骨导语音库的建立与骨气导语音的互信息分析
2019-07-19邢益搏张雄伟郑昌艳曹铁勇
邢益搏,张雄伟,郑昌艳,曹铁勇
骨导语音库的建立与骨气导语音的互信息分析
邢益搏,张雄伟,郑昌艳,曹铁勇
(陆军工程大学指挥控制工程学院,江苏南京 210007)
首先设计了适用于骨导语音增强的语料采集方案,采集了1 320句涵盖音节全面的语料,并制定了相应的录音规范;其次介绍了骨导语音库建立的意义,说明了语音库建立的实施方案,建成了由40个说话人录制的包括气导语音和骨导语音各8 000句的语音库;然后在对比骨导语音与气导语音声学特性的基础上,分析了骨气导语音在高频和低频的互信息量,为骨导语音的增强提供了理论依据;最后基于现阶段的研究及文中构建的语音库对今后的研究做出展望。
骨导语音;语音库;互信息分析;语音增强
0 引言
语音是人与人之间最方便自然的交流方式,如何确保在强噪声等复杂环境下进行有效的通信是一个十分重要的研究课题。骨导语音是通过在人的发声部位采集发声器官的振动而得到,对噪声具有很强的鲁棒性[1-5]。在背景噪声格外强烈等极端复杂的环境下可以采集到信噪比较高的语音。
骨导语音的这一特性使得其在公安、消防以及军事等方面有着重要的应用。但是,与气导语音相比,骨导语音存在着低频成分厚重、高频成分衰减严重、声音沉闷等缺陷,导致语音的可懂度较低。针对这一问题,国内外很多专家学者开展了广泛的研究。
语音库的建立在语音处理技术的研究和发展过程中起着基础性的作用,是进行研究的数据支撑。目前,已经有大量数据库广泛应用于语音识别、语噪分离和语音增强等方面的研究,如Timit语音数据库[6]、Noise92噪声数据库[7]以及南京大学、东南大学构建的耳语音数据库[8-9]等。但是目前仍未发现公开的骨导语音数据库。
本文建立了一个由汉语常用语构成的包含气导语音和骨导语音的语音库,为研究骨导语音的声学特性及其增强技术提供了数据支撑。
1 研究背景及现状
目前,国内外对骨导语音的研究已取得一定的成果,并基于各自的研究内容建成了小规模骨导语音库。文献[2]中建立了一个包含100个日语单词和45个日语常用短语的语音库,由2名女性和8名男性在无噪声环境下录制完成;文献[10]录制了2个长句、3个短句和5个元音构成的实验数据,由2名男性和2名女性录制完成;文献[11]使用的语音库包括日语、英语以及越南语等3个数据集,每个数据集都有5~10名说话人参与录制,采集到的数据具有多样性,但是数据集涉及的语料内容较少;文献[12]采集6名说话人的骨导语音和气导语音进行研究,每名说话人进行50个日语词组的录制,语料考虑了音节的多样性与发音的均衡性。上述数据库较好地满足了研究需要,但尚存在规模较小、涵盖的音节不够全面等不足,且到目前为止,国内外未发现公开的汉语骨导语音库。
为了汉语骨导语音研究的需要,本文建立了一个由20名男性和20名女性,共40名说话人同步录制的骨导语音和气导语音构成的汉语语音库,每名说话人对分配到的200句语料进行录制。最终得到的语音库语料涵盖音节全面,说话人样本广泛,可满足骨导语音相关研究的基本需求。
2 骨导语音库的建立
基于现有的语音库建库规范,参考文献[8]中耳语音情感数据库的制作过程,本文设计了语音库的制作流程,如图1所示。

图1 语音库建立过程的流程图
2.1 语音库制作规范
语音库的制作规范包括发音人规范、语料规范、录音规范、数据存储规范、标注规范以及法律声明等。具体规范要求如表1所示。
2.2 语音库的整体规划
考虑到骨导麦克风主要应用于公安、消防、军事以及极限运动等场合,在语音库建立时,选择年龄分布在20~40岁的说话人进行录音。
考虑到语音库中语料对于音节覆盖的全面性、多样性、语料的重复以及训练和测试数据的划分等有较高的要求,以确保最终的语音库能够包含每个音素以及不同韵律的语句并能合适地划分,因此,我们主要从日常生活用语、新闻以及报刊杂志中精选了1 320句语料并对其进行编号,针对“特定说话人”和“特定说话内容”两个方面进行语料的分配和数据集的设计。最终建成的语音库分为两个数据集,语料的具体分配原则如表2及表3所示。

