基于图游走的并行协同过滤推荐算法
2019-07-16顾军华谢志坚武君艳许馨匀张素琪
顾军华,谢志坚,武君艳,许馨匀,张素琪
(1. 河北工业大学 人工智能与数据科学学院,天津 300401; 2. 河北工业大学 河北省大数据计算重点实验室,天津 300401; 3. 天津商业大学 信息工程学院,天津 300134)
近年来随着互联网科技的发展,大数据在促进社会进步的同时,也带来了“信息过载”问题。如何快速从海量数据中获取有价值的信息成为当前大数据发展的关键性问题[1]。为满足人们在大数据中快速获取有价值信息的需求,推荐系统应运而生。推荐系统的目标是根据用户的个性化需求将最符合用户喜好的信息挑选出来并推荐给用户,以减轻用户的选择负担。协同过滤推荐算法是一种目前应用最广泛的推荐算法[2],可以在用户没有明确提出自己需求的情况下,根据用户的行为对用户进行推荐。但由于大数据环境下用户和项目的数量不断增长,协同过滤推荐算法面临着严重的数据稀疏性和可扩展性问题[3]。
针对稀疏性问题,许多学者从不同角度进行了相关研究。SUN等[4]采用聚类和时间影响因子矩阵来监测用户兴趣漂移程度,更准确的预测项目的评分。彭宏伟等[5]提出一种基于矩阵分解的上下文感知POI推荐模型,有效地缓解稀疏性问题。WU等[6]将异构信息网络建模为张量,并提出两种随机梯度下降方法同时进行分解。MA等[7]提出了一种局部概率矩阵分解的方法,降低稀疏性的同时有效地缓解了每个局部模型的过拟合问题。以上的方法均通过缓解数据稀疏性问题来提高推荐的准确度。
针对协同过滤推荐算法在处理大规模数据所遇到的可扩展性问题,许多学者在并行方法上进行了相关研究。杨志文[8]、LU F[9]、KUPISZ[10]等将协同过滤推荐算法部署在Hadoop和Spark并行平台上,取得了良好的执行效率。
本文针对协同过滤推荐算法的数据稀疏性问题和可扩展性问题进行研究。针对稀疏性问题,在皮尔逊相关相似度的基础上引入交占比系数来计算用户的直接相似度,提出了一种基于图游走的协同过滤推荐算法(GW_CF),使用图游走的方法计算用户的间接相似度,然后根据直接相似度和间接相似度重建用户的相似度矩阵,最后进行推荐。在Movielens-100k数据集和IPTV数据集上实验,验证GW_CF在提高推荐准确度上的有效性。针对可扩展性问题,在Spark平台上实现GW_CF算法,并使用Movielens-1M和Movielens-100k数据集进行实验,验证GW_CF算法的可扩展性。
