数据挖掘技术在节水管理中的应用
2019-07-29
(北京大学 城市与环境学院,北京 100080)
1 研究背景
水资源是生产生活中不可或缺的战略性资源,在促进经济社会可持续发展中具有不可替代的作用[1-3]。我国面临着水资源供需矛盾突出、用水效率不高等问题[4],严峻的水资源形势迫使我们必须从战略高度上充分认识节水管理工作的重要性。
目前,我国节水管理主要面临着以下问题[5]:在法律法规层面,可操作性不强、约束力度不大;在政策体制层面,难以形成以经济化手段为核心的市场管理制度;在计量监测层面,缺乏针对性;在产业结构层面,难以发挥水资源的调控作用。节水管理涉及到的行业广泛、主体多元,从工农业用水到生活生态用水,从企业单位到机关学校,不同用水主体的行为习惯和用水特点各不相同[5-6]。因此,节水管理需要结合不同主体的用水模式,向有针对性的差异化、精准化管理转型,从宏观政策走向微观手段,从省市政府走向企事业单位,从“一刀切”方式走向个性化方式。
为满足节水管理新需求,水利部于2016年首次在全国开展了企事业单位的用水监控工作,颁布了《国家重点监控用水单位名录》(第一批)[7]。该工作首次从微观层面和用户需求角度,客观考察和评估用水户的用水状况,共从全国约800家企事业单位收集到约26万个用水数据,需采用专门的数据分析技术从中提取节水管理需要的信息[8-9],为改进以后的数据采集方式和数据采集标准提供理论依据,并为精准化、差异化节水管理奠定科学基础。
数据挖掘是通过对大量数据进行分析处理,并从中寻找出有意义的模式和有价值的信息的过程[10],具有面向数据量巨大、自动或半自动发现数据内在联系等特点[11]。数据挖掘方法包括分类、估计、预测、聚类等分析模型[12]。数据挖掘在水科学的诸多领域中发挥着重要作用[13-17],聚类分析能够在没有事先定义类别的前提下依据不同特征将主体划分为不同类型[9],在用水效率评价、水资源优化配置等领域应用已较为成熟[18-19],但在用水模式划分领域的应用还相对缺乏。
综上,考虑到我国节水管理新需求,本文采用数据挖掘技术处理实测用水数据,提取特征信息,划分不同用水业务群,对精细化和差异化节水管理提出针对性建议,为提升水资源配置效率提供更加可靠的科学依据。
2 数据来源与研究方法
2.1 数据来源
本文选用《国家重点监控用水单位名录(第一批)》(以下简称《名录》)中各单位实际用水数据进行数据挖掘。《名录》基于水利部发布的《关于加强重点监控用水单位监督管理工作的通知》[7],该通知于2016年发布,2017年末获得首批数据,实际取得713家单位的用水数据。数据集包含各单位的2016年实际用水量(WU act16)、2016年预计用水量(WU pre16)以及2017年预计用水量(WU pre17),数据总量共计26.02万条,2017年及以后数据的收集受机构改革影响而暂缓。用水单位行业分布如图1所示,用水单位地域分布与各地区生产总值如图2所示。

图1 《名录》中用水单位行业分布Fig.1 Industry distribution of water use units inthe monitoring list

图2 《名录》中用水单位地域分布与各地区生产总值Fig.2 Regional distribution of water use units andGDP of each province
《名录》中单位行业划分参考《国民经济行业分类》(GB/T 4754—2017)[20]中的二级行业分类。从图1和图2可见,《名录》中单位行业类型齐全,电力、石化、钢铁、煤炭等高耗水行业[21]的单位数量较为丰富,在地域分布上与我国地方发展水平大体吻合,因此可以认为该数据在行业和空间分布上有很强的代表性。本文选用此数据能够从水资源需求取向入手,站在企事业单位的微观层面,提取用水特征,从而区分不同用水模式,为差异化节水管理提供科学依据。
2.2 研究方法
本文采用数据挖掘技术中的聚类分析方法,对不同用水模式进行分类、确定不同用水业务群,从而进行差异化节水管理。聚类分析是将数据集中的样本划分为若干个不相交的类或簇,使得类别之外的数据差别尽可能大,类别之内的数据差别尽可能小,是一种不依赖预先定义类的非监督学习过程[12]。
由于用水特征与用水模式先前未知,具体算法选用基于DB index准则进行特征选择的k-means算法。该方法是一种基于非监督学习的特征选择方法,试验结果表明该算法具有时间复杂性低、执行效果好等特点[22]。特征选择是从原始数据中提取特征的过程,选择效果会直接影响分析模型的性能[23]。