表1 骨导语音库建立规范

表2 数据集1分配方式

表3 数据集2分配方式
表2和表3中的测试集1和测试集2的语料内容及分配方式完全相同。利用数据集1中的语音数据,可以对特定说话人的骨导语音进行研究;利用数据集2中的数据,可以对语料涉及到的特定说话内容骨导语音进行研究。
2.3 语音录制
为保证骨导语音与气导语音录制标准相同并且能够同步采集,避免引入不必要的干扰因素,采用同一台电脑进行录制。采用以下录制设备:笔记本电脑1台、骨导麦克风1个、高保真麦克风1个以及一分二音频转换头等。录音软件采用Cool Edit pro 2.0软件,录音时采用双声道(左声道为骨导语音、右声道为气导语音)录制、16位存储格式、32 kHz采样频率,左右声道同步采集,录制的语音保存为wav格式。
参考气导语音库建立的录制环境和注意事项,考虑到骨导语音设备的特殊声学特性,骨导语音录制时需注意以下几点:
(1) 每次录音前,为避免录制的语音出现声音过大或声音过小的问题,需要根据不同说话人的发音习惯对麦克风采集的声音大小进行调整;
(2) 需要消声室进行录制以保持较高的信噪比;
(3) 骨导语音与气导语音同步采集;
(4) 在录音过程中,说话人尽量避免移动,以免混入由麦克风摩擦产生的噪声;
(5) 说话人朗读语句时,尽量保持声音高低一致,声音大小不能有明显起伏;
(6) 录制时,骨导传感器需按要求佩戴,与皮肤紧密接触,保证传感器佩戴在震动最大部位,确保声音被正确采集。
录制的具体方式如图2所示。

图2 语音采集示意图
Fig.2 Schematic diagram of speech acquisition
2.4 语音切分及标注
在对语音进行标注之前需要对采集的语音进行切分,使得语音库中的最小单位是一个完整的句子。由于骨导语音的辅音、气音以及摩擦音等成分的丢失,不能够将需要的语音准确切分出来,因此,切分语音时,以气导语音为参照,将骨导语音按照气导语音切分的时间点进行切分,以得到较为精确的切分结果。
语音切分完毕后进行录制语句的标注,即对每句语音给出采集方式、说话人编号和句子编号。如编号为1的男性对编号为10的语料录制得到的语音分别标注为AC-M1-10和BC-M1-10,其中AC和BC分别代表气导语音和骨导语音。。
2.5 语音库建成
最终建成的语音库包含骨导语音和气导语音各8 000句,由20名男性和20名女性按照表2和表3的语料分配方式进行录制。语音库中语句的具体分布如表4所示。
3 骨导语音与气导语音的比较
3.1 声学特性比较
本节利用建立的语音库,对同一句语料的骨导语音与气导语音进行分析对比。

表4 最终语音数据库
图3是同一语料的骨导语音与气导语音的语谱图,语料内容为“人人拥护安全措施”,其中,图3(a)为气导语音,图3(b)为骨导语音。从频率轴观察可知,在中频以及低频部分,骨导语音频率成分厚重,在高频部分骨导语音的衰减较为严重;从时间轴观测可以看出,在摩擦音以及辅音等声带震动较小的部分,骨导语音存在明显的缺失。

图3 气导语音与骨导语音的语谱图对比
图4所示的是两者的时域波形、短时能量和短时过零率。从图4中可以看出,骨导语音的短时能量在喉部振动强烈的音节(“拥护”)能量较高,在震动较弱的音节(“人”“施”)能量较低;骨导语音的短时过零率整体较低,气导语音中清音部分(“措施”)过零率较高。
3.2 互信息分析
骨导语音的低频成分厚重且高频成分衰减严重,这导致骨导语音的可懂度较低且声音沉闷,但仍可以听懂语音包含的字词信息。本文分别分析纯净气导语音与骨导语音以及纯净气导语音与带噪气导语音的低频成份之间和低频与高频成份之间的互信息量,其中带噪声的气导(简称:带噪气导)语音由录制的纯净气导语音与噪声混合得到,通过对比可对骨导语音的质量相较于带噪气导语音的质量有更为直观的理解,为低信噪比下利用骨导语音实现语音增强提供理论依。

图4 气导语音与骨导语音的特征比较
结合信息论等相关知识,下面我们选取6名说话人(3名男性和3名女性)的语音数据,对其骨导语音与气导语音各个频率分量所包含的互信息量进行分析。
3.2.1 互信息量计算
文献[13-14]给出了一种估计语音互信息量的方法。梅尔频率倒谱系数(Mel-Frequency Ceptral Coefficients, MFCC)[15]经常用来进行语音识别相关的研究,通常用其表示与语音内容相关的信息,因此,计算互信息量时以MFCC的概率分布为基础。
实验将语音信号的高频部分和低频部分看作独立的两段语音,并提取出骨导与气导的低频语音(0~2 kHz)和高频语音(2~4 kHz)的MFCC,利用高斯混合模型对其建模,分别得到高频、低频的概率密度函数以及两者的联合概率密度函数,表示为
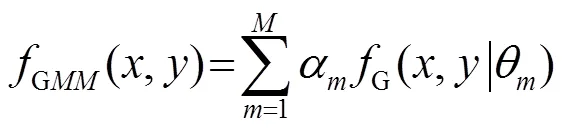


