基于多维度特征的饮食健康推荐
2019-07-16郝梓杰罗裕升朱珍民
喻 兵 郝梓杰 罗裕升 朱珍民*
1(湘潭大学 湖南 湘潭 411105)2(中国科学院计算技术研究所 北京 100080)
0 引 言
随着社会不断进步与发展,人们的生活质量不断提高,健康话题越来越被人们所关注。然而,不良的生活方式是导致慢性非传染性疾病不断增加的重要因素,其中,饮食方面尤为突出。因此,注重饮食的合理性和健康性,才能确保和维持人体中必需营养素的平衡性,避免慢性病的发生[1],从而提高人的寿命和健康水平。
如何为人们提供合理的饮食方案便成为世界各地营养学家的职责。如今,由于营养学家人数有限且行医水平参差不齐,人们想要便捷地了解自己的饮食状态并不方便。但是随着移动互联网产业的兴起,各种推荐系统应运而生[2],作用于不同应用的场景。最近几年也有学者尝试将推荐算法应用在饮食推荐中,例如:2012年,北京大学的孔令恺等[3]在传统的协同过滤基础上引入遗忘曲线和修改权重来修改菜品的统计值,然后运用相关算法计算出用户之间的相似度,从而以相似用户的下单数据当作该用户的推荐依据;同年,北京大学的陈曦等[4]充分利用智能手机感知周围情境信息的功能,设计了一个基于Android移动终端的结合地理位置、时间、美食特点和用户个人信息的推荐系统;2015年,电子科技大学的赵恒等[5]提出了一种基于LBS的本地美食推荐系统,该系统基于地理位置和混合推送策略为用户进行推荐;2016年,盛实旺等[6]基于改进的Apriori算法进行用户的饮食爱好分析,实现个性化推荐。
近几年饮食推荐的研究,基本是基于内容、关联规则和协同过滤的推荐,旨在挖掘用户的喜好并以提高点击转化率和商业价值为目的,在健康饮食推荐方面的研究依然十分匮乏。故此,本文提出一种合理有效的多维度饮食推荐方法,从而弥补在健康饮食推荐方面的不足。
1 菜品特征
本文菜品数据集包含中华菜系、疾病调养食谱、功能性调理膳食、人群营养膳食等几大类菜谱。经过格式整理,菜品包含多个字段。将菜名、图片、制作方法、制作提示、口感、推荐食用时间、营养解析、食物相克作为普通字段,这些字段无实际意义,仅仅作为菜品的展示信息;而工艺、口味、菜系、功效、主料、辅料、调料、营养成分作为核心字段,这些字段对用户的饮食分析起到重要的作用,需要进行特征处理。本文重点在于判断用户的饮食是否符合健康标准,为了保证菜品数据能最大程度地反映用户饮食结构,需要对菜品数据进行预处理与特征构造。
1.1 菜品数据预处理
通过数据统计分析,发现不同菜品的质量存在一定的差异,这可能导致各个成分含量存在较大的波动。为了提高本文推荐算法的准确率,故对所有数值型特征进行数据标准化预处理。
由于菜品数据在特征空间内存在较多离群点,导致空间分布不均匀并且各个特征维度有不同的量纲。故此,本文对数值型特征先进行ln函数平滑,再对平滑后的值进行Z-Score标准化处理,能让数值特征的分布更加均匀,并且对各个数值型特征的量纲进行了统一。
