水稻冠层叶绿素含量高光谱估算模型
2019-07-18武旭梅常庆瑞落莉莉由明明
武旭梅,常庆瑞,落莉莉,由明明
(西北农林科技大学资源环境学院,陕西 杨凌 712100)
叶绿素含量是评价作物生理状态和长势的重要参数[1],对其进行估测可作为评估作物生长发育状况及产量高低的有效手段。目前,国内外已有很多学者借助高光谱遥感技术对不同作物的叶绿素含量进行了估测,尺度包括叶片和冠层,应用的光谱信息包括原始光谱、导数光谱以及由此构造的特征参数、植被指数,均取得了一定的效果[2-9]。水稻是我国的主要粮食作物,对其叶绿素含量的估测亦有很多研究[10-16],但主要集中在南方稻作区。针对北方,特别是西北引黄灌区的研究相对较少,且不同研究者应用的光谱信息均是在特定条件下提取的,建立的估算模型具有地域性和时效性,不能直接用于该区域水稻冠层叶绿素含量的估测,因此有必要进行相关研究。
便携式叶绿素仪SPAD-502采用光电无损检测方法测定植物叶片的叶绿素含量,其测得的SPAD(Soil and Plant Analyzer Development)值与叶绿素含量具有较高相关性,常用于表征叶绿素含量[17-19]。本研究将西北引黄灌区水稻作为研究对象,通过田间试验,观测水稻冠层SPAD与高光谱数据,应用植被指数建立水稻冠层SPAD的高光谱估算模型。通过比较探索,寻求能够高精度反演西北引黄灌区水稻冠层SPAD的遥感模型,从而为实时监测本区水稻生长发育状况提供理论和技术支持。
1 材料与方法
1.1 研究区概况与试验方案
田间试验布设在宁夏回族自治区青铜峡市叶盛镇宁夏农林科学院水稻示范基地(东经106°10′48″,北纬38°7′12″)。该基地属于中温带大陆性干旱气候,年日照时数2 955 h,年平均气温8.3~8.6℃,无霜期176 d,年降水量260.7 mm。
试验共36个小区,每个小区面积为60 m2(10 m×6 m)。各小区均施纯磷、纯钾各90 kg·hm-2作为基肥。试验设置3个氮素水平,即分别施纯氮0、240、300 kg·hm-2;4个碳素水平,即分别施纯碳0、4 500、9 000、13 500 kg·hm-2,共12个组合处理,每个处理重复3次。试验使用的肥料为重过磷酸钙、氯化钾、尿素和稻壳炭。每个小区选择2个样点,分别于2017年7月9日(抽穗期)、8月10日(乳熟期)和9月11日(蜡熟期)进行田间观测。
1.2 测定项目与方法
1.2.1 冠层光谱测定 采用美国SVC公司生产的SVC HR-1024i型便携式非成像全波段地物光谱仪测定。光谱仪波长范围350~2 500 nm,其中350~1 000 nm光谱分辨率≤3.5 nm,1 000~1 850 nm光谱分辨率≤9.5 nm,1 850~2 500 nm光谱分辨率≤6.5 nm;测量时镜头视场角25°,传感器探头垂直朝下,距冠层垂直高度1 m;每测量1个样点均用参考板进行标定。选择天气晴朗无云、风力微弱时测定,时间为10∶00~14∶00。每个样点测定5条光谱曲线,取其平均值作为该样点的光谱反射率。
