改进的Apriori算法的研究与应用∗
2019-07-13张可佳
李 龙 刘 澎 张可佳 黄 珊 李 倩
(东北石油大学计算机与信息技术学院 大庆 163318)
1 引言
数据挖掘是对大数据集的探索过程,并揭示出其中的隐含规律,它融合了众多的技术,是计算机科学的一个重要分支[1]。利用数据挖掘技术进行数据分析,是一项极具现实意义的尝试,它能够加速理论知识到实际应用的转化。其中关联分析是数据挖掘中重要的分析技术之一,关联分析是从历史数据集中发现隐含模式,从海量数据集中发现潜在价值的方法,它反映过了一个事件与其他事件相互关联的关系。
随着信息化时代的到来,各类公司积攒了大量的数据,如何利用这些长期积攒的数据成为了主要问题[2]。本文主要针对股票的历史交易数据进行挖掘,指导投资者合理购买股票,达到辅助决策的效果。
目前,部分研究学者提出了经典的Apriori关联规则挖掘算法[3~5],提出了股市中关联规则挖掘方面的相关技术应用。本文在具体探究中的研究目标是挖掘频繁项集中涉及到的Apriori算法,并将其改进。针对股票板块联动关联规则挖掘这一问题,提出一种改进的Apriori 算法。在目前传统Apriori算法的基础上改进算法中数据库的扫描次数,筛选出有用候选集,提高算法的利用效率。
2 改进的Apriori算法
目前研究学者提出的改进Apriori 算法[6~10]对扫描数据库的次数与时间过程的考虑较少,对Apriori 算法的研究并没有克服全部的局限性[11~15],没有做到将Apriori算法的运算时间效率提高。
本文在深入研究传统的Apriori算法的基础上,提出一种改进的Apriori-L 算法,优化频繁集的计算过程,提高算法的运行时间效率,对二项频繁集数目超过二项的频繁集方面的操作在具体实践应用中起到关键性的意义。
2.1 算法描述
综合性的结合Apriori 算法在学术界中相关的研究过程和现有的实验结果分析,可知算法在运算扫描过程中耗费时间多[16~20],筛选候选集是s函数,同时也是计算支持度的函数和产生过频繁项集的函数,进一步分析算法在运算过程中耗费时间长的原因主要有以下两方面:
1)候选集过多的问题。在频繁集生成候选集的过程中,即由k-1生成k的过程中,利用关联规则得到所有k 项集合作为候选集,部分K 项集存在对算法结果无用的现象。此时,这些无效的K 项集会造成算法时间的耗费。
2)算法在整个扫描操作中会产生比较多的扫描次数。在相关的扫描事务集、支持度的分析与计算、频繁集的获取操作中,算法应用中的循环次数与候选集数量两者之间的关联性有很强的关系,如果候选集的数量庞大,直接影响算法在运行过程中的时间效果。
