基于大数据技术的灾害监测系统联调联试数据挖掘研究
2019-07-22武明生杨礼熊伟
武明生,杨礼,熊伟
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
0 引言
自2008年京津城际开展联调联试工作以来,我国高速铁路灾害监测系统积累了京沪、武广、哈大、杭长、兰新二线等141条/段线路联调联试数据。随着大数据应用技术的发展,如何对灾害监测系统联调联试数据进行分析及展示,从中挖掘潜在价值、隐藏规律和发展趋势已十分迫切。
大数据技术是继云计算、物联网等技术之后又一重大技术革命,是人工智能、机器学习、模式学习、统计学等捕获数据的技术[1],具有体量大(Volume)、类型多(Variety)、速度快(Velocity)、价值密度低(Value)等特点。结合大数据技术,通过对灾害监测系统联调联试过程中产生的大量不规则数据进行研究,对文档结构化、技术架构、分析方法、采用算法等进行选择,提出数据挖掘流程和期望目标,并对成果应用进行分析,为灾害监测系统优化及联调联试改进提供参考[2]。
1 灾害监测系统联调联试数据
灾害监测系统主要实现对铁路沿线风、雨量、雪深及异物侵限的实时监测[3],保障列车运行安全。灾害监测系统联调联试项目包括风监测、雨量监测、雪深监测、异物侵限监测、设备冗余、状态监测及辅助功能[4],累计5个场景、42个检测项,设计监测点6 881个,2008—2018年共检测2 417个监测点(见图1)。

图1 联调联试现场监测点数量
灾害监测系统联调联试过程中形成的原始数据以纸质文档存储,后期整理为电子文档。电子文档主要为非结构化数据和半结构化数据,共256 G,电子文档存储格式见表1。
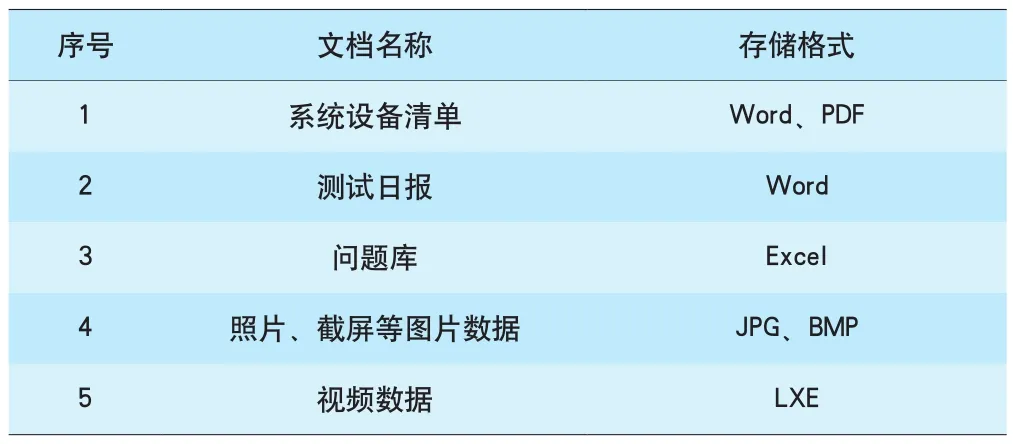
表1 联调联试数据电子文档存储格式
2 挖掘方案
2.1 文档结构化
当前灾害监测系统联调联试数据主要以文档形式存储,给数据利用带来很多不便。本研究基于大数据技术,通过读取Word、PDF、Excel等文档中的数据,按照一定规则整理后,存储到创建好数据表的MySQL数据库中,实现联调联试文档的结构化[5]。数据库设计见图2。