1 相关工作
1.1 问题定义
基于近邻的协同过滤问题可以描述为[11]:已知用户集合表示为,项目集合表示为,用户-项目评分矩阵,表示用户对项目的评分。基于近邻的协同过滤推荐算法的流程:1)根据评分矩阵R计算用户的相似度;2)计算目标用户的近邻用户集合;3)根据近邻用户的评分预测目标用户对未评分项目的评分,从而生成推荐列表。
1.2 用户相似度
用户相似度指用户与用户之间行为中表现出的相似程度,皮尔逊相关相似度是一种常用的计算相似度的方法,反映了两个用户的偏好信息的线性相关程度。用户和用户的皮尔逊相关相似度计算公式[12-13]如下:
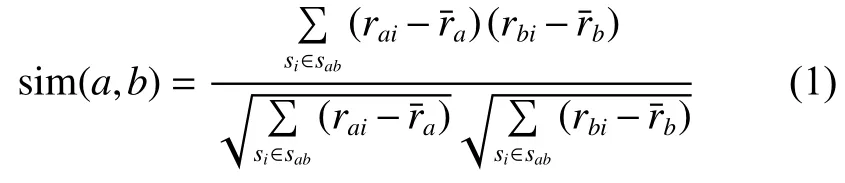
1.3 近邻用户
近邻用户表示与目标用户偏好信息最相似的一组用户,可以通过式(1)计算用户的相似度,然后计算目标用户的近邻用户。目标用户的多个近邻用户组成目标用户的近邻用户集合,常用的计算近邻用户集合的方法分为两类:基于数量的近邻用户集合和基于阈值的近邻用户集合。
基于阈值的近邻用户集合包含以目标用户为中心,与目标用户的相似度大于Value的用户。基于数量的近邻用户集合包含与目标相似度最大的Top-K个近邻用户。
1.4 个性化推荐
首先计算目标用户的近邻用户集合,然后对目标用户进行推荐。目标用户对未评分项目预测评分的计算公式[14]如式(2),最后将预测评分最大的K个项目推荐给目标用户。
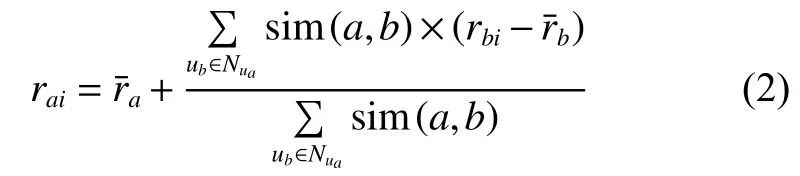
2 改进的皮尔逊相关相似度
皮尔逊相关相似度计算方法如式(1),仅仅考虑了用户的共同评分项,而忽视了共同评分项目与每个用户所有评分项的比例关系。这会导致如果两个用户仅有极少数共同评分项目,并且两个用户对共同评分项目的评分极度相似,使用皮尔逊相关相似度计算得到的用户的相似度,远远大于用户的真实相似度,降低了推荐的准确度。例如,用户曾对200个项目进行了评分,用户对300个项目进行了评分,两个用户仅拥有10个共同评分项目,且两个用户对每个共同评分项目的评分均相同。使用传统皮尔逊相关相似度计算两者的相似度为1(两个用户完全相似)。但实际上,除了10个共同评分项目以外,用户和用户还各自拥有大量的非共同评分项目,两个用户的喜好并不完全相同,利用皮尔逊相关相似度得到的结果远远大于两个用户的真实相似度。针对这个问题,本文在皮尔逊相关相似度基础上,引入交占比系数来缓解共同评分项占比的问题,交占比反映了两个用户的共同评分项在两个用户评分中的占比,加入交占比系数的皮尔逊相关相似度计算公式如下:
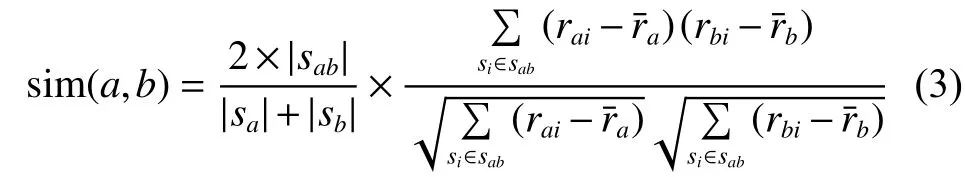
3 基于图游走的协同过滤推荐算法(GW_CF)
相似度计算是协同过滤推荐算法的关键部分,得到用户相似度之后可以确定用户的近邻用户集合。但以往计算用户的相似度时只考虑用户的直接相似相似度,这样将会遗失目标用户的间接近邻用户[15-16]。例如图1所示,、和表示3个用户,表示用户的评分项目,表示用户的评分项目,表示用户的评分项目。、、表示用户、和的相似度。依据式(3)计算用户和用户的相似度,由于用户和用户没有共同评分项,所以。但是用户和拥有共同评分项目和,那么,同理。由于相似性具有传递性,因此用户和可以通过共同的相似用户建立间接相似度,使得。如果两个用户没有共同评分项目,但间接相似度大于0,称这两个用户为间接近邻用户。在数据稀疏时,为用户寻找间接近邻用户能够有效地提高推荐的准确度。本文提出了基于图游走的方法,首先根据用户的直接相似度矩阵建立用户网络图,其次在用户网络图上进行游走计算间接相似度,然后根据间接相似度和直接相似度重建用户的相似度矩阵,最后进行推荐。

表 1 用户评分示例表Table 1 User rating
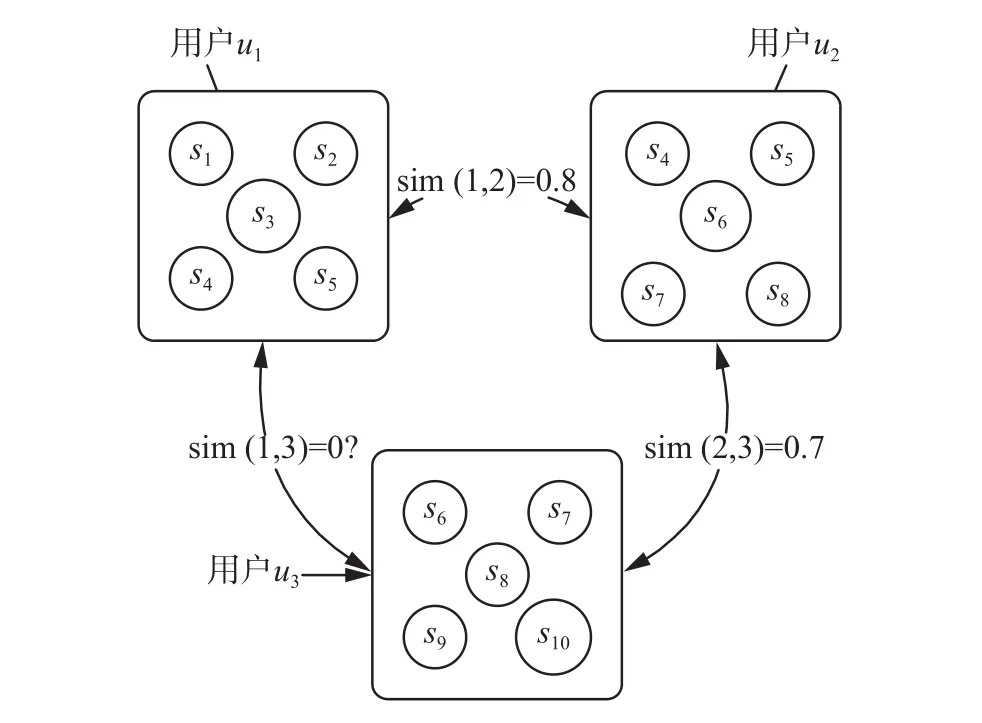
图 1 间接相似度关系图Fig. 1 Indirect similarity diagram
3.1 构建用户网络图
使用用户网络图来说明用户间的相似关系,从目标用户开始游走后停留在某个用户的概率越高意味着它与目标用户更相似。为了建立用户网络图,首先使用式(3)计算用户间的直接相似度,然后根据直接相似度建立用户近邻矩阵。为每个用户选择T个直接近邻用户,其他非T用户的相似度置0,得到的近邻矩阵如式(4)所示:

3.2 基于用户网络图游走
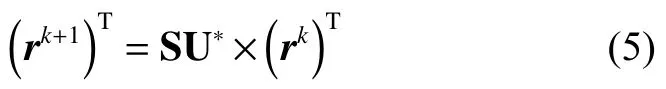
