融合用户经历的多策略自适应推荐模型
2019-07-09原福永冯凯东黄国言梁顺攀
原福永,冯凯东,李 晨,雷 瑜,周 馨,黄国言,梁顺攀
1(燕山大学 信息科学与工程学院计算机系,河北 秦皇岛 066004) 2(东北大学 软件学院,沈阳 110179)
1 引 言
随着互联网信息的爆炸式增长,推荐系统[1,2]越来越多地被选择为应对信息过载问题[3]的有效手段,例如亚马逊、阿里巴巴等平台利用推荐系统,帮助用户选择可能与用户当前任务相关但尚未体验过的产品来解决此种问题.
现有的推荐研究中采用非个性化推荐策略或个性化推荐策略来解决不同的问题.非个性化推荐策略主要用于解决冷启动用户的问题,算法通过不同维度(如,地理位置、社交网络等)获得冷启动用户[1]的基本特征,从而进行粗粒度[2]的推荐.其中最常用的方法是利用大众口味对冷启动用户进行推荐,待系统获取用户数据到一定阈值后,即系统积累了一些用户数据,再转用个性化推荐策略.
个性化推荐策略是很多推荐算法常用的策略,主要针对非冷启动用户,系统根据已有用户数据进行细粒度的推荐[2].目前矩阵分解算法[4]作为个性化推荐策略在推荐算法领域表现出优异的性能,该算法能够很好地补全用户-物品的评分矩阵中的缺失值并将缺失值作为个性化偏好的预测值,从而达到推荐的效果.
当前推荐系统方法主要可以分为两类[5]:基于显式反馈的推荐方法和基于隐式反馈的推荐方法.基于显式反馈(explicit feedback)的推荐方法通过获取用户的历史评分或者评价信息,对用户的潜在评分进行预测.但该方法往往需要大量的用户评分数据.在实际场景中,会存在用户很少购买或评价商品造成的评分数据稀疏问题,这使得该方法的应用受到限制,无法准确地为用户提供推荐.
基于隐式反馈(implicit feedback)[6,7]的推荐方法不同于显式反馈方法,不需要获取显式信息,而是通过获取用户的行为信息(如浏览点击,收藏等行为),得出用户偏好信息.由于用户的隐式信息远远多于显式信息.因此,该方法受到广泛应用.
本文的主要工作如下.1)提出了用户经历,将用户参与的隐式反馈加权和作为用户经历,将用户经历作为一个平衡系数使不同的推荐方法间有一个平滑的过渡;2)在此基础上,在该模型上加入阻尼系数,使得不同“经历”的用户都被推荐到热门的商品,从而防止推荐内容过于单一;3)利用贝叶斯个性化排名-优化规则对模型进行优化,对最后的推荐结果进行排名;4)在两个真实数据集上进行实验,采用随机梯度下降方法对参数进行训练,采用多种评估指标进行评估,得出评估结果并与其它算法进行比较分析.
2 相关工作
本节将介绍基于隐式反馈的推荐方法的相关工作,现有的隐式反馈推荐方法研究中,将隐式行为分为目标行为和辅助行为,因此可将隐式反馈推荐方法分为基于目标行为的推荐方法、基于目标行为与辅助行为的推荐方法和基于所有行为的推荐方法.
2.1 基于目标行为的推荐方法
目标行为是指只选用相对影响大的行为,如在点击、收藏以及购买三个行为中,只选择购买行为作为有效数据.Koren Y等人提出的基于矩阵分解的推荐方法[4]通过建立用户商品矩阵,将目标行为对应的商品作为已知,进而预测出矩阵中的未知值.例如奇异值分解(SVD)方法.Mnih A等人提出的基于概率的矩阵分解方法(PMF)[8]在矩阵分解方法基础上引入概率模型,利用最大后验分布与最大似然估计得出的特征矩阵来预测矩阵值.但是上述方法对于非目标行为利用不充分,而Rendle S等人提出的贝叶斯个性化排序(BPR)[9]算法将目标行为作为正向数据,将非目标行为作为负向数据,提出用户相对于负向数据更倾向于正向数据的观点,并提出了通用性的贝叶斯个性化排名-优化标准(BPR-OPT),通过贝叶斯分析得到最大后验分布,使得优化过的评估结果得到大大提高.BPR中只是将隐式反馈分为目标行为与非目标行为,没有将隐式反馈进一步划分.
