使用带分类参数贝叶斯网的虚拟机性能预测
2019-07-09尚聪聪张彬彬
尚聪聪,郝 佳,张彬彬,岳 昆
(云南大学 信息学院,昆明 650500)
1 引 言
基础设施即服务(Infrastructure as a Service,IaaS)是云计算[1]的一种资源使用模式,云计算通过虚拟化技术向用户提供计算、存储等资源,用户按需租用这些资源并支付费用.目前大部分云服务提供商,例如阿里云[注]Alibaba Cloud. https://www.aliyun.com/,2018/06/05.、亚马逊云[注]Amazon EC2. http://aws.amazon.com/ec2/,2018/06/05.等,都是以虚拟机的形式,向用户提供可选的若干种CPU、内存以及网络带宽等资源配置套件[2].这种业务模式,并未真正实现资源的按需分配,难以适应动态变化的资源需求,导致资源利用率低下.为了提高资源利用率以及实现按应用需求分配虚拟机所需资源,首先需要准确预测特定虚拟机特征配置下的性能[3].
然而,准确预测虚拟机特定特征配置下的性能,存在以下困难.一方面,虚拟机的性能与特征之间存在复杂的非线性依赖关系[4,5],虚拟机的各个特征之间相互作用共同决定了虚拟机性能.另一方面,由于虚拟机上所运行的负载具有复杂性、动态性以及不确定性,这也增加了虚拟机性能预测的难度.其中,应用负载的复杂性,是指多个虚拟机上的应用负载所需资源不同,可能会导致物理主机的资源使用超过所能承受的峰值;应用负载的动态性,是指不同负载的运行情况会随着时间变化而改变,可能会产生多个应用之间的通信,影响虚拟机性能;应用负载的不确定性,是指应用负载在不同时刻所需的资源大小不确定,可能会导致固定资源特征分配下虚拟机的性能产生波动.
学界已开展了很多虚拟机性能预测的研究,一些研究通过建立虚拟机特征和性能之间的线性模型,来实现虚拟机性能预测.文献[6]提出基于硬件计数器的虚拟机性能估算方法;文献[7]提出基于指数平滑模型的虚拟机预测算法.然而,虽然线性模型使用简单,但它难以有效拟合特征和性能之间的非线性依赖关系,从而导致模型的预测结果不够理想.
另一些工作通过建立虚拟机特征与性能之间的非线性关系模型来实现性能预测.其中,文献[8]提出基于奇异值近似分解的虚拟机性能预测方法,分析虚拟机性能的变化趋势,但难以将结果进行直观展示;文献[9]基于马尔科夫方法来预测虚拟机特定状态下的性能,但对时间序列太过依赖;文献[10]提出基于遗传优化的人工神经网络方法来预测不同配置组合情况下虚拟机性能,并从中找出具有最小资源开销的特征配置组合;文献[11]提出基于人工神经网络的迭代模型来预测给定特征配置下的虚拟机性能,虽然可以对虚拟机特征和性能之间存在的非线性关系建模,但耗费大量计算资源、且容易出现过拟合.综上所述,上述方法和模型中,虚拟机特征和性能之间的不确定性依赖关系仍然难以有效表达,且当虚拟机性能产生波动时,这些模型则无法准确预测这种性能波动情况.
文献[12]提出基于贝叶斯网(Bayesian networks,BN)来对虚拟机特征和性能之间存在的不确定性依赖关系建模的方法,用以虚拟机性能评估.贝叶斯网模型用条件概率表达各个信息要素之间的相关关系,能在有限、不完整、不确定的信息条件下进行学习和推理.BN是一个有向无环图(Directed Acyclic Graphic,DAG),图中的节点表示随机变量,节点间的边表示变量之间的依赖关系.每个节点都有一张条件概率表(Conditional Probability Table,CPT),用来刻画这种依赖的程度.BN能够有效地表达虚拟机各个特征以及特征与性能之间存在的非线性依赖关系,以及这种依赖关系的强弱,基于BN可进行概率推理计算[13].