在用户网络图中存在着与其他用户的相似度都很低甚至可以忽略不计的特殊用户节点。在用户网络图中此类节点只有入度,没有出度,如图2中节点D,此时由于图中D节点只有入度,没有出度,用户网络图演变为非强连通图,以式(5)的方法游走到图中节点D时将无法跳转到其他节点。整个用户网络图的游走最终停留在类似节点D的死节点,无法求得用户的间接相似度,因此对式(5)进行变形如下:
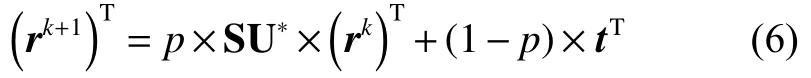
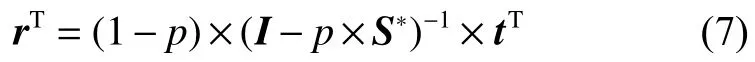

图 2 非强连通用户网络示例图Fig. 2 Non-strong connected user network
3.3 重建相似度矩阵
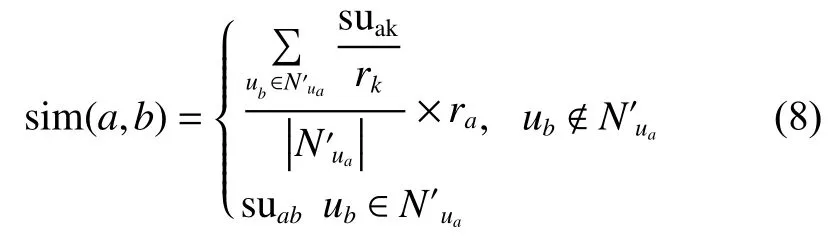
3.4 生成推荐结果
以每个用户顶点为起点进行游走查找其间接相似用户,得到重建的用户相似度矩阵,进一步得到目标用户的近邻用户集合。然后利用式(2)对目标用户的未评分项目进行评分预测,并将评分最高的Top-K个项目推荐给目标用户。
4 基于图游走的并行协同过滤推荐算法
4.1 Spark介绍
Spark是基于内存的分布式并行计算平台[19],它拥有Hadoop平台和MapReduce框架的全部优点,并且Spark运算的中间结果能存储在内存中,提高了并行计算的速度,因此Spark更适合进行数据挖掘与机器学习等需要迭代处理算法的实现[19-21]。Spark集群启动时包括一个Master节点和若干个Worker节点,其中Master节点主要负责集群资源的管理,Worker节点主要负责数据的计算。当在Master节点使用spark-submit命令提交作业时,首先在本地客户端启动一个Driver进程;Driver进程会根据设置的参数向Master节点申请相应的集群资源,主要有Worker节点个数、每个Worker节点上Executor的内存和CPU数量;Master节点与Worker节点进行通信,通知Worker节点启动Executor并向Driver进程注册;Driver进程与Worker节点连接起来,将需要执行的任务分配给集群中的各个Worker节点,Worker节点按照任务分配从HDFS上读取数据并缓存到内存中,Driver进程对各个Worker节点处理完的结果进行收集和汇总。在Spark平台实现基于图游走的协同过滤算法能够有效地提高算法的时间效率。
4.2 相似性计算的并行化
