基于变异字典的中国工尺谱即兴演奏研究
2019-07-30李荣锋李学明
李荣锋,李学明,柳 杨
(北京邮电大学 数字媒体与设计艺术学院,北京 100876)
1 研究背景
工尺谱是应用范围最广的中国传统乐谱.工尺谱的鼎盛年代在清代,也是中国戏曲盛行的年代.而词唱曲唱大量出现于当时盛行的昆剧中,因此词曲的工尺谱便作为昆剧中一个重要部分被大量记载,现存有许多珍贵资料.据《中国音乐书谱志》[1]记载,清代至民国年间共约有1071种工尺谱曲本,现存的乐谱是中国传统乐谱中保存最多的一种.工尺谱在解读过程中最大的难题在于即兴演奏.有关即兴演奏,大部分研究者秉持的是一种虽不精确但又不失逻辑的一种观点.其中,民族音乐研究学者奈特尔[2]认为,尽管影响同一首曲子每一次演奏的即兴因素有很多,随着时间和地点的不同还会有微妙的变化,然而这并不代表即兴等同于没有逻辑或者完全由演奏者根据个性随机决定的演奏,而是依赖一系列约定俗成的、隐性的规则.关于工尺谱的即兴演奏中的节奏问题,杨荫浏先生在《工尺谱浅说》[3]中明确地回答: “1. 如何决定一板中每个音的长短?有没有简捷的口诀可以很快学会?回答是: 没有.只能结合民间音乐实际学习工尺谱才能学会.2. 每个音的长短可否由应用者自由决定?回答是: 不能.因为在同一曲调中,在这些细微节奏的处理上,在民间实际流行的唱法中,一般来说是比较固定的.而且在各个流派之间,大体上是一致的.”由此可见,中外学者有关传统音乐中的即兴部分的观点是一致的.具体到工尺谱节奏翻译问题上,关于同一拍内音符时值的分配,虽然工尺谱没有公式化的规则,但是演奏者不能完全随机决定,而需要通过一定的演奏经验来进行合理的即兴演奏.这种经验通常需要通过长时间的口传心授,并结合大量的演唱经验才能获得,这对本来就相对小众的中国传统音乐来说,更加让学习者望而却步.通过将工尺谱翻译成在节奏上更加精确的简谱或者五线谱,结果并不唯一但却可以做到合理,这将会给工尺谱的学习者带来极大的便利.
关于工尺谱符号的解读,国内的音乐家已经做了多年的研究.早在20世纪50~60年代,老一辈音乐家杨荫浏[3],林石诚[4]就已经对工尺谱的符号规则作了细致的总结.吴晓萍[5]更在前辈们的基础上,全面介绍了工尺谱在不同历史时期以及不同乐种中的变体.许莉莉[6]则开始着手讨论将工尺谱符号翻译为五线谱的可行性,并就翻译过程中相对确定的部分进行了公式总结,而对于不确定的部分(音符的时值分配)则只提到“需要一些唱曲经验”.总之,尽管中国音乐家在工尺谱的理论和规则上面做了大量工作,但是对于工尺谱不确定的节奏,只能定性地判断为: 需要根据演唱经验进行决定,但有经验的音乐家在关键细节处理上大致相同,并不是随心所欲.
尽管经过几代音乐家在曲谱出版方面的努力,我们已经可以看到许多经典昆曲、京剧剧目的简谱以及五线谱版本,例如《振飞曲谱》[7]、《寸心书屋曲谱》[8]、《中国昆曲精选剧目曲谱大成》[9]已经出版.这些谱本均是通过人工翻译的方式,由工尺谱的嫡传音乐家经过多年的学习,花费大量心血谱写而成.然而类似的翻译谱本数量依然太少,现存的可以考证的中国传统曲谱中,绝大多数仍然只有工尺谱版本未被翻译.能正确解读工尺谱的专家已经越来越少,工尺谱作为一种非物质文化遗产,其传承正面临严峻考验.
