一种双优选的半监督回归算法
2019-07-16程康明熊伟丽
程康明,熊伟丽,2
(1. 江南大学 物联网工程学院,江苏 无锡 214122; 2. 江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122)
针对一些工业过程存在有标签样本数据少且获取代价大,而无标签样本数据大量存在的情况,研究利用少量有标签样本和大量的无标签样本来提高学习性能的半监督学习受到了密切关注[1-3]。如今,半监督思想已经应用于各行各业,根据半监督学习目的将其大致分为3类[4]:半监督聚类、半监督分类和半监督回归。其中,半监督聚类与半监督分类的研究很多,而半监督回归的研究相对较少。
半监督回归根据学习方法的不同大致分为两类[5-6]:第一类为利用流行学习的半监督回归算法;第二类为协同训练算法。其中,流行学习方面的研究有杨剑等[7]提出的一类广义损失函数的Laplacian半监督回归方法,该方法充分利用了有标签样本的结构信息来提高回归估计的精度。协同训练的典型代表为Zhou等[8]在2005年提出的基于协同训练的半监督回归算法,该方法通过建立两个学习器,以交互学习的方式来利用无标签样本,达到提高回归精度的目的,但是其对有标签样本两个冗余视图的假设,使得该方法在某些场合的应用受到限制。另外,一些其他的半监督回归方法也取得了不错的效果。如程玉虎等[9]提出的一种Help-Training的半监督支持向量回归算法,通过置信度评估选出了信任的无标签样本。盛高斌等[10]提出的基于半监督回归的选择性集成算法,考虑了如何通过对有标签样本的合理利用提高无标签样本预测的准确性。
上述方法有的从有标签样本角度出发,有的从无标签样本角度出发,本文为了更准确地利用无标签样本,同时考虑对无标签样本和有标签样本的筛选,通过定义两个优选准则,提出一种双优选的半监督回归算法。该方法首先筛选无标签样本,降低引入预测误差的可能性,同时筛选有标签样本,获得一个更有针对性的有标签样本集;然后利用高斯过程回归(GPR)方法对选出的有标签样本建立辅学习器,以对选出的无标签样本预测标签;最后利用这些伪标签样本和初始有标签样本集通过GPR方法建立主学习器,从而提升主学习器预测效果。通过两个仿真实验,验证了本文所提方法的有效性。
