反馈式K近邻语义迁移学习的领域命名实体识别
2019-07-16朱艳辉李飞冀相冰曾志高徐啸
朱艳辉,李飞,冀相冰,曾志高,徐啸
(1. 湖南工业大学 计算机学院,湖南 株洲 412008; 2. 湖南省智能信息感知及处理技术重点实验室,湖南 株洲412008)
命名实体识别(named entity recognition,NER)作为信息抽取的子任务,是指将非结构化文本中具有特定意义的实体抽取出来,对文本的结构化起着至关重要的作用。由于其在自然语言处理中的重要地位,许多国际会议,如MUC-6、MUC-7、Conll2002等,都将命名实体识别作为共享任务(share tasks)。国内会议诸如全国语义网与知识图谱计算大会(CCKS 2017),也组织了医疗实体识别的评测任务。传统命名实体识别采用最大熵、隐马尔科夫模型、支持向量机、条件随机场等方法,但传统机器学习方法需要人工定义特征模板,并且无法充分获取隐含信息,对文本长距离依赖关系难以捕捉。随着深度学习的快速发展以及卷积神经网络 (convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、长短期记忆网络(long short-term memory ,LSTM)等学习算法的提出,命名实体识别任务在获取隐含信息及捕捉长距离文字依赖关系上取得了长足的进步。命名实体识别是典型的序列标注任务,RNN可以很好地克服传统机器学习的文本长依赖信息难以获取的缺点[1],具有一定的记忆功能,但RNN在训练算法时存在梯度弥散和梯度爆炸问题。因此,Hochreiter等[2]提出了LSTM方法,LSTM是一种特殊的循环神经网络,能够学习到长期依赖关系,以解决RNN梯度消失和梯度爆炸的问题。Yoon[3]首次将CNN应用到自然语言处理领域并获得成功后,由于其可以利用窗口滑动,可以很好地解决词之间的组合特征及一部分依赖问题,故广泛的应用在自然语言处理领域。张海楠等[4]提出了一种用于深度学习框架的字词联合方法,结合字词特征,提高了系统性能,最终取得了较好的F1值。Ma等[5]提出了基于LSTMCNN-CRFs的端对端序列标注方法,该模型无需数据预处理和特征选择,在Conll2003语料库上F1值为91.21%。Chiu等[6]提出了BiLSTM-CNNs的新型网络框架,在Conll2003语料库取得F1值为91.61%的成绩。姚霖等[7]提出一种基于词边界字向量的中文命名实体识别方法,在Sighan Bakeoff-3语料中取得了F1值89.18%的效果,上述文献证明了深度学习神经网络用于序列标注任务的可行性和有效性。
迁移学习[8]是运用已有知识对不同但是相关领域问题进行求解的一种新的机器学习方法。其放宽了传统机器学习的两个基本假设,通过减小源域与目标域的数据分布差异,从而从已有的知识中解决目标领域中仅有少量或没有标签样本数据的学习问题。Pan等[9]提出了著名的迁移成分分析 (transfer component analysis,TCA)方法,针对域适配(domain adaptation)问题中源域和目标域处于不同数据分布,将2个领域的数据一起映射到一个高维的再生核希尔伯特空间,并在此空间中最小化源和目标的数据距离,同时最大程度地保留它们各自的内部属性。