1.2.2 叶绿素含量测定 对应于测定冠层光谱位置,采用便携式叶绿素仪SPAD-502对光谱仪视场范围内的水稻冠层叶片进行测定,得到10个SPAD数据,取其平均值作为该样点的冠层SPAD。
1.3 数据处理
利用光谱仪自带的处理软件对光谱曲线进行融合、平滑处理。其中,对400~2 400 nm波段的光谱以间隔4 nm进行重采样;利用Excel软件对光谱数据进行一阶导数变换,得到一阶导数光谱数据。
1.4 植被指数的选取
对众多学者研究中用来反演叶绿素含量的植被指数[1-19]进行分析,选取应用最广泛的比值植被指数(ratio vegetation index,RVI)、差值植被指数(difference vegetation index,DVI)、归一化植被指数(normalized difference vegetation index,NDVI)和土壤调节植被指数(soil-adjust vegetation index,SAVI)反演水稻冠层叶绿素含量(表1)。通过任意波段组合的方式,构建基于原始光谱和一阶导数光谱的植被指数,并分别与SPAD进行相关性分析,得到植被指数与SPAD决定系数等值线图。根据决定系数最大的原则,选择最佳波段组合建立植被指数。上述处理过程在MATLAB软件中实现。
1.5 模型构建及精度检验
分别利用普通回归分析方法和随机森林算法构建水稻冠层叶绿素含量估算模型,并进行对比分析。随机森林(Random Forest, RF)是一种基于分类树的机器学习算法,能够在保障模型精度的同时大大降低运算量,功能强大且简单易用[20],算法通过R语言中的randomForest软件包实现。采用决定系数R2、均方根误差RMSE和平均相对误差RE对模型预测值与实测值进行精度检验,RMSE和RE越小模型精度越高。
注:Rλ1、Rλ2分别为两个波长的冠层光谱反射率,Dλ1、Dλ2分别为两个波长的冠层光谱反射率的一阶导数;L为土壤校正参数,本文选取L=0.5。
Note:Rλ1andRλ2refer to the canopy spectral reflectance of 2 wavelengths,Dλ1andDλ2refer to the first derivative of the canopy spectral reflectance with 2 wavelengths, respectively.Lis the soil correction parameter, andL=0.5 is selected in this paper.
