智能问答系统设计与实现
2019-07-30杜阳阳常家鑫张志豪张宸楠李驰
杜阳阳,常家鑫,张志豪,张宸楠,李驰
(中国矿业大学计算机科学与技术学院,徐州221000)
0 引言
随着互联网技术的不断发展和成熟,以互联网为媒介的信息数量急速增长。与此同时,人们越来越依靠互联网获取相关信息,如何准确高效地从大量信息中获取所需知识成为亟待解决的问题。对于编程工作者来说,在实际编程过程中可能会遇到一些遗忘的知识点。传统的做法可能是询问同事、查看相关文档或者直接利用搜索引擎搜索答案。但是这些方式往往存在着获取知识耗时较长,所得知识不精确的问题。研究面向编程知识获取领域的智能问答系统,能够为编程人员的知识获取提供极大便利,提高工作效率和工作质量。
对于用户提出的问题,系统首先进行语义的分析和理解,之后在知识库中进行查询、匹配,最终将答案返回给用户。不难发现,系统中知识库质量的高低决定了系统返回答案的优劣程度,高质量知识库的构建是智能问答系统设计中需要面临的挑战之一。
当前问答系统的知识库大多存在问答对质量不高,问答对数目偏少的问题。经过对智能问答系统中问答对生成方法的研究,系统分别基于规则、NLP、机器学习,三种生成问答对方法进行智能问答系统构建,并对其构建的知识库进行分析比较,从中选择问答对质量最高的知识库作为系统最终的知识库。进而运用信息检索技术,实现高质量智能问答。针对搜索常见编程知识的需求,系统通过爬取www.runoob.com 编程知识网站内容构建知识库,实现“QA 对”的自动生成。
1 智能问答系统设计方案
本系统由前端、后端、知识库三大功能模块构成。前端既可面向普通用户提供查询服务,也可为管理员提供操作数据库的接口。后端实现数据获取、对接收数据进行分析和对前端请求的反馈并能对知识库进行人工的完善。知识库则根据所爬取网站www.runoob.com 的内容实现“QA 对”的自动生成。系统的构建流程如图1 所示。
设计目标如下:
前端设计:实现与用户的交互功能,并提供友好的交互界面。在实现全部功能的前提下,使得界面更加美观,为用户提供更加优质的信息服务。
后端设计:实现从网页中提取高质量问答对的功能。其中问题由网页中的标题和关键词构成,答案由标题和关键词附近的文本和链接组成。并能实现QA对增加、删除、修改、查询等功能。
知识库构建:由爬取内容自动生成的“QA 对”构建知识库。尽可能多地提取高质量问答对的同时保证知识库中不存在相同的问题。

图1 系统构建流程图
整个系统的结构图如图2 所示。
系统的实现采用B/S 结构,利用PHP Web 开发框架Laravel 实现前后端的交互逻辑。该框架采用MVC架构模式。此模式实现了模型、控制器、视图三个层次的隔离,在修改其中一个层次的代码的同时不会影响其他模块的功能,降低了层次之间的耦合性[1]。使用此框架将系统开发为一个Web 应用,使得系统和用户的交互更为友好。
2 智能问答系统实现
系统工作的第一步是为知识库的建立提供数据。以菜鸟教程网站内容作为数据源,利用网络爬虫技术获取页面信息,借助网页的结构和属性等特性获取所需数据,并将数据存入数据库中。
在爬虫获取页面并进行页面分析的过程中,获取的数据包括相关问题答案的链接、答案的文本内容,以及用于后续生成问题的问题标签列表。对于后续需要生成的问题,其问题标签列表由其答案所在位置的前三级标题构成。
在爬虫程序中,利用Beautiful Soup 库对页面进行层层嵌套解析的过程中获取了包含答案以及该答案对应的问题标签列表在内的数据。答案所在区域的前三级标题依次构成该问题标签列表,并将此列表保存在row_tags.txt 文件内。基于规则和NLP 的方法生成问题都需要结合row_tags.txt 进行分析。
2.1 基于规则和NLP的QA对生成
根据所爬取的html 文档结构,设计了以下规则。
规则1:假如最后一个标签以“参考手册”结尾,则使用“有哪些……?”来生成问题,其中“有哪些”后面的内容是该答案问题标签列表的倒数第二个元素,即该答案所在区域向前追溯的第二个标题。

图2 系统结构图
规则2:若最后一个标签以英文“?”中文“?”或者文字“吗”结尾,则将倒数第二个标签和最后一个标签组合在一起来生成问题。
设计规则的同时,以自然语言处理的方式对用户提问进行分析。并根据自然语言处理的结果设计相对应的规则,使生成的问题更加合理。
在自然语言处理的方法中,使用了哈尔滨工业大学社会计算与信息检索研究中心研制的语言技术平台(LTP)[2]以及“结巴”中文分词组件。
首先利用LTP 设计nlp_()方法,其功能是对输入的语句进行理解。该方法以句子作为参数,以列表作为返回值。返回值列表中的元素为Python namedtuple(命名元组),而每个命名元组代表对一个句子经过自然语言处理后所得到的单词及其属性。每个单词的属性值包括词性、命名实体、依存弧的父节点词的索引和依存弧的关系。
方法的实现经过四个过程,分别为分词、词性标注、命名实体识别和依存句法分析过程。首先对句子进行分词处理并将结果转换成列表类型。列表在经过去除首尾空格的处理之后作为词性标注过程的输入。以上两个过程的处理结果组合在一起,先后作为命名实体识别过程和依存句法分析过程的输入,最终即可获得一个单词的词性、命名实体、依存弧的父节点词的索引和依存弧的关系。
基于自然语言处理技术设计如下规则:
规则3:利用“结巴”中文分词中的posseg.lcut()方法对row_tags.txt 中的第三级标题进行分析。返回的结果为一个句子中所有的单词以及每个单词对应的词性。根据分析结果做如下处理,如果该标题经过分析之后仅含有一个词语(即该标题就是这个词语),这时查看row_tags.txt 中的第二级标题。如果第二级标题包含第三级标题,则把第二级标题作为问题。否则,将第二级标题和第三级标题按顺序组合为新的字符串作为问题。
规则4:利用上述设计的nlp_()方法对row_tags.txt中的第三级标题进行分析。在得到的分词列表中,寻找依存弧关系为’HED’的词语(依存弧关系为’HED’表示该词语在这个句子中作为根节点)并判断该词语的词性。如果该词语为动词,则在row_tags.txt 中的第三级标题前加上字符串“如何”作为新的字符串,并把这个新的字符串作为问题。否则,就直接把row_tags.txt 中的第三级标题作为问题。
以上规则规定了QA 对中问题的生成方法。针对不同的问题标签,遍历以上所有规则,找到与该问题标签相匹配的规则。之后将生成的问题和答案组合存入数据库。
2.2 基于RNN+LSTM的QA对生成
基于规则和NLP 的问题生成方法存在着问题生成质量不高,规则需要人工构建的缺点。基于此,我们尝试使用基于RNN+LSTM 的方法来生成QA 对。算法采用一种新的方式生成最终的问句。
该方法是:利用相关度判定模块(SVM 分类器)对用户所输入的问题去除冗余并生成关键词。利用排序算法(Word2Vec 词向量模型+RNNLM 语言模型)对关键词和预定义模板的匹配程度进行打分。之后得到分数最高的预定义模板,并根据此模板生成最终的问句[3]。
整个算法库由四部分组成。分别存放于templates、data、models 和QAS 文件夹内。对这四部分内容介绍如下。templates 为预定义检索词模板,data 内存放的是源数据(机器学习,深度学习),models 内为预训练的模型(SVM、Word2Vec、RNNLM),QAS 文件夹内包含了训练模块、相关度判定模块、相似度计算模块、频度计算模块以及排序生成模块[4]。
QAS 内的几大模块完成了该算法库的使用。
(1)训练模块(train_models.py)
此模块为模型训练器。且TrainModel 类被TrainSVM、TrainW2V、TrainRNN 类继承,原始数据集相对路径、转换后的训练集保存路径和模型保存路径作为其初始化参数。
训练SVM 的过程为:
from QAS import TrainRNN,TrainSVM,TrainW2V
初始化:
t=TrainSVM()
将原数据转换为训练集:
t.origin_to_train()
开始训练并将模型保存到默认路径:
t.train()
(2)相关度判定模块(correlation_calculate.py)此模块对待检索关键词进行判定并去除冗余,得到最终的关键词。
from QAS import Terms2Search
初始化一个实例
t = Terms2Search(['Mysql','通过命令窗口插入数据'],'models/svm')
计算搜索序列的相关度
t.correlation_calcuulate()
(3)相似度计算模块(similarity_calculate.py)
此模块依赖于W2V 词向量模型,利用WDM 算法计算文本之间的相似度,完成上述排序算法中的相似度计算。
from QAS import Search2Similar
初始化一个实例
s = Search2Similar(['Mysql','通过命令窗口插入数据'],'models/w2v')
计算查询词与模板的匹配度
s.similarity_calculate()
(4)频度计算模块(frequency_calculate.py)
此模块依赖于RNNLM(RNN+LSTM 语言模型),完成排序算法中的频度计算,最终为问句打分。
from QAS import Search2Frequency
初始化一个实例,传入语言模型和词典
s=Search2Frequency(['Mysql','通过命令窗口插入数据'],'models/rnn','models/rnn_dict')
计算搜索词序列的频度
s.frequency_calculate()
(5)排序生成模块(question_generate.py)
此模块综合利用上述各个模块的功能,对生成的问句排序打分,得到分数最高的预定义模板,并根据此模板生成最终的问句。
from QAS import QG
相似度序列
sim_list=[1.2375805176661339, 0.9552492172805888,0.9057426648128687,1.0242890857346802]
频度序列
fre_list=[-22.761973053216934,0.417869508266449,-7.039058595895767,-7.06894388794899]
初始化实例
q=QG(sim_list,fre_list,0.2,0.3,0.5)
排序打分
q.ranking()
本算法相对于基于规则和NLP 的QA 对生成算法具有如下优势:优势1:利用WDM 距离算法进行相似度计算使得检索词不再受限于关键词,还可以是短语或者句子。优势2:与传统方法相比,利用深度学习语言模型使得每个句子的得分更加合理。基于以上方法得到的问句便可和其对应的答案组成QA 对,存入数据库中。