Long等[10]在TCA基础上提出了联合分布适配方法(joint distribution adaptation ,JDA),在源域和目标域条件分布不同的基础上,提出了联合分布适配方法,同时适配源域和目标域的边缘分布和条件分布,在4种类型的跨域图像分类任务上取得了较好的效果。卞则康等[11]提出一种基于相似度学习的多源域迁移SL-MSTL算法,增加对多源域与目标域之间的相似度学习,可以有效地利用各源域中的有用信息。庄福振[12]介绍了迁移学习研究进展,并且针对迁移学习领域所做的工作和未来的方向做了总结和展望。
目前,已有命名实体识别方法在通用领域的人名、地名、组织机构名上取得了较好的效果。然而专业领域由于语料匮乏,导致领域命名实体识别进展缓慢且识别效果差强人意。因此,本文针对专业领域语料匮乏、标注语料缺失等特点,引入迁移学习技术,构建基于深度学习的BiLSTM-CNN-CRFs网络模型,提出一种反馈式K近邻语义迁移学习的领域命名实体识别算法。首先,对专业领域语料和通用领域语料分别训练得到语料文档向量,使用马哈拉诺比斯距离计算领域语料与通用语料的语义相似性,针对每个专业领域样本分别取K个语义最相似的通用领域样本进行语义迁移学习,构建N个迁移语料集。然后,使用BiLSTM-CNN-CRFs网络模型对N个迁移语料集进行领域命名实体识别,并对识别结果进行评估和前馈,根据反馈结果选取合适的K值,作为语义迁移学习的最佳阈值。实验结果表明,K近邻语义迁移学习算法取得了较好的结果,可以有效解决专业领域语料匮乏问题。
1 深度学习BiLSTM-CNN-CRFs网络模型构建
本文利用CNN的词组合特点和LSTM的长期依赖关系,结合CRF作为解码输出,构建一种基于深度学习的BiLSTM-CNN-CRFs网络模型,作为命名实体识别的学习算法。首先对文本的字训练词向量,将词向量输入到CNN层,得到窗口词组合特征,再进一步输入到LSTM层,LSTM选取分数最高的标签作为输出。但LSTM默认词之间是独立分布的,并未考虑相邻词之间的相关性及其约束性,对于序列标注任务,相邻词之间的标签相关性直接影响句子的最佳标签链,所以在输出层使用条件随机场(CRF)进行联合建模以解码标签序列。
1.1 词向量
自然语言理解的问题首先要转化成机器能够处理的问题,词向量[13](word Embedding)提供了一种将文本表达映射到低维向量空间的方法,词向量解决了传统稀疏表示的“词汇沟鸿”缺点,通过将词汇映射到一个新的低维空间,解决了维数灾难问题,并且可以挖掘到词汇之间的关联属性,提高向量语义的准确度。针对专业领域语料容易出现分词不准确,从而导致实体被错分出现无法识别的问题,本文不直接进行分词,采取训练字符级别的词向量方法,词向量形式如下:
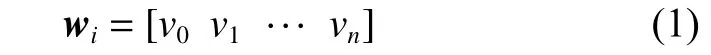
1.2 CNN层