原始菜品数据集中,菜品质量不同导致营养成分含量不同,仅对“营养成分含量”特征进行统计无法刻画菜品营养结构信息。为了消除菜品质量对营养结构分析的影响,本文采用1-范数正则化对营养成分含量特征进行正则化,目的在于获取每个成分含量所占有营养成分含量的百分比,从而得到菜品营养结构的信息。由于营养元素分为宏量营养元素和微量营养元素,而微量元素含量的变化必然会被宏量元素含量掩盖,导致模型无法捕捉到微量元素的特征。为了解决宏量元素与微量元素含量差距过大的问题,使用Max-Min标准化,再正则化,能够更准确地刻画菜品的营养成分。
1.2 菜品特征构造
在CTR预估场景中,为了提高模型预测的准确率,常常将数值型特征转换为离散型特征,主要原因是特征离散化后对特征的表达更加合理。比如对于年龄特征,可能将20~30岁区间作为同一个离散值更合理,因为人们不会因为增加了1岁而改变兴趣爱好,同时也会增强模型对数据异常值的鲁棒性。
本文对用户的口味偏好进行挖掘,需要将“调料成分含量”做进一步的特征构造。为了对用户口味偏好进行更好的建模,本文采用GBDT算法[7]对“调料成分含量”特征进行离散化,将原始的调料成分特征作为GBDT的输入,口味特征作为label训练模型,最终得到150个特征个数。GBDT特征构造的原理步骤如下:
(1) 利用菜品原始调料成分作为特征和口味作为训练标签,进行GBDT特征训练;
(2) 训练完成后,将训练样本输入GBDT中,得到样本在每棵树的叶子节点的编号,再对该编号进行one-hot编码;
(3) 将第二步得到的所有one-hot编码拼接成一组新的离散化特征(特征长度为所有叶节点的个数)。
通过数据预处理和特征离散化,得到了菜品数据集的全部特征,共分为7组特征,其中前3个特征组为原始特征,4、5特征组为经过平滑和标准化后的数值型特征,6特征组为营养成分含量归一化和正则化后的特征值,7特征组为调料成分经过GBDT模型离散化后的值,具体的特征列表如表1所示。
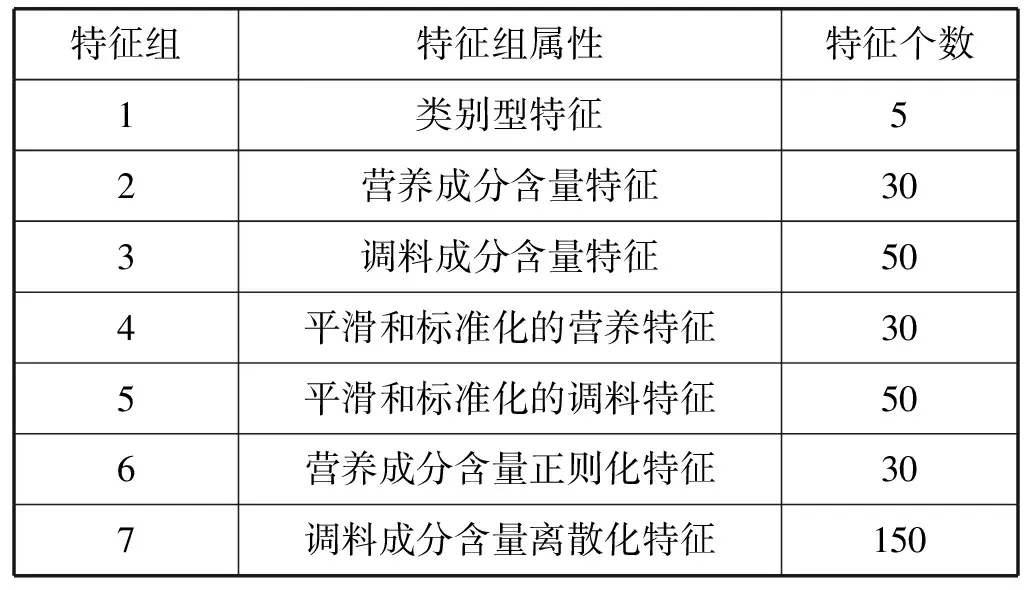
表1 菜品特征列表
对菜品进行数据分析,能够将菜品这个抽象的事物进行数字化或结构化的表征,使推荐算法能有效地猜测用户对菜品的所需和所爱。
2 多维度推荐算法
前面简单提到,大部分学者的饮食推荐工作主要以结合手机定位、社交网络等多维度的外部特征,从而最大化用户的点击率。与以最大化点击率为目标的个性化推荐算法不同,本文推荐算法是以调节用户饮食结构为主,口味挖掘为辅。因此,算法并未涉及到协同过滤等[8]传统的推荐技术,因为以最大化点击率为目标的推荐算法很大概率不符合健康标准。本文旨在基于用户画像、饮食记录、即时情境3种方式对用户进行饮食推荐,从而使用户饮食结构合理化。
