结合自注意力机制和Tree-LSTM的情感分析模型
2019-07-09张鑫倩陶永才
石 磊,张鑫倩,陶永才,卫 琳
1(郑州大学 信息工程学院,郑州 450001) 2(郑州大学 软件技术学院,郑州 450002)
1 引 言
近年来,随着互联网技术的快速发展,网民数量急剧上升,越来越多的网民在网络社区(如微博、Twitter)表达对于热点事件的观点、对于产品的体验等.这些文本信息具有情感倾向,分析这些文本有助于舆情分析、产品销售等[1].随着信息呈指数级别的增长,人工处理的方式逐渐被淘汰,促进了文本情感分析技术[2]的快速发展.
与普通文本分类相比,情感分类任务的难点在于多样化的表达方式和较为复杂的句式等,因此使用特征选择的方法具有局限性[3].
目前,情感分类常用的方法分为两种:一种是基于语义词典的方法:构造情感词典,借助该字典判断情感的倾向;另一种是基于机器学习的方法:利用人工的方式设计筛选出文本的特征,将文本特征向量化之后输入到机器学习算法(SVM、朴素贝叶斯、最大熵等方法)中进行分类.
目前,准确率比较高的算法是词典与机器学习混合的方法,其思路可以概括为两种:
1)“词典+规则”,融合不同种类的分类器进行情感分类;
2)“词典+现有特征”,选择最优的特征组合进行情感分类[4].
虽然上述的混合算法可以有效地提高文本情感分析的准确率,但其缺陷是费时费力,需要人工提取特征,标注数据.
所以随着媒体时代的快速发展,文本数据的规模不断扩大,将深度学习模型应用于情感倾向性分析已成为重要的研究趋势.
现有的深度学习方法大多是将文本分词之后转换为词向量,并输入到深度神经网络中学习,没有体现出对于文本中词语之间的联系和重要情感词汇的关注,为了解决以上问题,本文提出一种情感分析模型,在输入端添加自注意力机制,将得到的向量输入到融合树型结构的LSTM模型中,为解决随机梯度下降算法中存在的梯度弥散问题,在Tree-LSTM的输出端引入Maxout神经元,构建了SAtt-TLSTM-M模型.通过在公开数据集COAE2014上的实验,与现有结果相比,证明本文所构建模型有助于提升情感分析准确率.本文提出的模型不仅提高了情感分析的准确率,而且解决了经典深度学习方法忽视文本自身联系的问题以及深度学习中的梯度弥散问题.
2 相关工作
Pang 等人[5]在2002 年提出有关情感分析的内容,近些年来,文本情感分析受到学者的重点关注并且取得了较大的发展.李强等人[6]使用5 种情绪状态和语音特征,提出使用概率神经网络对情绪分类,并且取得了很好的结果.在自然语言处理中,神经网络中的注意力机制受到人类视觉中注意力的启发,注意力机制早期用于图像处理[7],注意力机制允许模型根据输入文本以及它到目前为止已经生成的隐藏状态来学习要注意什么,近来发现其在自然语言处理中,对于问答系统[8]、情感分析[9]的效果都有很大提升,并且出现了很多注意力机制的变形,比如自注意力机制.自注意力(Self-Attention)又称作内部注意力,其作用是能够注意到文本中的关键信息,通常不需要其他额外的信息,它能使用自注意力关注本身进而从句子中抽取相关信息,Vaswani等人[10]大量使用了自注意力(self-attention)机制来学习文本表示大大提升了机器翻译的效果.Tai等人[11]利用LSTM模型试以一种树型结构来描述文本,该模型在情感分析上取得了不错的效果.Tree-LSTM是LSTM的变形,融入了树型结构的特征,Tai[11]等人对树型结构的LSTM结构由底向上递归地合并相邻的节点.解决了循环神经网络在时间上的梯度弥散问题,但是在空间上仍然存在梯度弥散的问题,为此,Goodfellow等[12]将Maxout神经元引入到机器学习任务中,该神经元通过选取一组线性单元中的最大值来实现它的非线性化,在文本分类和语音识别领域取得了不错的效果.Cai等人[13]将Maxout神经元分别与CNN和LSTM模型想结合,构建CMNN和RMNN模型,并应用到语音识别领域.
