dn (5) dn+1,other>vn+2(t)+δ (6) 式中:dn,other,dn+1,other分别表示旁车道前方及后方距离;vn+2(t)为旁车道后方车t时刻车速.δ衡量车辆n的换道操作水平[32],δ越大,表现为越强制性换道,即在考虑换道时对目标车道后方车辆的间距及速度的要求越低. (2)加速规则.车辆在行驶过程中,当第n车辆在每个时间步开始时首先进行按常规加速度进行加速行驶估计.该步骤速度仅反映驾驶员试图保持高速行驶的意图,还需在接下来进行安全距离判断,因此不作为最终速度. vn→min(vmax,vn+a) (7) (3)确定性减速规则.传统NaSch模型设置方式不同,该规则主要保证了车辆间应保持的安全距离.当第n车辆与其前方车辆之间的距离小于该车行驶时所需要保持的安全距离dsafe,n、或该车行驶速度在经加速规则后超过安全速度vsafe,n时,为确保安全驾驶则需要进行确定性地减速. vn→min(vn,vsafe,n,dn,dsafe,n) (8) (4)随机慢行.考虑到驾驶员在行驶过程中可能存在的驾驶行为不稳定性,在演化规则中引入随机慢化概率prandom(0≤prandom≤1).行驶过程中的车辆按照随机慢化概率进行速度的慢化以更真实反映驾驶员的行驶不确定因素. vn→max(0,vn-1) (9) (5)位置更新.在速度演化更新规则的基础上,进行车辆位置的更新. xn→xn+vn (10) 如前所述,CAV的驾驶行为设计应遵循比RV更智慧的跟驰及换道策略.而目前大多数的CAV行为模型是在保证安全的条件下以自我利益最大化为目标、不考虑对周围车辆的影响的建模方式.随着CAV渗透率的提高,CAV与RV、CAV与CAV之间的动态交互将对车辆群体产生复杂的影响作用. 在强化学习领域,Q学习系统是一种典型的离散人工智能学习系统.在无需任何外界预先知识的情况下可以使学习主体(智能体)从零学起,直至形成一套足够优化的映射规则,因此可应用于CAV的行驶模式构建.Q学习系统由3个方面组成[33]:环境E、动作库A和奖励值r.智能体在状态S下选择特定动作A的过程称为策略π,即π:S→A.因此,在t时刻时智能体在状态st时首先选择动作策略a,随后外部环境给予奖励,智能体接收奖励并评估,以此决定下一动作并进入下一状态st+1.累积奖励值V为未来奖励的折现,回报折扣因子为γ(0≤γ≤1).智能体依靠累积奖励值的最大化,进而由反馈机制引导其在连续时间点中采取智慧高效的动作.设Qπ(s,a)表示在状态s时根据策略π而执行a动作的值函数估计,则 (11) π*=argmaxπVπ(s) (12) Qπ(s,a)=r(s,a)+γmaxa′Q(δ(s,a),a′)= (13) 式中:j为相对于时刻t的未来时间点;δ(s,a)为状态转换函数.Qπ(s,a)的更新满足Bellman方程如下: Qπ(st,at)=∑st+1[p(st,at,st+1)·r(st,at,st+1)]+γ∑st+1,at+1[p(st,at,st+1)·Qπ(st+1,at+1)] (14) 式中:p(st,at,st+1)为状态st时,智能体采取动作at转移到st+1状态的概率;r(st,at,st+1)表示动作at和状态st转移到st+1的回报值.Q学习对应的最优动作估计Qπ*(s,a)和最优策略π*(s)为 Qπ*(s,a)=maxπQπ(s,a) (15) π*(s)=argmaxπ[r(s,a)+γV*(δ(s,a))]= argmaxaQ(s,a) (16) 综上所述,可以总结基于Q学习的CAV训练过程:首先,确定车辆的状态定义和动作选择集合,构建由不同状态和动作选择组合的二维Q表;其次,将CAV放入仿真环境运行,并混以不同比例的普通车辆,结合式(11)~式(16)迭代更新Q表,以形成车辆完整的状态-动作映射;最后,在正式仿真过程中,收集交通微观数据,统计宏观交通特性. 目前在CAV的主流仿真研究中,均假设了车辆具备一定的周边交通感知能力及协同能力[34-35].因此,为体现CAV应有的智能水平,在跟驰和换道过程中除考虑自身行驶状态,还需要考虑本车所在车道的前方最近车辆n-1、相邻车道前后方最近车辆n-2、n+2的车辆行驶状态,并认为以上4车的行驶状态决定了本CAV的行驶策略.