卷积神经网络(CNN)通常用于字符级信息建模等自然语言处理任务,本文使用CNN对输入字的词向量利用窗口滑动将当前字与前后汉字连接,计算前后字对当前字的影响,所生成的词表示词语特征。本文以“中国包装网讯”一词为例,其CNN层结构如图1所示。卷积完成后提取出字符与字符之间的上下文信息,生成词语和句子表示特征,再输入到下层神经网络中。
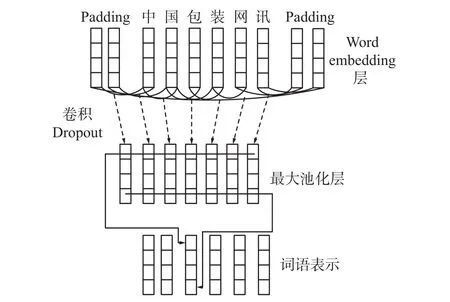
图 1 CNN层结构示意图Fig. 1 CNN layer structure diagram
1.3 LSTM层与CRF层
LSTM是一种特殊的循环神经网络(RNN),一个LSTM单元是由一个cell和输入门(input)、输出门(output)、遗忘门(forget)组成。LSTM自提出后,很多研究人员针对LSTM做了一系列优化改进工作,现已被应用于自然语言处理领域的各个方面。LSTM的特性使得其只能获取到本单元之前的所有单元的信息,但是无法获取此单元后的所有单元信息,因此双向LSTM(bi-directional LSTM,BiLSTM)应运而生,其基本思想是将每个序列向前和向后呈现为两个单独的隐藏状态,分别捕获过去和未来的信息,然后将两个隐藏状态链接形成最终输出。BiLSTM相较于LSTM识别效果更好,故本文使用BiLSTM作为一层网络。由于BiLSTM仅对于标签之间的独立任务(如词性标注)识别效果较好,而命名实体识别标签则是互相关联的,故考虑在BiLSTM输出层加入CRF层以增加约束,进行联合解码标签序列。
假设一个序列“中国包装网讯”及其序列标注如表1所示。
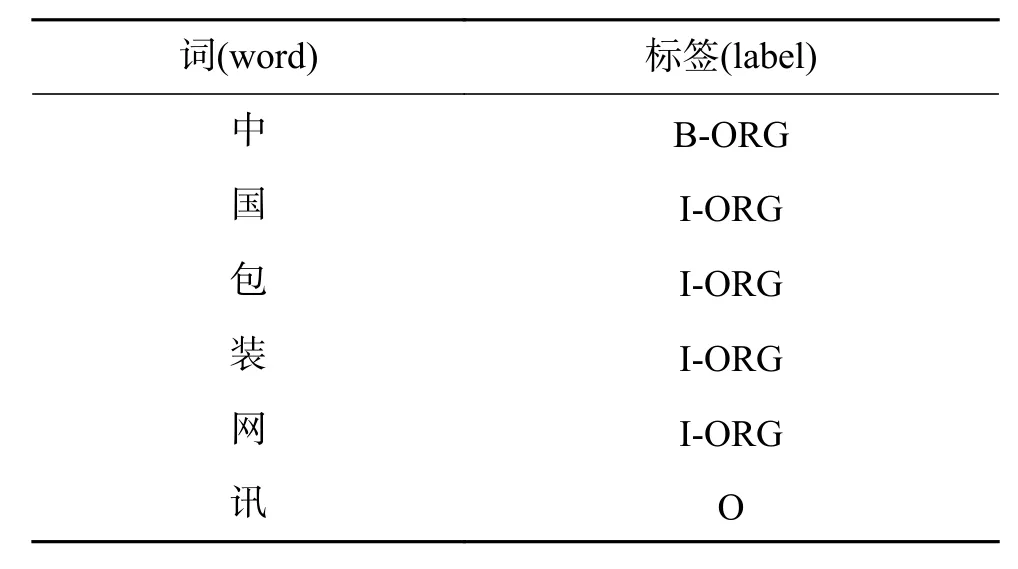
表 1 词序列及其标注Table 1 Word sequence and its annotation
将以上词序列的词向量输入BiLSTM-CRFs网络,假设以上词序列的词向量为:
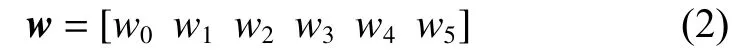
将式(2)作为BiLSTM-CRFs的输入,如图2所示。
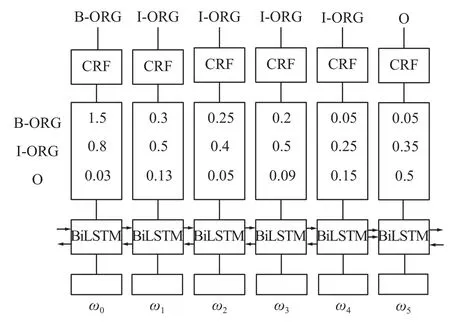
图 2 BiLSTM-CRFs网络结构Fig. 2 BiLSTM-CRFs network structure diagram
1.4 基于深度学习的BiLSTM-CNN-CRFs网络模型
本文构建的用于领域命名实体识别的基于深度学习的BiLSTM-CNN-CRFs网络模型如图3所示。对于一个句子序列,将每个字的词向量输入到CNN网络中,并在使用时对词向量进行微调(fine tuning),采用CNN的窗口滑动功能得到词表示向量,然后将词表示向量与字的词向量馈送至BiLSTM网络中,学习到句子序列标签的最高得分(虚线表示引入Dropout层防止数据过拟合)。最后BiLSTM输出的向量再馈送至CRF层,CRF通过从训练语料中自学习得到约束,对BiLSTM中的输出向量进行联合标签解码。在卷积过程和BiLSTM预测过程中引入Dropout技术以防止过拟合现象。
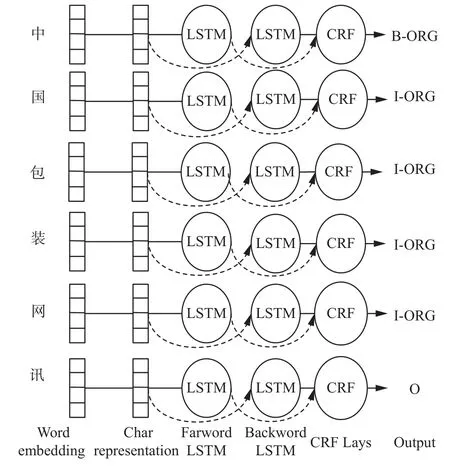