针对上述模型,本文首先融合了Self-Attention和Tree-LSTM模型,构建SAtt-TLSTM模型;其次引入Maxout神经元,构建SAtt-TLSTM-M情感倾向性分析模型,最后将上述模型用于COAE2014的微博情感分析数据集中,具有实用性和创新性.
3 混合神经网络的微博情感分析算法
3.1 自注意机制
使用自注意力关注文本本身进而从句子中抽取相关信息,自注意力又称作内部注意力,Self-Attention是注意力机制的一种特殊情况,在Self-Attention中,Q=K=V,每个序列中的单元和该序列中所有单元进行attention计算,在本文中,Self-Attention被当成一个层,与Tree-LSTM配合使用.
给定词向量矩阵:X=[x1,x2,…,xn],xi∈Rd,其中n表示给定句子的长度,d表示实数词向量的维度.自注意力的思想是在计算过程中直接将句子中任意两个单词的关系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征.包含句子上下文信息的词向量,其计算见公式(1).
(1)
其中,αi,j>0是自注意力权重,并且通过Softmax正则化技术使∑jαi,j=1.自注意力权重的计算公式为公式(2)和公式(3).
(2)
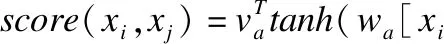
(3)
其中,score(xi,xj)是通过MLP实现的,用MLP来建模词对(xi,xj)的相关性.
最后,将上下文词向量gi和词向量xi进行拼接,作为Tree-LSTM的输入.
3.2 Tree-LSTM模型
循环神经网络(RNN)与卷积神经网络(CNN)被广泛用于解决不同的自然语言处理(NLP)任务,但是受限于各自的缺点(RNN效果较好但参数较多、效率较低,CNN效率高、参数少但效果欠佳).基于以上模型的不足,本文使用Tree-LSTM模型.详细的Tree-LSTM结构如图 1所示.

图1 树型结构的LSTM网络Fig.1 Tree-structured LSTM network
图1中h为LSTM的隐层,c为LSTM的记忆单元.计算过程为公式(4)至公式(10)(在普通LSTM的基础上做了修改).
(4)
(5)
fjk=σ(W(f)xj+U(f)hk+b(f))
(6)
(7)
(8)
(9)
hj=oj⊙tanh(cj)
(10)
其中,σ表示sigmoid函数;U表示孩子节点隐含值的权重;W表示不同结构内的权重;b表示不同结构的偏置项;⊙表示向量对应元素的乘积.计算模型中的任意一个单元,其孩子节点使用不同的参数矩阵.Tree-LSTM模型通过逐步训练将树根节点的隐含输出hroot作为句子的向量表示,输入到Maxout神经元中.
3.3 Maxout神经元
Maxout神经元可以看做是在深度学习网络中加入一层激活函数层,包含一个参数k,这一层相比ReLU,Sigmoid等,其特殊之处在于增加了k个神经元,并且输出激活值最大的值.
对于常见的Sigmoid函数的隐藏层节点输出见公式(11):
hi(x)=sigmoid(xTwi+bi)
(11)
如果选用Sigmoid作为激活函数,那么在使用梯度下降算法计算导数的时候,随着网络深度的增加,会出现梯度弥散的问题,而Maxout的出现恰好可以解决这个问题,而且有利于增加模型的深度[14],其结构如图 2所示.
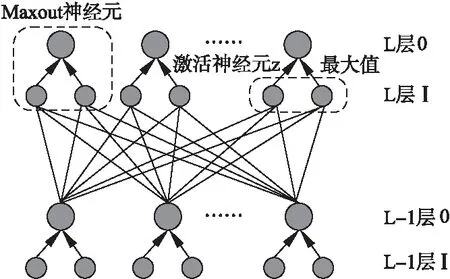
图2 Maxout神经元结构Fig.2 Maxout neuron structure
根据图 2可知,每一个Maxout神经元是由多个不同的神经元组成,并且输出是激活神经元中的最大值,在Maxout神经元中,其隐含层节点的输出表达式为式(12):
(12)
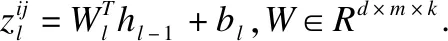
Maxout神经元在使用随机梯度下降算法进行训练过程中,其梯度的计算为式(13):
(13)
3.4 基于SAtt-TLSTM-M的文本分类模型
在以上模型的基础上提出了基于SAtt-TLSTM-M的情感分类模型,本文深度神经网络模型的构造从以下3个方面考虑:
a)对于句子中的词向量,通过引入自注意力机制来学习句子内非连续词之间的语义相关特征;
b)输入到Tree-LSTM中学习到句子结构特征;
c)为防止梯度弥散的问题,引入Maxout神经元得到更好的分类结果.其结构见图3所示.