图2 联调联试数据库设计
2.2 技术架构
为提高数据的分析效率以及未来同其他业务数据进行融合分析,依托中国国家铁路集团有限公司数据服务平台,开展灾害监测系统联调联试数据的分析和展示。铁路数据服务平台由中国国家铁路集团有限公司统一建设部署,是集数据分析、计算、存储、整合等功能为一体的大数据分析平台[6],平台技术架构见图3。
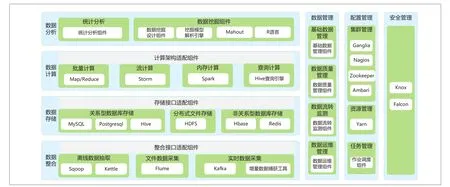
图3 铁路数据服务平台技术架构
2.3 分析方法
根据灾害监测系统联调联试数据的种类、特征,采用多维数据分析方法[7],对数据从多个角度即多个维度进行观察和分析。通过对多维形式组织起来的数据进行切片、切块、聚合、钻取、旋转等操作,展开数据剖析,从多种维度、多个侧面、多种数据综合度分析数据,从而深入掌握基础数据的信息和内涵。
灾害监测系统联调联试数据包含灾害监测、灾害报警、设备类型、故障类型、线路类型、设备厂家等维度,通过多维数据的切片、切块、聚合等分析操作,从联调联试数据中提取各种维度的数据,可为管理、运维、检测、科研等不同的用户统计分析不同维度关联信息。多维数据分析方法逻辑架构见图4。

图4 多维数据分析方法逻辑架构
2.4 算法选择
大数据挖掘常用的算法有分类、线性回归、聚类、关联规则、神经网络方法、Web数据挖掘等,灾害监测系统联调联试数据分析、挖掘算法主要采用线性回归法[8]。
线性回归是确定2种或2种以上变量间相互依赖的定量关系的一种统计分析方法,其表达形式为y=w’x+e,式中:y为因变量;w’为方程参数;x为自变量;e为误差,服从均值为0的正态分布。回归分析可反映数据库中数据属性值的特性,通过函数表达数据的映射关系,从而发现属性值之间的依赖关系,主要应用于对数据序列的预测及相关关系的分析。利用线性回归法,可以从灾害监测、灾害报警、设备状态监测及性能检测数据中有效地分析各种数据的相关性,输出期望目标。
2.5 挖掘流程
基于大数据技术优势,结合灾害监测系统两级架构及功能、性能检测项目,实现纸质、电子数据的采集,非结构化、半结构化数据经过清洗形成结构化数据并存储[9]。对结构化数据进行分析,形成风、雨、雪、异物侵限监测、报警及设备类型、故障类型等多维度数据,通过多维度数据的挖掘,实现灾害监测系统联调联试数据期望目标可视化展示。联调联试数据挖掘流程见图5。
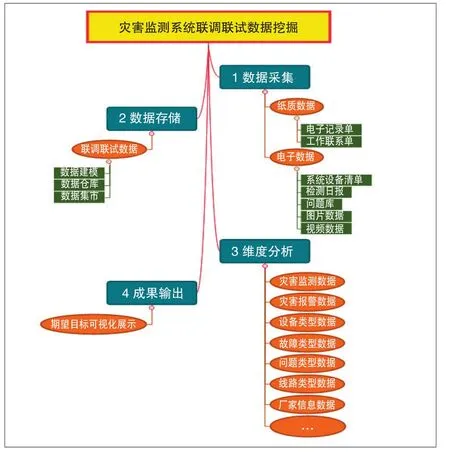
图5 联调联试数据挖掘流程
2.6 期望目标
通过对灾害监测系统联调联试数据进行清洗、分析、挖掘,从中识别出有效的、潜在的、有价值的数据,为辅助决策、运维管理、测点优化、科学研究、厂家评价等提供数据支撑[10]。
(1)辅助决策。统计分析全路风速风向、雨量、雪深及异物侵限监测现场采集设备的种类、品牌、数量、年限;统计分析全路服务器、网络设备、存储设备的种类、品牌、数量、年限及CPU、内存、硬盘配置信息;统计分析全路应用系统、操作系统、数据库种类、版本信息,为相关决策人员提供设备选型、系统优化、设备检定等参考数据。
(2)运维管理。统计分析不同线路风速风向、雨量、雪深及异物侵限监测现场采集设备的种类、品牌、数量、年限;统计分析不同线路服务器、网络设备、存储设备的种类、品牌、数量、年限及CPU、内存、硬盘配置信息,为铁路局集团公司工务、通信、信息相关部门设备更换、检定、检查提供参考数据。
(3)测点优化。统计分析全路各测试场景、测试项目出现问题的数量和频率;统计分析不同线路、不同厂家、不同版本系统出现问题的规律、趋势,为联调联试检测项目的细化、增减及测试设备研制提供参考数据。
(4)科学研究。统计分析全路不同线路风速风向、雨量、雪深、异物侵限监测点的数量和现场采集设备的种类、品牌、数量、年限;统计分析全路服务器、网络设备、存储设备的种类、品牌、数量、年限及CPU、内存、硬盘配置信息;统计分析不同地区、不同线路相关监测点设置情况,为科研人员课题研究提供参考数据。
(5)厂家评价。统计分析同年度相同数量的线路不同厂家出现问题的数量;统计分析同一厂家不同版本系统、同一厂家不同线路出现问题的趋势;统计分析同一厂家不同测试场景、不同测试项目发生问题的频率,为设备厂家系统研发提供评价参考数据。
3 成果应用
(1)辅助决策方面,通过对灾害监测系统联调联试数据的分析、挖掘,可对全路现场采集设备的种类、型号、年限,服务器、网络设备主要配置信息,灾害监测系统的功能、性能实现及存在问题等进行统计、分析和展示。决策管理层可根据设备类型、故障类型、问题数量等系统整体信息,指导新建铁路灾害监测系统,并在运营维护方面完善管理办法。2008—2017年全路灾害监测系统现场采集设备类型、品牌、型号及异物侵限监测设备类型的统计分析见图6。