图2综合考虑以上多变量影响因素在车辆行驶过程中表现出的高度动态性,为了更好地模拟真实状态,车辆n通常需要考虑连续若干时间步的状态,并结合自身的最优行驶利益来决定下一时间步的行驶策略. 图2 CAV状态 Sn(t)=[vn+2;pn+2;dn+1,other;vn;dn;dn,other;vn-1;pn-1;vn-2;pn-2] (17) 其中,pi表示i号位置对应的车辆类型(i∈{n-1,n-2,n+2},pi∈{CAV,RV,None}).若i号位置无车辆,则pi=None,vi=0.可以看出,在双车道环境下,当第n辆CAV车辆在跟驰CAV或RV时,由于pn-1取值不同,因此所对应状态表征也不同,据此可以做出不同的动作选择. 一般情况下,车辆的动作空间Aall有6个不同动作,分别为:本车道减速“F-”、本车道保持车速“F=”、本车道加速“F+”、换车道减速“C-”、换车道保持车速“C=”、换车道加速“C+”.为确保车辆间无碰撞无追尾等冲突发生,需要对CAV添加一定的先验知识,以避免缺乏合理性的模拟过程,从而显著提高学习效率.如当dn=0时车辆n不可能采取本车道加速的“F+”动作.设车辆n在状态S时可行的非空动作空间为Afeasible,n(S),且Afeasible,n(S)∈Aall.为了充分体现Q强化学习方法的在线学习性,采用ε-贪婪策略选取即时动作,即车辆n处以ε的概率执行Q表中状态S的动作价值最大对应的动作,以(1-ε)概率随机执行动作,即 (18) 其中,rand()表示[0,1]中一个随机数,F(·)表示随机选择函数.奖励值的设置以行驶目标为准则.基于所有车辆均以获得最大平均速度为行驶目标的假设,因此Q学习中的奖励应引导CAV尝试提速操作.奖励值计算如下: r=vn(S′)-vn(S) (19) 式中:vn(S)表示车辆n在状态S时的车速,且S′:S×π(S). CAV与RV在仿真系统中的训练过程如图3所示.由于混合交通流中CAV与RV共存,两种智能体分别由Q学习和CA构造,因此考虑对Q学习进行改造,取消Q学习中的周期,并将Q学习中的迭代步与CA的时间步训练演化策略相融合.同时,系统中所有CAV共享Q表,以显著加速强化学习速度. 仿真平台由python语言编写,以道路长度L=3 km的双车道作为仿真模拟环境.为更细致地反应车辆在车道上的行驶性质,单元元胞长度lcell设置为1 m,车辆车身长度l为5 m,即单车占用5个连续元胞.车辆最大行驶速度vmax为25元胞·s-1(90 km·h-1),最大加速度a与最大减速度b分别设为5元胞·s-2、10元胞·s-2.RV的换道操作水平δ={-2,-1,0,1,2},随机慢行概率Prandom=0.05.为简化分析维度、更大程度地揭示两种车型不同的微观行驶特性、提高仿真效率,假设换道概率Pchange=1,即当车辆满足换道条件时便采取换道操作.设N表示车辆总数,β为CAV车辆渗透率,T为有效仿真时长,则车流平均速度为单位时期内所有车辆速度总和的平均值,车流平均密度为每公里每车道平均的车辆数,流量为单位时间内通过某一道路横截面的车辆数. 图3 仿真模拟过程示意图 (20) (21) (22) (23) 式中:i为具体车道编号,即i={1,2}. 整个仿真过程分为训练过程及正式模拟过程.在训练过程,分别在不同密度不同CAV渗透率下运行106时间步用于训练并形成CAV的运行模式;在正式模拟中,每次演化时间步,只保留最后5 000步作为有效稳定结果.每种仿真环境均重复运行20次,将每次仿真得到的车道平均密度、车辆平均速度及平均流量再次平均化并以此最终仿真结果,用以降低瞬时效应. 图4反应了不同密度及CAV车辆渗透率对混合交通流特征的影响程度.可以清晰看出车辆密度和CAV渗透率对混合交通流的通行能力及平均速度的影响效用.从图4a可以看出,对于一定的β,密度与车辆速度呈现反相关关系.密度越大,车辆速度越低,并且当30 veh·km-1≤ρ≤40 veh·km-1时影响效果最显著.