由于皮尔逊相关相似度计算公式较为复杂,全局搜索较多,因此在实现本文方法并行化时引入中间变量,反映了用户在项目上的相似度权重,计算公式如下:
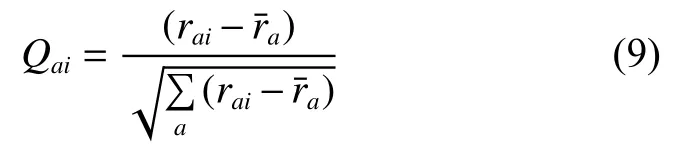
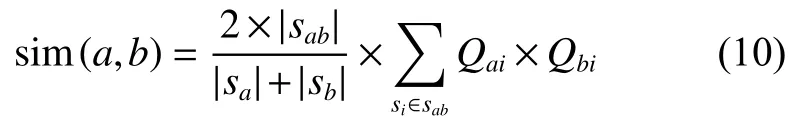
4.3 基于图游走的协同过滤算法并行化流程
基于图游走的协同过滤推荐算法在Spark平台上的并行化包括3部分,分别是读入数据创建RDD、计算用户的相似度以及生成推荐列表,该算法的并行化主要体现在计算用户相似度和生成推荐列表。基于图游走的并行协同过滤推荐算法示意图如图3所示。
具体过程如下:
1) 读入用户行为数据,构建RDD1;
2) 将 RDD1转换成形式的 RDD2,按照用户ID进行聚集得到RDD3,使用flatMap算子计算每个用户的中间变量,并按照项目ID进行聚集得到RDD4;
3) 根据 RDD4计算用户和用户的,得到形如的RDD5,其中的1和toNum是为了便于计算交占比系数而设置的;
4) 将3)的RDD5使用ReduceByKey算子统计其共同评分项,计算结合交占比系数的相似度,得到形如的 RDD6;
5) 利用4)的相似度RDD6,构造用户相似度矩阵userMatrixRDD,使用Spark中的线性代数库Breeze,调用其库函数 inv()计算userMatrixRDD的逆矩阵invMatrixRDD,进一步通过式(7)和(8)求得得间接相似度,重建相似度矩阵得到RDD7;
6) 根据RDD7按用户划分得到RDD8,并进一步得到目标用户的近邻用户集合RDD9,最后进行推荐。
5 实验与评价
实验使用Movielens数据集和IPTV数据集[20]进行实验。Movielens是一个基于Web的研究型推荐系统,用于接收用户对电影的评分并提供电影的推荐列表,Movielens数据集在协同过滤研究领域得到了广泛研究,也是使用最多的数据集之一。IPTV数据集来源于天津市IPTV电视用户的收视日志数据,经过对日志数据进行预处理和隐式评分处理,形成IPTV数据集。相比于Movielens数据集,IPTV数据集应用性更高。Movielens-100k数据集包含943用户,1 682项目,共10万条评分记录;Movielens-1M数据集包含6 040个用户和3 952个项目, 共计100万条评分记录。IPTV数据集选取193用户,8 200项目,共计43 175条评分记录。