2.2 基于目标行为与辅助行为的推荐方法
只对目标行为进行处理会导致数据处理不充分,因此在采集目标行为数据之外,加入辅助行为,例如在把购买作为目标行为之外,将点击作为辅助行为加入到模型中,将辅助行为与目标行为相结合,从而得到更为精准的推荐结果.Pan W等人提出的自适应贝叶斯个性化排序(ABPR)[10]将用户的购买行为作为目标行为,将点击行为作为辅助行为,首次提出将辅助行为与目标行为联系到一起.Qiu H等人提出的基于三位一体偏好的多元隐式反馈贝叶斯个性化排序(TBPR)[11]在联系辅助行为与目标行为基础之上,加入了无交互行为(用户与商品无行为发生),推荐效果得到提升.但上述推荐方法只是应用到了少数隐式行为,并没有将所有的隐式行为考虑进去.
2.3 基于所有隐式行为的推荐方法
基于所有隐式行为是将所有的隐式行为都作为目标行为,为不同的行为赋予不同的权重值,从而利用所有的隐式反馈信息,得到精准的推荐结果.Loni B等人提出的基于多层次用户反馈的贝叶斯个性化排名(MC-BPR)[12]利用不同层次的隐式反馈对采样进行扩展.不同于BPR中的目标行为大于非目标行为,而是详细给出不同隐式行为的权重,高权重的隐式行为大于低权重的隐式行为进而大于未观测到的行为,而未观测到的行为优于差评行为.但是该方法没有解决用户冷启动问题,只是增强了用户个性化推荐部分.
本文提出的融合用户经历的自适应推荐模型能够很好地解决用户冷启动与个性化推荐之间的关系,实现了从用户冷启动到个性化推荐的平滑过渡,使得推荐结果更加人性化,更符合用户需求.在用户经历中,考虑到了所有的隐式行为,通过迭代训练为每个用户的每种隐式行为赋予不同的权重.引入阻尼系数,提出加入阻尼系数的融合用户经历的自适应模型,以防止推荐内容过于单一,保证针对不同“经历”的用户都能被推荐到热门的商品.在后面的实验部分中,实验结果表明加入阻尼系数的模型效果更优.
3 融合用户经历的多策略自适应推荐模型
本节主要提出了一种融合用户经历的推荐系统模型.首先引入用户经历的概念,并介绍用户经历在模型中的作用.其次给出了需要平衡的多种策略,最后提出利用用户经历进行平衡的多策略自适应模型.
3.1 用户经历
如上所述,隐式反馈相对于显式反馈,不需要用户主动提交反应用户偏好信息的行为,是比较容易获得的.因此本文利用隐式反馈,将用户的隐式反馈累计数量作为用户经历.具体定义如式(1)所示.
(1)
式(1)中eui表示用户u对商品i的经历值,Xuik表示用户u对商品i在反馈行为k上的数量,Wuk表示用户u在反馈行为k上的权重值.
3.2 多种策略
3.2.1 非个性化推荐策略
非个性化策略,是针对冷启动问题,行为数量少的用户的推荐策略.本文选择的是根据物品本身的属性进行推荐,借鉴了经典算法Most Popular和用于信息检索与文本挖掘的常用加权方法词频-逆文档频率的思想,即物品的评分数据与物品在数据集记录中出现的次数成正比,如公式(2)-公式(4)所示.
popi=σ(ci,cavg)
(2)
(3)
(4)
式(2)中POPi表示物品i的受欢迎程度,Ci表示物品i词频,即物品i在数据集中出现的次数.式(3)中Cavg表示平均每个物品的记录数,Call表示数据集中的总记录数,Cai表示物品出现的次数.