2.3 信息检索
基于以上三种方法,我们已经构造了不同的问答对,并将其构建为本系统的知识库。针对每个查询,我们需要在已有的知识库中匹配与之相似度较高的问答对。实现此部分功能,我们对两种文本相似度计算算法进行分析,并利用相关Python 库实现。
算法1 TF-IDF 使用统计的方法来评估一个字词对于某一文件集或某一语料库中的其中一份文件的重要性[5]。计算公式为:
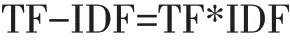

某一个给定的词语在该文档中出现的次数被称作TF(词频)。这个数字通常会被归一化。IDF 指:假如包含某一词条的文档越少,那么该词条的IDF 值越大,同时说明该词条具有较高的类别区分能力[6]。计算公式为:

算法2 潜在语义索引(LSI)作为一种索引和检索方法,与TF-IDF 不同,LSI 不是基于统计的方法。它基于奇异值分解(SVD)的数学技术来得到一段文本的主题。在LSI 中,相同上下文中使用的单词一般具有相近的含义。此外,利用建立在上下文中出现的术语之间的关联,LSI 能够将文本主体的概念内容提取出来[7]。
LSI 克服了布尔关键字查询中两个最有问题的约束:同义词和多义词。同义词通常是文档作者和信息检索系统用户使用的词汇不匹配的原因。因此,布尔或关键字查询通常会返回不相关的结果并错过相关的信息。相比之下LSI 算法比TF-IDF 算法更具优势。以下为使用LSI 算法进行文本相似度计算的过程。
在此,使用Gensim(Python 第三方库)建立相应模型进行文本相似度的计算。实现过程分为以下两步。
第一步,为所有数据表建立相似度模型,并将模型持久化。
训练语料的预处理。预处理的过程也就是将原始文本转换成Gensim 能够理解的稀疏向量的过程。
dictionary=gensim.corpora.Dictionary(texts)
corpus=[dictionary.doc2bow(text)for text in texts]
主题向量的变换,首先需要将模型对象初始化,Gensim 将训练语料作为初始化参数。
tfidf=gensim.models.TfidfModel(corpus)
在此基础上,利用此模型将语料转化为用TF-IDF值表示的文档向量。
corpus_tfidf=[tfidf[doc]for doc in corpus]
Gensim 的LSI 模型训练建立在TF-IDF 之上,用来解决潜在语义。
利用TF-IDF 值表示的文档向量训练LSI 模型,并将文档映射到一个50 维的topic 空间中。
lsi = models.LsiModel(corpus_tfidf,id2word=dictionary,num_topics=50)
corpus_lsi=[lsi[doc]for doc in corpus]
接着,将待检索的文档向量作为相似度计算对象的初始化参数。
index_tfidf=gensim.similarities.MatrixSimilarity(corpus_tfidf)
index_lsi=gensim.similarities.MatrixSimilarity(corpus_lsi)
将模型持久化:
dictionary.save("MODELS/%s_dic"%table_name)
lsi.save("MODELS/lsi_%s"%table_name)
index_lsi.save("MODELS/lsi_index_%s"%table_name)
第二步:加载模型计算文档相似度并获取答案。
对于给定的一个查询,需要从所有的文本中查找出具有最高主题相似度的文本。
首先,加载已经生成的模型:
lsi = models.LsiModel.load ("MODELS/lsi_% s"% table_name)
lsi_index=gensim.similarities.MatrixSimilarity.load("MODELS/lsi_index_%s"%table_name)
dictionary=corpora.Dictionary.load("MODELS/%s_dic"%table_name)
其中,待检索的查询和文本必须用同一个向量空间表达。
利用jieba 库的精确模式,将待检索的查询切开。并调用LSI 模型将语料转化成LSI 向量。
text=dictionary.doc2bow(seg_text)
lsi_text=lsi[text]
利用lsi_text 对象计算出任意一段查询和所有文本集合的相似度:
sims=lsi_index[lsi_text]
得到其中相似度最高的三个:
positions=sims.argsort()[-3:]
之后在已经建立好的数据库中查询出这三个相似度最高的问题所对应的答案并返回。
3 结语
本文给出了基于规则、NLP、机器学习,三种生成问答对方法的智能问答系统构建过程。其中采用深度学习方法生成问答对的质量最高。并比较介绍了信息检索的两种相似度计算算法,最终选择LSI 作为系统的相似度计算算法。以上算法的选择和实现保证了系统问题检索与答案匹配的极高准确率,具有一定的实际意义。