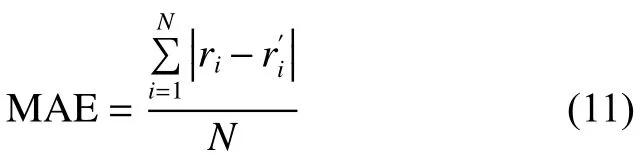
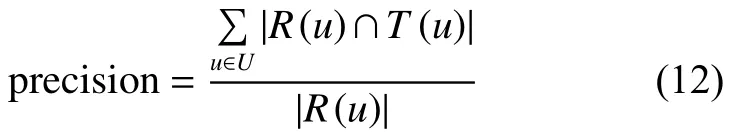
以加速比作为可扩展性的实验指标,加速比为

5.1 相似度交占比系数的有效性验证实验
在原始的皮尔逊相关相似度的基础上,为了比较加入交占比(YPCC)和未加入交占比(PCC)对预测评分误差的影响进行本次实验。此次实验使用Movielens-100k数据集,共943用户,1 682个项目,共10万条评分记录,稀疏度为94.12%,训练集和测试集按8:2分割。实验结果如图4。
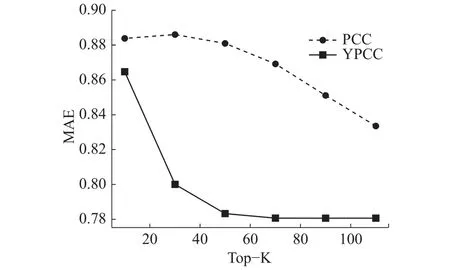
图 4 交占比系数有效性验证实验Fig. 4 Trial ratio validity validation experiment
从图4中可以看出,协同过滤推荐算法的预测评分误差受到近邻用户个数Top-K的影响。随着近邻用户个数Top-K的增加,PCC和YPCC曲线均呈现下降趋势并最终趋于稳定,但是YP-CC曲线明显低于PCC曲线,尤其Top-K在[40,60]时差距最明显。实验结果表明,无论近邻用户个数如何选取,在皮尔逊相关相似度上加入交占比系数均可以有效地减小评分预测误差。
5.2 基于图游走方法的有效性验证实验
5.2.1 Movielens数据集实验
为了验证基于图游走方法在降低评分预测误差和提高推荐准确率上的有效性,本次实验使用Movielens-100k数据集,训练集和测试集按8:2分割。先通过实验确定用户直接近邻个数T的最优取值,然后比较在不同的推荐近邻个数Top-K下,本文方法和基于用户的协同过滤推荐算法(BSCF)与基于聚类的协同过滤推荐算法(kmeans_CF)的和。
图5为选取不同直接近邻个数时的评分预测误差曲线,T表示直接近邻用户选取的个数。图5表明,当T>60时,趋于稳定。
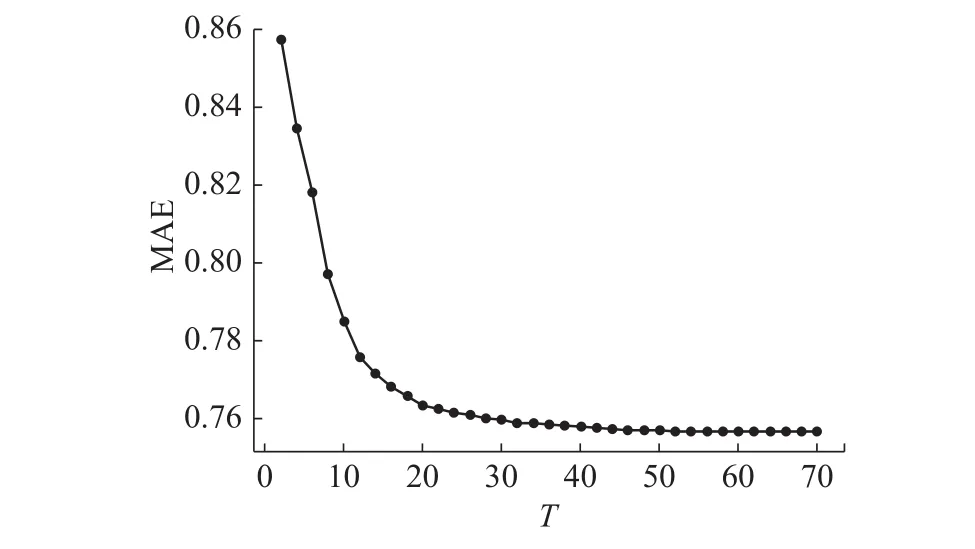
图 5 参数T测试图Fig. 5 Parameter T test chart