3.2.2 个性化推荐策略
个性化推荐策略,是针对用户个性化的推荐策略.在机器学习领域,隐式因子模型表现出优秀的性能,又因为基本的矩阵分解的参数相对较少,能够在一定程度上减小训练的难度,因此,本文实验选择隐式因子模型来训练.将用户-物品的行为矩阵低秩表达为用户特征矩阵和物品特征矩阵,用户特征矩阵表示用户对隐式特征的包含程度,物品特征矩阵表示物品对隐式特征的包含程度,通过计算用户向量和物品向量的点积确定用户对物品的偏好程度.具体如公式(5)所示.
(5)
其中,pu表示用户的特征矩阵,qi表示商品的特征矩阵,Xui表示用户u对商品i的预测评分.
3.3 融合用户经历的多策略平衡
本模型通过引入经历系数,实现多种策略的平衡,主要分为三个部分:非个性化策略、个性化策略和经历系数,模型如公式(6)所示.
(6)

经历系数,是非个性化策略与个性化策略之间的平衡系数,当用户在系统中的数据十分稀疏时,经历系数的值很小,此时非个性化策略在用户喜爱偏好上占主导作用;反之,经历系数值很大,个性化策略在决定用户喜爱偏好上占主导作用.假设用户的不同隐式反馈行为是不同的维度,将用户在各个维度上的隐式反馈行为数目加权求和作为经历系数,如公式(1)所示.
为了提高训练时每次迭代的训练速率,本文将公式(1)简化,提前算好常量用户隐式反馈的数目,如公式(7)所示.
(7)
3.4 融合用户经历的多策略自适应推荐模型
自适应是根据已有的数据特征不断调整,从而达到不断逼近目标的目的.机器学习是通过学习模拟大量的数据规律,然后利用学习规律预测新的事物.自适应推荐模型需要通过机器学习的训练方法来获得最佳的处理效果.梯度下降法(Gradient Descent Optimization)是机器学习中最常用的训练优化方法.
对于自适应推荐模型,基本都是采用梯度下降算法来进行优化训练的.梯度下降算法的原理是通过计算得到的目标函数对于参数的梯度是目标函数上升最快的方向,对于最小化优化的问题,只需要设置参数在梯度相反的方向增加一个学习速率,即步长,就可以实现在目标函数上的下降.参数更如公式(8)所示.
θ=θ-ηJ(θ)
(8)
公式(8)中J(θ)表示参数的梯度,η表示学习速率.
本文使用的是梯度下降方法中的随机梯度下降算法(Stochastic Gradient Descent),因此在本文实验中采用的数据集样本量很大的情况下,只需少量样本数据,就可以将所有参数迭代到全局最优解或局部最优解.
在以上基础上,本文采用贝叶斯个性化排名优化准则(BPR-OPT)[6]对最终的推荐结果进行排序,并将排名前十的商品推荐给用户.
在文献[6]中,BPR-OPT的定义如式(9)所示.
(9)
式(9)中λθ表示模型的正则化参数,θ表示要求解的模型参数.p(>u|θ)定义如式(10)所示.
p(>u|θ)=σ(ruij(θ))
(10)
ruij(θ)表示模型参数θ的任意矢量函数.对于本文应用的矩阵分解模型,在文献[6]中,ruij定义如公式(11)所示.
ruij=rui-ruj
(11)
其中rui为用户u对商品i的评分预测,具体表达式如公式(11).利用随机梯度下降算法对BPR-OPT进行求解.如公式(12)所示.
(12)
(13)
(14)
(15)
(16)
4 模型优化
上述融合用户经历的多策略自适应推荐模型忽略了一个问题,即一味地为“用户经历”丰富的用户推荐个性化的商品,这会导致推荐的结果过于单一,正如机器学习中的过拟合问题,本推荐模型面临着“过个性化”的问题.
借鉴谷歌的佩奇排名(Page Rank)算法的思想,大多数用户都不会接受“过个性化”的推荐,他们希望得到个性化推荐的同时,也能体验时下的热点信息.因此,本文猜想对非个性化策略的比重加以控制,是否能够提升推荐算法的预测精度.
具体做法是:将佩奇排名算法的思想融入到本文的研究中,即使对于非常有“用户经历”的用户,也会获得非个性化的推荐内容.引入阻尼系数,将其作为非个性化策略的系数,使针对不同“用户经历”的用户都被推荐到热门的商品,以此提升算法的新颖性.用户对于物品的个性化预测评分模型如式(17)所示.