2.1 基于用户画像的推荐算法
用户画像就是根据用户的人口属性、偏好习惯和行为信息而抽象出来的标签化画像[9]。基于该类特征可以准确定义不同用户的营养成分含量合理摄入区间的差异性。本文将用户画像定义为年龄、性别、身高、体重、过敏源、人群、疾病7个方面,其中人群包含7类:普通人群、老人、孕妇、乳母、婴儿、幼儿、青少年;疾病包含6类:高血压、高血脂、糖尿病、冠心病、脂肪肝、肝硬化。基于用户画像的推荐方式是确定性算法,可以形式化为:
y1=H(Df,Cf)
(1)
y2=G(y1,Qf,BMI)
(2)
y3=G(y2,Af)
(3)
式中:Df表示疾病特征,Cf表示人群特征,Qf表示历史摄入量,BMI表示体质指数,Af表示人体过敏原。通过形式化的表达可知,本推荐方式可分为3个步骤进行,从而产生最终的推荐列表y3,算法步骤可描述如下:
(1) 根据用户的疾病特征和人群特征的营养成分合理摄入区间进行菜品过滤,得到列表y1;
(2) 先对用户近期的菜品进行未达标和超标元素的统计,再对未达标和超标列表对y1进行不满足条件菜品过滤,然后根据BMI指数对脂肪含量极端值进行过滤,得到列表y2;
(3) 最后根据主料、辅料、调料成分含量,将推荐列表y2中具有过敏原的菜品数据进行过滤,产生最终推荐给用户的菜品列表y3。
通过上述算法,以用户画像为依据,判断用户近期饮食是否符合该画像的膳食指南,从而可以推荐最满足该用户身体状态的菜品列表。
2.2 基于饮食记录的推荐算法
饮食记录是用户在本实验平台上操作的所有行为记录,比如食用、喜欢、不喜欢等,该类特征可以有效挖掘用户的饮食偏好,从而判断用户的营养结构是否合理并且挖掘出用户喜爱的口味。
2.2.1基于营养结构的推荐算法
在营养结构挖掘中,聚类与分类的不同在于,聚类所要求划分的类是未知的,根据信息相似度进行信息聚类;而分类是每个样本数据已有类标识,然后将该对象归为对应的类中。因此,本文通过聚类的方法将包含相似营养成分的菜品聚在相同的簇内,达到分类的效果。算法步骤如下:
(1) 将所有菜品数据按表2中的4、6特征组进行聚类,簇数可以调整;
(2) 判定该用户最近K次食用的菜品,统计其簇数分布;
(3) 推荐该用户食用簇数最少的簇内食物,目前采用随机推荐。
2.2.2基于用户口味的推荐算法

VDM定义如下:令mu,a表示在属性u上取值为a的样本数,mu,a,i表示第i个样本簇中属性u上取值为a的样本数,k为样本簇数,则属性u上两个离散值a与b直接的VDM距离公式如下:
(4)
类VDM定义如下:对于每个用户来说,mu,a表示所有食用的食物中属性u上取值为a的菜品数,mu表示所有食用的食物中具有属性u的菜品数,所以类VDM距离公式如下:
(5)