通过式(1)、(2)可以分别计算骨导语音与气导语音的各个频率成分之间包含的信息量。
3.2.2 仿真及结果
对骨导语音与气导语音的互信息量进行计算可以对录制的骨导语音质量有较为直观的了解,同时也可以为骨导语音的增强提供理论上的支撑。
实验选取了4名男声和4名女声共8名说话人的数据,对骨导语音与纯净的气导语音以及带噪的气导语音与纯净气导语音包含的互信息量进行对比分析。随机抽取每名说话人训练集和测试集的各一半数据共100句话,并将噪声按照不同的信噪比与气导语音混合得到带噪的气导语音进行实验,信噪比从-5 dB增加到30 dB,以5 dB递增。由于白噪声覆盖整个频带,对于信息量的估计不具有偏好,实验选用白噪声进行混合。
图5给出了0、5、10 dB和15 dB四种信噪比下骨导语音与纯净的气导语音、带噪气导语音与纯净的气导语音在低频部分之间的互信息量。从图5中可以看出,在高信噪比条件下(15 dB),带噪的气导语音与纯净语音有较高的互信息;在信噪比较低的情况下(信噪比低于10 dB),骨导语音由于未被噪声所干扰,与纯净的气导语音互信息较高。从图 5在不同信噪比下的互信息量趋势可以预测到,信噪比更低时,带噪的气导语音与纯净气导语音包含的互信息量会更低。

