X射线图像语义分割及其应用
2019-07-09杨叶金承圭吴志敏
杨叶 金承圭 吴志敏*
1 伊士通(上海)医疗器械有限公司 (上海 200438)
2 Vieworks Co.,Ltd.(慧理示先进技术公司) (韩国 首尔14055)
内容提要: 随着计算机技术尤其是图像识别领域的发展,X射线人体图像信息可以被智能识别,这为AI人工智能诊断提供基础。文章通过对图像语义分割,解读部位信息,对限束器区域内图像对比度增强处理、骨密度测量,通过曝光指数计算判断获取的图像是否适合预期的图像质量水平,以进一步指导操作技师选择合适的曝光剂量。
X射线图像一般是灰度图像,反映了X射线经过人体衰减的图像信息。对骨骼、软组织疾病是一种较好的临床诊断方法。随着计算机技术尤其是图像识别领域的发展,X射线人体图像信息可以被智能识别,这为AI人工智能诊断提供基础。分割是图像处理中的一个重要课题,在X射线图像处理中也有应用。本文提出了一种X射线图像的语义分割方法,并将其应用于限束器区域内图像检测和曝光指数的计算。本文描述了一般语义分割、基于深度学习的语义分割的数据组织及其应用。
1.语义分割
语义分割旨在理解像素单位意义上的图像表达方式,不像一般的分割,使用像素值或梯度信息。如图1所示,这不仅涉及到分割图像的区域,还涉及到将图像信息分类为预定义的内容,如地面、草、树、天空、建筑等。
如图2所示,是一些用于语义分割的公共数据集。图2a显示了Pascal VOC数据集的一个示例,其中包含20个类和10K幅图像[1];图2b显示了来自MS COCO数据集的示例,其中包含91个类和120K幅图像[2];图2c显示了来自Cityscapes数据集的示例,其中包含30个类、5K幅高质量像素级注释图像和20K幅弱注释图像[3]。这些公共数据集对分割、识别研究有很大的贡献。

图1. 语义分割

图2. 公共数据集例(2a.Pascal VOC;2b.MS COCO;2c.Cityscapes)
2.数据集
2.1 结构
用于语义分割的公共数据集是由普通色彩图像组成,其完全不同于X射线图像。一幅X射线图像通常是由灰度像素组成,其灰度动态范围要远高于自然色彩图像。两者最大的区别是,在X射线图像中的语义分割由于骨骼重叠,每个像素区域都可能归为多个标签。如图3所示,方框区域内像素可能归类为“目标Object”“骨Bone”“骨盆Pelvis”和“股骨Femur”。

图3. X射线图像像素重叠的多标记
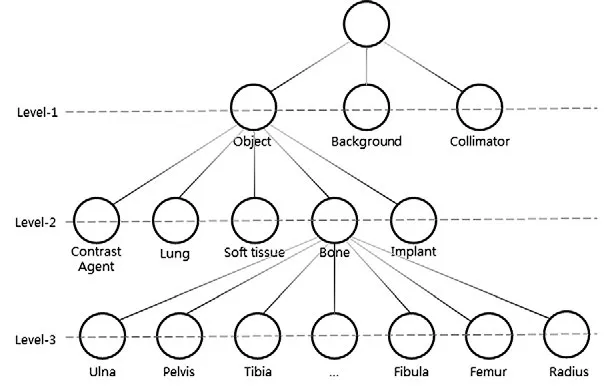
图4. 分层树结构
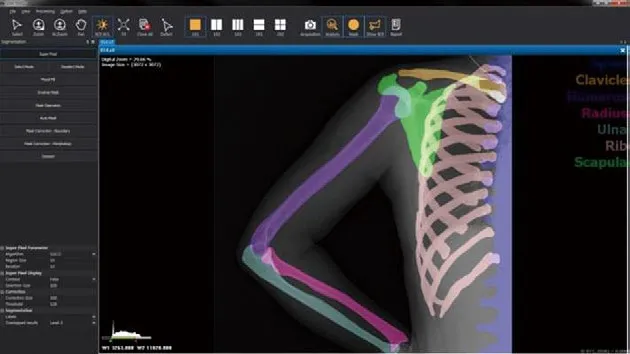
图5. VDP.tool用户界面
本文涉及的图像数据集包括一般人体射线照相,乳腺X射线检查、动物和工业图像不包括在内。本文将X射线图像的每个像素被划分为23个预定义的类别,把数据集结构分为三个层次。如图4所示,第一层由“Object”“背景Background”和“限束器Collimator”类组成。在第二层,“Object”被细分为“Bone”“软组织Soft Tissue”“植入物Implant”等。第三层将“Bone”细分为“Pelvis”“Tibia”“Femur”等。
2.2 注释
接下来将描述如何标注和分类数据集。由于X射线图像数据量大且复杂,并且注释背景图可能需要很长时间,有效的用户界面是必不可少的。因此,作者开发了一个名为VDP.TOOL的用户界面工具。如图5所示,用于对图像进行分类注释,可以识别植入物、限束器和背景区域,可以更精确地提取目标区域。