目前,利用信息技术处理工尺谱的研究和探索相对较少,并且主要集中在工尺谱的纸质乐谱的数字化上面.例如陈荣鑫[10]为福建南音工尺谱设计了排版软件,可以使用电脑进行工尺谱的输入以及排版.陈根方对工尺谱纸质乐谱的数字化,即光学乐谱识别(Optical Music Recognition, OMR)方面做了大量研究,包括工尺谱的音乐信息提取以及有效信息提取的工作[11-13].其中文献[11-12]分别利用经典的遗传算法、BP(Back Propagation)网络和K近邻(K-Nearest Neighbors, KNN)法等模式识别技术对清代《九宫大成南北词宫谱》[14]和《纳书楹曲谱》[15]的部分工尺谱进行音乐信息识别,但正确识别率较低;而文献[13]则利用层次聚类分析方法对工尺谱的有效信息进行提取,有效信息的提取正确率达到了90%以上.工尺谱的OMR研究工作为纸质工尺谱的数字化提供了重要技术支持,也是利用数据和统计模型进行工尺谱自动翻译的前提.
在乐谱自动翻译问题上,由于节奏时值分配不明确属于中国传统音乐的独有问题,因此目前还没有相应的国外研究.由于音乐学与计算机科学之间的知识鸿沟,国内在这个问题上的研究者也极少.周昌乐[16]在古琴的演奏法与记谱方面进行数字化研究,并探讨了古琴的减字谱的自动翻译问题.他主要探讨的是古琴打谱过程中指法编配的合理性,并未使用大量数据进行实证.作者在工尺谱自动翻译问题上做过一些前期研究.文献[17]探讨了影响音符时值分配的因素,并得出其歌词的声调具有决定性作用的结论;文献[18-19]分别尝试使用序列标注模型(隐马尔可夫模型、条件随机场模型)以及贝叶斯分类器进行工尺谱自动翻译;文献[20]探讨了序列模型中特征的音乐语义,并提出了一种基于时间序列的自动翻译方法;文献[21-22]将用于翻译工尺谱的序列模型用于使用古诗词进行自动作曲.这些研究的数据来自钱仁康先生编写的《请君试唱前朝曲》[23].该著作翻译了《碎金词谱》[24]中的工尺谱形式的唐诗宋词,并编写成了简谱(等价于五线谱)的形式.尽管作者在这66首曲子的数据库上取得了90%以上的正确率,然而这些研究依然停留在较浅层阶段,具体存在如下问题:
(1) 实验数据过少,很难证明在一般情况下该模型的通用性;
(2) 这些研究尚停留在就纯粹的数据进行分析的阶段,并没有对其中的音乐内涵进行深入探讨;
(3) 训练和评测也是基于简单的符号比对,演唱者在同样的一段工尺谱符号的一些即兴发挥,均会造成训练模型和评测结果的崩溃.
综上所述,关于工尺谱的自动翻译研究,虽然已经有一些理论支持以及乐谱数字化的前期研究,但涉及音符时值分配这个关键问题的研究工作则刚刚开始,尚待进一步展开.本文主要针对工尺谱对同一段符号的即兴演奏问题进行展开.
2 中国工尺谱翻译的基本框架
本文以昆曲、京剧以及古乐器演奏中所使用的工尺谱作为研究对象,研究工尺谱符号,包括音高、节拍、歌词及其读音的组合所产生的音乐学及语言学的可量化的语义,借鉴自然语言处理中运用成熟的基于深度神经网络的序列转换模型,建立工尺谱自动翻译系统.同时,利用歌词语言学上的格律与音符在音乐学上的格律两者之间的共性与差异性,建立两者的低维空间映射,以应对自动翻译时训练数据不足的问题.针对演唱者的即兴演唱问题,利用数据驱动方法,自动生成基于每一拍实际演唱音符的变异字典,所得结果为评测模型的正确性做进一步的准备工作.具体内容如下:
(1) 如何对工尺谱音符提取具有音乐学即语言学语义的特征,以建立高正确率的自动翻译模型?
在工尺谱符号中,能够与节奏型对应的特征有很多,包括与音高相关的特征(如音高、音程、调性),与歌词相关的特征(读音、声调),如何选择与节奏型最相关的特征是本问题的关键.具体翻译过程中,由于需要考虑上下文关系,因此除了特征选择之外,还需要对上下文依赖关系进行建模,例如可以考虑一阶模型(每一板只受相邻的一板影响)或者高阶模型(每一板受相邻的若干板影响),可以考虑因果系统(每一板只受前面的板影响)或者非因果系统(每一板受前后多板影响).
(2) 如何应对工尺谱翻译的训练数据不足引起的模型训练问题?