图 3 基于深度学习的BiLSTM-CNN-CRFs网络模型Fig. 3 BiLSTM-CNN-CRFs network model based on deep learning
2 反馈式K近邻语义迁移学习算法
2.1 问题描述
传统机器学习假设训练数据与测试数据满足数据同分布,然而现实中的大量数据并不满足这种同分布假设。随着深度学习的发展,对数据量的要求不断增大,现实中很难获取到如此大量的同分布数据集。在此背景下,迁移学习的提出,为数据量不足的问题提供了新的解决思路。迁移学习可以利用已有的数据迁移知识,用于帮助目标域中的学习问题。针对特定领域,虽然随着计算机的普及与发展已产生大量的非结构化文本,但这些语料并未标注,导致专业领域文本训练语料严重缺乏。而随着互联网行业与移动互联网的发展,互联网上产生了海量的通用领域新闻文本,且形成了成熟的标注语料库。而通用领域新闻文本与专业领域新闻文本同属新闻语料,彼此具有一定的相似性和数据同分布性,这为我们提供了解决特定领域文本严重不足的思路。
为了解决领域训练语料严重缺乏的现实,本文应用迁移学习方法从通用新闻语料中得到与专业领域语料语义正相关的数据以扩充领域语料集。应用迁移学习技术解决专业领域语料不足的问题,面临的主要挑战如下:1)如何表达通用新闻数据中的知识,以适配专业领域样本语义中的知识与分布,从而达到迁移目的;2)在解决1)中问题的基础上,如何衡量通用新闻语料与领域新闻语料的相似性;3)对于迁移的标准与质量应该如何度量,何时达到迁移阈值,停止迁移,防止“负迁移”出现。
针对上述挑战,本文提出一种反馈式K近邻语义迁移学习(feedback K-Nearest-neighbor semantic transfer learning,F-KNST)算法,并采用 BiLSTM-CNN-CRFs深度学习网络模型,对领域实体进行识别,其流程如图4所示。针对1),本文选用文档向量(Doc2Vec)衡量通用新闻语料与领域语料的语义差异性。Doc2Vec[14]是由Quoc Le 和Tomas Mikolov在Word2Vec的基础上提出的,文档向量充分利用了词向量和段落向量(paragraphs vectors),可以很好地预测文档之间的语义相似性。针对2),本文提出一种使用马哈拉诺比斯距离[15](马氏距离)的语义距离度量方法。传统欧氏距离存在无法结合先验知识、同等看待样本等局限性,在实际应用中常无法满足需求。马氏距离是由印度统计学家马哈拉诺比斯提出的,表示数据的协方差距离,它是一种有效的计算2个未知样本集的相似度的方法,其协方差特性不仅可以结合数据的统计特性,还能兼顾到样本的相关性。杨绪兵等[16]已经通过证明和相关实验验证了马氏距离相对于欧氏距离的优越性。针对3),提出F-KNST算法,从1)和2)中得到通用新闻语料与领域语料的语义向量距离作为迁移标准,从通用新闻语料中获取K个与每篇特定领域语料最相近的文本,从而达到扩充领域语料集的目的。将扩充的语料集送入1.4节所述网络模型中进行实体识别,由实体识别结果作为反馈不断修正K值,从而实现最佳迁移标准与质量。
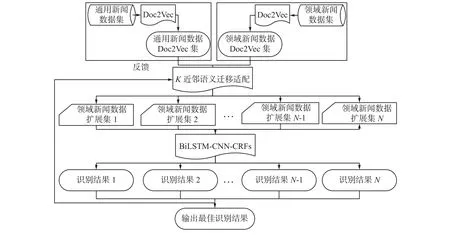