图6 的实验中T=60。推荐时近邻用户个数Top-K作为单一变量,对基于图游走的协同过滤推荐算法(GW_CF)、基于用户的协同过滤推荐算法(BSCF)、基于聚类的协同过滤推荐算法(kmeans_CF)进行对比实验。图6Top-K表示推荐时近邻用户选取的个数,表示评分预测的平均绝对误差。从图中可以看出,随着近邻用户个数Top-K的增加,3条曲线均呈下降趋势,BSCF曲线和k-means_CF曲线比较接近,GW_CF曲线明显低于另两条曲线,当Top-K大于80时更加明显。实验结果表明:GW_CF算法在降低评分预测误差方面是有效的。
图7中虚线反映了使用GW_CF推荐的准确度,实线反映了使用BSCF推荐的准确度。生成推荐列表时推荐项目数为10,从图中可以看出,随着近邻用户个数Top-K的增加,两条曲线呈上升趋势,GW_CF准确率曲线高于BSCF曲线。实验结果表明,基于图游走的协同过滤推荐算法GW_CF可以有效地提高推荐准确率。
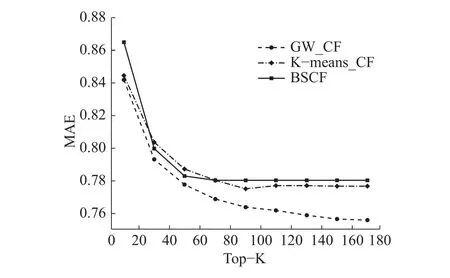
图 6 图游走效果图Fig. 6 Random walk effect graph
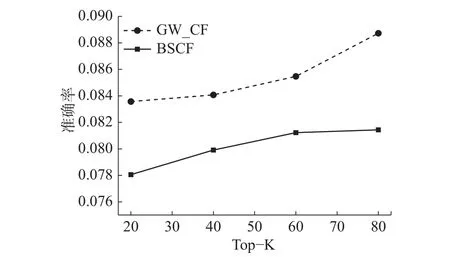
图 7 准确率对比图Fig. 7 Accuracy comparison chart
5.2.2 IPTV隐式评分数据集实验
为了验证基于图游走方法在降低评分预测误差和提高推荐准确率上的有效性,本次实验使用IPTV数据集,训练集和测试集按8:2分割。先通过实验确定用户直接近邻个数T的最优取值,然后比较在不同的推荐近邻个数Top-K下,基于图游走的协同过滤推荐算法(GW_CF)和基于用户的协同过滤推荐算法(BSCF)的和。
图8为选取不同直接近邻个数时的评分预测误差曲线。 图8表明,当T>20时,趋于稳定。
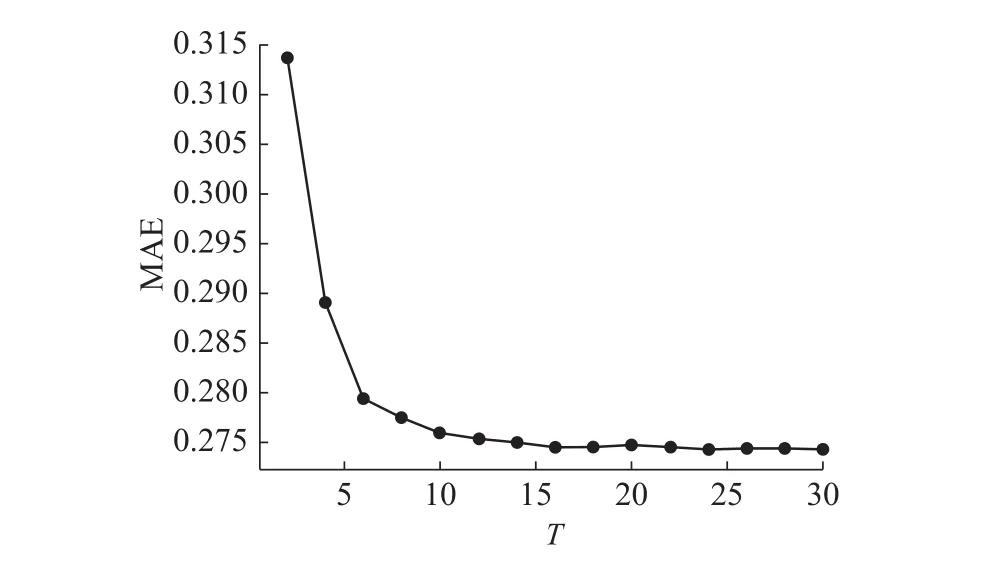
图 8 参数T测试图Fig. 8 Parameter T test chart
图9 的实验中T=20,推荐近邻用户Top-K作为单一变量,对基于图游走的协同过滤推荐算法(GW_CF)和基于用户的协同过滤推荐算法(BSCF)进行对比实验。从图9 中可以看出,随着近邻用户个数Top-K的增加,两条曲线均呈下降趋势,GW_CF曲线明显低于BSCF曲线。实验结果表明:GW_CF算法在降低评分预测误差方面是有效的。
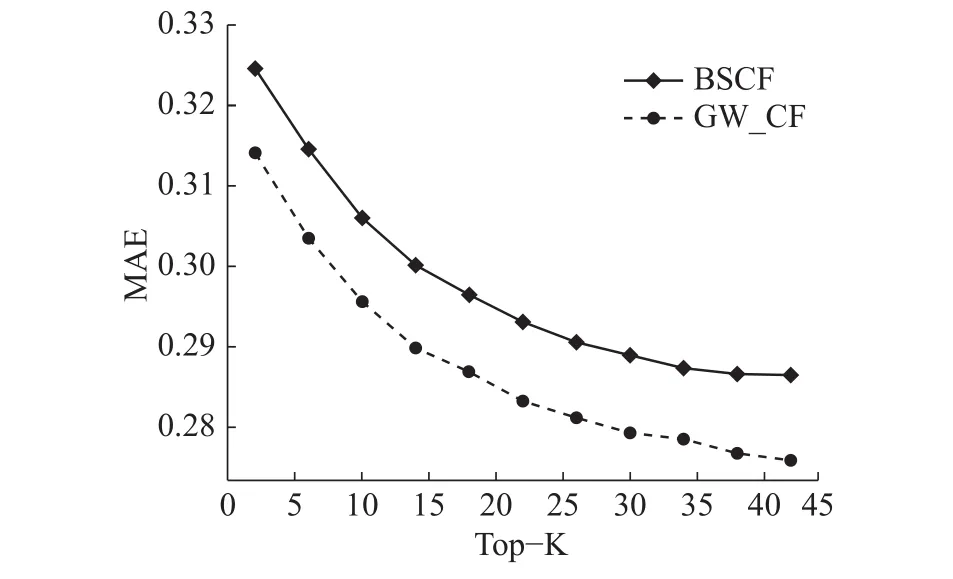