然而,对于一般的BN模型来说,模型的构建依赖于数据的训练结果,当虚拟机特征取值的组合未出现在训练数据集中时,BN便无法预测这些特征所对应的性能.此外,当影响虚拟机性能的特征节点数量较多时,会导致性能节点的CPT组合情况复杂,增加参数计算以及性能预测的复杂性.
因此,本文采用一种带分类参数的BN模型(Class parameter augmented BN,CBN).该模型首先对虚拟机进行分类,然后基于分类结果与对应的虚拟机性能值,构造CBN模型以实现对任意特征配置下的虚拟机性能预测.经过对常见的分类模型比较,基于集成学习的随机森林(Random Forest,RF)模型与其他分类算法相比,能够处理高维度的复杂特征数据,预测速度快且准确率高,还能够平衡不均衡数据的预测误差,具有分类结果稳定且不易过拟合等优点[14].因此,本文采用随机森林作为CBN模型的分类器.
综上,本文的主要工作包括:
1)基于虚拟机特征数据训练随机森林模型作分类器.
2)基于虚拟机的分类和性能数据,训练CBN模型,用于表达虚拟机特征和性能之间的依赖关系.
3)基于CBN的概率推理预测任意虚拟机特征配置下的虚拟机性能和性能波动情况.
本文第2节给出CBN模型的构造方法,第3节给出基于CBN预测虚拟机性能的方法,第4节给出实验结果,第5节总结全文内容并展望将来的工作.
2 CBN模型构建
影响虚拟机性能的特征包括硬件特征、软件特征以及运行时环境特征[9].这些特征的不同组合值,构成不同配置的虚拟机.当某个应用在特定的虚拟机配置上运行时,应用的运行时间可以反映当前虚拟机的性能.为了能够方便地获取虚拟机特征-性能数据,我们把应用在特定特征配置虚拟机上的运行时间作为当前虚拟机的性能值.
假设共有m种可调整的虚拟机特征,其中包括虚拟CPU的个数、内存大小、同时运行的虚拟机个数等,分别表示为V1,V2…,Vm.假设每一个特征都有i种取值情况,如特征Vm的取值为vm1,vm2,…,vmi,则m个特征可构成im种不同虚拟机特征配置.本文通过RF分类算法,将im种虚拟机分为r个类别.在CBN模型中,m个虚拟机经过分类后构成一个分类节点Z,Z有r种可能取值,表示为z1,z2,…,zr.下面给出CBN的定义.
定义1.CBN为一个有向无环图,表示为GCBN=(U,E,θ),其中:
·U为GCBN中的节点集合,包括虚拟机分类节点Z和虚拟机性能节点T,即U=Z∪T.
·E表示U中各个节点之间边的集合.用e(Ui,Uj)来表示一条由节点Ui指向节点Uj的有向边,则e(Ui,Uj)∈E,i≠j.在CBN模型中,只包含一条由分类节点Z指向性能节点T的边.
·θ表示GCBN中各个节点的参数集合,由各个节点的条件概率表构成,度量了虚拟机性能节点T对虚拟机分类节点Z的依赖程度的大小.
在CBN中,无父亲的节点Z的参数为边缘概率分布值P(Z),节点Z的子节点T的参数值为条件概率分布值P(T|Z).P(Z)和P(T|Z)构成了CBN的参数θ.
CBN的构建包括结构构建和参数计算,结构构建部分包括RF分类器的训练,以及根据分类结果的结构学习;参数计算部分包括对虚拟机分类节点Z和特征节点T的后验概率计算.
2.1 CBN模型中随机森林分类器训练
随机森林回归算法以CART决策树[14]为基础,利用Bootstrap重采样方法,从含有L个样本的训练数据集D中,有放回地抽取s个样本组成新的样本集合S,该样本集合称为Bootstrap样本.分别对每个Bootstrap样本构建一棵CART决策树,最终根据所有决策树分类结果进行投票,将投票结果作为随机森林的最终分类结果[15].