图3 基于SAtt-TLSTM-M的情感分类模型Fig.3 Sentiment ananlysis model based on SAtt-TLSTM-M
由图 3可知,该模型实现情感分析时可分为以下几个关键步骤:
1)分词预处理.本文使用结巴分词工具的精确模式将COAE2014中的40154条中文文本切分成以词为单位的形式,并且使用哈工大的停用词表去除文本中的停用词,使用正则表达式去除文本中无用的字符.
2)构建词向量矩阵.Word2vec是Google公司开源的一款将词表征为特征向量的工具,先利用该工具将1)中得到的分词后的文本转为向量词典,然后构建官方公布的5000条带有情感标签的词向量矩阵.该矩阵的行数为每条文本的词数,列数为每个词对应向量指定的位数,截取微博为相同的长度,句子词较少的用0填充.
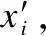
4)hs经过Tree-LSTM模型后,句子的最终表示为:ht.
5)情感分类.将句子特征向量ht输入到全连接层Maxout神经元中,接着输入到Softmax分类器中,对文本进行积极和消极的二分类.
4 实 验
4.1 实验环境
本文的实验环境及其配置如表 1所示.
4.2 实验数据集和评价指标
本文采用COAE2014微博数据集,包括40000条微博数据,其中官方公布了5000条数据的情感极性,由于该5000条带有情感标签的数据集中,数据量较小,又没有明显的训练和测试集之分,所以本文对该5000条数据进行10折交叉验证,利用数据集提供的40000条数据训练词向量.
表1 实验环境配置
Table 1 Experimental environment configuration

实验环境环境配置操作系统处理器内存编程语言深度学习框架Windows7NVIDIAGeForce940M8GBPython3.6Tensorflow1.8
本文使用3个评价指标作为评价标准:① Precision:评估的是分类结果的查准率,具体计算见式(14),② Recall:评估的是分类结果的查全率,具体计算见式(15),③F1-measure:综合评价指标,具体计算见式(16).
(14)
(15)
(16)
其中,TP(True Positive)代表实际和预测一致,都是积极样本;TN(True Negative)代表实际和预测一致,都是消极样本;FP(False Positive)代表实际和预测不一致,预测是积极样本,实际是消极样本;FN代表实际和预测不一致,预测是消极样本,实际是积极样本.
4.3 实验可调参数设置
本文首先使用jieba对文本进行分词,然后使用Word2vec工具将分词后的文本转化为词向量,经过jieba分词和word2vec向量化之后,微博文本数据转换成了由向量组成的向量矩阵.详细参数设置如表 2所示.
表2 模型参数设置
Table 2 Model parameter setting

参数名值单位文本保留最大长度词向量维度Word2vec训练窗口大小训练批大小(batch-size)Dropout参数Tree-LSTM输出维度140505320.5300字符维———维
4.4 本文模型与基本模型的实验对比
本文实验数据设置了四组对比实验,将由word2vec训练得到的词向量矩阵输入到以下所描述的7个模型中.
1)SVM模型和MNB模型(multinomial naive Bayes,MNB)[14]:这两种模型是机器学习中比较经典的分类模型,在很多基础分类任务中取得了不错的分类结果.
2)LSTM模型和RMNN模型:选取经典的LSTM模型和RMNN模型[13]作为比对模型,RMNN模型在LSTM的基础上引入了Maxout神经元,目的是为了证明Maxout在模型中起到了优化的作用.
3)Tree-LSTM模型和Self-Att+Tree-LSTM模型:这两个实验对比的目的是为了证明添加自注意力机制后模型在情感分析任务上性能得到了提升.