2 结果与分析
2.1 水稻冠层SPAD的统计特征
试验共得到216个样点数据,将其随机分为两组,其中144个作为训练样本进行分析与建模,72个作为验证样本对模型精度进行检验,各组样本的SPAD统计特征见表2。从表2中可以看出,训练样本的SPAD在8.1~55.4之间,包含了整体样本的最小值与最大值,区间分布比较合理,变异程度相对较大,在一定意义上保证了所构建的水稻冠层SPAD估算模型的适用范围。验证样本和训练样本的统计特征相似,能够对所建立模型的可靠性进行验证。
2.2 水稻冠层SPAD与光谱的相关性
将水稻冠层SPAD与原始光谱、一阶导数光谱进行相关性分析,结果如图1所示。

表2 水稻冠层SPAD统计特征
由图1可知,水稻冠层SPAD与原始光谱在752~880 nm范围内呈正相关,其余波段呈负相关。其中在400~740、760~812、956~1 000、1 084~2 400 nm波段范围相关性均达到极显著相关水平(99%置信度,n=216),相关性在700 nm处达到最大(R=-0.833)。水稻冠层SPAD与一阶导数光谱的相关系数介于-0.834~0.737之间,在680 nm处达到-0.834。与原始光谱相比,一阶导数光谱与SPAD的相关性在740~760、800~920 nm波段得到显著提高。
2.3 水稻冠层SPAD与植被指数的相关性
采用任意波段组合的方式,运用原始光谱构建植被指数,并分别与SPAD进行相关性分析,得到决定系数R2等值线图(图2)。从图2可以看出,在每个植被指数与SPAD的决定系数等值线图中都存在R2大于0.7的区域,表示由这些波段组合构建的植被指数与SPAD的相关性达到较高水平。与DVI和SAVI相比,RVI和NDVI与SPAD相关性较好的波段组合范围相对较大。RVI的最佳波段组合为RVI(R696,R540),DVI为DVI(R700,R536),NDVI为NDVI(R600,R592),SAVI为SAVI(R700,R536),R2分别为0.838、0.805、0.830、0.831。
采用同样方法构建基于一阶导数光谱的植被指数,得到最佳比值植被指数RVI(D1316,D736)、最佳差值植被指数DVI(D704,D700)、最佳归一化植被指数NDVI(D1228,D752)、最佳土壤调节植被指数SAVI(D704,D700),R2分别为0.843、0.791、0.827、0.791。可见,上述8个植被指数与水稻冠层SPAD的相关性明显高于原始光谱、一阶导数光谱与SPAD的相关性,可以更好地用来建立估算模型。
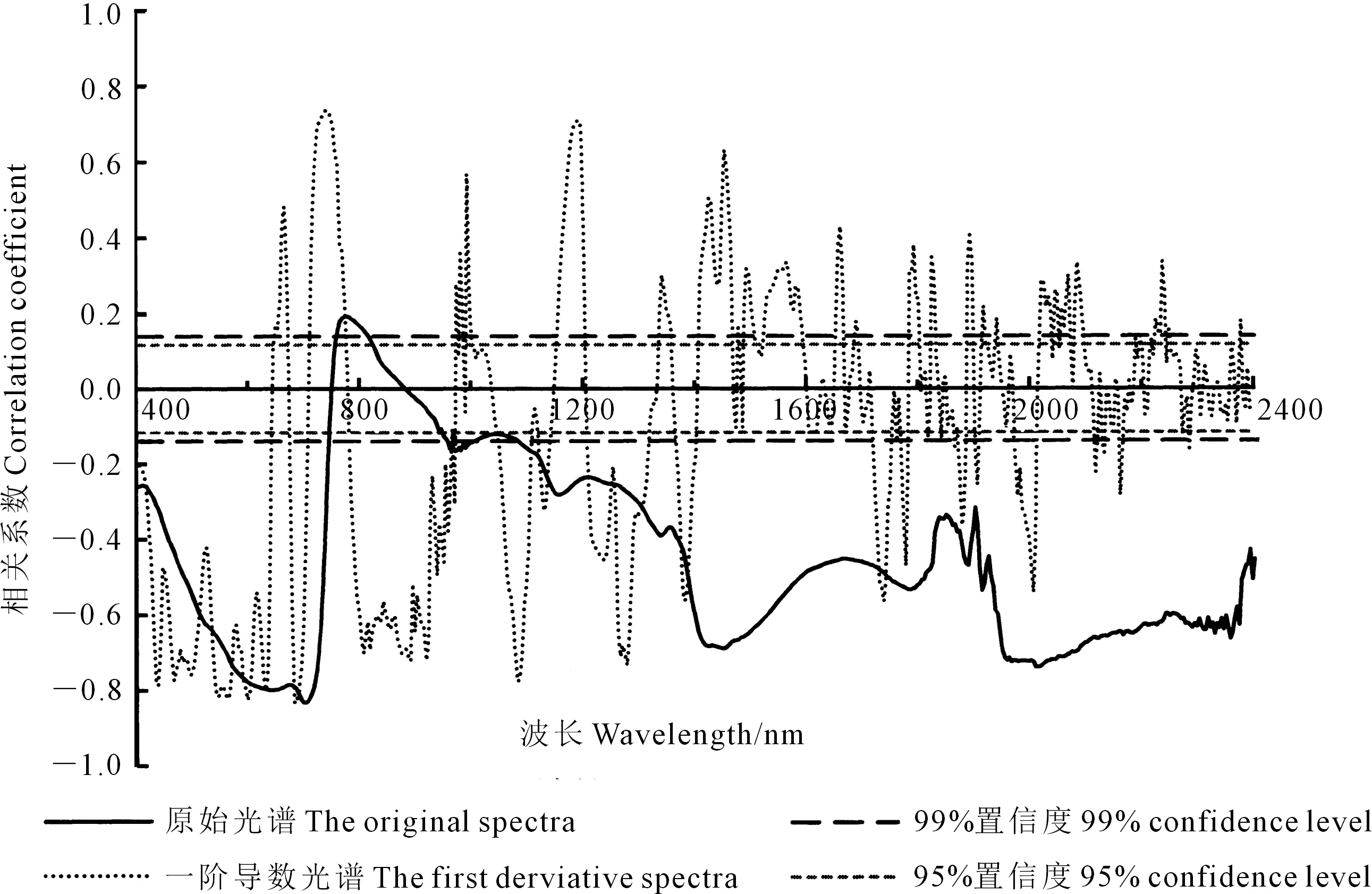