构建决策树时,我们选用基尼系数(GINI)作为当前虚拟机特征分裂的依据.选择具有最小Gain_GINI值的虚拟机特征Vm及其相应的特征值vmi,作为当前CART分类树的最优分裂节点及其相应的分裂特征值.Gain_GINI的值越小,则证明被分裂后的样本“纯净度”越高,则选择该特征值作为分裂依据的效果越好.对于含有s个虚拟机特征-性能样本的集合S来说,它的GINI系数计算方式如式(1)所示.
(1)
在(1)中,pk表示虚拟机分类为第k类的概率,即Z为zk(k∈{1,2,…,r})的概率值.
对于含有s个样本的集合S来说,根据虚拟机特征Vm的第i个属性值,即vmi,将S划分为S1和S2两部分后,Gain_GINI的的计算方式如(2)所示.
(2)
其中,n1和n2分别为S1和S2中样本的个数,GINI(S1)和GINI(S2)的计算方式类似于公式(1).对于特征Vm来说,通过公式(2)分别计算当选择vm1,vm2,…,vmi作为分裂特征值时,对应的Gain_GINI值的大小,并选择使得Gain_GINI最小的特征值,作为虚拟机特征Vm的最优分裂值.即,
(3)
对于样本集S来说,计算所有特征Vm的最优二分方案,选择其中的最小值,作为样本集合S的最优二分方案,即,
(4)
上述方案中,虚拟机特征Vm和它的特征值vmi,即为样本S的最优分裂特征及其最优分裂特征值.
通过上述方法,可构造一棵CART决策树.当给定一组虚拟机特征配置时,可用该树预测出当前特征配置的所属类别.当随机森林中一共包含t棵CART分类树时,它们的分类结果的投票结果即为虚拟机的分类.
综上,虚拟机分类的随机森林模型构建步骤如下:
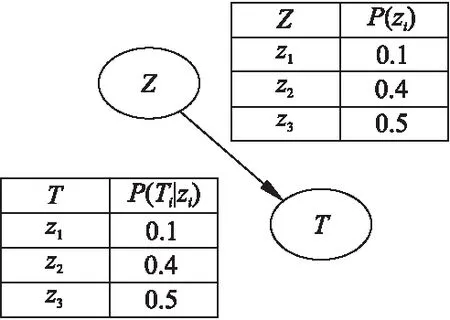
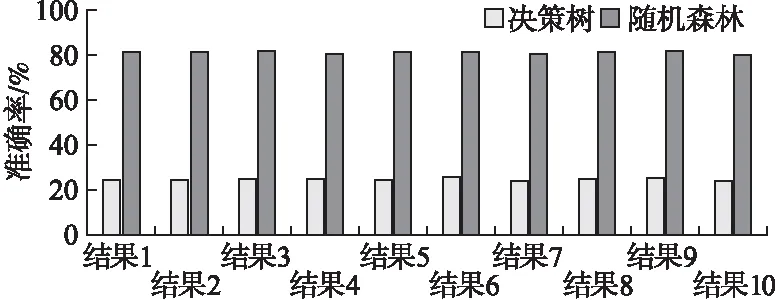
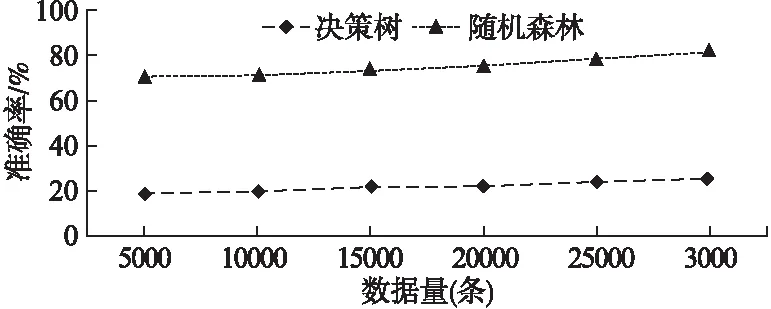
1)从训练数据集D中,采用Bootstrap方法抽取s个数据样本作为第i棵树的训练集Dsi(0 2)如果queue非空,则取出一个节点node.基于node中的虚拟机特征-性能数据样本Dnode和m个虚拟机特征节点,依次计算特征节点Vj(1≤j≤m)的每一个特征值vjk(1≤k≤r)所对应的Gain_GINI值大小,并找出最小的Gain_GINI值min和对应的特征节点Vj和特征值vjk.如果min大于阈值q,则根据分裂特征Vj和特征值vjk将当前节点分裂出两个孩子节点,并将两个孩子节点加入队列queue,否则不做操作.重复执行上述过程,直到queue为空,完成当前决策树的构造. 3)重复步骤1)和2),直至建立t棵CART分类树,最终构成虚拟机分类的随机森林模型RF. 算法1具体描述了上述思想. 算法1.基于随机森林的虚拟机分类 输入:D:虚拟机特征-性能数据集; L:虚拟机特征-性能数据集中的数据条数 t:随机森林中决策树的数量 m:虚拟机特征的个数 r:虚拟机特征的取值个数 q:GINI系数最小的阈值 Gm[m]:用于存储虚拟机特征的最小Gain_GINI值 Vm[m]:用于存储最小Gain_GINI值对应的特征值 Gr[r]:用于存储同一个虚拟机特征按不同取值分裂的Gain_GINI值 Vr[r]:用于存储虚拟机一个特征所有取值 输出:RF:基于随机森林的虚拟机分类模型 步骤: 1.fori←1 totdo 2.Dsi←Bootstrap(S,D)//为第i棵树选择样本Dsi 3.root←makeNode(Dsi)//集合Dsi作为根节点 4.queue←root//将root加入队列 5.whilequeue!