表2 最先筛选出的特征Table 2 First three features selected
注:WSE为2016年实际用水与2016年预计用水比率;EW为2017年预计用水与2016年预计用水比率;Cv为2016年实际用水变异系数;字符带横线为平均值
2.2.1 DB index准则
依据DB index准则[22]进行特征选择的核心思想是:利用类间距离和类内离散度,构建DB index作为判断函数用于特征选择,即

(1)

进行特征选择的过程如下:构建特征集F,从F中依次删除一个特征xi1,利用剩余特征计算相应的DBk(i)值。当DBk(i)最大时证明被删除的特征xi1对于聚类效果影响程度最大,因而被筛选出来。重复上一步直至选择出m个特征,即对全部特征进行排序,选择排序靠前的特征应用于聚类模型。
2.2.2 k-means算法
k-means算法针对给定样本集D={x1,x2,…,xm}和所得类别划分C={C1,C2,…,Ck}构建判别函数E用于衡量类别内部的分散程度,即
(2)
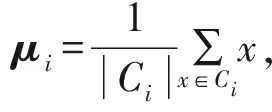
A(k)=(DBk+1-DBk)/DBk。
(3)
当使A(k)达到一个较小的值或接近于0,此时k为合适的类别数。
3 结果与讨论
将原始用水数据进行缺失值补充等数据预处理后,应用多项式、指数函数、对数函数等非线性数据变换等手段,提取、构建出用水数据的10维特征集,然后基于DB index准则对特征集进行特征选择,将筛选出来的合适特征应用到k-means算法,进行用水模式的聚类。其结果为差异化节水管理提供科学依据。
3.1 计算结果
3.1.1 特征选择
特征选择结果如表1所示。将特征集输入,用水类型划分为5类,即k=5时满足A(k)最小,以随机抽取10%的训练集作为测试样本,测试的分类结果与训练集的分类结果不同(混淆矩阵中非对角线上的值)计为分类错误,经过多次测试,分类错误率趋于0.126 7,验证了该方法在本文数据集上的可用性。最先筛选出的特征如表2所示。

表1 特征选择结果Table 1 Result of feature selection
注:分类错误率=分类错误的样本总数/(测试样本总数×抽取次数)
如表1、表2所示,最先被筛选出来的特征分别是F9,F7,F6。其中:
2016年实际用水占预计用水的比率为
WSE=WU act16/WU pre16 ;
(4)
式(4)可从总体上衡量用水单位在2016年实际节水情况的现状特征。
2017年预计用水占2016年预计用水比率为
EW=WU pre17/WU pre16 ;
(5)
式(5)可反映出单位综合考虑了本年度实际用水情况和对于单位第二年发展情况的预计用水量变动情况,也就是单位节水的愿景特征。
实际用水量的变异系数(Cv)为