基于上述的类别型特征距离计算方法,再结合传统的数值型特征距离计算方法,便可以对菜品数据进行距离计算,从而挖掘出相似口味的食物。口味挖掘算法步骤如下:
(1) 将所有菜品数据特征进行表示,查询该用户最近的M次饮食记录,利用本文提出的类别型距离计算公式计算各个类别间的距离;
(2) 在全集菜品中,以距离远近为标准选择口味最相似的N个菜品进行推荐。
上述两种算法都是依据用户的饮食记录,产生不同的推荐列表,分别满足用户营养均衡需求和用户口味偏好的需求。
2.3 基于即时情境的推荐算法
前两种推荐算法主要侧重于用户属性和历史记录推断“用户应该吃什么”和“用户可能爱吃什么”。但是依据静态特征所做出的判断,往往没有考虑到即时情境的影响。本文将此时的时间、此时的运动消耗作为特征,提出一种即时情境的推荐方式。
本文将饮食时间划分成早、中、晚3个时间段,运动量划分成低、中、高3个等级(基于运动步数划分),并且用户的饮食热量含量应该随着时间中、早、晚和运动量高、中、低依次递减。将用户的即时状态编码成两位的字符,例如“00”代表此时是晚上并且用户运动量低,需求等级为0,此时需要最低热量的食物即可;“22”代表此时是中午并且运动量高,需求等级为4,此时需要最高热量的食物比较合适。该推荐算法步骤如下:
(1) 获取用户特征、用户近期饮食的菜品以及用户饮食的行为;
(2) 依据用户特征、用户近期饮食的菜品特征,采用上述用户画像推荐算法得到推荐列表y1;
(3) 依据用户近期饮食行为,采用上述饮食记录推荐算法得到推荐列表y2;
(4) 获取用户当前时间与运动步数,将用户的即时状态进行编码;
(5) 根据用户的编码,依次在y1和y2列表中返回与用户热量需求等级最相近的菜品。
该推荐方法与前两种推荐方法属于递进关系,即在前两种推荐列表的基础上考虑了即时情境对饮食的影响,将时间和用户运动量特征作为外部特征对前两种推荐列表进行重排序,产生菜品列表。
3 实验结果与分析
3.1 基于用户画像的实验分析
依据营养学会针对不同疾病和人群的膳食营养指南,制订了各个营养摄入量规则。其中不同人群、不同病种的膳食指南可简化抽象如表2所示。

表2 不同人群和不同疾病膳食指南概括
本实验的具体步骤如下:
(1) 随机模拟不同的用户画像;
(2) 根据模拟用户的疾病、人群特征在全集菜品中初步筛选出所有符合该用户特征的菜品;
(3) 根据该用户的近期饮食记录和BMI值,并按规则对菜品进行二次筛选;
(4) 过滤过敏源,产生最终符合条件的菜品进行推荐。
基于用户画像的推荐是基于领域知识设定规则的推荐。本研究共进行了50次不同用户画像的随机模型实验,通过对各类用户画像的推荐菜品进行原始营养元素含量数据的均值统计,并与全集菜品的相关营养元素含量的均值统计值进行对比;针对不同疾病和不同人群,模拟用户1和用户2,假设用户1是一位患有高血压的孕妇,用户2是一位患有高血压的老人;分别列举两组推荐菜品的统计信息,统计其相关营养元素含量进行比较,实验结果如图1和图2所示。