1 高斯过程回归
GPR是一种基于统计学习理论的非参数概率模型,适合处理高维度、小样本及非线性等数据的建模问题[11]。
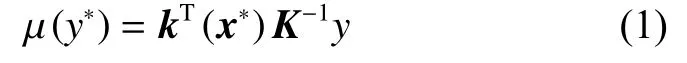
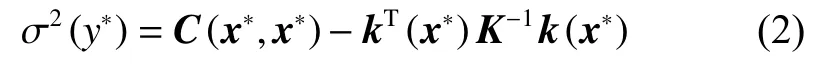
协方差函数是GPR方法中的重要组成部分。GPR方法可以选择多种协方差函数,只需保证对任意输入能够得到一个非负定协方差矩阵。本文选择常用的高斯协方差函数,定义为
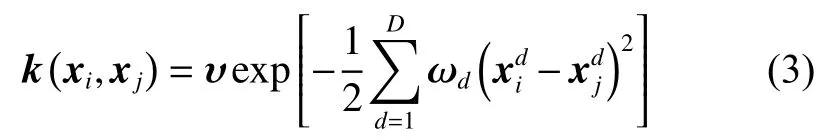
2 基于双优选的半监督回归策略
本文提出的双优选策略,通过定义两个优选准则来综合考虑无标签样本的筛选,有标签样本筛选以建立辅学习器两方面问题,进而达到准确预测无标签样本的目的。
2.1 双优选准则
上述两个优选准则,优选准则1通过马氏距离选出以有标签样本密集区中心为球心为半径的球域内所有无标签样本点,利用该准则有利于选出能够被准确预测的无标签样本,剔除了可能带来较大预测噪声的无标签样本。优选准则2采用了Knoor等[14]提出的基于距离的离群点的定义,通过马氏距离度量的相似度,剔除了阈值限定下的离群点,从而提升辅学习器的预测精度。有标签样本与
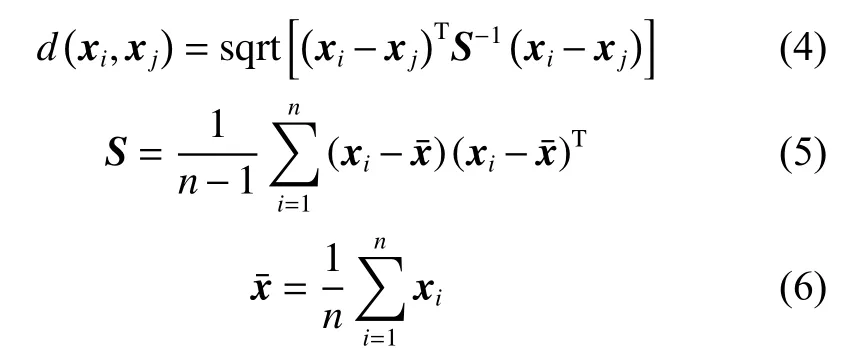
2.2 无标签样本筛选
为了选出能够被准确预测的无标签样本,利用优选准则1对无标签样本进行筛选,选出满足条件的无标签样本。而该准则能否做出有效筛选,取决于样本密集区中心是否准确,尤其在有标签样本数目比较少时,此时样本密集区中心对离群点更敏感。针对这种情况,提出一种新的寻找有标签样本密集区中心的方法。