基于二维信息增益加权的朴素贝叶斯分类算法①
2019-07-23任世超黄子良
任世超,黄子良
(成都信息工程大学 通信工程学院,成都 610225)
引言
随着互联网技术的快速发展,海量的文本信息及其多样化使得文本分类任务越来越受到研究界的关注.文本分类在信息检索方面能够加速检索过程,提高检索性能.同时,文本分类在新闻专线过滤、专利分类和网页分类方面都发挥了重要的作用.文本分类中数据往往具有的高维、稀疏、多标号等特点,这些往往是机器学习需要解决的问题.因此文本分类在机器学习方面具有重要的价值.
目前虽然有许多算法可以实现文本分类,如SVM,KNN,神经网络、深度学习等,但是在简洁性和有效性方面朴素贝叶斯算法都要优于其他算法[1-3].朴素贝叶斯算法发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率.在数据较少的情况下仍然有效,它是在贝叶斯定理的基础上提出了一个属性条件独立性假设,即对于已知类别,假设所有属性相互独立,对于分类结果互不影响[4],所以朴素贝叶斯可以有效的用于文本多分类任务.因此我们决定使用朴素贝叶斯算法用来文本分类的研究.由于朴素贝叶斯算法是在条件独立性假设的基础上提出来的,即所有属性的权值都为1,但实际上每个属性对于文档的分类的重要性是不同的,也就是权值的取值不同.特征提取是文本分类的关键步骤,由于不同的加权算法对应权值计算,直接会对我们的特征的提取以及最终分类的结果造成比较大的影响,所以研究者们提出不同的权值计算方法来进行改进加权.如文献[5]中把特征信息增益加到TF-IDF算法中相应改善算法性能后,之后文献[6]又把信息增益与信息熵结合,文献[7]中提出了根据特征在类间的词频和文档频率重新计算反文档频率,文献[8]中把各特征相对于类别的互信息作为权重.但是这些算法没有全面考虑影响特征权重的因素.
本文通过对现有文献中文本分类算法的研究,提出了基于二维信息增益的加权算法IGC-IGD (Information Gain of ocument and Category),从类别信息增益和文档信息增益两个方面综合考虑特征词对分类效果的影响,并设计实验进一步验证了IGC-IGD 算法在各个评价指标上都要优于其他算法.
1 朴素贝叶斯及其改进加权算法
1.1 朴素贝叶斯算法
本文采用了文献[9]所给出的贝叶斯模型为多项式模式,算法思想是:首先计算出各个类别的先验概率,再利用贝叶斯定理计算出各特征属于某个类别的后验概率,通过选出具有最大后验概率(maximum a posteriori,MAP)估计值的类别即为最终的类别[9].
算法描述:
设文档类别为C={C1,C2,···,Cj},j=1,2,3,···,V,则每个类的先验概率为P(Cj).设Di为任意一篇文档,其包含的特征词为Di={t1,t2,···,tm},把Di归为哪一类的概率就是后验概率P(Cj|Di).

贝叶斯分类的过程就是求解P(Cj|Di)最大值的过程,显然对于给定的训练文档P(Di)是个常数.所以求解过程可转化成求解:

因为Di={t1,t2,···,tm},根据朴素贝叶斯假设,{t1,t2,···,tm}各特征相互独立,所以式(2)可等效成:

其中,P(Cj)表 示Cj类出现的概率,P(ti|Cj)出现ti属于Cj类的概率.
1.2 基于TF-IDF 加权朴素贝叶斯算法
由于朴素贝叶斯算法没有考虑到不同特征对分类效果造成的影响,通常采用TFIDF 算法[10]对特征进行特征加权.加权朴素贝叶斯模型:

由于每次计算的概率可能会比较小,为了避免出现下溢的情况,通常采用对决策规则取对数的形式:
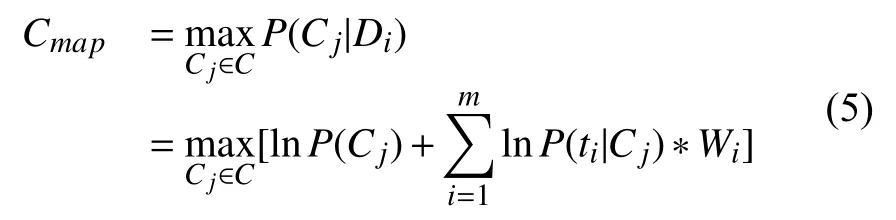
TF-IDF 算法的思想:特征单词虽然在整个文本集中出现的频率比较低,但是在某特定文本中出现的频数越大,则对于该文本的分类作用越大,反之,特征单词在大多数文档中出现的频数越大,对于文本的分类作用越小[6,11].TF-IDF 算法将词频和反文档频率结合作为特征的权重,归一化计算方法:

其中,TF(ti)为特征ti在训练集中出现的频数,IDF(ti)是反文档频率,N表示训练集的总文档数,n(ti)表示出现特征ti的文档数.
1.3 基于TF-IDF*IGC 加权改进算法
虽然TF-IDF 算法一定程度上能提高分类的精确度,但效果并不是很明显.因为该算法只考虑了特征词在训练集中的总体分布情况,而忽视了特征词在类别中的分布情况对其权重造成的影响.针对这个问题,文献[5]的工作主要是把信息论中信息增益应用到文本集合的类别层次上.提出了一种改进的权重公式TFIDF*IGC,首先计算出各个类别的信息熵,然后计算各特征词在每个类别中的条件信息熵,利用两者的差值计算出单词在各个类别中的信息增益,把该信息增益反映在权重中,计算公式:

其中,C为文档的类别集合,为类别Cj在训练集中的概率,为每个特征词t在类别Cj中出现的概率,表示类别总数.
利用TF-IDF*IGC 算法能够将特征在类别中的信息反应出来,并同时能够对每个特征权重做一定的修正.当特征词t在某个类别中分布很多,而在其他类别中分布很少时,利用信息增益计算公式就能得到很高的信息增益值,这样就能很好的反应出特征词的分布对分类的影响,反之就能得到较小的信息增益值[5],所以在一定程度提高了算法的精确度.
2 基于IGC-IGD 特征加权朴素贝叶斯算法
由于1.3 节给出的TF-IDF*IGC 算法只考虑了特征词在类列间的分布情况并没有考虑到特征词在每个类别文档中的出现情况,因此会对对权重造成的影响.以进一步提高算法精度为目标,针对TF-IDF*IGC 算法的缺陷,本节定义一个新的权重计算函数:IGC-IGD 函数.由于信息增益是描述某个属性对分类效果提升作用的指标,信息增益越大,意味着特征属性对文档分类提升越大[4].二维信息增益的定义即为同时从特征词关于文档的信息增益和特征词关于类别的信息增益这两个维度进行考虑,有效的结合了特征在两个方面的性能来刻画特征类别和特征文档对分类作用的提升程度,这里定义了新的方法求特征类别概率:

其中,t f(Dt,Cj)表示各特征词在类Cj中的频数,所以P(t,Cj)就表示类Cj中出现的特征词在训练集该特征词总数中出现的概率.式中的L是为了抑制概率为0 的情况所加入的平滑因子,本文中取L=0.01,V表示类别数.同样的方法得到各类别中特征词出现的文档数在训练集中对应特征词所出现的总文档数中出现的概率:

其中,tf(Dt,Cj)表示在类Cj中t含有特征词的文档数,L=0.01 为平滑因子,V表示类别数.
传统的求特征文档信息增益的方法仅仅考虑了特征与文档的关系[11],而忽略了文档与文档类别的关系,所以这里定义新的求特征文档信息增益的公式把特征与文档的关系同时把文档与文档类别的关系结合在一起,由此可以得到新的特征类别信息增益和特征文档信息增益:

其中,IGC表示特征类别信息增益,刻画特征与类别的关系;IGD表示特征文档信息增益,刻画特征与文档的关系;P(Dt,Cj)和P(t,Cj)分别表示上文提出的求特征类别概率和特征文档概率.这样得到的两组信息增益能够准确的反应出每个特征词对每个类别的影响力以及每个特征词对每类文档的影响力.同时把特征词类别信息增益和文档信息增益结合起来,并采用归一化方法进行处理,得到权重表示为:

其中,IGC(ti)、IGD(ti)分别表示数据集的某一个特征的类别信息增益和文档信息增.式(14)首先计算IGC(ti)×IGD(ti)的值获得原始数据,然后再进行归一化.归一化的目的是为了使数据等比例的变化,这样不会影响整体的权重调整.这也就是二维信息增益的具体定义.
下面举例说明新权重的合理性,假设训练集包含3 个类别,每个类别中有3 篇文档,特征词集合为{t1,t2,t3}分布情况如表1所示.