(6)
式(6)可用于衡量各单位在实际用水过程中的波动特征。
在F6被提取出后,3个特征涵盖了数据集中的大部分信息,因此可以将其后筛选出的特征进行舍弃。计算各个特征之间的相关系数,形成特征相关性热力图如图3,图中颜色越深表示相关系数越高。经计算3个特征之间的相关系数为{0.23,0.31,0.17},相关性程度不高,在热力图上属于颜色较浅的低谷区,独立性强。从物理意义来看,筛选出来的特征可以分别表征重点监控用水单位的现状特征、愿景特征以及波动特征。因此可以认为,无论是从信息保留率、特征相关性,还是从物理意义上来讲,特征筛选效果较好,筛选出的特征可用于表征各单位的实际用水情况。
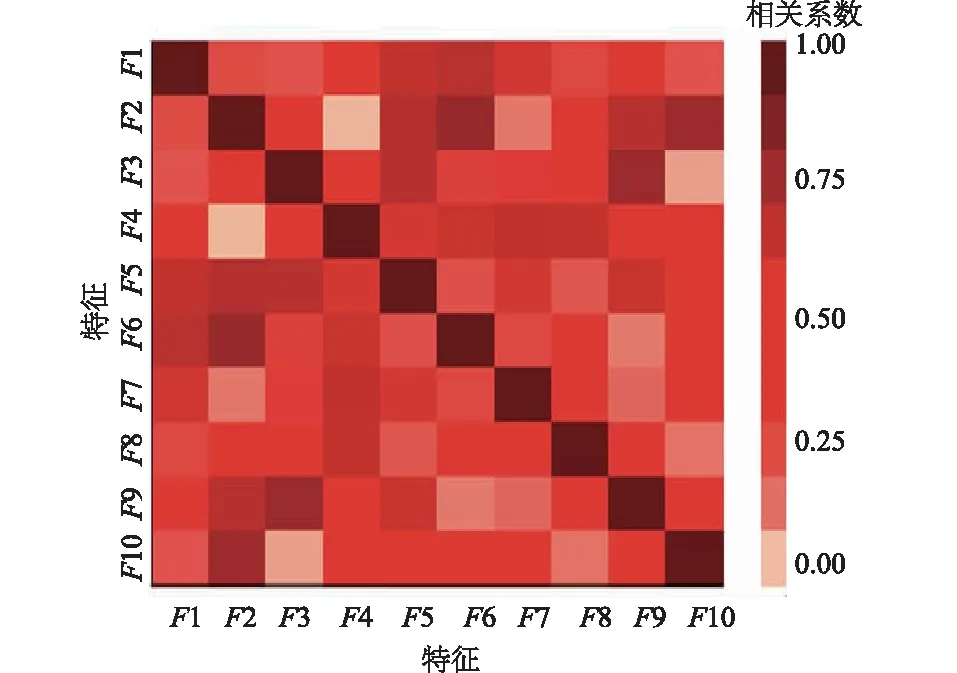
图3 特征相关性热力图Fig.3 Heatmap of correlation among features
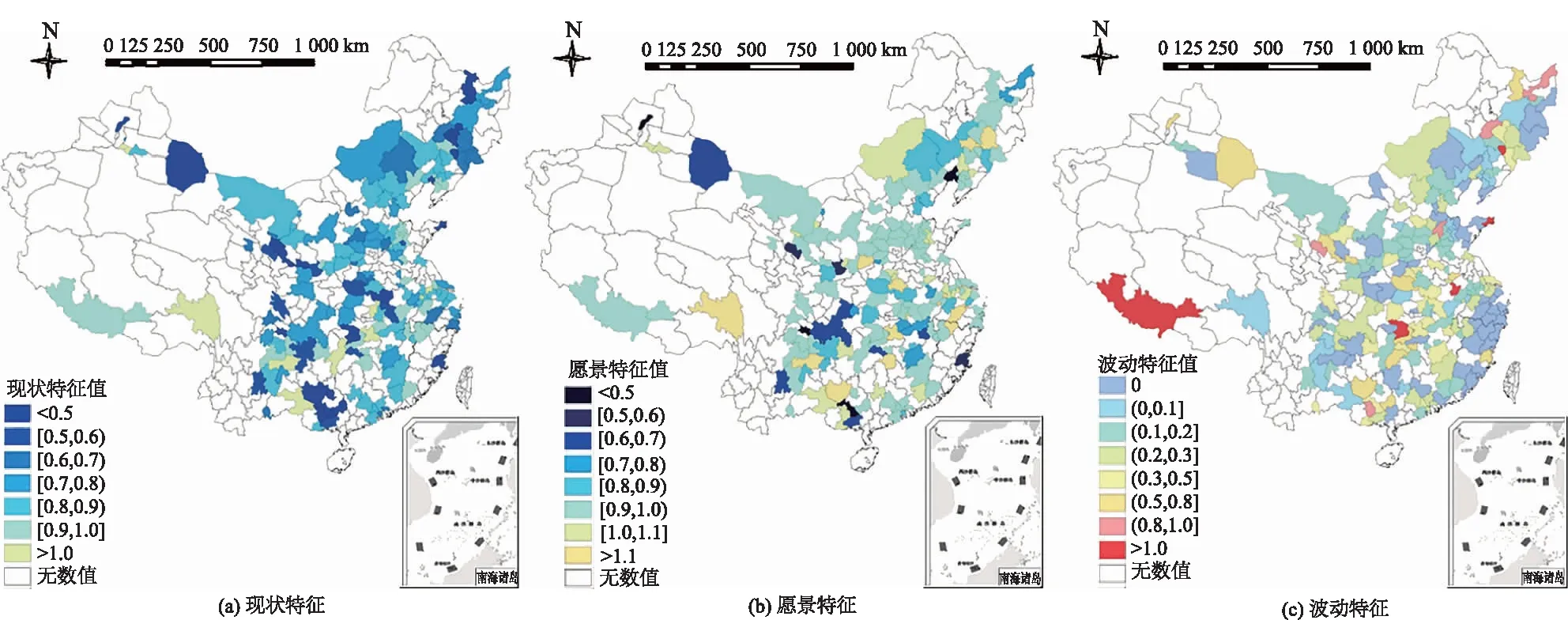
图4 用水特征空间分布Fig.4 Regional distribution of the selected three features
结合表2和图4,得到现状特征均值为0.825 4,全国大多数城市的用水单位将实际用水量控制在计划用水量之内,现状特征值主要集中在[0.7,0.9];广西百色、贵州毕节、西藏昌都等个别西南地区或有极大值出现,节水能力稍弱。