该方法首先寻找出有标签样本中属于样本密集区的样本,然后对这部分属于样本密集区有标签样本求各属性均值,得到样本密集区中心。其具体操作如下,依次计算每一个有标签样本与周围有标签样本间的马氏距离,然后判断是否小于阈值,统计周围满足条件的有标签样本数量若大于1,则为有标签样本密集区样本,最后用所得样本密集区样本确定样本密集区中心。在确保准则1的筛选效果后,再利用其筛选无标签样本。具体伪代码如算法1所示。
算法1 无标签样本筛选
输入有标签样本集(由自变量与因变量组成),无标签样本集(只包含自变量),阈值和,计数变量输出选出的无标签样本集

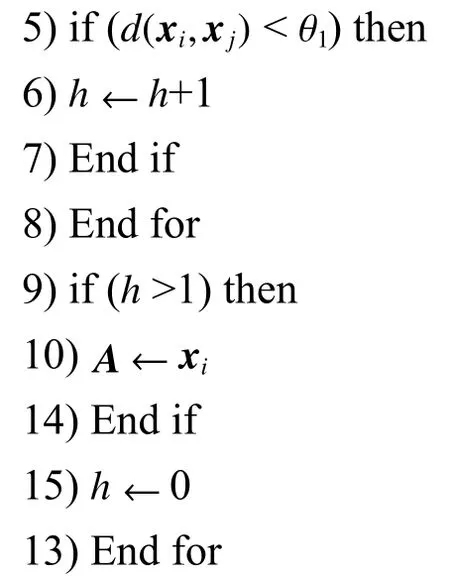
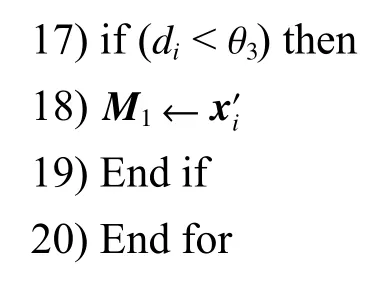
2.3 辅学习器建立
算法2 辅学习器建立
输入有标签样本集(由自变量与因变量组成),阈值,计数变量
输出辅学习器
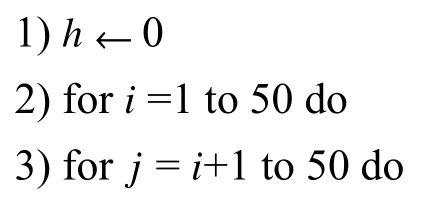

2.4 基于双优选的半监督算法流程
综合考虑无标签样本和有标签样本的选择,提出了一种带双优选过程的建模方法,建模流程如图1所示。具体建模步骤如下:
2) 根据优选准则2选出有标签样本,建立一个更有针对性的辅学习器。
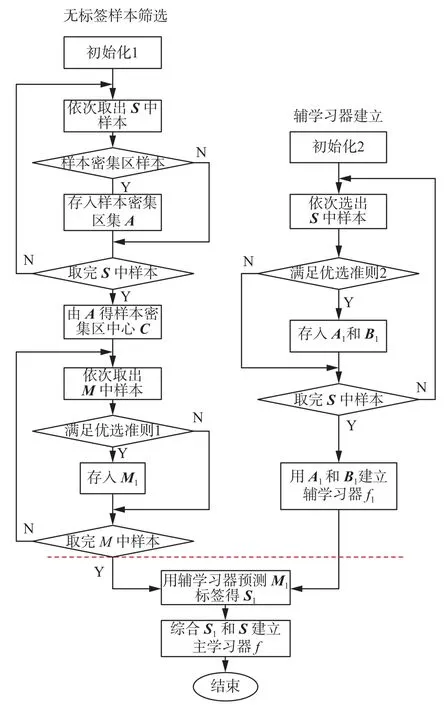
图 1 总体算法步骤Fig. 1 Overall algorithm steps
3 数值仿真实验
为了验证所提双优选方法的有效性,采用文献[15]中的非线性函数进行数值仿真:
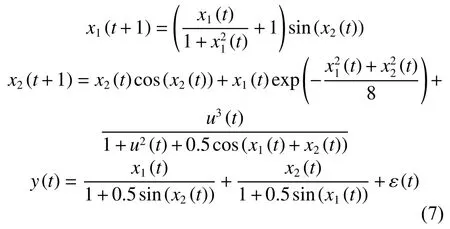
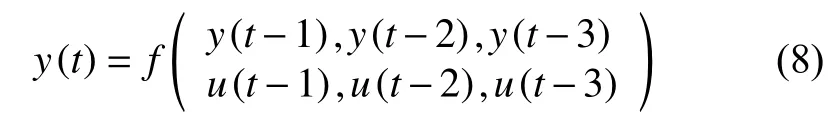