图1 水稻冠层SPAD与原始光谱、一阶导数光谱的相关性Fig.1 Correlation betweenthe original spectra, the first derivative spectra, and SPAD of rice canopy
2.4 水稻冠层SPAD估算模型及精度检验
2.4.1 普通回归估算模型及精度检验 以上述植被指数为自变量,分别与水稻冠层SPAD进行线性函数、指数函数、二次多项式、对数函数、幂函数拟合,构建水稻冠层SPAD的估算模型。通过比较决定系数R2、均方根误差RMSE和平均相对误差RE,得到各植被指数的最佳单变量估算模型(表3)。
由表3可知,不同植被指数的SPAD估算模型均为非线性,主要是由于同时期不同土壤肥力造成水稻植株的明显差异以及不同生育期植株的持续生长带来的变化导致水稻冠层SPAD与植被指数之间呈现非线性变化。8个模型的建模R2介于0.77~0.88,RMSE介于4.2~5.3,RE介于15%~30%;验证R2均在0.69之上,RMSE均低于4.8,RE<21%,模型精度较高。其中以RVI(D1316,D736)为自变量建立的指数模型建模R2最大,建模和验证的RMSE、RE明显低于其他模型,精度最高。对比4种植被指数,以RVI和NDVI为自变量建立的模型略优于DVI和SAVI,其原因可能是水稻在抽穗期和乳熟期的植被覆盖度较高,使DVI和SAVI对冠层SPAD的敏感度下降。

表3 水稻冠层SPAD单变量估算模型
2.4.2 基于随机森林算法的估算模型及精度检验 为了更准确估测水稻冠层SPAD,采用随机森林算法建立估算模型。应用上述8个植被指数为自变量构建模型,得到各自变量的重要性指标(表4),其中精度平均较少值(%IncMSE)和节点不纯度平均减少值(IncNodePurity)越大说明自变量的重要性越强。通过对比,选择重要性最好的4个植被指数RVI(R696,R540)、DVI(R700,R536)、SAVI(R700,R536)、RVI(D1316,D736)建立模型。
在模型构建中,有两个影响模型精度的重要参数决策树(ntree)和分割变量(mtry),需对其进行合理设置。图3是决策树的数目与模型误差的折线图,可以看出,当决策树的数目大于500后,模型误差趋于稳定。理论上,决策树的数目越多,模型的效果就越好,但是计算量也就越大,增加树的数量带来的效果提升程度是递减的。考虑其运算成本,本试验确定随机森林算法中决策树ntree=1000。根据经验及逐一尝试,分割变量mtry设置为2。
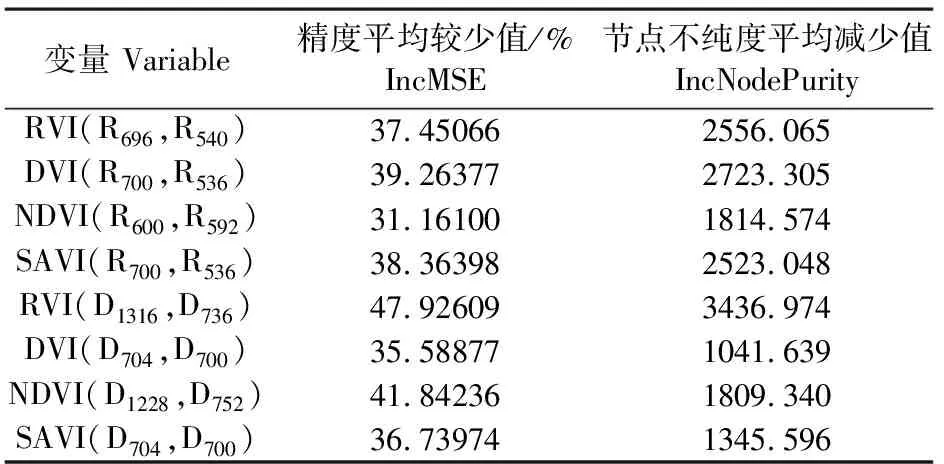
表4 随机森林自变量重要性指标
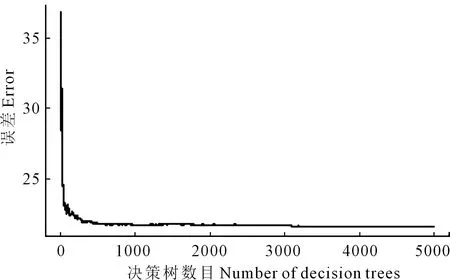