图1 高血压推荐菜品与全集菜品的营养元素对比

图2 高血脂推荐菜品与全集菜品的营养元素对比
根据BMI指数对菜品数据中“脂肪含量”高于或低于一定阈值的菜品进行过滤,从而进一步产生合理的推荐列表。针对上述高血压孕妇的案例,模拟用户3和用户4,其BMI指数分别高于正常值和低于正常值,对比营养元素变化。实验结果如图3和图4所示。
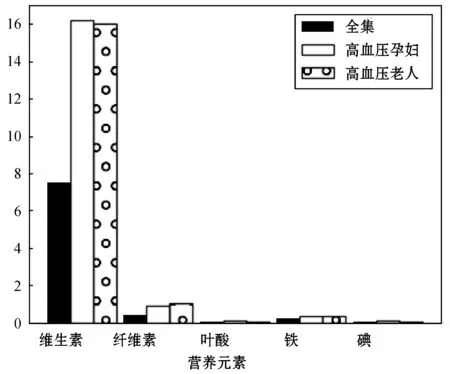
图3 双重条件改变时营养元素含量变化
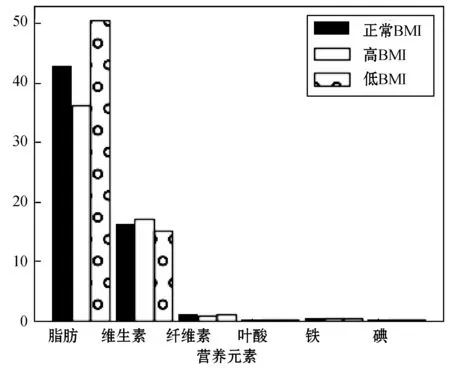
图4 BMI指标变化时营养元素含量变化
将图1、图2与表2作对比可知,表2的所有指标,均符合膳食指南建议,从而证明了本推荐算法对于单一人群或疾病特征具有有效性。
由图3可知,在双重条件控制下,本算法依然可以返回相对合理的菜品推荐列表。在关键营养元素上,由于人群特征的不同而导致其含量不同,例如“叶酸含量”和“碘含量”在高血压孕妇推荐菜品相比于高血压老人推荐菜品会有一倍以上的提升,同时也能保证“纤维素含量”、“维生素含量”等均保持较高的水平。
由图4可知,在BMI指数过高时,推荐菜品的平均脂肪含量会相对下降,而在BMI指数过低时,推荐菜品的平均脂肪含量会相对上升,并且对于疾病和人群特征的关键营养元素的含量没有发生太大变化,依然符合膳食指南标准,从而证明了本推荐策略的有效性。
3.2 基于用户饮食记录的实验分析
3.2.1营养结构实验分析
本文根据用户最近饮食记录,对菜品进行聚类分析。聚类性能度量的方法大致分为两类:(1) 人工标注的外部指标;(2) 内部指标。因为本数据集中的所有菜品数据均缺少营养结构标注,所以本研究采用内部指标作为聚类算法效果的度量指标。假设某聚类算法对数据集的簇划分为C={C1,C2,…,Ck},则有如下定义:
(6)
diam(C)=max1≤i≤j≤|C|dist(xi,xj)
(7)
dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj)
(8)
dcen(Ci,Cj)=dist(μi,μj)
(9)
式中:dist()函数代表两个实例之间的距离计算公式;μ代表簇C的中心点,avg(C)表示簇C内样本间的平均距离,diam(C)表示簇C内样本间的最远距离,dmin(Ci,Cj)表示簇Ci和Cj最近样本间的距离,dcen(Ci,Cj)表示簇Ci和Cj中心点间的距离。基于上式,可以导出下面两个常用的聚类性能度量内部指标,DBI值越小越好,DI值越大越好。
1) DB指数DBI(Davies-Bouldin Index):
(10)
2) Dunn指数DI(Dunn Index):
(11)