同时为了解决由于训练样本与测试样本过于相似而带来的对建模效果评价的可信度问题,仿真中通过两种不同方式分别产生训练样本和测试样本。对于训练样本,首先产生[-2,2]的随机信号与[-2,2]的随机信号然后将这两组信号作用于系统,最终得到600组数据作为训练样本;对于测试样本,首先令产生[-2,2]的随机信号然后这两组信号作用于系统,最终得到200组数据作为测试样本。600组训练样本中选取50组作为有标签样本,另外550组作为无标签样本。
为了更直观地说明双优选方法的必要性,对数值仿真产生的训练样本数据进行了直方图统计,分别统计了变量在每一维度上的分布特点,具体如图2所示,其中横坐标为样本分布区间,纵坐标为样本出现的频数。
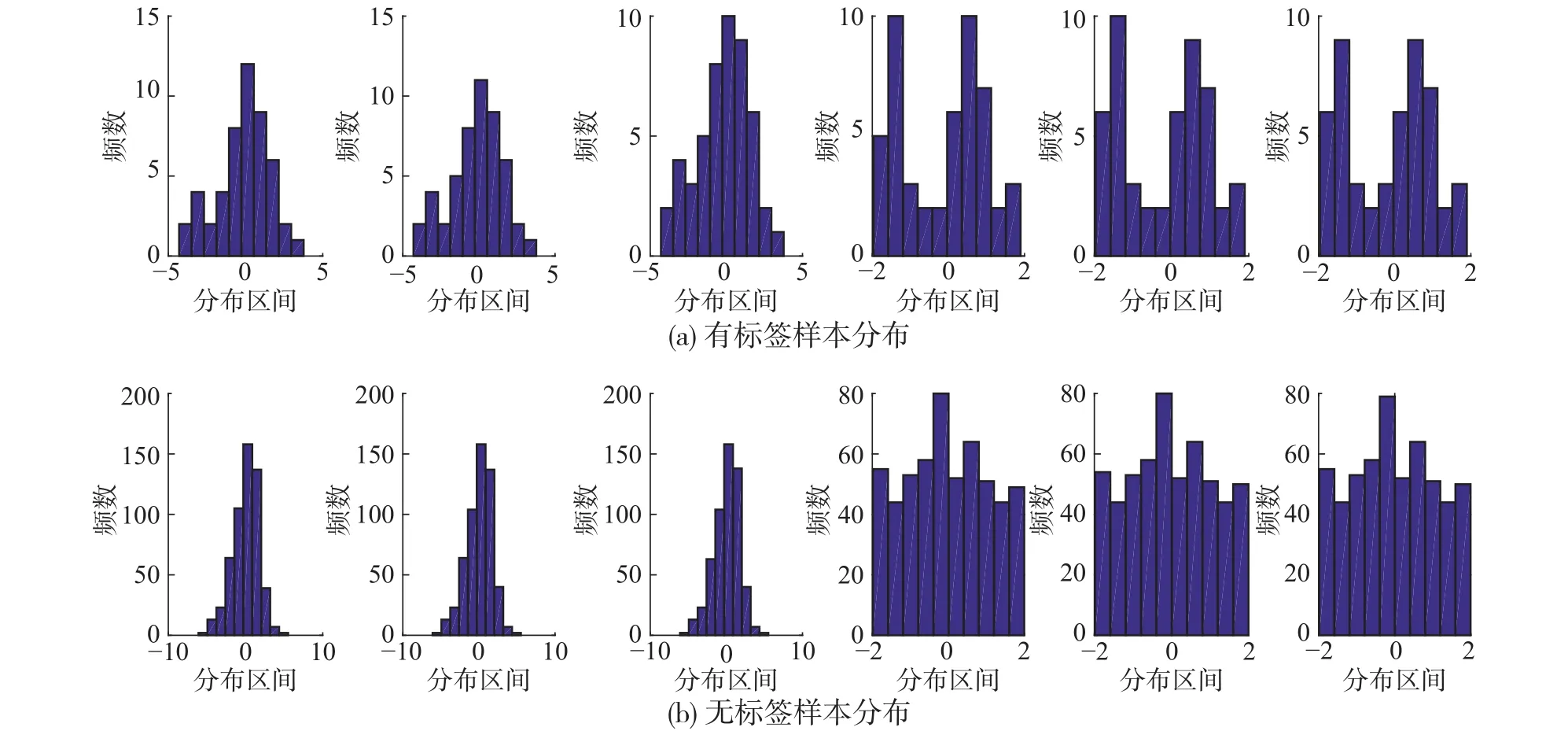
图 2 有标签样本与无标签样本的直方图分布Fig. 2 Histogram distribution about labeled and unlabeled samples
在图2中,图(a)为50组有标签样本辅助变量分布的直方图统计,图(b)为550组无标签样本每一维度分布的直方图统计。因为大量无标签样本更能够反映过程的整体特点,由图2(a)和图2(b)前3幅图的对比,发现无标签样本分布大致成一种正态分布,而图2(a)有标签样本的分布中,-5~0这段趋势明显异于整体的正态分布,可知部分初始有标签样本是游离在整体特性之外的。为保证准确性,需使建模样本与预测样本分布特性尽量一致。由图2(a)后3幅图发现,有标签样本分布在-1~1这段的数量相对较少,约占全部有标签样本的1/2,而由图2(b)后3幅图发现,无标签样本分布在-1~1这段的数量明显更多,约占全部无标签样本的3/4。由上述对比可知,仅靠现有的有标签样本,难以准确预测所有的无标签样本。因此,想要利用无标签提升建模效果,需要根据优选准则1筛选出能够被准确预测的无标签样本,剔除那些可能会带来大量噪声的无标签样本。另外,由于有标签样本很少,不符合优选准则2的有标签样本将对辅学习器的针对性产生较大影响,必须剔除以保证对无标签样本预测的准确性。通过上述分析,从数据分布的角度说明了双优选方法的必要性。