图 4 反馈式K近邻语义迁移学习的领域命名实体识别流程Fig. 4 F-KNST domain named entity recognition flowchart
2.2 F-KNST算法实现
通用新闻数据集(以下称源域)中存在许多可以迁移到特定领域新闻数据集(以下称目标域)的知识。由于目标域除了行业名词之外,与源域数据格式、报道措辞均相差不大,数据分布基本满足独立同分布。因此,从源域中获取与目标域中语义相近的新闻语料以填充目标域可以更加丰富目标域中数据分布特点,扩充目标域中语义特征,使目标域在后续预训练和训练过程中获取到足够的语义信息及类实体特征。
1)马氏距离定义
设随机向量x∈Rn,来自分布X(XRn),E∈Rn与 Σ∈Rn×n分别表示的期望和协方差,是的一组观测值,并且满足独立同分布条件。
定义1设为空间Rn的一个维向量,Σ是分布X的协方差,则称
定义2在M范数定义下,若,则马氏距离定义为:
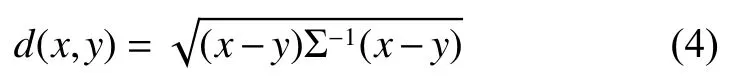
2)F-KNST算法描述
输入源域数据集,目标域数据集,样本近邻数;
输出目标域数据扩展集;
3 实验与分析
为验证本文所提出算法的有效性,本文分别以包装领域和医疗领域为例进行命名实体识别实验。
3.1 包装领域命名实体识别
3.1.1 数据准备
中国包装网作为我国最大的包装行业专业网站,包含了大量的包装领域文本。本文从中国包装网[17]上获取包装行业新闻作为实验数据构成迁移学习目标域样本,共计500篇。为保证源域与目标域的样本分布,本文选取搜狗实验室[18]的全网新闻语料,通过xml解析并去除Html标签后得到共计3.8 GB约120万篇新闻,作为源域数据集。为更好的完成包装领域命名实体识别任务,获取了包装领域专家完成的包装领域产业分类体系结构,确定了如表2所示6类实体类别。

表 2 包装实体类别及其含义Table 2 Packaging entity categories and their meanings
由于包装语料中包含大量的包装专业名词,如“瓦楞纸板”、“静电复印纸”等,故对包装语料进行分词容易导致实体被错分,从而导致无法识别命名实体。所以本文选择字标注方法对包装语料进行标注,采用BIO标注法,其中B表示实体的开头,I表示实体的剩余部分,O表示非实体序列。具体实体类别及其标注方法如表3所示。

表 3 实体标注方法Table 3 Entity labeling method
在确定包装领域实体类别及其标注方法后,本文采用人工标注与CRF相结合的迭代修正方式对包装语料进行标注。首先人工标注50篇文章,然后将其送入CRF中进行训练,得到实体识别模型,并预测50篇未标注文档,再使用人工方法对CRF模型标注错误的数据进行修正,得到100篇标注文本。再将100篇未标注文档送入CRF中进行训练识别,如此反复。随着语料的增加,CRF的拟合结果越来越好,人工修改的工作量逐渐减少,最终迭代完成后形成500篇质量较高的标注语料。
3.1.2 实验设计及参数设置
本文实验使用TensorFlow框架编写BiLSTMCNN-CRFs网络模型,软硬件环境如表4所示。