图3 决策树的数目与模型误差折线图Fig.3 Line chart of decision trees and model error
分别对训练样本和验证样本的实测值与模型预测值进行拟合分析,检验所建模型的精度,结果如图4所示。
由图4(a)可见,训练样本点均匀地聚集在1∶1线附近,表明模型预测值与实测值很接近,模型的建模R2达到0.898,RMSE<2.1,RE低于8%。对比表3和图4可知,与普通回归估算模型相比,基于随机森林算法的估算模型建模和验证R2增大,RMSE、RE减小,预测精度得到明显提高,可以实现水稻冠层SPAD的精准估测。
3 结论与讨论
本研究通过田间试验获取了西北引黄灌区水稻的冠层光谱和SPAD数据,运用任意波段组合的方式构建了一系列基于原始光谱和一阶导数光谱的植被指数RVI、DVI、NDVI和SAVI。通过计算植被指数与SPAD的相关性,筛选出了最优波段组合构建的植被指数作为自变量,利用普通回归分析方法和随机森林算法建立了水稻冠层SPAD估算模型。最后,通过对比分析得到了能够高精度反演西北引黄灌区水稻冠层SPAD的遥感模型,可为实时监测该区域水稻生长发育状况及估产提供理论和技术支持。
相比原始光谱,西北引黄灌区水稻冠层一阶导数光谱在部分波段与SPAD的相关性更强,这与前人研究结果[21]一致。应用普通回归分析方法,以RVI(D1316,D736)为自变量建立的指数模型是估算西北引黄灌区水稻冠层SPAD的最佳单变量模型。采用随机森林算法,以4个植被指数RVI(R696,R540)、DVI(R700,R536)、SAVI(R700,R536)、RVI(D1316,D736)建立的估算模型比普通回归模型预测精度更高,可作为反演西北引黄灌区水稻冠层SPAD的最佳模型。但随机森林算法计算量大,在实际应用中对软硬件要求都比较高。相对而言,基于单变量的普通回归分析方法参数单一,计算方式简单,在对精度要求不是很高的情况下可以直接用于西北引黄灌区水稻的实际监测。

图4 基于随机森林算法的水稻冠层SPAD估算模型检验Fig.4 Accuracy verification of rice canopy SPAD estimation model based on random forest algorithm
本研究建立的模型与以往学者针对南方稻田得到的研究结果[15-16]有所差异,原因在于水稻冠层光谱受光照条件、冠层结构和土壤、水体等复杂情况的影响产生很大差异,由此建立的模型不能统一。针对西北引黄灌区水稻冠层叶绿素含量的估测,秦占飞等[19]应用了红边参数,本研究应用植被指数亦取得了很好的效果。但受天气条件限制,本研究仅在水稻抽穗期、乳熟期、蜡熟期进行了采样,模型的可靠性和普适性尚需进一步验证。用更多的数据、更科学的建模方法建立可通用的水稻冠层叶绿素含量估测模型将是未来研究工作的重点。