为了进一步验证方法的实际效果,分别比较了GPR(不利用无标签样本)、无优选半监督GPR(non-optimal semi-supervised GPR,NS-GPR)和本文方法(利用优选准则1和优选准则2)对真实值的跟踪效果,具体效果如图3所示。
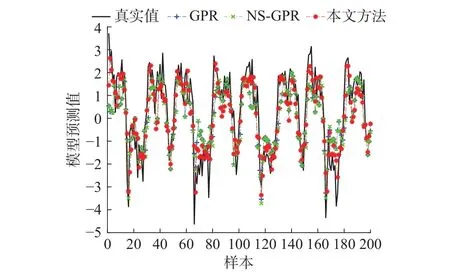
图 3 数值仿真双优选半监督预测效果Fig. 3 Numerical simulation of double-optimal semi-supervised prediction
由图3可知,本文方法对真实值的跟踪效果远远优于GPR和NS-GPR。双优选方法在充分准确地利用无标签样本后,对测试样本真实值的跟踪效果明显加强,拟合效果有了明显的提升。具体拟合指标如表1所示。由表中数据可知,所提双优选方法跟踪效果相较GPR,均方根误差由1.109 6下降到了0.927 8,可知本文方法在有标签样本很少时也能够取得优秀的跟踪效果。

表 1 数值仿真双优选的拟合性能Table 1 The fitting performance of numerical simulation of dual-optimal selection
4 脱丁烷塔仿真实验
为了进一步验证本文方法性能,选用脱丁烷塔过程作为对象。脱丁烷塔装置是石油炼制生产过程中脱硫与石脑油分离装置的重要组成部分[16]。该过程样本数据有7个辅助变量,分别为:塔顶温度;塔顶压力;塔顶回流量;塔顶产品流出;第六层塔板温度;塔底温度1;塔底温度2;主导变量为塔底丁烷浓度。详细的工艺过程描述可见文献[17]。
该实验过程数据源于真实过程的实时采样,共获得2 394组样本。选出150组作为有标签样本,选出500组作为无标签样本。在有标签样本中,50组作为建模样本,另外100组作为测试样本。
为了进一步分析本文算法性能,纵向比较了几点改进对模型跟踪效果的影响,具体方法如下。
1) GPR方法。不利用无标签样本,仅利用已有的有标签样本建立GPR模型,然后测试其对测试样本的跟踪效果。