=Φdo 6.node←pop(queue)//队列取出一个节点 7.Dnode←OutData(node)//获取当前node的数据 8.forj←1 tomdo 9.r←CountNum(Dnode,j)//当前特征取值个数 10. fork←1 tordo 11.Gr[k]←Calculate(Gain_GINI(Dnode,j,k)) //计算虚拟机特征Vj的取值为vjk时的Gain_GINI值的大小存储到数组Gr[r]中 12.Vr[k]←findValue(Dnode,j,k)//第k个特征值 13.k←k+1 14.endfor 15.Gm[j]←findNum(MIN(Gr[r])) //找到Gr[r]数组中最小的Gain_GINI值 16.Vm[j]←relevantValue(Gm[j],Gr[r],Vr[k]) //找到最小Gain_GINI值对应的特征取值 17.j←j+1 18.endfor 19.min←findNum(MIN(Gm[m]))//最小Gain_GINI值 20.ifmin>q 21.Vj←relevantFeature(min,Gm[m]) //找到最小Gain_GINI值对应的特征 22.vjk←relevantValue(min,Gm[m],Vm[j]) //找到min对应的虚拟机特征的取值 23.lchild,rchild←makeNode(split(node,Vj,vjk)) //根据分裂特征和分裂值,将节点node分成左右节点 24.queue←lchild,rchild//将节点存储到队列中 25.endif 26.endwhile 27.RF←root//将root加入随机森林中 28.endfor 29.returnRF 基于算法1可实现对多个虚拟机进行分类.当给出一组未知虚拟机特征时,分别由随机森林中的t棵树分类,分类结果按少数服从多数进行投票,投票结果即表示该组特征的分类结果.算法1运行时,假设每一棵决策树需要计算m个特征的Gain_GINI值系数,则基于含有N个样本的训练数据集D,来构建含有t棵决策树的随机森林时,该算法的时间复杂度为O(t(mt*logN)). 例1. 使用表1中的数据,根据算法1构建CART决策树.首先计算每个属性的每个取值的Gain_GINI值.根据公式(2)可以算出: CPUnum取1为分裂值时,Gain_GINI值= 2/4(1-(1^2+0^2+0^2))+2/4(1-((1/2)^2+(1/2)^2))=1/4 CPUnum取2为分裂值时,Gain_GINI值=1/4 MemorySize取1024为分裂值时,Gain_GINI值=1/2 MemorySize取512为分裂值时,Gain_GINI值=1/2 CPUFreq取3.3为分裂值时,Gain_GINI值=1/4 CPUFreq取3.6为分裂值时,Gain_GINI值=1/4 表1 虚拟机特征与分类实例 CPUnum(个)MemorySize(MB)CPUFreq(GHz)Z15123.3z1210243.6z325123.6z2110243.3z1 根据算法1,我们选取Gain_GINI值最小的属性和取值作为最优分裂特征和分裂值.本例我们选择CPUnum是否取1作为分裂特征和分裂值,将数据分为实例分为两部分.第一部分包含z1与z4,第二部分包含z2与z3.对于第一部分,类别标签只有z1,所以无需再分.对于第二部分重复上述步骤,得到MemorySize是否取1024为最优分裂特征和分裂值.由此构建出如图1所示的决策树. 图1 CART决策树实例Fig.1 An example of CART decision tree 根据先验知识,可确定虚拟机特征将对虚拟机性能产生不确定性影响,且它们之间存在相互依赖关系.所以CBN的结构中只存在一条由Z指向T的有向边,即e(Z,T).基于算法1可将所有的虚拟机分为r个类别,即Z⊆{z1,z2,…,zr},而性能节点有j种取值,即T1,T2…Tj.