Django实现ORM模型数据查询优化
2019-07-11郭显娥
郭显娥
(山西大同大学计算机与网络工程学院,山西大同037009)
通常情况下,数据库查询使用原生的SQL语句实现。随着项目越来越大,采用写原生SQL的方式在代码中会出现大量的SQL 语句,如下问题就出现了:
(1)SQL 语句重复利用率不高,越复杂的SQL语句条件越多,代码越长。会出现很多相近的SQL语句;
(2)很多SQL 语句是在业务逻辑中拼出来的,如果有数据库需要更改,就要去修改这些逻辑,这会很容易漏掉对某些SQL语句的修改;
(3)写SQL 时容易忽略web 安全问题,给未来造成隐患。
Dango开发使用ORM 模型的查找操作,大多是基于QuerySet 上的一些 API 的使用,通过Filter、Exclude以及Get 三个方法来实现,在调用这些方法的时候传递不同的参数来实现查询需求[1-3]。
1 Django与ORM概述
1.1 Django简介
Django 已经成为web 开发者的首选框架,是一个遵循 MVC 设计模式的框架。MVC 是 Model、View、Controller 三个单词的简写,分别代表模型、视图、控制器。
Django 其实也是一个MTV 的设计模式。MTV是Model、Template、View三个单词的简写,分别代表模型、模版、视图。
1.2 ORM简介
ORM,全称Object Relational Mapping,叫做对象关系映射。通过ORM 类的方式去操作数据库,而不用再写原生的SQL 语句。其原理是把表映射成类,把行映射作实例,把字段映射为属性。ORM在执行对象操作的时候最终还是会把对应的操作转换为数据库原生语句。使用ORM 有如下优点:
(1)易用性:使用ORM 做数据库的开发可以有效的减少重复SQL语句的概率,写出来的模型也更加直观、清晰;
(2)性能损耗小:ORM 转换成底层数据库操作指令确实会有一些开销。但从实际的情况来看,这种性能损耗很少(不足5%),只要不是对性能有严苛的要求,综合考虑开发效率、代码的阅读性,带来的好处要远远大于性能损耗,而且项目越大作用越明显;
(3)设计灵活:可以轻松的写出复杂的查询;
(4)可移植性:Django 封装了底层的数据库实现,支持多个关系数据库引擎,包括流行的MySQL、PostgreSQL 和SQLite。可以非常轻松的切换数据库。
2 利用Django搭建ORM模型
2.1 ORM模型创建
ORM 模型一般都是放在app 的models.py 文件中。每个app 都可以拥有自己的模型。并且如果这个模型想要映射到数据库中,那么这个app 必须要放在settings.py 的INSTALLED_APP 中进行安装。本项目中app 命名为front,实验需用的四个ORM模型分别为:Author 模型(见图1)、Publisher 模型(见图2)、Book 模型(见图3)与Book_order 模型(见图4)。