表 4 实验软硬件环境Table 4 Experimental software and hardware environment
本文使用Doc2Vec计算源域与目标域的文档向量,并且使用Word2vec对目标域扩展集预训练词向量,F-KNST算法中初始值K=100,以100为步长分别获取7组数据构成7个目标域扩展集。设计的实验参数如表5、表6所示。
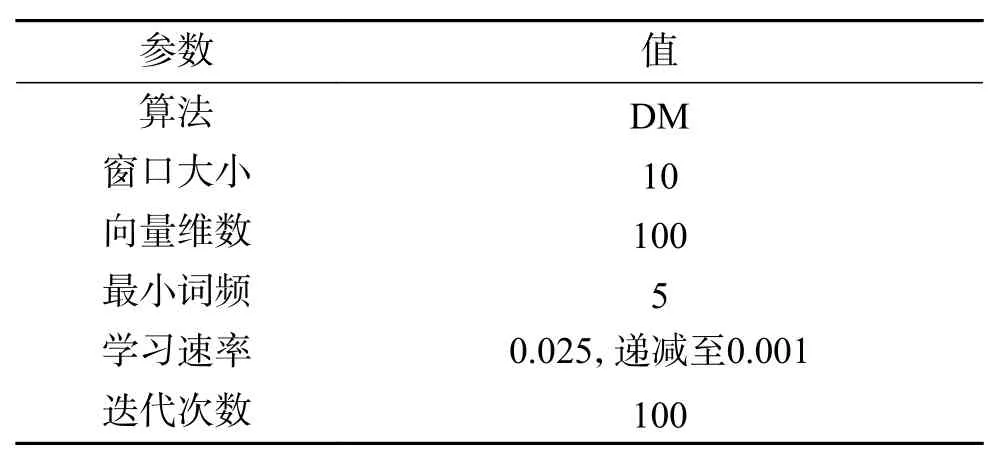
表 5 Doc2Vec参数表Table 5 Doc2Vec parameter list
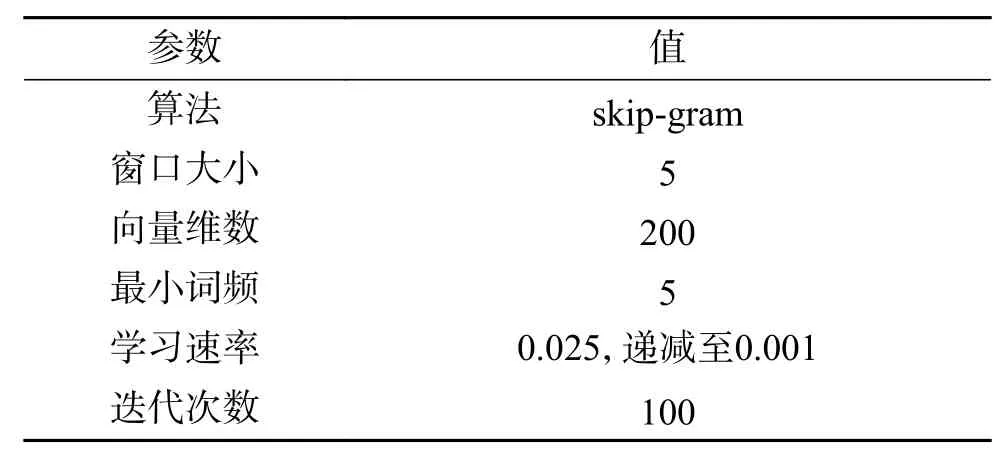
表 6 Word2Vec参数表Table 6 Word2Vec parameter list
基于深度学习的BiLSTM+CNN+CRFs网络模型参数如表7所示。

表 7 BiLSTM-CNN-CRFs模型参数表Table 7 BiLSTM-CNN-CRFS model parameter table
3.1.3 实验结果与分析
评价指标采用准确率、召回率和F值。这3个指标广泛用于信息检索和统计学分类领域,用于评估结果质量。准确率、召回率和F值定义如下:

式中:TP(true positive)表示正类且被预测为正类的数目;FP(false positive)表示负类且被预测为正类的数目;FN(false negative)表示正类被预测为负数的数目。
本文将包装标注语料按照6:2:2的比例切分为训练集、验证集和测试集,分别使用LSTMCRF模型、BiLSTM-CRF模型和BiLSTM-CNNCRFs模型对迁移和非迁移方法进行对比实验。
1)反馈值K的选取实验
分别使用LSTM-CRF、BiLSTM-CRF和BiLSTM-CNN-CRFs 3组模型进行语义迁移学习,识别包装领域实体,所获得的识别效果随K值的变化情况如表8所示。
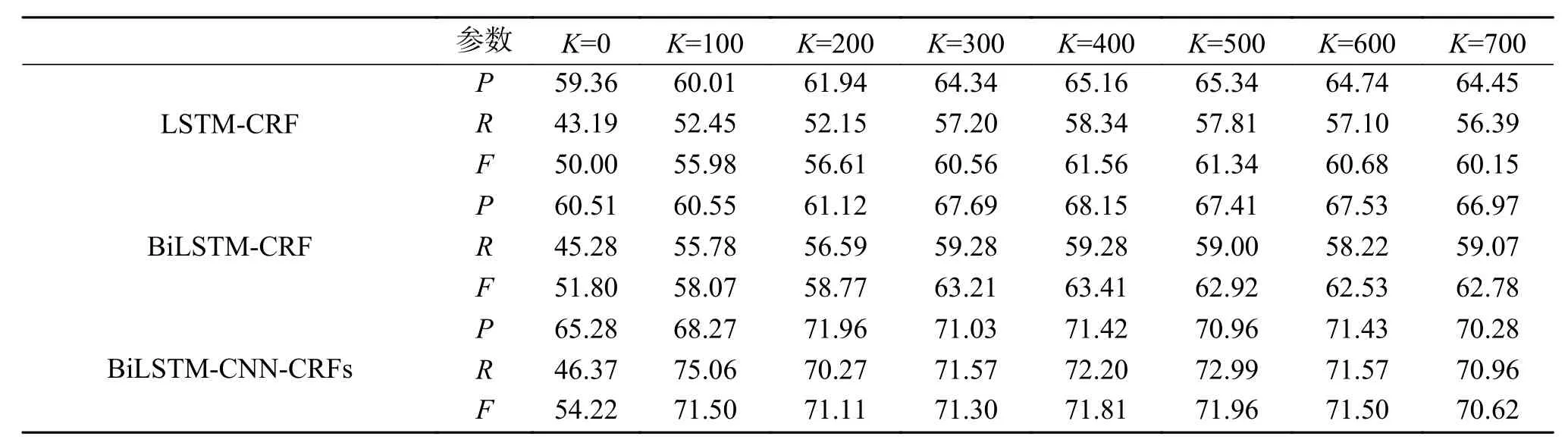
表 8 识别结果随K值的变化情况Table 8 The experimental results changed with K
各模型识别结果如图5~图7所示。
实验结果表明,3组模型的P、R和F值,均先随着K值的增大呈上升趋势,当达到某一特定值时反而呈下降趋势,LSTM-CRF和BiLSTMCRF模型在K=400时F值达到最大,而BiLSTMCNN-CRFs模型在K=500时F值达到最大。证明了随着迁移语义知识的增加,提高了模型的识别率。但随着领域新闻数据与通用新闻数据样本语义距离的增大,准确率、召回率和F值反而开始下降。这是由于随着语义距离的增大,通用新闻数据与领域新闻数据语义相关性降低,此时引入的样本多为“噪声”,开始产生“负迁移”现象,应停止迁移,选用得到最佳识别结果的K值作为最佳迁移阈值。因此,接下来反馈值K分别取400和500进行对比实验。
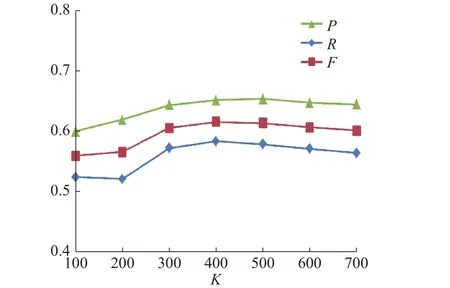
图 5 BiLSTM-CNN-CRFs识别结果Fig. 5 BiLSTM-CNN-CRFs results