例1是一个CBN的特征选择以及结构构造示例. 待分类的虚拟机特征为虚拟CPU个数(CPUnum)、内存大小(MemorySize)、同时运行的虚拟机个数(coVMS)和物理主机的CPU主频(CPUFreq),取值情况如表2所示.运行算法1后,这些不同的特征配置被分为4个类别,即z1,z2,z3,z4,它们所对应的性能值分别为T1,T2,T3,T4.表1展示了具体取值情况. 基于这4个特征的分类结果Z和所对应的性能值T,可以构造CBN的结构. 例2. 对于CBN的参数计算来说,我们运用最大似然估计(Maximum Likelihood Estimation,MLE)来计算CBN中各个节点的参数,即节点的CPT.计算公式如(5)所示. (5) 其中,θijk表示当节点Ui取值为k,且Ui的父节点取值为j时节点Ui的参数.Num((Ui=k),Pa(Ui=j))表示当节点Ui取值为k,且Ui的父节点取值为j时,虚拟机特征-性能数据集D中的数据条数.而Num(Pa(Ui=j))表示Ui的父节点取值为j时的数据条数.在CBN中,所有节点的CPT,构成了CBN的参数值θ. 表2 虚拟机特征、分类与性能实例 CPUnum(个)MemorySize(MB)coVMS(个)CPUFreq(GHz)ZT151213.3z1T12102423.6z2T23150033.6z3T34204813.3z4T4 基于CBN结构及参数值,可以预测任意虚拟机特征配置下的的性能.当某一组虚拟机特征配置为{v11,v21,…,vm1}时,经过RF算法分类后,该虚拟机被分为类别zi.基于CBN可得到zi所对应的虚拟机性能值分别为T1,T2,…,Ti的条件概率.具有最大条件概率值的性能即为CBN预测的虚拟机性能值. 例如,CBN的结构构建和参数计算情况如图2所示.图中节点Z为虚拟机分类节点,所有的虚拟机特征配置被分为3个类别,即z1,z2和z3,经过计算后,这三个类别的取值概率分别为0.1,0.4和0.5.而虚拟机的性能节点T的取值共有3种,通过MLE可计算相应类别下的条件概率值.图1中节点T的CPT展示的是当虚拟机类别为z1时,性能分别为T1,T2和T3的条件概率值. 图2 CBN示例Fig.2 Example for CBN model 当Z的取值为zi时,性能节点T的取值为Ti的条件概率计算公式如(6)所示. (6) 使用RF算法对虚拟机的某一组特征进行分类后,结果记为zi,然后用CBN分别预测当前配置性能为T1,T2,…,Ti的概率.预测过程即是计算P(T=T1|Z=zi)),P(T=T2|Z=zi)),…,P(T=Ti|Z=zi))的过程.最终,我们选择具有最大后验概率的性能值,作为当前配置下虚拟机性能的预测值. 算法2描述了具体的性能预测过程. 算法2.基于CBN的虚拟机性能预测 输入:v11,v21….vm1:待预测虚拟机的虚拟机配置 j:性能值个数 Tj[j]:存储虚拟机所有的性能值 Pj[j]:用于存储每个性能值的条件概率 输出:X:CBN预测的最大概率值 Ti:基于CBN所预测的性能值 步骤: 1.zi←RF(v11,v21….vm1) //RF根据m个特征取值得到分类结果 2.fork←1 tojdo 3.Pj[k]←Calculate(P(T=Tk|Z=zi)) //分类结果为zi时,性能为Tk的条件概率 4.endfor 5.X←findMax(Pj[j])//找到性能预测最大概率 6.Ti←findPerformance(X,Pj[j],Tj[j]) //根据X找到对应的性能值,作为性能预测值 7.returnXandTi 基于算法2,当虚拟机分类为zi时,分别计算它所对应的j个性能值的条件概率,则算法2的时间复杂度为O(j). 例3. 