综上所述,针对目前传统Apriori算法在具体应用中所存在的不足之处,本文结合实际问题制定出科学可行的改进算法-Apriori-L 算法。改进后算法的主要思路如下:
1)首先,将一项频繁集L 获取到,并与每一个事务集进行合并操作,找出每个事务集中频繁性小的数据,将其删除,获得W。
2)其次,在W中找出所有的二项子集cu。
3)再次,二项候选集z 由cu 生成,将二项候选集z 作为关键值存入一个h 表中。如果h 表中己经存在将要存入的关键值,把与这个关键值相对应的v值在应用中加1处理;若h表中没有所需存入相关关键值,需要把key 直接存储在h 表中按照专业性的流程有效处理,同时将其对应的v值变成1。
4)最后,在h 表中将关键值变成二项候选集z,关键值对应的v即为该二项候选集z的支持度。
2.2 算法分析
假设事物集a中的事物项的数量为b,n为平均元素在事物项中,L1代表的是一项频繁集在算法应用中的实际数量。
假设O(n)指的是各个事物项在算法操作中和频繁集所有时间的复杂度,O(Cn2)代表的是二元子集在具体操作中的时间复杂度情况,O(1)是指存入表与v值在操作中加1的时间复杂情况。
基于上述综合性的分析可知,在进行二项候选集Cz获取时,将支持度进行综合性分析计算的操作过程中,Apriori-L的时间复杂度表示如下:
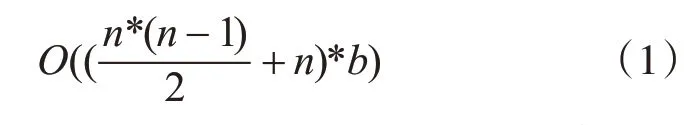
对上述步骤按照专业性的规范流程进行扫描,即可有效地获取到候选集的支持度h 表s,并对每一个候选集在算法应用中的支持度和最小支持度关系的时间复杂度进行判断并表示如下:
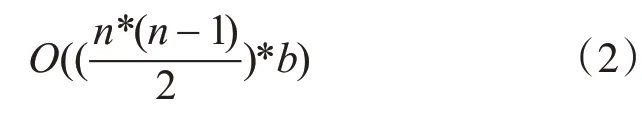
由式(1)、(2)可知,Apriori-L 在生成二项频繁集的过程中的时间复杂度为

通过综合性的对比分析,能够明确地推断出Apriori 算法在形成二项频繁集过程中的时间复杂度情况。
在进行二项候选集C2 获取的算法操作时所对应的时间复杂度表示如下:

事务集的扫描、支持度的分析计算以及频繁集选取所对应的时间复杂度表示如下:

由式(4)、(5)可知,Apriori 算法在生成二项频繁集的过程中的时间复杂度为

综上所述,可知Apriori算法在运算过程中比改进的Apriori-L 算法需多运算L21,对比分析Apriori算法与Apriori-L 算在的时间复杂度表示情况能够明确的推断出,Apriori-L算法在进行二项频繁集生成的操作中,能够科学精确地获取到L21/n 在算法应用中的加速效果,可提高算法的使用效率。