(17)
公式(17)中γ表示控制非个性化策略的系数,防止在用户行为较多的情况下,用户的非个性化推荐策略完全消失.同样需要更新的参数为Pu,Qi,Qj和Wuk,对于Pu,Qi和Qj三个参数来说,更新公式如公式(13)-公式(15)所示.Wuk对应的参数更新梯度如公式(18)所示.
(18)
通过公式(13)-公式(16)多次迭代更新参数Pu,Qi,Qj和Wuk,达到最大迭代次数或者达到收敛条件,最终得出较优的参数值.
算法1.融入阻尼系数的融合用户经历的多策略自适应推荐模型参数求解算法.
输入:用户对商品行为集合,用户集合,学习率,正则化系数以及阻尼系数;
输出:参数集合Pu,Qi,Qj和Wuk.
步骤:
1.初始化参数Pu,Qi,Qj,Wuk;
2.Repeat;
3.从用户集合中选取用户u,从该用户对应商品集合中选取商品i;
4.计算用户经历eui;
8.Util 达到最大迭代次数或收敛;
9.End.
5 实验结果与分析
本节主要展示在两个真实数据集Sobazaar和淘宝上,本文提出的两个算法及相关算法的实验结果,并进一步对实验结果进行分析.
5.1 数据集
Sobazaar[注]https://github.com/hainguyen-telenor/Learning-to-rank-from-implicit-feedback/tree/master/Data是由Telenor Digital开发的一款时尚社交应用程序.该应用可以提供给用户许多不同的时尚服装,用户可以自行设计发表的内容.数据集的样本数据来源于2014年9月至2014年12月,所有用户在Sobazaar应用的行为信息,用户行为信息分为9种.
淘宝数据集[注]https://tianchi.aliyun.com/datalab/dataSet.html?spm=5176.100073.0.0.26a16fc1khUmdr&dataId=6包含了从2017年11月25日至2017年12月3日之间的用户的行为记录,记录了约一百万名随机用户的四种行为(用户行为包括了点击、购买、加入购物车、喜欢).
两个数据集的主要行为数量对比如表1所示.从表1可以看出,淘宝数据集的规模要远大于Sobazaar数据集的规模.
5.2 评估指标
在推荐系统领域中,评估指标作为衡量推荐系统算法效果的标准,评估指标可分为[13,14]预测指标(prediction metrics)、集合推荐指标(set recommndation metrics)、排名推荐指标(rank recommendation metrics)以及多样性指标(diversity metrics).
表1 Sobazaar与淘宝数据集行为数量
Table 1 Behavior number of sobazaar and taobao
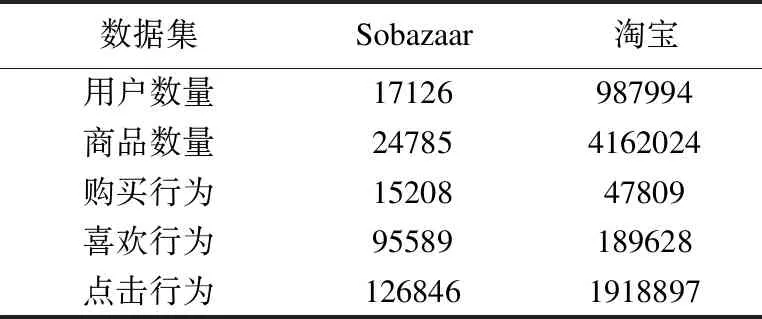
数据集Sobazaar淘宝用户数量17126987994商品数量247854162024购买行为1520847809喜欢行为95589189628点击行为1268461918897
由于在本文提出的模型中需要为用户按照权重推荐不同的商品,因此本文选用的是集合和排名推荐指标,包括准确率(precision)、召回率(recall)、AUC以及NDCG.
在本文中,采取留出法对数据集进行划分.即将数据集中的80%作为训练集以对模型进行构建,将20%作为测试集,对模型进行验证.
1)准确率(precision)
表示在预测出的所有推荐结果中,与用户相关的推荐结果所占比例.具体表达式如(19)所示.