假定某台虚拟机配置为CPUnum为2个,MemorySize为1024MB,CPUFreq为3.3GHz.根据例1的出的CART决策树可以得到类别为z3.再根据相应的CPT表,查询z3的性能值,就可以得到该虚拟机的性能预测值. 实验环境如下:Intel(R)Core(TM)i5-6200U处理器;2.40GHz的CPU主频,8GB内存,Windows10 64位操作系统,Python 3.5.2:Anaconda 4.2.0(64-bit)为开发平台. 为了测试本文提出的CBN模型在预测虚拟机性能时的有效性和准确性,我们使用阿里云公布的批处理任务运行数据集BatchInstance做测试[注]Alibaba ClusterData, https://github.com/alibaba/clusterdata, 2018/08/27..该数据集包含了部署在阿里云中的某个实际运行的集群(共包含13000台物理主机)上的虚拟机,在12个小时内运行批处理任务的信息统计情况.这个数据集共有34762条数据,其中包含了任务开始与结束的时间戳、任务ID、CPU利用率、内存利用率等特征,以及所对应的任务运行时间. 为了验证CBN预测的准确性,选择任务ID、最多CPU利用个数、平均CPU 利用个数、最大内存利用情况以及平均内存利用情况,作为虚拟机待分类特征,分别表示为job_id,real_cpu_max,real_cpu_avg,real_mem_max,real_mem_avg.同时,用虚拟机上任务的响应时间response_time作为待预测的虚拟机性能.我们将所有虚拟机性能数据分为20个类别,分别表示为C1,C2,…,C20.采用十折交叉验证的思想,将数据均分为10份,轮流将其中9份作为训练数据集来建立CBN模型,一份作为测试数据集,进行模型构建和验证.每次验证都能得到对应的虚拟机性能预测准确率.我们把实验分为以下两类,首先按照特征取值对虚拟机分类,采用随机森林的分类结果与决策树的分类结果做对比,验证随机森林模型对虚拟机分类的准确性.其次,将CBN对虚拟机性能的预测结果和线性模型的结果做对比,说明CBN对于虚拟机性能预测的准确性. 为了验证随机森林算法对虚拟机分类的准确性,首先根据BatchInstance数据集中的response_time的大小,人为地将不同虚拟机特征配置分为20个类别.基于十折交叉验证的思想[16],将数据均分为10份,轮流将其中9份作为训练数据,1份作为测试数据,基于这10组数据分别运行随机森林算法和决策树分类算法,并统计两个算法分类的准确率.图3是两个算法分类的准确性对比情况,横坐标表示实验结果,纵坐标表示准确率. 图3 随机森林和决策树的平均分类准确率Fig.3 Classification accuracy rate of random forest and decision tree 从图3中,可以看出,随机森林算法在进行虚拟机分类时,准确率平均可以达到80.87%,而决策树的分类准确率平均只有25.05%.由此可以说明我们提出的基于随机森林的虚拟机分类算法具有较高的准确率.另外,十组数据中,随机森林算法分类准确率最大值与最小值之差为1.1%,而决策树算法为1.9%.由此可以说明随机森林算法对数据的适应性更高. 为了验证随着数据量的增长,两个模型的分类准确率是否有所变化,我们做如下测试:将数据集以5000为一个增长单位,依次验证数据量为5000、10000、15000、20000、25000、30000条时,随机森林和决策树对虚拟机分类的准确性.结果如图4所示. 图4 分类模型准确率与数据量变化关系对比Fig.4 Relationships between classification model and amount of data 从图4中可以得出,对虚拟机分类时,随机森林算法和决策树算法分类的准确率均随着数据量的增长而增长.