Apriori算法在生成二项频繁集时,时间复杂度与L12有重要的关系,一项频繁集数量L1直接影响算法的运行效率,如果L1数量特别多,则算法的使用效率变低。而在Apriori-L 算法中,生成二项频繁集的过程与L1关联性不大,与事务项中的元素平均数量n 的关联性较强,n 作为事物集中的平均数量,n 小的情况下,该算法可以对算法的运行效率产生较好的影响,即提高运行效率。在实际生活中,有许多一项频繁集数量大于事物集中平均元素数量的基本现象。比如说,水果超市中销售的水果类别要超过平均每一位顾客所选购的水果类别的实际数量。
3 Apriori-L算法的实际应用
股票模块是按照上市的股票进行的分类,主要包括行业、概念、地区等方面,本文主要对30 个模块采取科学的方式进行关联性分析操作。这些模块在算法应用中主要涉及到酒店餐饮、旅游、石油和电力等诸多专业性的模块。把模块联动看为一个模块的涨和跌和另外一个模块的涨和跌相互影响。对于投资者来说获取模块的联动信息的价值十分重要。利用经验去判断模块间的关系缺乏科学依据,如旅游行业和酒店餐饮行业两个模块通过经验可以分析出具有一定的关联性,可是关联的强度靠经验较难判断。现有的挖掘股票数据的方法主要有Apriori算法,利用此算法可以得出确切的模块间联动信息,指导投资者进行股市投资,帮助股市投资者及时规避风险。
本文在具体分析中采取科学的理论提出了改进的Apriori算法,实践操作中对各行业模块间的所存在的关联规则有效的挖掘,与以往探究板块间关系的方法具有很大差别,本文在原有研究方法的基础上,对不同模块的涨跌幅度联动性结合实际情况综合性的探究,根据在实践应用中的每一种涨跌幅其模块之间的关联性的数据挖掘,对于股市投资者全面明确模块之间的联动的关联规律起到直接性的促进作用。
3.1 数据预处理
对板块每一天的具体涨幅情况进行综合性的分析计算,深入化的探究海量的测试数据集在算法应用中的数据分布状况,将每个模块的涨幅划分为6 个部分:0<幅度<0.01;-0.01<幅度<0;0.01<幅度<0.03;-0.03<幅度<-0.01;幅度>0.03;幅度<-0.03。板块的幅度在实践操作中能够均匀有序的归入到这6 个种类中是主要的划分准则。按照专业性的规范标准将幅度区间有序的划分,为每一个模块所对应的幅度区间合理的排号。表1 是每日的模块数据的具体转化情况。
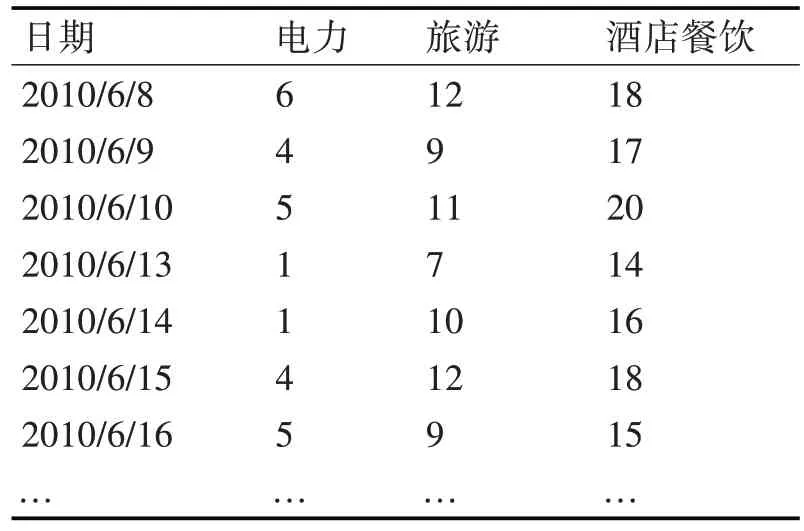
表1 部分模块数据
综合性地把排号和数字6 科学的运算所获取到的值与数字6 中的某种状态是相互对应的。处理好的数据后存入到数据库中。对处理后的数据采用sql进行检测,结果如下:
1)未在数据中发现空值、冗余值,2322 条记录与2322 天30 个板块指数的情况一一对应,完整性良好。
2)利用统计方法,找出所有板块每天的涨幅几乎均落在6 种状态下。因此可知涨幅区间的划分是合理有效的。
3.2 频繁项集