具体到每一板的音符组合中可能有1~6个音符,每个音符的音高可能值从合到乙10个音符以及它们的高八度低八度版本共30个音名(乐器曲则能达到50个),因此最多有可能有306种音符组合模式.记录音乐实际演奏过程(即采风)本身是一件代价昂贵的事情,训练过程中,所收集的工尺谱实际演唱数据不可能涵盖所有的音符组合,而自然语言处理中的大数据深度学习模型所需要的数据量在本研究中并不具备.因此这就要求抓住音符组合在音乐学和语言学语义上的根本差别,通过有限的数据来对训练数据中没有出现的音符组合进行判定.合理利用音乐学和语言学上已有的一些定性结论,建立工尺谱特征符号的一个既定量又具有音乐学、语言学解释性的度量空间,并将特征空间映射到这个度量空间,将可以有效降低维度,以根据度量涵盖所有可能的音符组合情况.
(3) 如何进行变异性建模,以模拟演唱者实际演唱中的即兴处理?
即兴处理是中国传统音乐区别于西方古典音乐的典型特点.工尺谱自动翻译模型必须能够模拟演唱者在实际演唱中对个别音符的长短进行灵活处理,甚至增加,舍去个别音符的情况.具体来讲,就是要对满足一定条件的音符组合统计其在音乐学上可能即兴处理的情况,通过建立即兴处理当中的变异字典进行有效的建模.
本文的研究框架如图1所示.
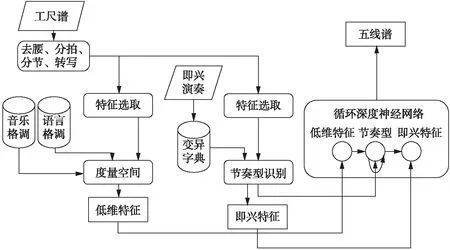
图1 总体研究的技术流程图Fig.1 Technical flow chart of overall research
本文总体研究的技术路线如下: 首先,将工尺谱按照去腰、分拍、分节和转写的步骤,以板为单位转换成序列数据;其次,选取合适的特征,根据音乐学以及语言学的格调理论,建立度量空间,并将原音符特征映射为低维特征;同时,选取合适的特征,根据即兴演奏的结果建立变异字典,在进行节奏型识别的同时获取即兴特征;最后,用低维特征、节奏型以及即兴特征建立循环深度神经网络,完成工尺谱自动翻译,输出五线谱.
3 基于即兴字典的工尺谱即兴演奏
根据图1的研究框架,工尺谱即兴演奏系统的各个流程如下:
(1) 基于度量空间的音乐、语言格调特征学习

基于度量空间的音乐、语言格调特征学习算法的示意图如图2所示.
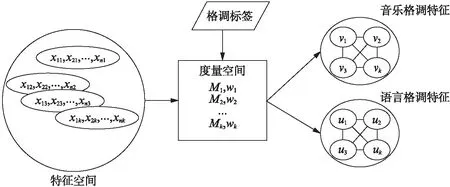
图2 基于度量空间的音乐、语言格调特征学习算法的示意图Fig.2 Schematic map of music and language style feature learning algorithms based on metric space
(2) 即兴演奏字典的构建
接下来我们对即兴演奏中的变异构建变异字典.
如果演奏者某一板所演奏的音符发生了音符的增加及减少,或者头字尾字错板(音符不符合实板和虚板的要求),则称之为变异.在本文中,我们只讨论变异所带来的即兴演奏.我们总结了钱仁康先生的《请君试唱前朝曲》中的变异情况,共有8种增删音符(两谱字3种,三谱字2种,四谱字3种),及头音错板,尾音错板2种情况,共10种变异情况.因此即兴演奏特征可以表示为1维标签形式f∈{0,1,2,…,9}.
(3) 基于循环深度神经网络的工尺谱自动翻译系统
该系统与自然语言处理中的序列匹配模型相似,主要是用于匹配(1),(2)的输出结果: 低维的可度量的语言格调特征v以及即兴特征f.其中,在进入循环深度网络之前,我们额外使用2个深度网络D={d1,d2,…,dL}和C={c1,c2,…,cM},将低维特征以及即兴特征转化为节奏型特征{S1,S2,…,SN}.
工尺谱自动翻译的循环深度神经网络模型如图3(第318页)所示.