随着数据量从5000增长到30000,随机森林算法的分类准确率提高了10.8%,而决策树算法的分类准确率提高了6.4%. 为了验证CBN模型预测虚拟机性能的准确性,我们用CBN的预测结果和线性模型的预测结果对比说明.图5为基于十折交叉验证,用CBN和线性模型来预测虚拟机性能的准确率.从图5可以得出,线性模型在预测虚拟机性能时,平均准确率只能达到22.7%.而CBN模型在预测虚拟机性能时,平均准确率达到76.36%. 图5 CBN模型和线性模型预测结果准确率Fig.5 Prediction accuracy rate of CBN and linear model 同样地,将数据量分别设置为5000、10000、15000、20000、25000、30000条时,对比CBN和线性模型的虚拟机性能预测准确性.结果如图6所示. 图6 性能预测准确率与数据量变化对比Fig.6 Relationship between accuracy of CBN and amount of data 图6中可以看出,CBN模型对于虚拟机性能的预测准确率远高于线性模型,且准确率随着数据量的增长而增长.当数据量从5000增加到30000时,CBN模型的预测准确率提高了12%.而线性模型的预测准确性却没有太大改变,最高的预测准确率只达到了24%. 图7 CBN预测概率分布与实际概率分布Fig.7 CBN predictions and experimental data distribution 由于CBN可以预测出虚拟机性能的波动情况,我们随机选择四组数据,用CBN推理出各个可能取得性能值的概率分布情况,并用推理结果和实际数据的分布情况作对比,验证CBN预测的虚拟机性能概率分布是否和实际情况相符合.具体情况如图7所示,图中性能值为虚拟机上应用的运行时间. 从图7中可以看出,CBN预测虚拟机性能的结果,与实际数据的分布情况相符合. 为了验证CBN预测的虚拟机性能分布情况是否与实际的数据分布情况相符,分别计算以上四组数据中,最大概率估计值相对于从实际数据中统计得到的概率值的误差和相对误差. 误差的计算方式为error=PC-PS,而相对误差的计算方式为relativeerror=|PC-PS|/PS,PC表示由CBN模型所预测得到的性能概率值,PS表示从实际数据统计出来的性能概率值.计算结果如表3所示,为了区分4组数据,使用1,2,3,4为4组数据编号. 表3 CBN预测结果的误差与相对误差 数据集responsetime/sPCPSerrorrelativeerror1400.610.60.011.67%2400.70.660.069.01%3200.790.750.045.33%4500.770.750.022.66% 从表3中可以看出CBN对于虚拟机性能分布概率的预测误差中,相对误差最低的只有1.67%,而最大的误差达到9.01%.通过计算,可以得出CBN预测的平均误差为:0.0325,而相对误差的平均值为:4.67%. 通过以上实验,验证了我们所提出方法在虚拟机分类,以及虚拟机性能预测时的有效性和准确性. 本文针对虚拟机特征与性能之间存在不确定性依赖关系,导致虚拟机性能难以被准确预测的问题,提出了一种基于带分类参数的BN模型,来实现虚拟机性能预测.该模型克服了传统BN对于训练集中未出现过的数据,无法进行预测的局限性,以及当虚拟机特征节点过多时,性能预测的复杂度增加、准确率下降的情况.实验结果表明本文提出的方法预测虚拟机性能的高效性和准确性. 然而,本文提出的随机森林模型是将虚拟机作为一个整体进行分类,针对虚拟机不同类型的特征差异性所导致的分类误差尚未充分考虑.因此,在后续方案中,我们考虑将多个虚拟机的分类细化,以实现更加准确地预测虚拟机的性能.