图6 2008—2017年全路灾害监测系统相关设备统计
(2)运维管理方面,针对已开通线路,可按照不同铁路局集团公司、不同年限,对传感器类型、型号、品牌,异物监测电网安装类型,监控数据处理设备,设备使用年限等进行统计分析。铁路局集团公司通过掌握本局管辖线路设备类型、使用年限、故障类型等信息,可明确运维管理工作重点,从而制定更加合理的运行维护、设备更换、系统升级等实施计划。中国铁路广州局集团有限公司监控数据处理设备类型、服务器品牌、数据库软件等统计见图7。

图7 中国铁路广州局集团有限公司监控数据处理设备信息统计
(3)测点优化方面,通过对检测问题的挖掘,输出不同年限、铁路局集团公司、设备厂家及具体检测场景、检测项目、问题类型统计结果。检测单位可依据故障类型、发现问题等统计信息,优化、改进联调联试检测项目,并为测试手段、方法的完善提供参考。不同年限、项目在联调联试过程中发现问题的统计见图8。

图8 联调联试发现问题统计
(4)科学研究方面,灾害监测系统相关设备类型、品牌、型号、数量、检测问题及不同铁路局集团公司、不同地区现场采集设备应用情况等数据的统计分析成果,可为科研课题提供有效数据支撑。科研单位利用灾害监测、灾害报警、状态监测等统计数据,可开展灾害监测系统优化研究工作,并为相关标准的制定及完善提供参考。风、雨量、雪深、异物侵限监测等现场采集设备相关信息统计见图9。
(5)厂家评价方面,灾害监测系统设备厂家较多,利用设备厂家检测问题总数及每年、每条线检测问题数量,实现对设备厂家的排序及评价(见图10)。设备厂家可根据灾害监测、报警及设备状态监测等方面问题变化趋势的统计信息,掌握设备的短板,制定更好的产品研发、优化方向。
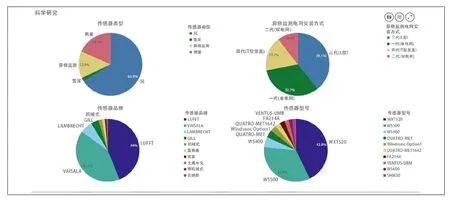
图9 现场采集设备相关信息统计

图10 设备厂家检测问题统计及评价
4 结束语
高速铁路灾害监测系统积累了大量联调联试数据,是铁路宝贵的数据资源。大数据技术在联调联试数据中的应用,对于灾害监测系统发展及联调联试工作持续改进至关重要。基于大数据技术,对灾害监测系统联调联试数据进行挖掘研究,可为高速铁路其他专业联调联试提供参考,使大数据技术更好地为高速铁路发展服务。