愿景特征均值为0.990 1,全国大多数单位的愿景特征集中在[0.8,1.0]之间,预期节水意愿充足;东北、东南部等个别城市愿景特征稍弱。波动特征均值为0.214 5,多数单位波动特征集中在[0.1,0.5]之间;东南沿海地区用水均匀,中西部和部分东北城市用水波动性较高。
3.1.2 用水模式分异
应用特征选择结果采用k-means算法进行聚类,将各用水单位划分为5种用水模式,F检验的通过再次验证了聚类结果的可靠性,聚类结果如表3。
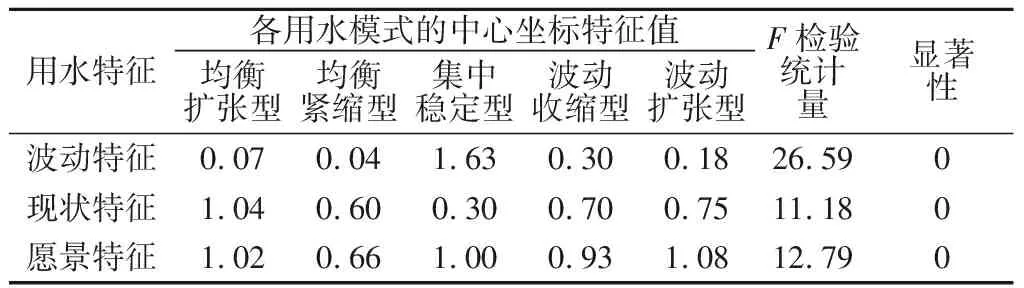
表3 聚类结果Table 3 Result of clustering
从表3结果看出,用水模式被划分成5种,依据中心坐标的特征值将各用水模式命名为:均衡扩张型、均衡紧缩型、集中稳定型、波动收缩型和波动扩张型。由表4可知:用水模式属于均衡紧缩型和集中稳定型的行业较少,代表性有待考证;用水类型为波动收缩型的行业数量最多,包括黑色金属冶炼和压延加工业、化学原料和化学制品制造业等,该类型包括了大多数产能过剩的高耗水行业;用水类型属于波动扩张型的行业有商业服务业、公共设施管理业、生物科技与生物化工等。
从图5用水模式地域分布来看,绝大多数单位的用水模式是波动收缩型,波动扩张型集中在北京、上海、山西、新疆等地,均衡扩张型用水单位分布在上海、广西、江西、青海等地,均衡紧缩型与集中稳定型的用水模式在全国范围内分布极少。