2) NS-GPR方法。不利用优选准则做筛选,直接对有标签样本建模,获得辅学习器,然后预测无标签样本的标签,进而利用伪标签样本更新主学习器。
3) 第一类单优选半监督GPR(single-optimal semi-supervised GPR,SS-GPRa)。利用优选准则1筛选无标签样本,然后直接对有标签样本建模得到辅学习器,后续过程同方法2)。
4) 第2类单优选半监督GPR(简称SS-GPRb)。首先利用优选准则2筛选有标签样本,然后对其建模得到辅学习器,后续过程同方法2)。
5) 本文方法。
图4为不同方法的预测值与真实值的比较,纵坐标为测试样本真实值,横坐标为测试样本预测值,数据点离基准线越近,表示预测效果越好。
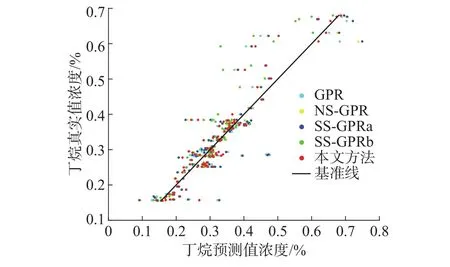
图 4 不同方法的纵向比较Fig. 4 Longitudinal comparison of different methods
分析图4发现,本文方法在几种方法中的效果最好。为了更直观地比较各方法的预测效果,图5通过跟踪误差表现了各方法的跟踪效果,其中,纵坐标为预测值与真实值的差值。
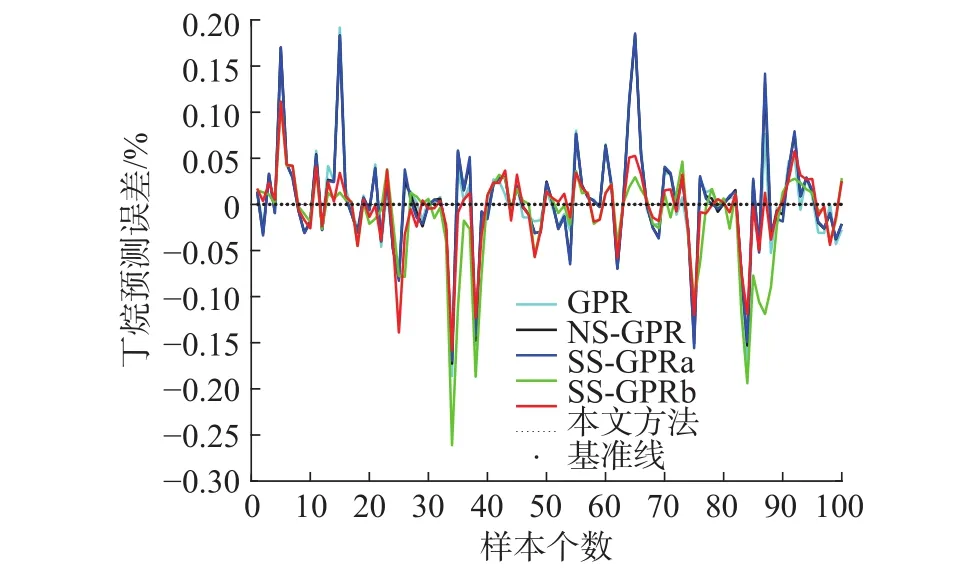
图 5 不同方法的预测误差对比Fig. 5 Comparison of prediction errors of different methods
综合图4和5可以看出,NS-GPR虽然考虑了无标签样本信息,但其无差别的利用将会带来大量噪声,而SS-GPRa虽然筛选了无标签样本,但是由于辅学习器建立过程中,没有考虑有标签样本的针对性,也会带来大量噪声。而SS-GPRb在考虑筛选有标签样本后,能够对部分无标签样本进行更准确的预测,因此获得了较好的模型预测效果。
本文方法在综合考虑无标签样本与有标签样本筛选后,在绝大多数测试样本的跟踪上,都有很好的效果。这是因为在利用双优选准则后,既降低引入噪声的可能性,又保证了辅学习器的针对性,因此方法的跟踪效果有了明显的提升。