另一方面,β对速度的影响表现出了明显的非线性,即Q学习下CAV与CA强规则的RV具有不同的演化方式.当ρ在0~20 veh·km-1区间(车流稀疏)时,β对速度的影响程度不大.当ρ在20~60 veh·km-1区间(车流趋于拥堵),且β在0~0.65区间内时β对速度的影响程度较弱,此时车流仍具有较大速度;当β在0.65~1.00时β对速度的影响程度加强,表现为在同一密度下,β越大,车流速度越大;当ρ在60~160 veh·km-1区间(车流处于轻微拥堵至较重拥堵状态),β的提高显著减小了密度对车速的影响程度;当ρ大于160 veh·km-1时,即交通处于严重拥堵,β对车流速度的影响程度降低,但仍然满足正相关关系. a β-ρ对速度的影响 b β-ρ对速度的影响 由式(23)可知,图4b与图4a的流量与速度在β与ρ的变化上具有相似特征,且由图5还可以看出,当β=0时,道路最大通行能力Qmax=2 073 veh·h-1;当β=1时,Qmax=3 013 veh·h-1,即100%CAV的交通条件下通行能力提升了45.34%.此外,定义Φη(β)为在β一定时,密度ρ对应的车辆流量Qρ大于η·Qmax的密度区间,即 (24) η=0.85时不同的β所对应的Φη(β)如图6所示.可以看出,β有效地延长了道路高通行能力的适应密度. 由以上混合交通流特征分析可以看出,伴随CAV渗透率的提高,交通流状态有明显改善.分析原因,主要是: (1)CAV允许更小的车头时距,CAV可以以更紧密的车队集合行驶; (2)经过充分优化训练的CAV智能体对每个可选动作都事先加以评估,并选择最优驾驶行为,以期在动态交通环境中达到更大速度,从而提升整体交通流的通行能力和平均速度. a 速度-密度关系 b 流量-密度关系 图6 Φ0.85(β)范围曲线 研究表明,频繁的换道是引发交通拥堵及事故的主要成因之一[36].换道操作改变了车辆横向稳定性,会对交通流产生重要影响.定义混合流换道频率fLC为单位时间单位车辆的换道次数,由普通车辆及CAV车辆的换道频率计算得 (25) 式中:Np,LC为有效仿真过程中p类型车辆的换道总次数;Np为p类型车辆数.仿真结果如图7所示. 另一方面,随着ρ的增加,fLC、fCAV,LC、fRV,LC在不同β下均呈现类基本图走势.ρ越大,保持的换道频率水平越低.具体而言,当ρ低于转折点对应密度时,车辆间仍具有相对充足的空间进行自由换道操作,此时fLC、fCAV,LC、fRV,LC与ρ呈现正相关关联性;当高于转折点对应密度后,受道路空间限制的趋势加强,fLC、fCAV,LC、fRV,LC表现为与ρ呈反相关.此外,相比于CAV,由于RV的换道条件对道路空间要求更高,因此fRV,LC表现出对ρ变化更加敏感. 图7 不同渗透率、不同密度的换道频率 通过探索一种双车道环境下的强化学习方法与元胞自动机相结合的演化机制,提出了基于改进的Q学习方法,精准模拟普通车和智能网联车辆的微观行驶策略,以此构建了一种针对双车道环境下混合交通流的高效仿真方法.此方法以个体优化为目标,探讨CAV微观驾驶行为所产生的集聚效应是否对交通流有优化作用,得到结论如下: (1)相比于高度规则化的元胞自动机,强化学习形成的行驶策略具有更高的灵活性及相邻时空环境适应能力,更符合CAV的智慧行为特征; (2)不同车流密度条件下,道路通行能力及车流平均速度可随着CAV渗透率的提高而增加,且维持高通行能力的密度范围也同步扩大,一定程度上延后了车流拥堵密度; (3)不同车流密度条件下,随着CAV渗透率的提高,混合车流换道频率降低,车流横向稳定性增强. 由于采用的对称式双车道的道路仿真环境相对简单,对整体交通情况的刻画还不够贴近,因此可能与现实情况还存在一定差距.将来的研究工作需要进一步改进道路模型,也需要对更复杂的道路交通环境下的混合交通流特性进行深入研究.2 CAV行为建模
2.1 基于Q学习的训练方法
2.2 车辆状态定义

2.3 状态动作选择
2.4 混合训练
3 仿真与数值分析
3.1 仿真设计

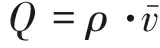
3.2 不同CAV渗透率下的交通流特征分析



3.3 换道频率分析


4 结论