表4 各用水模式下的用水单位所属行业Table 4 Industries corresponding to each water-usepattern
注:*用水单位的行业划分参考《国民经济行业分类》(GB/T 4754—2017),个别用水单位业务涵盖多个行业,无法做具体区分

图5 用水模式地域分布Fig.5 Regional distribution of water-use pattern
3.2 分析讨论
用水特征上,全国大多数城市的用水单位节水现状较好,有一定的预期节水意愿,波动特征大体呈现由东南沿海向内地增加的趋势,可能与各地水资源禀赋和降水模式有关。
用水模式上,绝大多数单位的用水模式属于波动收缩型,其次为波动扩张型与均衡扩张型。从行业分布来看,波动收缩型主要涵盖产能过剩的钢铁、化工、石化、金属等高耗水行业,均衡扩张型与波动扩张型多为高新科技与服务业。在地域分布上,由于《名录》本身在农业、服务业的单位数量分布相对较少,因而全国各地的用水模式构成较为单一,没有明显的分布规律。
产业结构上,农业的用水模式为集中稳定型,工业的用水模式有其他4种用水类型,但主要的用水类型是波动收缩型,服务业的用水模式为波动扩张型。随着我国经济发展和产业结构升级,用水模式结构势必会随之变化。但由于首批获得的用水数据在行业分布、数据维度和时间跨度上都不够丰富,算法本身只能得到一个局部最优解而导致数据挖掘的结果具有一定的局限性[22]。因此希望后续研究能够在算法选择和数据丰富度方面加以改进,得到更多维度的用水特征,刻画出更为完善的用水模式,建立起行业、产业结构与用水模式之间更为稳定的映射关系,探究各行业用水模式发展变化趋势,据此来判断各单位在所在行业中用水模式的相对位置,评价各省市用水模式的相对优劣,并提出针对性的奖罚措施,为差异化节水管理提供科学依据。
4 结论与建议
4.1 结 论
本文结合我国节水管理现状,应用数据挖掘手段中的聚类分析,对我国首批重点监控用水单位的实际用水数据进行了用水特征的提取和用水模式的分异,主要得到以下结论:
(1)利用基于DB index准则进行特征选择的k-means算法进行用水数据的聚类分析,当分类数k=5时,A(k) 最小。经多次测试,稳定的分类错误率较低,验证算法可用。
(2)最先筛选出3个特征为:现状特征(WSE)、愿景特征(EW)、波动特征(Cv)。三者信息保留率高,相关性低,物理意义明确,可用于表征重点监控用水单位的实际用水情况。除广西百色、贵州毕节、西藏昌都等西南个别地区外,其余地区节水现状较好,现状特征集中在[0.7,0.9];除东北、东南部分地区外,多数地区预期节水意愿充足,愿景特征集中在[0.8,1.0];东南沿海地区用水相对均匀,中西部和部分东北城市用水波动性较高,波动特征集中在[0.1,0.5]。
(3)应用筛选出的用水特征,采用k-means算法进行用水模式分异,将各单位划分成均衡扩张型、均衡紧缩型、集中稳定型、波动收缩型和波动扩张型5种用水模式。其中波动收缩型在全国的分布数量最高,除个别行业以外,该用水模式涵盖了大多数产能过剩的高耗水行业,而波动扩张型与均衡扩张型则涵盖了大部分高新科技与服务业。产业结构上,农业的用水模式为集中稳定型,工业拥有其他4种用水类型,服务业的用水模式为波动扩张型。
4.2 节水管理建议
为促进节水管理向差异化、精准化管理转型,本文基于上述结论,结合不同主体的用水特征与用水模式,对节水管理提出针对性的建议。
在法律法规层面,需加强对用水企事业单位的实际用水研究,制定需求导向的节水管理法规,对于不同的用水模式设立差异化的操作性指标,提升法规的可操作性。
在监控指标层面,设立针对性考核指标与考核周期:对于均衡扩张型、均衡紧缩型的行业,适宜设置月均用水监控指标;对于集中稳定型的行业,在每年用水高峰时段进行重点监控与考核;而对于波动收缩型和波动扩张型的行业,采取年度总量控制的监控方式更为合适。
在政策体系层面:形成以经济化手段为核心的市场管理制度。可以利用各单位用水特征,促使波动特征充足的用水单位与用水稳定的单位进行用水权交易,识别现状特征和意愿特征均较高的单位进行精准定向的税收优惠政策和财政补贴,充分激发用水单位的节水热情。
在产业结构调整层面,建立起产业结构与用水模式的映射关系,依据用水模式助力产业结构调整,判断用水模式变化趋势,使用水模式与创造产值相匹配,逐步提升用水效率,实现水资源的合理配置与可持续利用。