图6. VDP.TOOL功能
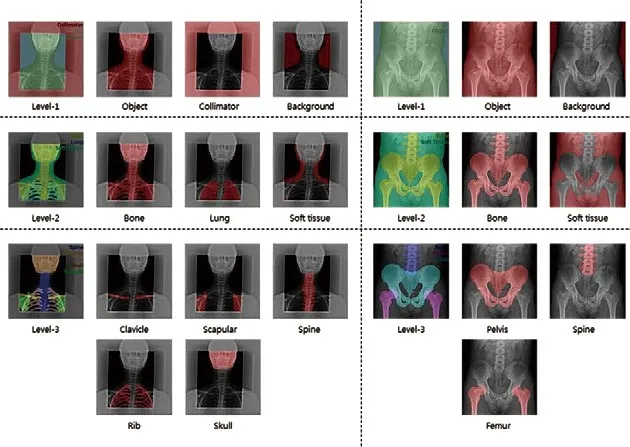
图7. 数据集中标注的图像样本
VDP.TOOL工具包含多个用于快速有效注释的功能,如图6所示,其一个重要功能将图像分割为超像素,允许用户快速选择任何细分部位。另一个重要的功能是区域校正功能,它使用户能够精确地注释和分类选定的区域。
9个人使用VDP工具观察图像并注释(标签)图像的每个部位,然后放射科医师检查图像和注释是否匹配。本文的数据集包含3992幅原始图像和每个标签分类的注释图像(本文中选取的实例图像是经过处理的图像,而不是原始图像)。其中80%(3194幅)的图像用于训练神经网络,其余20%(798幅)图像用于神经网络的测试。样本数据集如图7所示。
3.方法
Long等[5]在2015年提出全卷积网络(Full Convolutional Networks,FCN)。自FCN引入以来,出现了许多语义分割网络模型,如DeconvNet,DeepLab和PSPNet[6-8]。近年来的语义分割算法的研究大多基于FCN。
本研究的语义分割模型的网络结构借鉴了已有的理论模型和X射线图像的各种实验的结果。同时,还考虑在不使用GPU的环境中使用模型的用例。
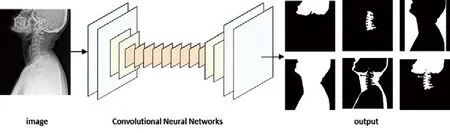
图8. 分隔模型网络
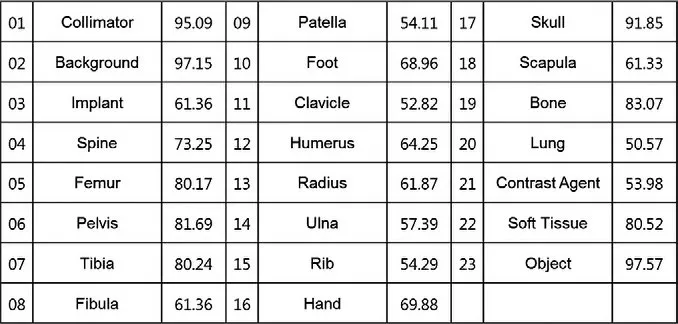
图9. IoU性能评估