图1 Author模型

图2 Publisher模型
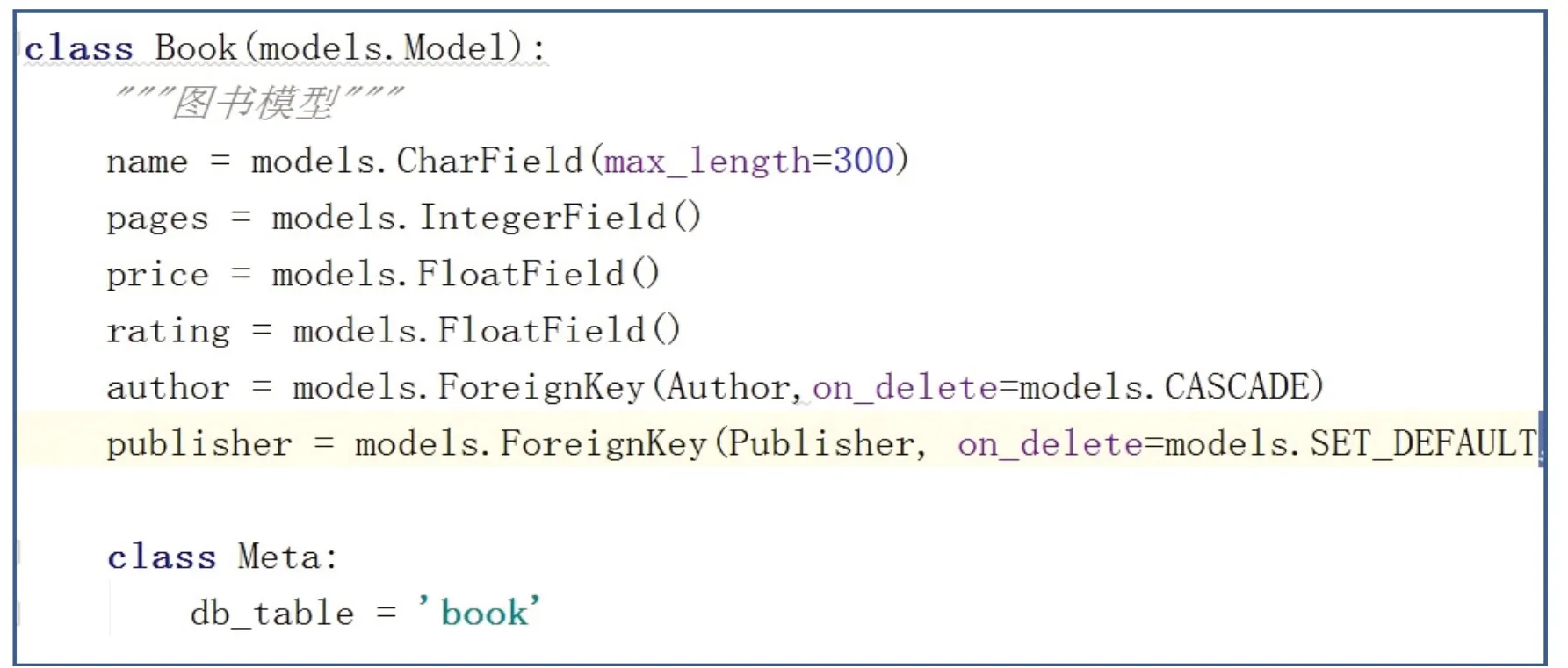
图3 Book模型

图4 Book_order模型
2.2 映射模型到数据库中
将ORM 的四个模型映射到数据库中。步骤如下:


Step2.在项目同名目录下的__inti__.py 中初始化 mysql 驱动,告诉 django 用 pymysql 驱动,代码如下。
import pymysql
pymysql.install_as_MySQLdb()
Step3.在命令行终端,进入到项目所在的路径,然后执行命令python manage.py makemigrations生成迁移脚本文件。
Step4.同样在命令行中,执行命令python manage.py migrate 将迁移脚本文件映射到数据库中,生成相应的数据库表:author表、publisher表、book表和book_order表。
2.3 录入表中原始数据
分 别 在 author 表 、publisher 表 、book 表 和book_order 表中录入3 至6 条记录,数据清单见下图:author 表(图5)、publisher 表(图6)、book 表(图7)和book_order表(图8)。
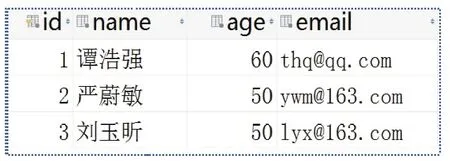
图5 author表数据

图6 publisher表数据

图7 book表数据

图8 book_order表数据
2.4 视图函数的实现
视图写在app 的views.py 中。视图的第一个参数是request 对象。这个对象存储了请求过来的所有信息,包括携带的参数以及一些头部信息等。在视图中,一般是完成逻辑相关的操作。比如这个请求是添加一篇博客,那么可以通过request来接收到这些数据,然后存储到数据库中,最后再把执行的结果返回给浏览器。视图函数的返回结果是HttpResponseBase 对象。示例代码如下:

2.5 URL映射
视图创建后,要与URL进行映射,也即用户在浏览器中输入什么url 的时候可以请求到这个视图函数。在用户输入了某个url,请求到网站的时候,django 会从项目的urls.py 文件中寻找对应的视图。django 会从urls.py 文件中urlpatterns 变量中读取所有的匹配规则。示例代码如下:

3 数据查询及优化
3.1 问题提出
在book 模型(图3 与图7)中,首先查询与book对应的author 数据,即每本书对应的作者;再次查询与book 对应的bookorder 数据,即每本书的订单情况。
3.2 数据查询使用的方法
数据库相关联表的存在如下四种关系:一对多、一对一关系,多对一、多对多关系,下面分别分两种情况实现查询的优化。
3.2.1 一对多或一对一查询的传统方法
针对3.1 问题之一,先用传统方法实现:第一步查询所有的book,第二步遍历books,查询作者的信息,在每本图书上发生一次查询。Views.py 源代码为:

测试结果分析(图9):本例共有三本图书,共发生四次查询,如果增加图书的数量,查询次数随之增加。设有n本图书,那么发生的查询次数就是n+1次。
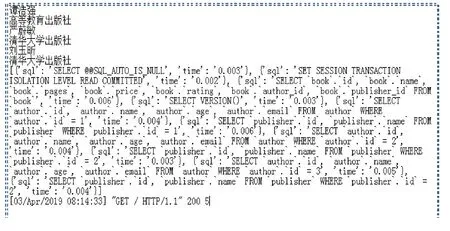
图9 优化前测试结果
3.2.2 select_related方法实现查询优化
使用select_related 方法,可以实现一对多或一对一查询的优化,将传统方法中的:
books=Book.objects.all()
改为:
books= Book.objects.select_related("author","publisher")测试结果数据见图10。
分析其原理,对于相关联的模型,查找book时一次性地查找相关联的其它数据,并放入缓冲区备用,而不用每次从数据库中查找。
用select_related 方法优化后,本实例只发生一次查询,如果图书数量增加,也同样只发生一次查询。这样节省了开销,提高了查询效率。
但是,select_related 只能用在一对多或者一对一中,不能用在多对多或者多对一中。下面引入prefetch_related 方法,实现多对一或一对多查询优化。
3.2.3 prefetch_related方法实现查询优化
针对3.1 问题之二,使用prefetch_related 方法,实现多对一或多对多查询优化。Views.py 源代码为:


测试结果见图11。
prefetch_related:这个方法和 select_related 非常的类似,就是在访问多个表中的数据的时候,减少查询的次数。这个方法是为了解决多对一和多对多的关系的查询问题。优化后,本实例只发生两次查询,如果图书数量增加,也同样只发生两次查询,大大节省了开销。

图10 select_related优化后测试结果
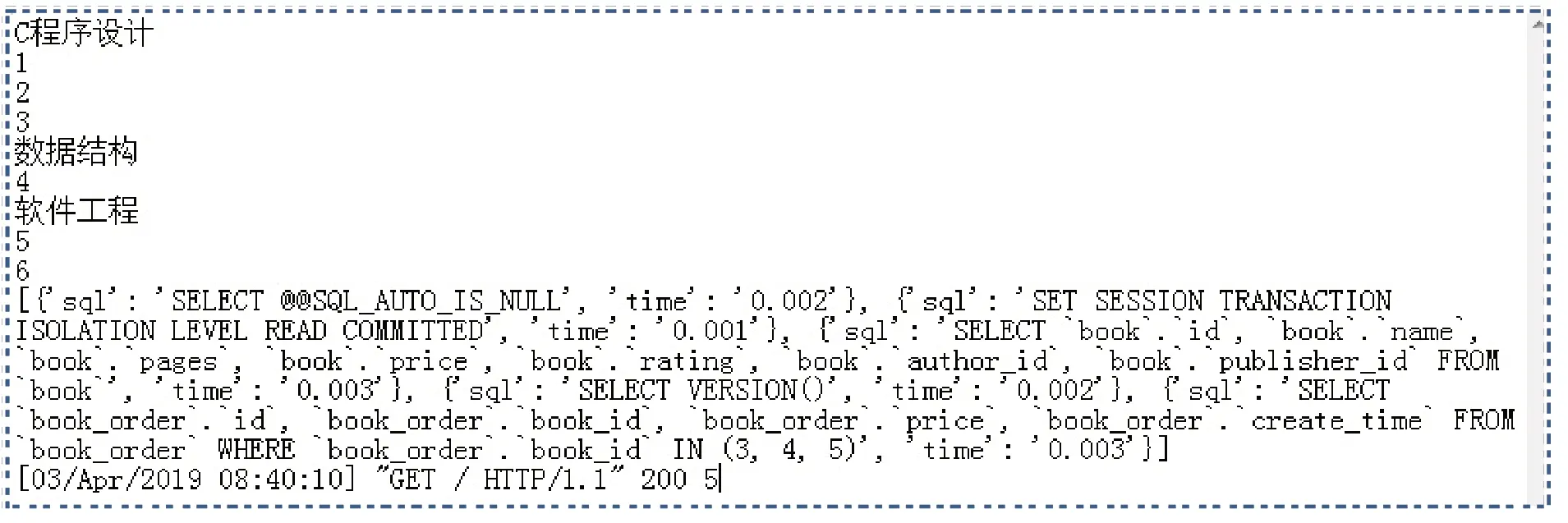
图11 select_related优化后测试结果
4 结语
介绍的两种方法select_related与prefetch_related 有各自不同的应用场景。前面已经实现了查询图书信息时一次性地把图书订单也查询出来,若在此基础上另增需求,查询图书订单是给定限制条件的,也就是在上述两种方法基础上能否使用fileter做进上步的过滤呢?会不会把已有的优化算法破坏掉?那如果确实是想要在查询的时候指定过滤条件该如何做呢,这时候就得使用django.db.models.Prefetch 来实现,用Prefetch包裹后,即使在查询文章的时候使用了filter,也只会发生两次查询操作。