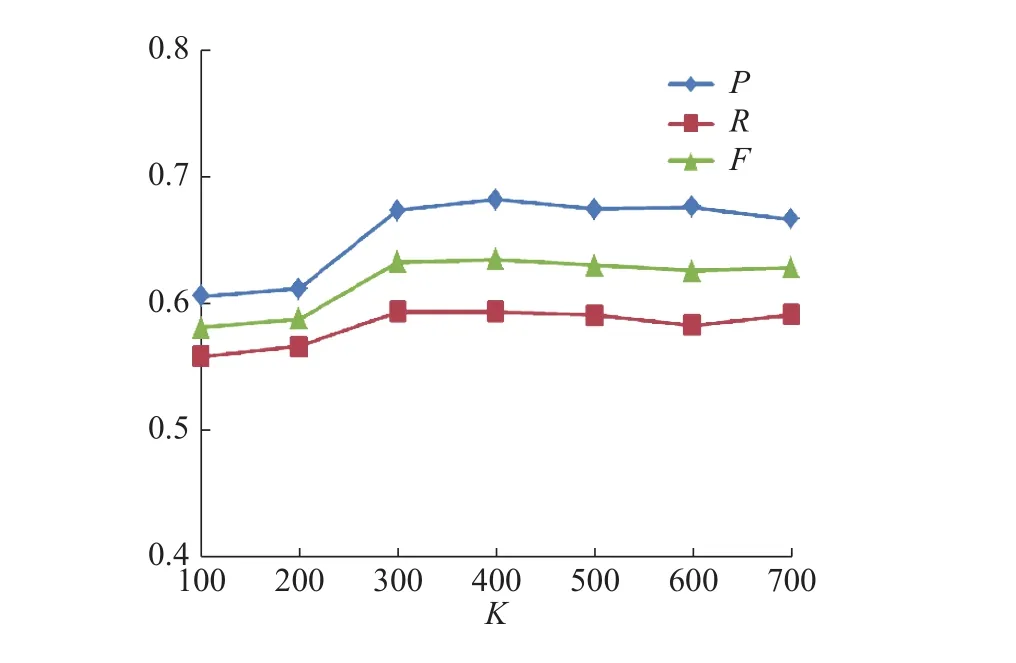
图 6 LSTM-CRF识别结果Fig. 6 LSTM-CRF results
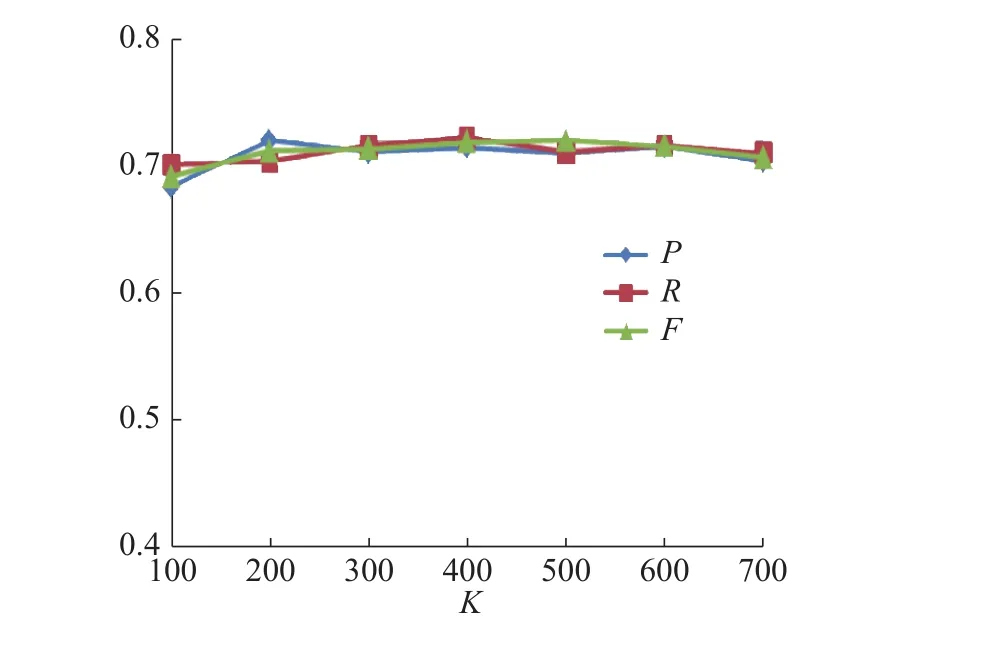
图 7 BiLSTM-CRF识别结果Fig. 7 BiLSTM-CRF results
2)对比实验与分析
LSTM-CRF、BiLSTM-CRF和BiLSTM-CNNCRFs三种模型下迁移前后对比实验结果如表9所示。
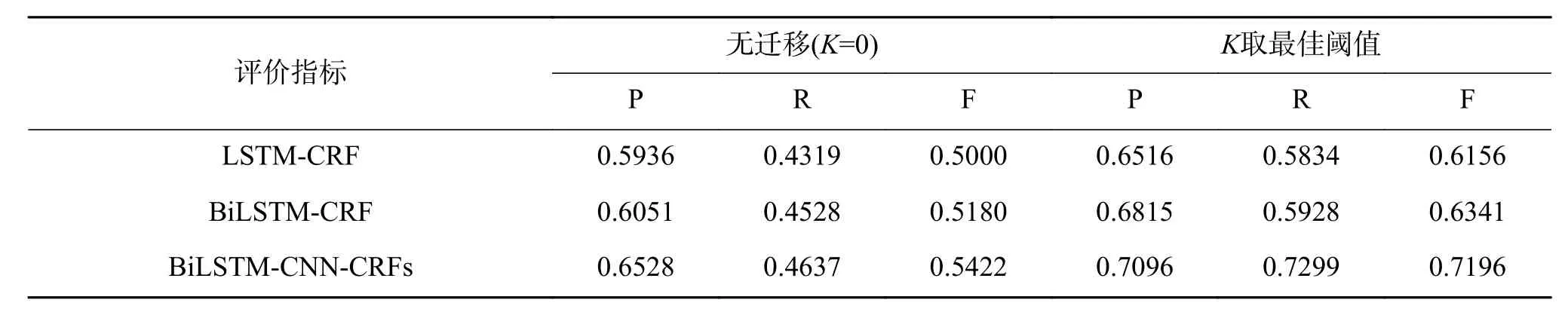
表 9 3种网络模型迁移前后实验结果Table 9 Experimental results before and after transfer of three network models
结果表明,3种模型采用F-KNST算法迁移后的P、R、F值均比迁移前提升很多,F值分别提升23.1%、22.4%和32.7%,BiLSTM-CNN-CRFs模型相比其他2种模型的P、R、F值亦有较大提升,迁移前的F值分别提升8.4%、4.7%,采用F-KNST算法迁移后的F值分别提升16.9%、13.5%,亦有效证明了本文构建的用于领域命名实体识别的BiLSTM-CNN-CRFs深度学习网络模型相较于其他模型的优越性。
3.2 医疗领域命名实体识别
3.2.1 数据准备
本文采用CCKS 2017[19]任务二提供的电子病历命名实体识别语料作为迁移学习目标域样本,共计1 200篇。
CCKS 2017任务二的电子病历语料数据集来源于真实电子病历经脱敏处理后形成的标注数据,电子病历按照数据组织不同分为:一般项目、病史特征、诊疗过程、出院情况。该数据集已经详细标注了实体名称、实体起始终止位置与实体所属类别等。CCKS的电子病历语料规定的抽取实体如表10所示5类实体类别。

表 10 医疗实体类别及其含义Table 10 Medical entity categories and their meanings
为了保证迁移学习的质量,本文编写网络爬虫分别从医疗资讯网[20]、好医生在线[21]等医疗在线网站获取医疗健康咨询数据,通过网页去重、xml解析和Html标签去除后得到共计100万篇作为源域数据集。
本文在进行医疗实体识别时同样采用字标注方法对医疗实体进行标注,采用BIO标注法,具体实体类别与标注编码如表11所示。
3.2.2 实验设计及参数设置
本文实验使用TensorFlow框架编写深度学习网络模型。为验证反馈K近邻迁移学习算法的有效性,本文保证实验中其他因素的一致性,故实验环境、Doc2Vec参数、Word2Vec参数与模型参数表均与3.1.2节中参数保持一致。设置FKNST算法中初始值K=100,以100为步长分别获取7组数据构成7组目标域扩展集。
3.2.3 实验结果与分析
本实验评价指标与3.1.3中(5)式完全一致。本实验采用CCKS的标准测试集进行实验结果测试,验证集按照8:2的比例从训练集中切分得到。分别使用LSTM-CRF模型、BiLSTM-CRF模型和BiLSTM-CNN-CRFs模型对迁移和非迁移方法进行对比实验。