图10. 可视化图像三级层次识别结果
本研究的模型的概述如图8所示。本文不涉及神经网络的细节。
4.实验结果
利用每个类的交并比(IoU)来评价神经网络性能。IoU是指训练的神经网络产生的目标窗口和原来标记窗口的交叠率。IoU被广泛用作图像分割和检测领域的性能评估指标。
为性能评估,未用于训练神经网络的798幅图像来测试神经网络。神经网络对每个像素的输出值是0和1之间的某个值,接近于0的值代表这个像素不属于此类的可能性较高(比如:空气或背景),接近于1的值代表属于此类的可能性较高(比如,手或骨)。然后神经网络的输出值和原来标记窗口进行比较。
本研究的系统实现是基于深度学习框架Caffe[9]。IoU性能评估指标实验结果如图9所示。可视化图像结果如图10所示。实验结果表明,“Object”“Bone”“Collimator”等图像中的大尺寸类识别取得了良好的性能。
5.应用程序
5.1 限束器边缘检测
现有的限束器边缘检测实现限束器区域图像识别,并将它们连接起来创建一个多边形。本研究提出一种基于语义分割的限束器检测方法,它通过将多边形拟合到限束器区域来定义实际限束器区域。
图11所示,当限束器边界太厚可能导致C-脊柱侧视位图边界不清晰。然而,基于语义分段的限束器检测可以显著提高性能,因为它可以识别限束器区域并将多边形与之匹配。
5.2 曝光指数的改善
目前曝光指数是根据目标区域的平均像素值来计算的。传统的方法是根据图像的直方图提取目标区域,并去除距离中心较远的区域,以减少误差。基于语义分割的曝光指数更准确地提取和分类区域为种植体、限束器或背景。
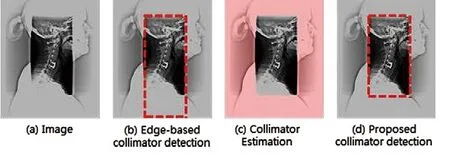
图11. 限速器边缘的图像检测与匹配
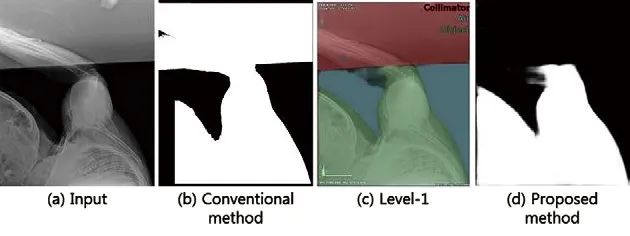
图12. 曝光指数的改善
传统方法中,如果将包含限束器区域整幅图像作为对象,则曝光索引值会明显不同(见图12)。然而,当使用深度学习的语义分割时,可以获得更稳定的曝光指数,因为目标区域是从限束器中分离出来的。
6.小结与未来工作
6.1 小结
本研究开发了一种X射线图像数据的语义分割算法,并将其应用于限束器检测和曝光指数计算。
此外,本语义分割研究结果可以用于各种应用,如X射线图像增强。通过使用额外的数据集和模型改进,仍然有提高性能的空间。随着性能的提高,预计该技术可以在更多的应用程序中使用。
6.2 未来工作
虽然本研究的数据集目前仅限于人体,但作者计划将其扩展到包括动物、乳房X射线照相术和工业放射学。数据集将不仅在数量上而且在质量上得到改善。同时,作者还计划通过各种方法和实验来完善深度学习算法。
总之,本研究将有助于提高算法的性能,通过语义分割,完成如限束器检测和曝光指数的计算。