图5 低频骨导和气导语音之间的互信息量
图6所示的是带噪气导语音的低频成分和纯净的气导语音的高频成分以及骨导语音的低频成分和纯净气导语音的高频成分之间的互信息,信噪比分别为10、15、20 dB和25 dB。从图6中可以看出,在20 dB时,骨导语音的低频与纯净气导语音高频的互信息量就超过了带噪的气导语音;在信噪比更低时,气导语音混入了更多的噪声,导致互信息量更低,而骨导语音不受影响。
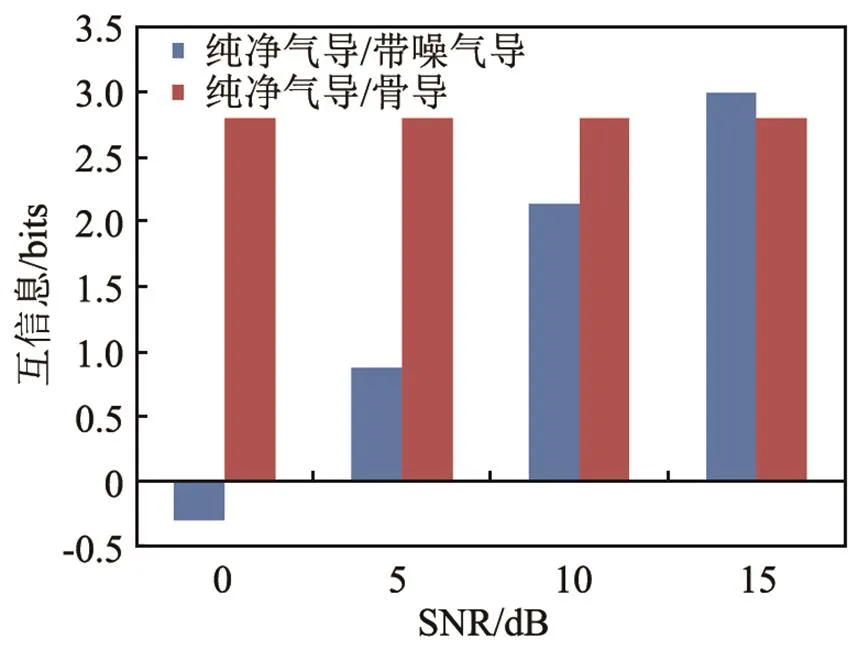
图6 高低频骨导和气导语音之间的互信息量
Fig.6 Mutual information contents between high frequency pure air-conducted speech and low frequency noisy air-conducted speech(blue) and between low frequency bone-conducted speech and high frequency noisy air-conducted speech (brown)
4 结束语
基于骨导语音处理研究的需要,本文精选了1 320句音节均衡的汉语语料,并以此为基础构建了包含骨导语音与气导语音各8 000句的语音数据库。在对骨导语音与气导语音的声学特性和互信息量进行分析后,得出骨导语音与气导语音包含较高的互信息量这一结论,为骨导语音增强提供了理论依据。
[1] SHIN H S, KANG H G, FINGSCHEIDT T. Survey of speech enhancement supported by a bone conduction microphone[C]// Speech Communication; 10. ITG Symposium; Proceedings of. VDE, 2012: 1-4.
[2] YU J N, ZHANG L Y, ZHOU Z. A novel voice collection scheme based on bone-conduction[C]//IEEE International Symposium on Communications and Information Technology. 2005: 1164-1168.
[3] OKAMOTO Y, NAKAGAWA S, FUJIMOTO K, et al. Intelligibility of bone-conducted ultrasonic speech[J]. Hearing Research, 2005, 208(1-2): 107-113.
[4] SHIN H S, FINGSCHEIDT T, KANG H G. A priori snr estimation using air-and bone-conduction microphones[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2015, 23(11): 2015-2025.
[5] RAHMAN M S, SHIMAMURA T. Pitch characteristics of bone-conducted speech[C]// IEEE, Signal Processing Conference, 2010, European. 2010: 795-799.
[6] ZUE V, SENEFF S, GLASS J. Speech database development at MIT: TIMIT and beyond[J]. Speech communication, 1990, 9(4): 351-356.
[7] VARGA, STEENEKEN H J. Assessment for automatic speech recognition II: NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition sys-tems[J]. Speech Communication, 1993, 12(3): 247–251.
[8] 金赟, 赵艳, 黄程韦, 等. 耳语音情感数据库的设计与建立[J]. 声学技术, 2010, 29(1): 63-68.
JIN Yun, ZHAO Yan, HUANG Chengwei, et al. The design and establishment of a Chinese whispered speech emotion database[J]. Technical Acoustics, 2010, 29(1): 63-68.
[9] 杨伟. 汉语与汉语耳语的平均频谱的测量与计算[D]. 南京: 南京大学, 2012.
[10] SHIMAMURA T, TAMIYA T. A reconstruction filter for bone-conducted speech[C]//48th Midwest Symposium on Circuits and Systems, 2005. IEEE, 2005: 1847-1850.
[11] VU T T, UNOKI M, AKAGI M. An LP-based blind model for restoring bone-conducted speech[C]//IEEE, Second Interna-tional Conference on Communications and Electronics, 2008: 212-217.
[12] KONDO K, FUJITA T, NAKAGAWA K. On equalization of bone-conducted speech for improved speech quality[C]//IEEE International Symposium on Signal Processing and Information Technology. NJ: IEEE, 2007: 426-431.
[13] BOUSERHAL R E, FALK T H, VOIX J. On the potential for artificial bandwidth extension of bone and tissue conducted speech: a mutual information study[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. NJ: IEEE, 2015: 5108-5112.
[14] BOUSERHAL R E, FALK T H, VOIX J. In-ear microphone speech quality enhancement via adaptive filtering and artificial bandwidth extension[J]. J. Acoust. Soc. Am., 2017, 141(3): 1321- 1331.
[15] 林玮, 杨莉莉, 徐柏龄. 基于修正MFCC 参数汉语耳语音的话者识别[J]. 南京大学学报(自然科学版), 2006, 42(1): 54-62.
LIN Wei, YANG Lili, XU Boling. Speaker identification in Chinese whispered speech based on modified-MFCC[J]. Journal of Nanjing University (Natural Science), 2006, 42(1): 54-62.
Establishment of bone-conducted speech database and mutual information analysis between bone and airconducted speeches
XING Yi-bo, ZHANG Xiong-wei, ZHENG Chang-yan, CAO Tie-yong
(The Army Engineering University of PLA, Institute of Command and Control Engineering, Nanjing 210007, Jiangsu, China)
In this paper, a corpus acquisition scheme suitable for bone-conducted speech enhancement is designed, total 1 320 syllabic balanced sentences of covering comprehensive syllables are collected and a corresponding recording specification is developed. The significance of establishing bone-conducted speech database and the implementation scheme of the database are introduced, and a database containing 8 000 air-conducted and bone-conduced speeches spoken by 40 speakers is constructed. Based on the comparison of acoustic characteristics between air-conducted and bone-conducted speeches, the mutual information contents between bone and air conducted speeches at high and low frequencies are analyzed, which provides a theoretical basis for the enhancement of bone-conducted speech. Finally, based on the current stage of research and combining the database constructed in this paper, the future research direction is prospected.
bone-conducted speech; speech database; mutual information analysis; speech enhancement
TN912
A
1000-3630(2019)-03-0312-05
10.16300/j.cnki.1000-3630.2019.03.013
2018-01-08;
2018-02-20
国家自然科学基金资助项目(61471394、61402519)
邢益搏(1994-), 男, 山西临汾人, 硕士研究生, 研究方向为语音信号处理。
邢益搏,E-mail: 18252059100@163.com