1)反馈值K的选取实验
由以上的实验设置通过3组模型进行语义迁移学习,最终所获得的识别效果随K值变化情况如表12所示。
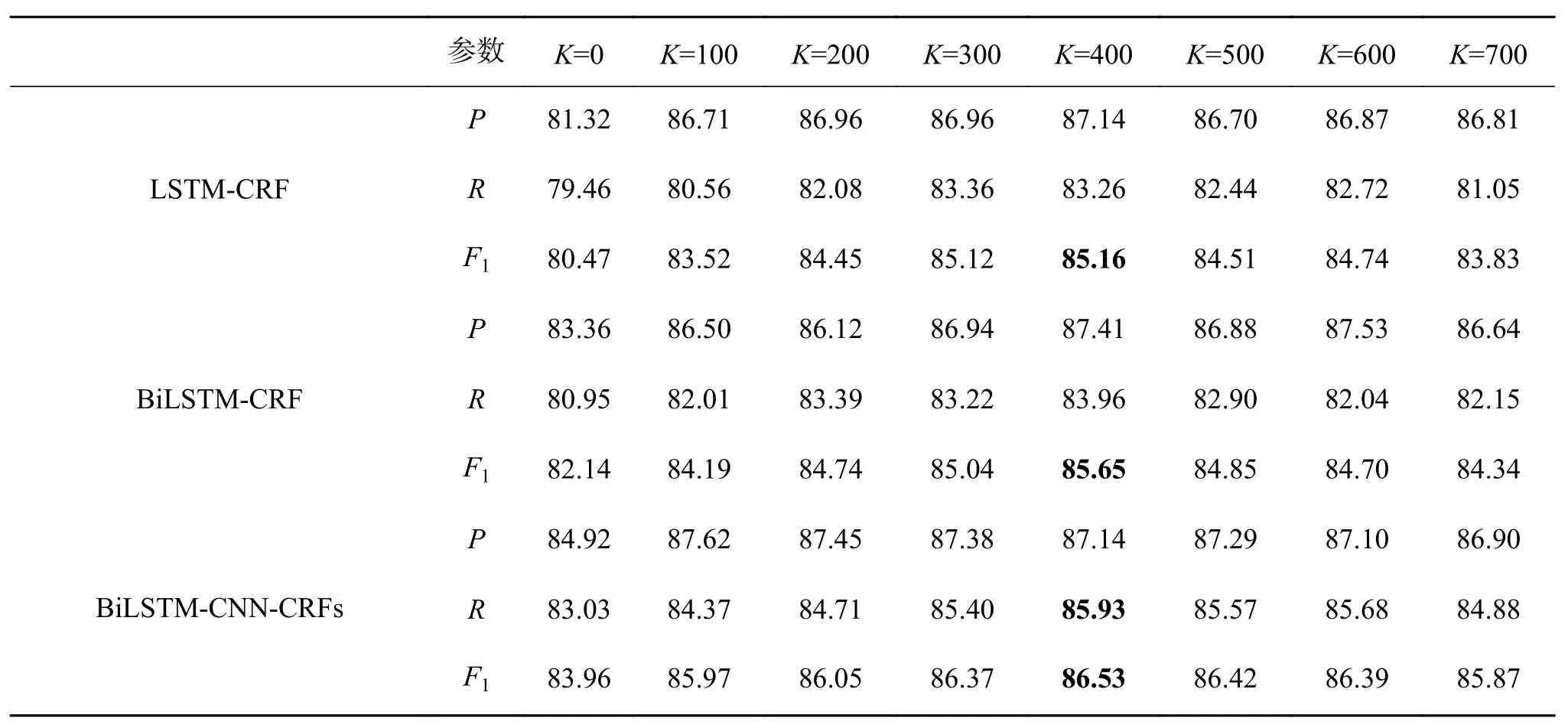
表 12 识别结果随K值变化情况Table 12 The experimental results changed with K
3组模型识别结果变化折线图分别如图8~图10所示。
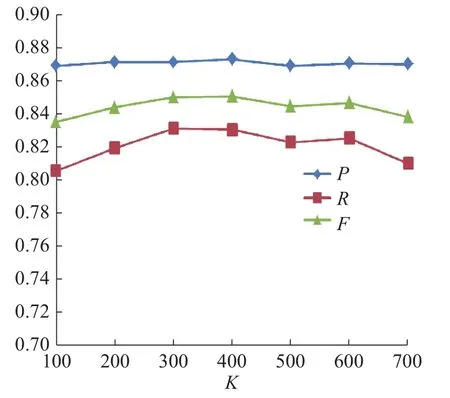
图 8 BiLSTM-CNN-CRFs识别结果Fig. 8 BiLSTM-CNN-CRFs results
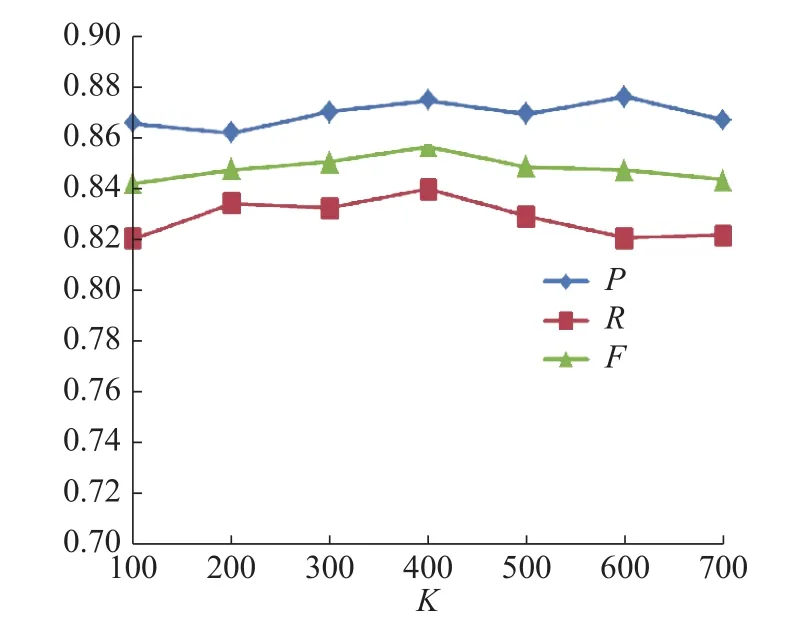
图 9 LSTM-CRF识别结果Fig. 9 LSTM-CRF results
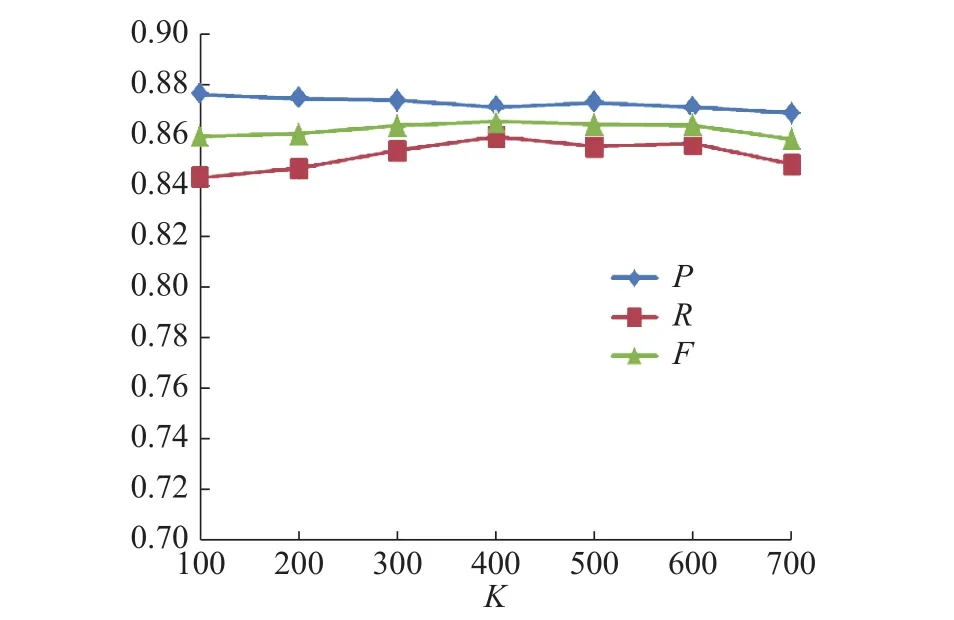
图 10 BiLSTM-CRF识别结果Fig. 10 BiLSTM-CRF results
实验结果表明,3组模型的P、R和F值,同样呈现出先上升后下降的趋势,3组模型均在K=500时F值达到最大。证明了随着迁移语义知识的增加,提高了模型的识别率。接下来取最佳阈值K=500的识别结果进行对比试验。
结果表明,在不同数据集上K值的选择是由该数据集上的实验结果反馈决定。本实验最优结果在K=400时达到稳定。而实验一中的包装实体识别在K=500时达到最优结果。如表13所示医疗领域语料采用F-KNST算法迁移后的P、R、F值同样有效果提升,F值分别提升4.96%、3.15%和2.57%,通过医疗领域的命名实体识别实验,亦有效证明了本文构建的用于领域命名实体识别的BiLSTM-CNN-CRFs深度学习网络模型相较于其他模型的优越性。
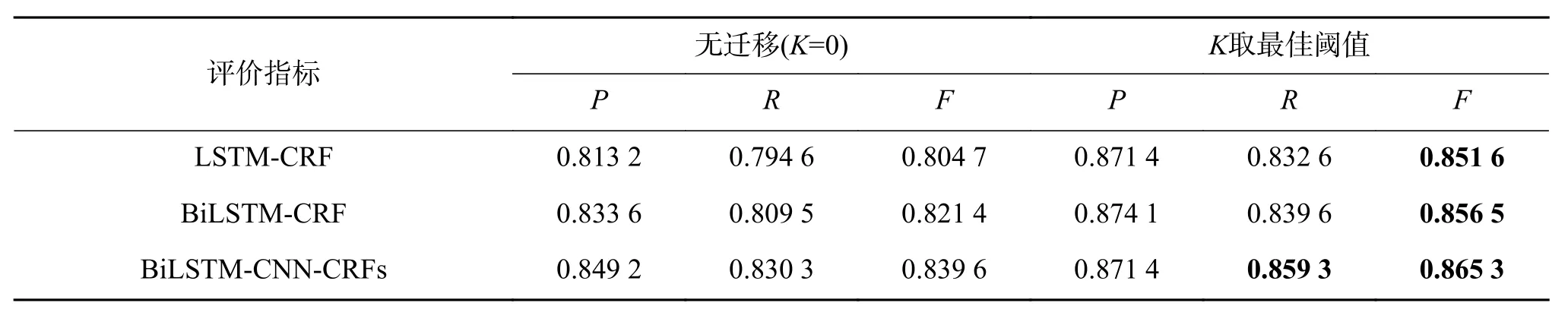
表 13 3种网络模型迁移前后实验结果Table 13 Experimental results before and after transfer of three network models
4 结束语
本文针对专业领域语料匮乏的特点,构建基于深度学习的BiLSTM-CNN-CRFs网络模型,以包装领域和医疗领域为例,提出了一种基于反馈式K近邻语义迁移学习的命名实体识别方法。本文方法不仅避免了传统机器学习无法学习到长距离依赖等缺点,而且很好地解决了专业领域的命名实体识别问题,有较强的通用性。实验结果表明,本文提出的F-KNST算法和BiLSTM-CNNCRFs网络模型可以很好的提取语义信息,扩充专业领域语料集,提高专业领域命名实体识别的准确率。
本文仍存在以下不足之处:1)Doc2Vec能够提取的语义信息比较有限,对于文本实体分布信息等并没有进一步挖掘;2)包装领域语料为多人协作标注,由于对包装实体有着不同的理解,导致部分实体标注标准不尽相同,影响识别率。接下来将对以上缺点开展进一步的研究,以进一步提高专业领域命名实体识别的效果。