实验中,输入的低维特征为(1)中所述的2维特征,即兴特征为(2)中的一维标签.网络D与C均选择了2层网络,并使用了tensorflow的tf.nn.rnn_cell模块进行训练.
在实验中,我们的工尺谱翻译数据来自钱仁康先生所著的《请君试唱前朝曲》[11].该书翻译了《碎金词谱》[12]中的96首曲谱,大部分为唐宋以来的著名古词.我们选择了其中的60首具备板眼符号的曲目作为时间序列模型的训练与测试数据.目前该数据使用人工录入的方式,并存储在MySQL数据库.该数据库包含了969个乐句,6347个拍子.我们将整个数据集随机分成两组(在同一乐句的拍子分在同一组),分别用于训练与测试.其中训练集的拍子数为3174拍,测试集的拍子数为3173拍,不同音符数的拍子数量统计见表1(第318页).
我们以晏殊的浣溪沙(图4,第318页)为例,经过深度网络处理后生成的五线谱如图5(第318页)所示.
4 总结与展望
尽管本文的工尺谱即兴演奏模型的音乐学内涵仍待进一步挖掘,但至少在人工智能的新时代,使用机器学习的方式来处理乐谱学问题是一个完全值得尝试的方向,具体体现在: 该模型可以将原本正在流逝的通过口传心授代代相传的宝贵经验得以保存,为研究以工尺谱为基础的中国传统音乐,例如昆曲、京剧以及古琴、南音等传统器乐曲的理论研究提供有力支持.通过本文的模型,可以在短时间内将大量的工尺谱翻译为五线谱.学生只需接受过义务教育中基本的五线谱基础即可入门,大大降低了学习门槛.因此,该研究将为中国传统音乐进入基础音乐教育提供了可能性,使中国传统音乐教学不再仅存于专业音乐院校中.

图3 工尺谱自动翻译的循环深度神经网络模型Fig.3 Recurrence depth neural network model for automatic translation of Gongchepu

图4 晏殊《浣溪沙》的工尺谱Fig.4 The Gongchepu of Yan Shu’s “Huanxi Sha”
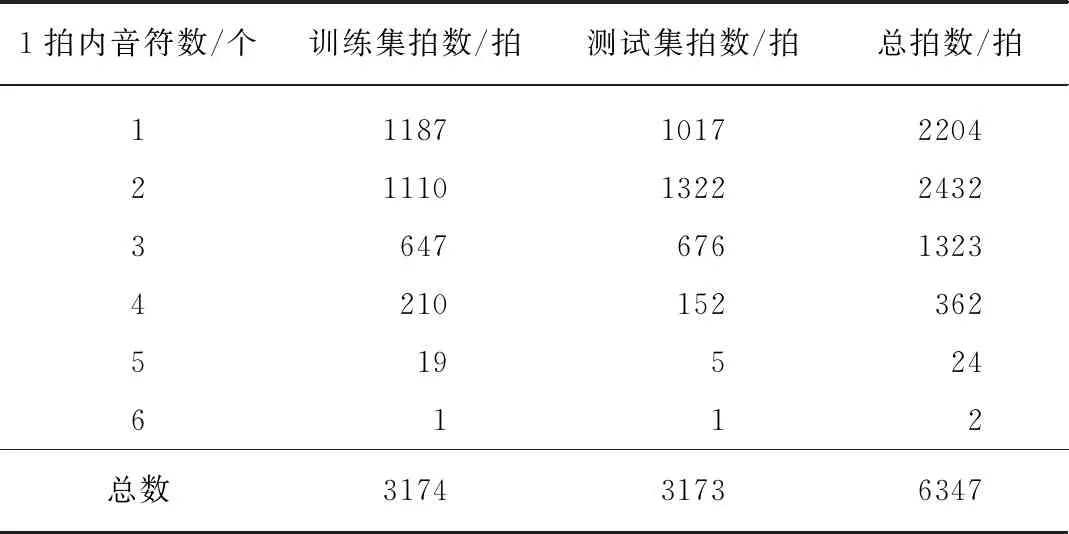
表1 《请君试唱前朝曲》的工尺谱数据集

图5 晏殊《浣溪沙》的五线谱翻译Fig.5 Staff of Yan Shu’s “Huanxi Sha”