Table 1 Example for classification of virtual machines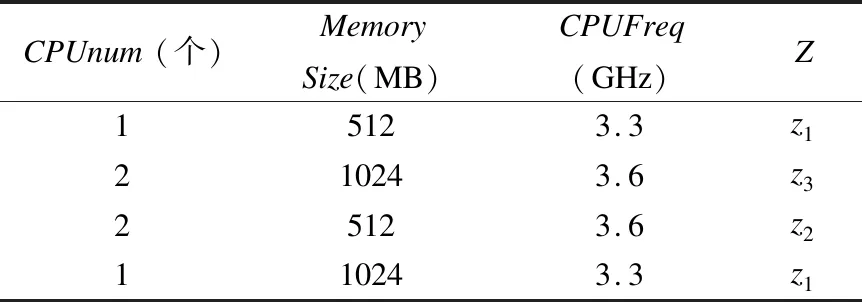

2.2 CBN的结构构造与参数学习
Table 2 Example for features and the classification of virtual machines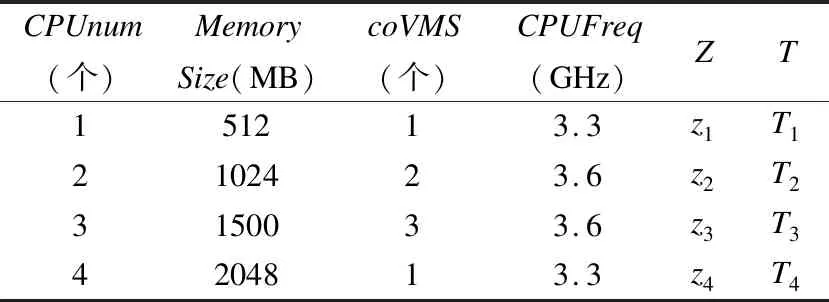
3 基于概率推理的虚拟机性能预测
4 实验结果
4.1 随机森林算法分类准确性
4.2 CBN模型预测准确性
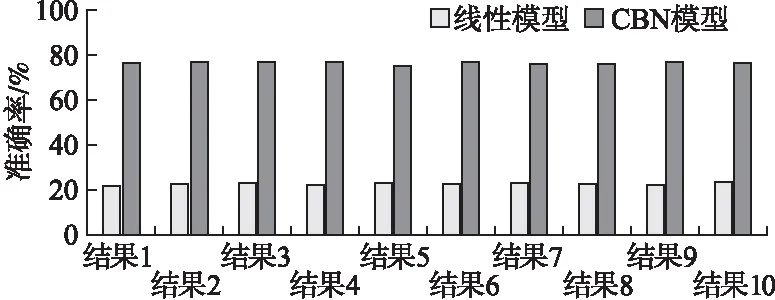
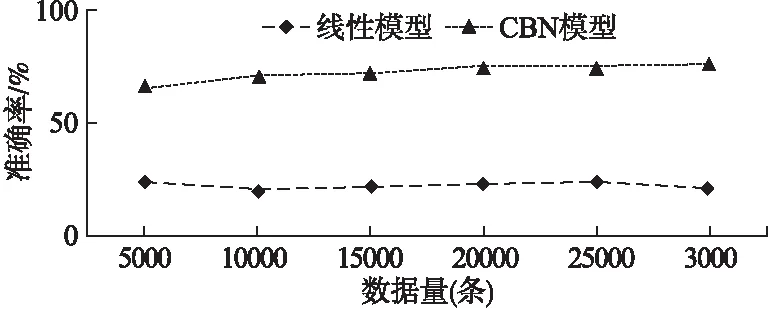

Table 3 Error and relative error of CBN predictions
5 总结与展望