上述分析均建立在各方法对真实值的跟踪效果对比上,为了更客观地对比方法之间的效果,进行了各方法预测值的直方图统计。图6分别统计了真实值与各方法预测值的分布,其中,纵坐标为分布在每一区间的样本出现的频率,横坐标为预测值与真实值分布的区间。
由图6(a)、(c)和(d)的对比可知,NS-GPR与SS-GPRa在0.1~0.15和0.5~0.6两个区域的预测值有比较明显的误差。同样,由图6(a)与图6(b)的对比发现,GPR在0.4~0.6区域的预测值的误差也较大。进一步由图6(a)与图6(e)的对比发现,SSGPRb在0.6~0.7区域中无法实现良好跟踪。最后,综合对比图6各方法发现,本文方法在上述区域均能进行更准确地跟踪。
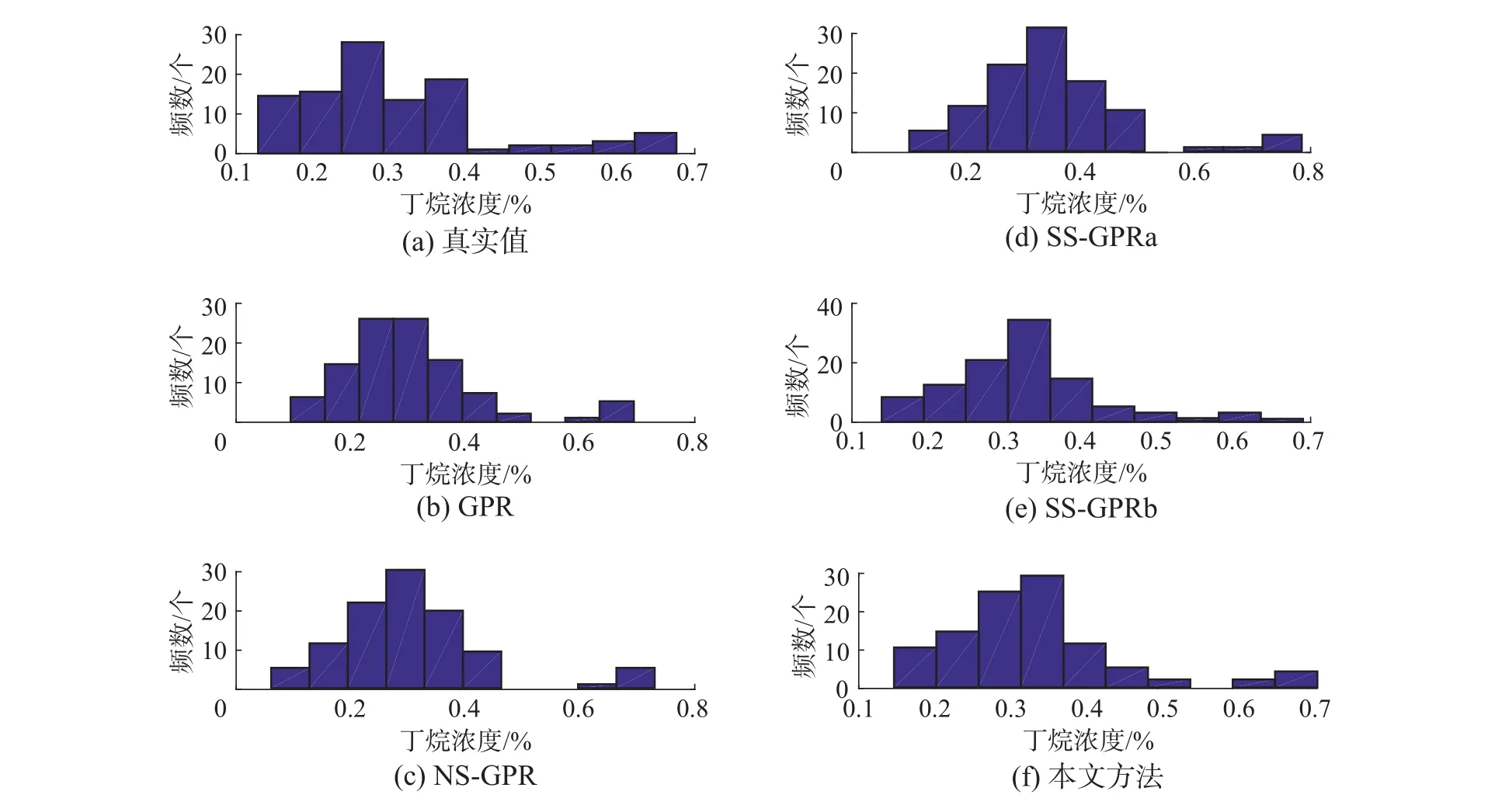
图 6 多种方法预测值与真实值的直方图统计Fig. 6 Histogram statistics of predicted and real values of various methods
上述分析对比,验证了本文方法的实际效果。发现同时考虑无标签样本与有标签样本的筛选,获得了更好的预测效果。各方法具体跟踪效果如表2所示。
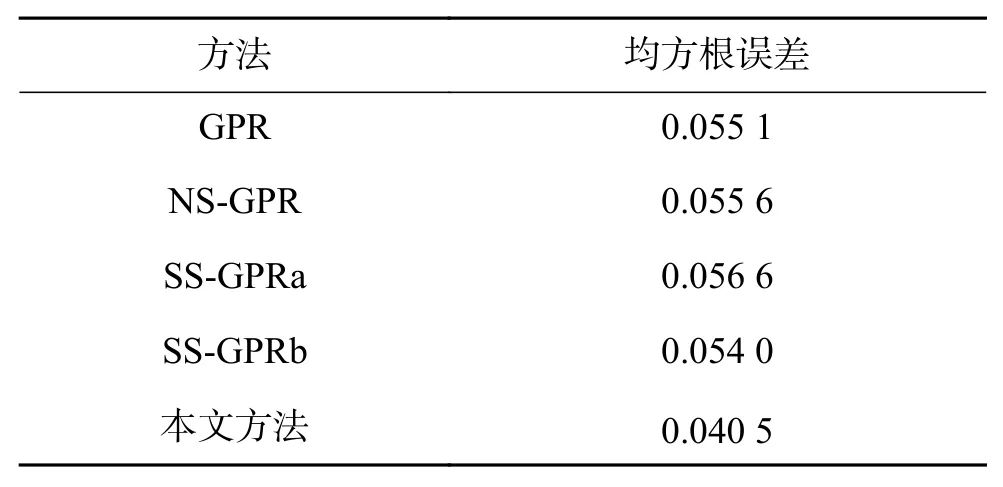
表 2 不同模型预测效果对比Table 2 Comparison of prediction effects of different models
5 结束语
本文提出的带双优选过程的半监督回归算法,基于两种优选准则,一方面筛选合适的无标签样本,另一方面筛选有标签样本,从而建立更有针对性的辅学习器,实现了对无标签样本的更准确地利用,达到了提升主学习器性能的目的。将算法进行数值仿真并应用于脱丁烷塔过程,实验结果表明,所提方法在有标签样本较少时,具有良好的预测效果,为半监督回归提供了一种新思路。