(19)
其中,K表示为用户推荐项目的数目,本实验中设置K=10,δ(x)函数表示当x条件为真时,函数返回1,否则返回0.Zu表示用户u在测试集中的所有目标行为集合.准确率越高,代表推荐结果更加准确.
2)召回率(recall)
表示在所有与用户有关的商品中,被推荐出来的商品所占比例.具体表达式如(20)所示.
(20)
其中,Tu表示用户u的所有目标反馈行为集合.召回率越高,代表推荐结果更加精确.
3)AUC
本意指ROC曲线下面积,文献[6]中将其进行类推,并作为评估BPR-OPT算法效果好坏的指标.具体表达式如式(21)所示.
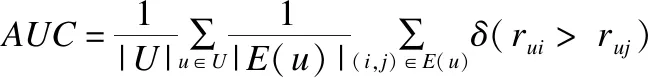
(21)

4)归一化折损累积增益(NDCG)
具体定义式如式(22)(23)所示.
(22)
(23)
其中,ru,ij表示用户u对商品ij的行为预测,IDCGu为idealDCGu即需要对K个用户商品预测值首先进行降序排序,根据式(23)计算可得出IDCGu值.
5.3 实验结果
为了验证本文算法的优越性,我们设计了两组实验,其中第一组验证加入阻尼系数对模型的影响.第二组将本模型与其它模型进行对比,最终得出实验结果.
5.3.1 UE+实验结果
本节在两个数据集上对两个算法进行实验,得出结果如图1所示.通过图1中的曲线趋势可以看出,随着迭代次数不断增加,模型逐渐收敛.并且在两个不同的数据集上,UERM+模型在两个不同的评估标准下的效果明显优于UERM模型,从而在两个数据集上,证明加入阻尼系数后的模型效果是要优于不加入阻尼系数的模型,验证了优化方案的正确性.
5.3.2 对比其他自适应推荐模型的实验结果
将UERM+模型与以下三种模型进行比较,比较结果如表2所示.
表2 比较模型在Sobazaar和taobao数据集的评估结果
Table 2 Evaluation result comparison on Sobazaar and taobao
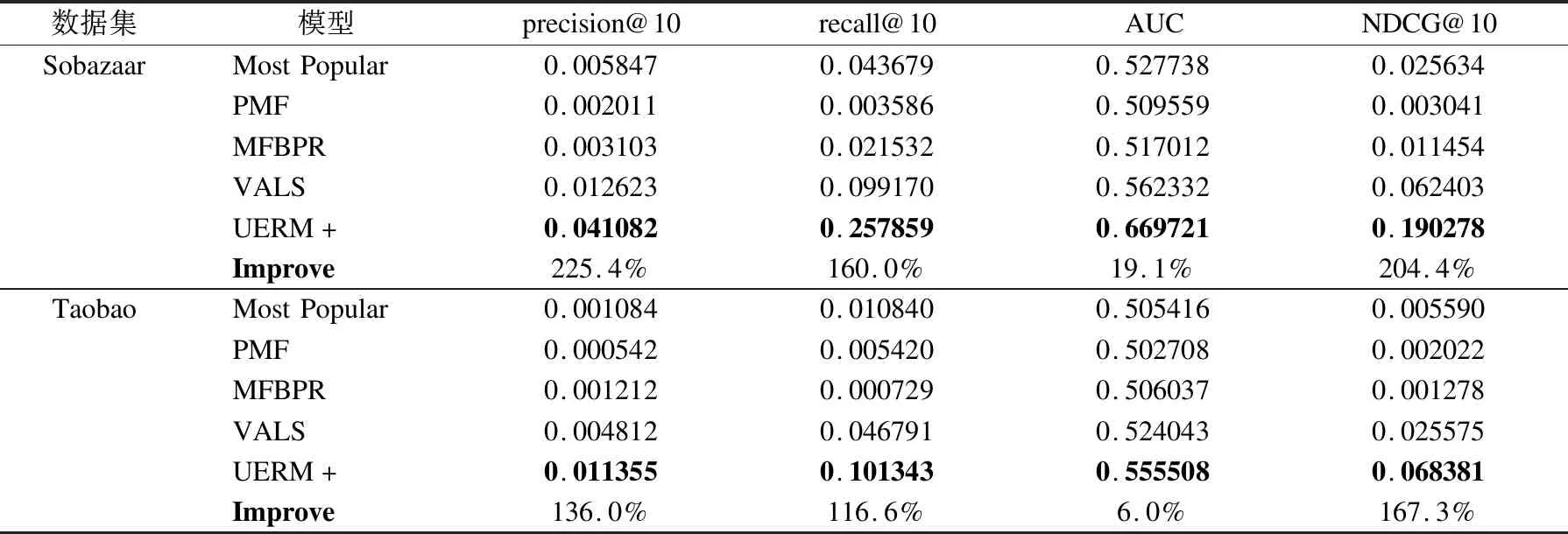
数据集模型precision@10recall@10AUCNDCG@10SobazaarMostPopular0.0058470.0436790.5277380.025634PMF0.0020110.0035860.5095590.003041MFBPR0.0031030.0215320.5170120.011454VALS0.0126230.0991700.5623320.062403UERM+0.0410820.2578590.6697210.190278Improve225.4%160.0%19.1%204.4%TaobaoMostPopular0.0010840.0108400.5054160.005590PMF0.0005420.0054200.5027080.002022MFBPR0.0012120.0007290.5060370.001278VALS0.0048120.0467910.5240430.025575UERM+0.0113550.1013430.5555080.068381Improve136.0%116.6%6.0%167.3%