4)SAtt-TLSTM-M模型:本文的情感分类模型融合了自注意力机制、Tree-LSTM、Maxout进行情感分类.
4.5 实验结果分析
图 4展示了所有模型在训练过程中测试集的分类准确率,图中横坐标为训练次数,纵坐标为分类准确率.

图4 所有模型训练过程测试集分类准确率Fig.4 Accuracy for all models on the training set
由图 4可知,随着训练次数的增加,7个模型的分类准确率逐渐提升,最终稳定在15到20次之间.最基本的SVM模型和MNB模型在16次以后,其准确率停留在71%和72%左右,均低于其他模型.最基本的LSTM模型在训练19次以后,其准确率停留在75%左右,在LSTM模型的基础上,引入了Maxout神经元的RMNN模型的准确率停留在80%左右,相比LSTM模型提高了5%左右.这说明了Maxout神经元起到了优化分类结果的作用.Tree-LSTM和Self-Att+Tree-LSTM模型的实验结果对比,验证了Self-Att对于句子内部特征表达的重要性,提高了约2%.对于本文提出的SAtt-TLSTM-M模型在Tree-LSTM的基础上,不仅加入了自注意力机制用于提取句子内部词间的上下文信息,而且还引入了Maxout神经元,解决了梯度弥散的问题,实验表明,本文提出的模型优于其他对比模型,准确率稳定在88%左右,由此证明了该模型的可行性和优越性.
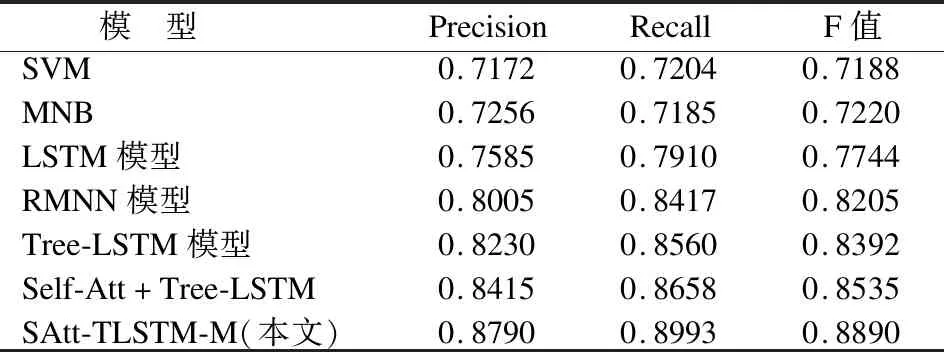
表3 最佳参数模型分类结果
Table 3 Accuracy for models in optimal parameter
模 型 PrecisionRecallF值SVMMNBLSTM模型RMNN模型Tree-LSTM模型Self-Att+Tree-LSTMSAtt-TLSTM-M(本文)0.71720.72560.75850.80050.82300.84150.87900.72040.71850.79100.84170.85600.86580.89930.71880.72200.77440.82050.83920.85350.8890
四组对比实验在COAE2014微博数据集上3个测评结果如表 3所示.
实验结果表明,在情感分类任务上,采用Tree-LSTM模型整体上优于其他机器学习方法.SAtt-TLSTM-M模型在Precision上最优,说明引入自注意力机制和Maxout起到了重要的优化作用,在Recall和F值上也均优于其他模型,充分证明了SAtt-TLSTM-M有助于提升情感分析的准确率.
5 结 论
本文基于Self-Attention、Tree-LSTM和Maxout神经元提出了SAtt-TLSTM-M模型,首先引入自注意力机制使句子上原始的词向量融入了上下文向量;其次利用树型结构的LSTM学习句子的文本特征;最后引入Maxout神经元解决了梯度弥散的问题.在COAE2014数据集进行训练和测试,证明了该模型优于传统的机器学习模型,不仅在情感分类准确率上得到了提升,而且有助于社交媒体评论的情感分析,进一步证明了深度学习在情感分析领域的可行性.在接下来的研究中,将对跨领域的文本情感分析进行进一步研究,以期进一步提高深度学习在多领域情感分析的适应性.