通过对不同的最小支持度的调整,对Apriori算法以及Apriori-L 算法分别科学的分析与挖掘数据的频繁集。
基于各种支持度的实际情况可知,图1 是原始Apriori 算法和Apriori-L 算法在二项频繁集计算过程中相关运行时间的具体示意图。

图1 不同支持度下的运行时间
支持度320 下,Apriori算法和Apriori-L 算法在进行关联规则算法应用中总时间和二项频繁集时的时间计算的综合性对比情况如下图2 和图3 所示,其中a为计算二项频繁集时间,b 为计算关联规则总时间。
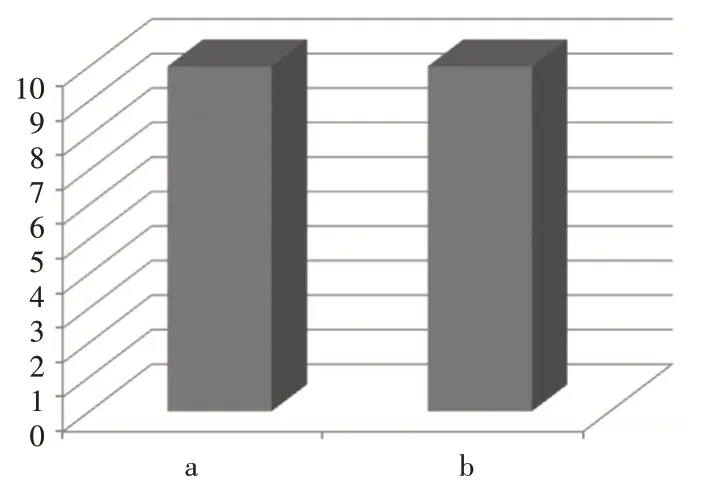
图2 Apriori算法
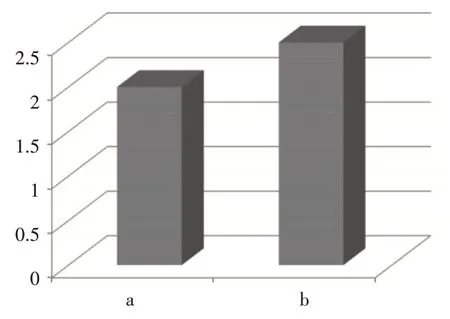
图3 Apriori-L算法
由图2、图3 的实验结果可知,在支持度320下,改进后的Apriori-L 算法相比较原Apriori 算法可提高算法中二次频繁集的计算时间效率值约为81.5%,可提高算法总体运行时间效率值约为78.5%。
综上可知,Apriori-L算法的性能与原始Apriori算法相比有很强的优势,Apriori-L能够在实践应用中展现出较强的算法功能特性。
3.3 计算关联性
在实践应用中选取支持度320 下的相关频繁集,结合实际需求将置信度设置为0.8,在此基础上采取专业性的操作方式计算关联规则,获取到如表2所示的具体计算结果。
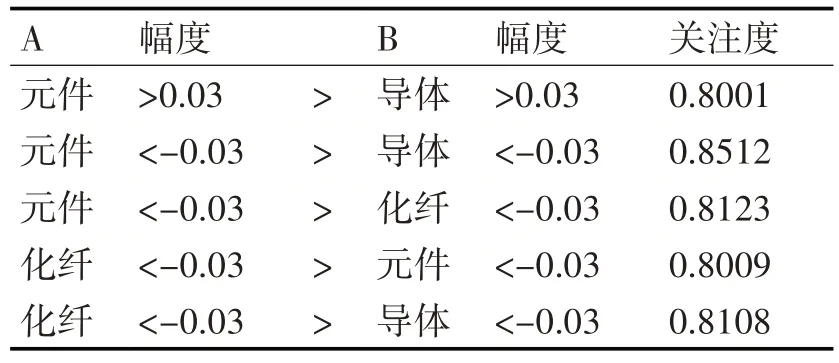
表2 部分模块联动性
在计算关联规则的综合性操作过程中能够有效地获取到元件、导体、化纤这三个主要的板块在涨幅区间中具体的关联规则情况。如果元件涨幅超过0.03,导体模块可能大于0.8001 的涨幅情况会超过0.03。所以投资者在观察到元件涨幅超过0.03时,可以对导体模块加强关注。
与根据模块的是否涨跌来进行关联挖掘相比,新的基于涨跌幅关联挖掘可以排除股市小幅正常涨幅的影响;获得信息也更加具体精确,相同模块中的不同涨跌幅度在一定程度上和不同的模块会产生联动作用。
4 结语
对股市的历史数据进行关联规则的挖掘分析对股市的投资者具有重要的指导意义。Apriori 算法作为挖掘频繁项集最重要的一种算法具有较好的意义,但是算法运行效率有一定的缺陷性。本文提出的Apriori-L 算法先分析时间复杂性,再在分析的基础上找出在人们日常生活中的实际性,在弥补算法不足的基础上将算法应用到实际中发现本文的方法对提高算法的运行效率具有一定意义。本文将提出的算法应用到股市模块联动性的挖掘中,改进后的Apriori算法能够快速发现不同股票模块的不同幅度之间的联动规则,可为股市投资者提供数据信息支持,为决策提供数据支撑。