表1 特征词分布
由表1知t1在三个文本中都出现过,t1只是在类别1 中出现过,说明t1能够准确的代表类别1 的信息,应当给予较大的权重,t3在三个类别中都出现相同的次数,说明不具有分类能力,应当给予较小的权重,大部分出现在类别3 中,t2所以分类能力要比t1好,但是比t2要差,所以权重值应当介于t1和t2之间,使用以上三个算法得到的权重结果如表2所示.
由表2中的结果可以看出,TF-IDF 算法因为针对的是整个训练集中的特征,所以词频越大的特征被分配的权重越大,导致结果与实际情况有点截然相反.TF-IDF*IGC 算法不仅考虑了在整个训练集中的情况,还考虑了特征词与类别间的关系,所以权重分配比较更合理一些,但因为仍然与反文档频率相结合导致t1与t3的权重相差很小,这种时候可能会影响到分类效果,相比之下IGC-IGD 算法不仅让没有分类能力的特征词t2权重消零,而且让t1与t3的权重拉开了差距,这样能让各个特征起到决定分类作用的效果.
3 实验设计与结果分析
3.1 实验数据及其预处理
实验数据采用国际通用的20_NewsGroup 数据集
进行验证.该数据集为英文数据集,从qwone.com/~jason/20Newsgroups 官网下载,一共包含20 个类,从中选出6 个类:alt.atheismcomp.graphics,misc.forsale,rec.autos,sci.crypt,talk.politics.guns,从每个类别中各抽出100 篇文档,一共600 篇文档,采用交叉验证法[12],随机选出60%(360 篇)作为训练集,40%(240 篇)作为测试集.
实验数据预处理:去除掉标点符号,停用词,数字以及一些特殊符号,为了降低空间复杂度和分类计算的时间,把词频特作为选择单词的标准,对每次选取500 特征进行实验,重复实验十次求平均值来验证算法的准确性.
3.2 实验结果分析
本实验中使用上文介绍的三个加权算法与朴素贝叶斯算法结合进行实验.采用查准率(P)[12,13],召回率(R)[14,15],F1 值(F1)和宏F1 值(Macro_F1)四个指标[16-20]算公式如下:

TP表示正确的标记为正,FP错误的标记为正,FN错误的标记为负,TN正确的标记为负[4],如表3所示.

表3 参数含义
实验结果如表4所示.

表4 算法测试结果比较
由表4可以看出,当使用基于二维信息增益IGCIGD 加权的朴素贝叶斯文本分类算法时,查准率,召回率和F1 值这三个指标总体上都有明显的提高.具体的,IGDCNB 算法对所有类别的查准率都要高于其他两种算法,除了comp.graphics,misc.forsale 两个类别的召回率略低于TF-IDF*IGC 特征加权的朴素贝叶斯文本分类算法,对于F1 值,IGDCNB 算法也都要领先于其他两种算法,个别类别比如sci.crypt 和talk.politics.guns,虽然传统的基于TF-IDF 特征加权的朴素贝叶斯文本分类算法具有较高的查准率,但其召回率却远远低于IGDCNB 算法,这也不是研究者希望出现的.总体上看,与TF-IDF*IGC 加权算法相比,三个指标都能提高3%到4%;与TF-IDF 加权算法相比三个指标都能提高4%到6%,这充分证明了IGC-IGD 加算法的有效性.查准率对应实际被分类的比例,召回率对应应该被分类的比例.由于查准率较高时召回率不一定能够很高,所以本文最后采用比较三种算法的宏F1 值的方法来验证IGC-IGD 加权的朴素贝叶斯文本分类算法的有效性.本文通过选择不同的特征数来验证算法的准确性,实验结果如图1所示.

图1 3 种算法宏F1 值比较
F1 值对应查准率P和召回率R的调和均值.宏F1 值是所有类别对应的F1 值得平均,能够反应各加权算法整体性能(查准率、召回率、F1 值)的指标.由图1可以看出,当特征数量从500 增加到1000 时,IGC-IGD 加权的朴素贝叶斯分类算法的宏F1 值要高于其他两个算法,根据3.2 宏F1 值的计算公式计算可以得到该算法相比传统的加权算法宏F1 值提升将近6%左右,而且该算法本身不会因为特征数量的变化出现较大的波动,说明在给定一定量有价值的特征时,二维信息增益IGC-IGD 加权的朴素贝叶斯分类算法能够有效的对文本进行分类.
4 结束语
本文通过有机的结合特征类别信息增益(IGC)和特征文档信息增益(IGD),提出了二维信息增益加权的朴素贝叶斯分类算法,充分利用了文本中特征的二维信息,克服了传统朴素贝叶斯算法分类性能上的缺陷,通过实验进一步验证了该算法的有效性.为了进一步提升朴素贝叶斯文本分类算法的性能,以得到更为精确迅速的分类方法.下一步的工作将会从朴素贝叶斯算法中的条件概率计算方法这个方面进行改进.