图1 两种模型在不同迭代次数下的评估结果Fig.1 Evaluation resuls of two models in different iterations
1)MostPopulary:一种非个性化推荐模型,通过统计商品与用户的交互行为次数,将行为次数多的商品推荐给用户.
2)PMF:Mnih A等人[8]提出的利用概率模型优化矩阵分解的方法.
3)MFBPR:Rendle等人[9]提出的贝叶斯个性化排序是首个将成对法应用于商品推荐的算法,通过成对排序思想优化矩阵补全模型,并通过随机梯度下降方法对参数进行训练.
4)VALS:Ding等人[15]提出的目前较为先进的利用隐式反馈的个性化推荐模型.通过将隐式反馈行为分为购买,查看和未查看三种行为,进一步利用用户隐式反馈提高个性化推荐质量.
由表2可以看出:
1)非个性化策略的重要性:从两个数据集中可以看出,Most Popular非个性化策略在某些场合下的效果是要优于个性化策略的,如以precision指标为例,在上述表2中,可以看出Most Popular模型得出的值是大于PMF以及MFBPR两个模型的,充分说明了非个性化策略在推荐结果中的重要性以及不可忽略性.
2)个性化策略的改进:在推荐系统中,如何提高个性化策略一直是近年来研究的热点.从表2中结果可以看出,VALS作为目前最新的研究成果在各个评估指标上都优于之前提出的个性化推荐模型.证明了个性化推荐在推荐系统研究中的重要地位.
3)平衡系数用户经历:从表2中可以看出,加入用户经历作为平衡系数之后,在不同数据集的不同评估指标上,UERM+模型的效果明显优于其它模型.验证了本文提出的融合用户经历的自适应推荐模型,在融入阻尼系数后,达到了本文的预期结果.
6 结论与工作展望
本文提出了融合用户经历的自适应推荐模型(UERM)以及融入了阻尼系数的UERM+模型.相对于其它模型,本文首先充分利用了用户的隐式反馈,将用户的所有隐式行为信息利用起来.其次引入了用户经历概念,将用户的行为种类赋予初始权重,并在不断训练中更新权重,将行为权重与行为数量结合构成用户经历.最后,以用户经历作为系数将个性化策略与费个性化策略相结合.并在此基础上,引入阻尼系数对初始模型进行优化,防止由于用户经历过大导致个性化策略与非个性化策略之间的失衡,使得非个性化策略失效.
通过在两个真实数据集上进行实验,验证了本文模型在不同评估指标上,效果优于其它模型,能够为用户提供更加准确的推荐结果.
本文的主要工作是利用隐式反馈将个性化与非个性化推荐策略结合起来.在以后的工作中,将深度学习与推荐系统相结合,从而改进个性化推荐策略,从而提高个性化推荐质量.