本文分别考虑K-means[10]和DBSCAN[11]两种不同的聚类算法。K-means算法是一种无监督的聚类算法,它被称为K-平均,由于聚类效果不错,被广泛使用。DBSCAN算法是一种基于密度空间的聚类方法,它不易受到噪声样本的干扰,可以有效地分离出噪声样本。本文将两种算法的聚类簇数控制在3、5、7个,进行度量指标的对比。实验结果如图5和图6所示。

图5 K-means和DBSCAN在DBI指标对比

图6 K-means和DBSCAN在DI指标对比
当cluster=5时K-means算法的DBI指数略差于DBSCAN,其余指标均优于DBSCAN算法。故本文采用K-means算法进行营养结构分析,进而为用户进行合理的膳食推荐。本文的特征达到60维,无法直接进行可视化效果展示,故经PCA降维,cluster=5时,K-means与DBSCAN的聚类效果比较如图7所示,左侧为K-means效果,右侧为DBSCAN效果。

图7 K-means和DBSCAN的聚类效果展示
3.2.2口味偏好实验分析
本文采用类VDM计算特征距离的相似度,挖掘出与用户饮食记录最相似的食物进行推荐。本文共进行了50组模拟实验,分别对类VDM距离计算相似度和传统欧式距离计算相似度进行对比。每次实验输入一组菜品代表用户历史饮食记录(分别设置历史记录长度为1、3、5进行实验),两种相似度计算方法分别返回最相似的Top10菜品,并由5位志愿者对结果进行标注,准确率如图8所示。
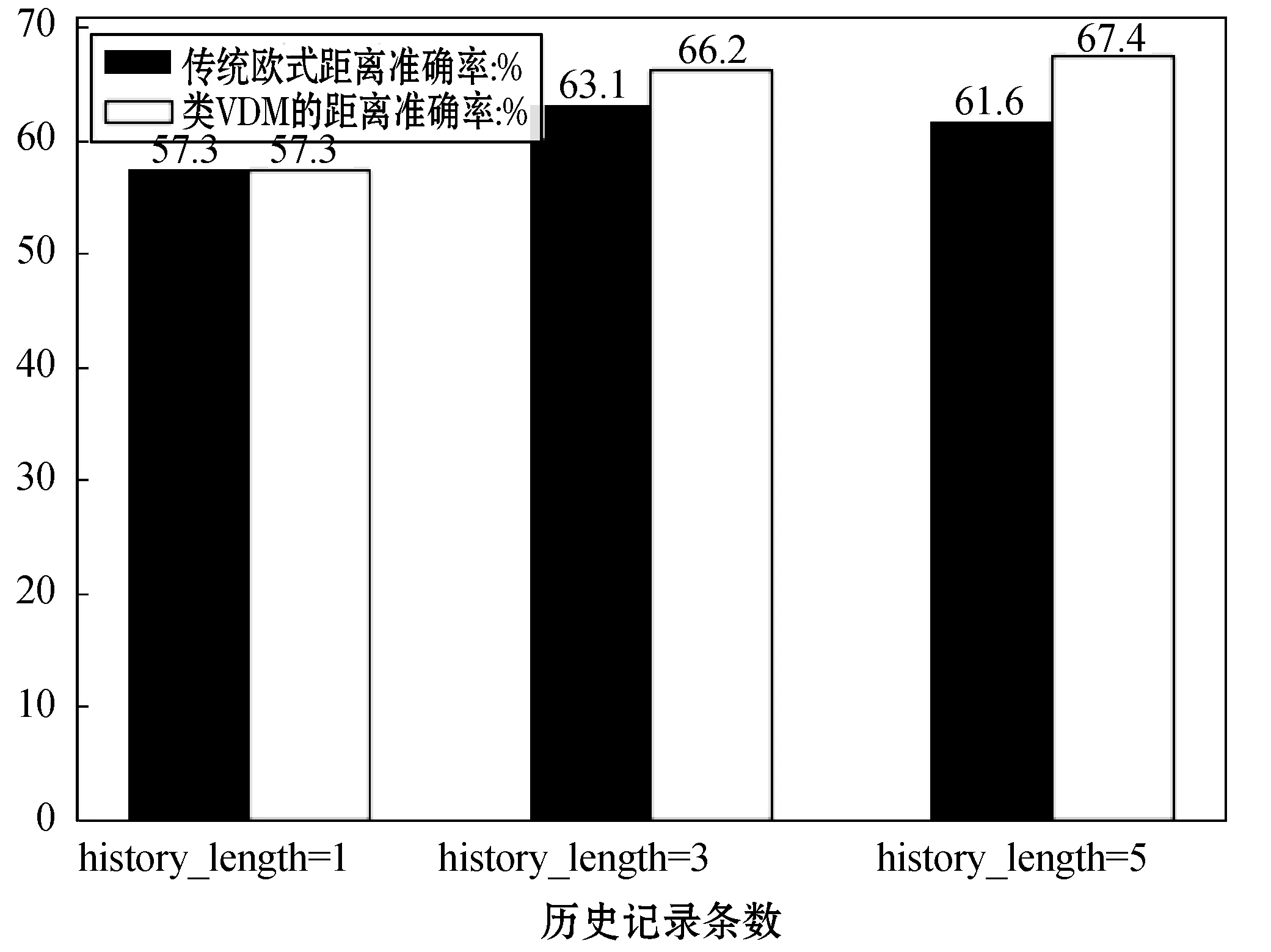
图8 两种距离计算方式准确率对比
由实验结果可知,在仅考虑1个历史饮食记录时,本方法和基于欧氏距离的计算方法没有任何差别,返回相同的结果。但随着历史记录的增长,本方法在类别型特征相似度计算上相比与原始方法有了较大优势,在历史长度为5时,准确率可以达到67.4%,故验证了本方法的有效性。
4 结 语
在快节奏生活和高强度工作下,人们的健康状态难以得到保障,本文在充分掌握了各种人群膳食指南的基础上,利用多种数据处理方法、GBDT自动特征构造和不同聚类算法等,提出了一种基于用户画像、饮食记录、即时情境的饮食推荐算法,旨在帮助人们改善饮食结构,合理化不同营养元素的摄入量,从而达到健康饮食的目的。本文存在的不足在于用户的饮食记录行为数量不足,缺少线上用户饮食数据进行对比。本文后续工作将使实验平台上线获取更多的用户饮食数据进行迭代优化,使得推荐效果更加准确;基于用户画像的推荐和基于饮食记录的推荐相结合,对画像产生的推荐列表根据口味偏好进行排序;在基于即时情境的推荐方面做很多深入的研究,例如可以与无创生理指标检测方面的算法进行融合,挖掘更多的即时情境等。本文具有重要的实际应用价值,可帮助人们改善饮食结构、预防慢性疾病的发生,提高全民的健康素养。