图 9 图游走效果图Fig. 9 Random Walk Effect Graph
图10 中生成推荐列表时推荐项目数为10,随着近邻用户个数Top-K的增加,两条曲线呈上升趋势,GW_CF准确率曲线趋势更明显并且高于BSCF曲线。实验结果表明,在一般情况下,GW_CF比BSCF拥有更高的推荐准确率。
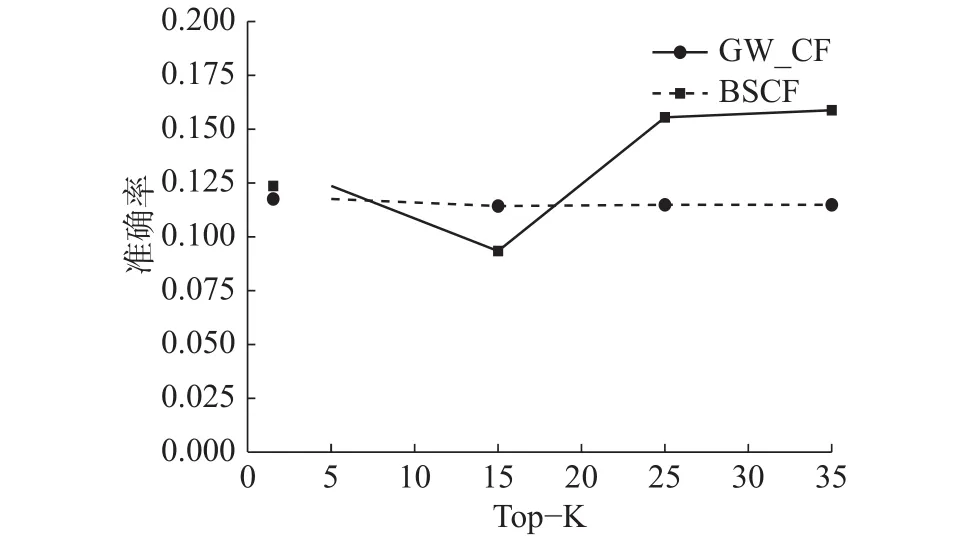
图 10 准确率对比图Fig. 10 Accuracy comparison chart
5.3 基于图游走的并行协同过滤推荐算法可扩展性实验
为了验证基于图游走的并行协同过滤推荐算法的可扩展性,使用Movielens-1M和Movielens-100k数据集在Spark平台进行实验。其中1M数据集包含6 040个用户和3 952个项目,共计100万条评分记录;100k数据集包含943用户,1 682项目,共10万条评分记录。实验在Spark集群上实现,集群环境包括6个节点,一个Master节点,5个worker节点,每个节点的配置相同,且处在同一个局域网内,操作系统为CentOs6.5,CPU为E5-2620 v4,核心频率2.10 GHz,节点内存32 GB。加速比结果如图11。
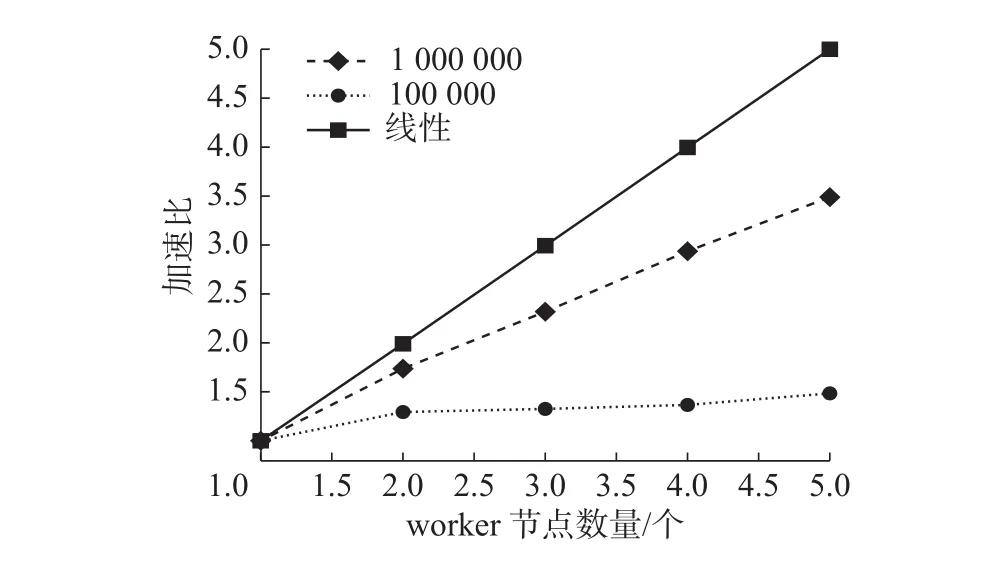
图 11 加速比示意图Fig. 11 Speed-up ratio graph
从图11中可以看出,随着节点个数的增加,加速比呈现上升趋势,100万数据集更逼近线性加速比。实验结果表明,并行协同过滤推荐算法在大规模数据集的情况下有较好的可扩展性。
6 结束语
本文针对协同过滤推荐算法中的数据稀疏性问题和可扩展性问题进行研究。针对稀疏性问题,在基于用户的协同过滤推荐算法的基础上,首先为传统的皮尔逊相关相似度引入交占比系数来计算用户的直接相似度,其次提出一种基于图游走方法来计算用户间接相似度,并重建相似度矩阵和进行推荐。针对可扩展性问题,在Spark平台上实现本文方法的并行化。通过在Movielens数据集和IPTV数据集上进行实验,先后验证了加入交占比系数和基于图游走的方法在提高推荐准确度上的有效性,以及本文方法的可扩展性。实验结果表明,本文的方法在提高推荐准确度上是有效的,并且在大规模数据上拥有较好的可扩展性。
