基于主题层次的文本篇章结构分析方法
2019-07-08黄细凤
黄细凤

摘要:针对文本篇章结构分析与语义内容理解,提出了基于主题层次的文本篇章结构分析方法,包括文本篇章结构表示体系、文本篇章结构分析框架及关键技術描述。首先根据文本篇章的外在形态和内在逻辑构建了包含主题维度和结构维度的文本篇章结构表示体系,然后,基于表示体系构建了基于主题分割的文本篇章结构分析框架,并重点对其中的主题分割和篇章关系分析算法进行了阐述。
关键词: 篇章结构分析; 篇章关系识别; 主题层次; 主题分割; 句际关系
中图分类号:TP306 文献标识码:A
文章编号:1009-3044(2019)13-0012-05
Abstract: For text structure analysis and semantic content understanding, a text structure analysis method based on topic level was proposed, which includes text structure representation system, text structure analysis framework and key technologies description. Firstly, according to the external form and internal logic of text, a text structure representation system including topic dimension and structure dimension was constructed. Then, a text structure analysis framework based on topic segmentation was constructed based on the representation system, and the algorithms of topic segmentation and text relationship analysis were emphatically expounded.
Key words: text structure analysis; text relation recognition; topic level; subject segmentation; inter-sentence relations
1 引言
文本的篇章结构分析与语义内容的自动理解是自然语言处理(Natural Language Processing,简称NLP)的一项重要的基础研究内容,是基于文档库的问答系统、文本阅读理解、文本的摘要生成等技术和应用系统所必需的研究基础。
自然语言的单位由小到大可以分为字、词、短语、句子、段落和篇章;其中,篇章的语义最为完整,能够从多个侧面、按多层级关系,描述具有关联关系的一个或多个主题、事件、问题或情境,它由一系列连续的子句、句子或语段构成。因此,篇章既包含了组成篇章的各级语义单元,还包含了他们之间的链接及逻辑关系。目前,针对篇章结构的分析一般也是基于修辞结构理论(Rhetorical Structure Theory, RST)从这两个维度进行的,具体包括对篇章单位、连接词、篇章结构、篇章关系、篇章主次等方面的分析。
英语篇章结构分析的理论研究比较多,相关理论主要包括Hobbs模型[1-2]、修辞结构理论(Rhetorical Structure Theory, RST)[3-4]和宾州篇章树库体系(Penn Discourse Tree Bank,PDTB) [5-6]。汉语篇章结构分析的理论研究较少,当前阶段,仍然基于西方现代篇章语言学理论(比较有影响的是RST和PDTB体系)所进行,因此需要建立适合汉语特点的篇章结构表示体系。为了进行全面、系统的篇章级文本分析,本文提出了一种基于主题层次的篇章结构表示体系,在此基础上建立了文本篇章结构分析的框架。
2 基于主题层次的文本篇章结构表示体系
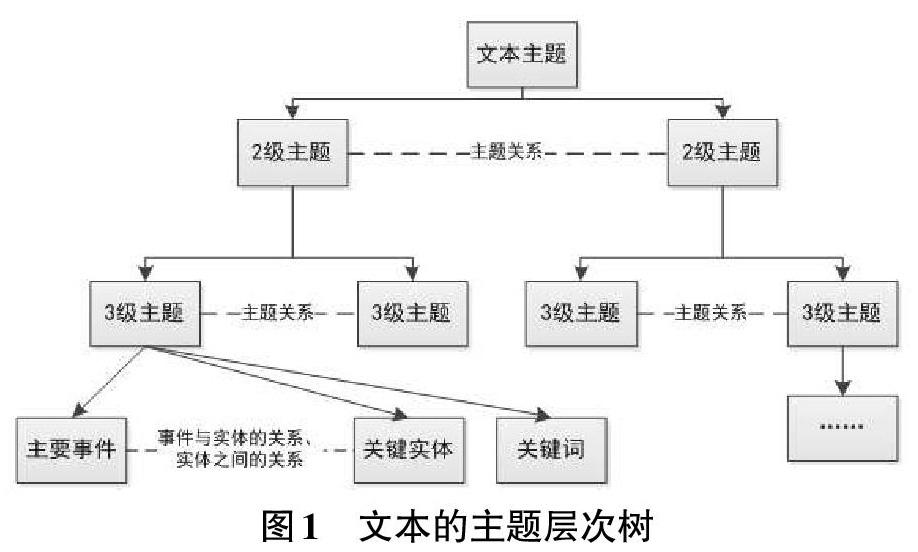
一篇文档(尤其是长文档)往往描述了一个主题,而各个不同语义片段又描述了该主题的不同侧面,不同侧面下还可进行再细分,因此整篇文档的各层语义片段的主题共同形成了一棵主题层次树。主题层次树中的不同节点之间存在着不同的关联关系;在不同层级的主题中,又包含了不同的语义单元和连接关系,如图1所示。
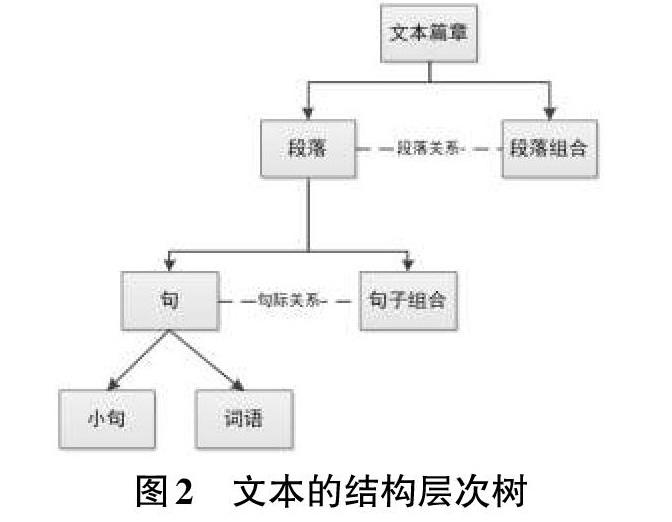
从文本的组织上,文本篇章是通过各级语义单位按照一定关系进行组织的,由词语和小句(小句即一个句子中包含的小的分句)构成句子,由句子的组合构成段落,由段落的组合构成篇章;其中,篇章关系表示同一篇章内相邻或跨度在一定范围内的文本片段之间的语义连接关系,可以包括句际关系(即句子或小句之间的关系)和段落之间的关系(也称为宏观篇章关系)。其层次组织关系如图2所示。
根据文本的篇章组织结构以及所表达的主题层次,将一篇文本分解成如图3所示。
从而形成基于主题层次的篇章结构表示体系,如图4所示。文本的外在形态是篇章结构层次及关系、内在逻辑是主题层次及关系;篇章结构层次之间的关系反映的就是主题层次的关系。
基于主题层次的篇章结构表示体系包括表示维度和描述方法。表示维度从主题维度来说,包括主题、子主题、元事件、实体等,其中,主题和子主题通过主题描述、关键词、主题与子主题的关系、子主题间的关系等;元事件通过元事件类型、元事件描述、各要素等来描述。结构维度包括篇章、段落、句等,并通过篇章结构层次、篇章关系来描述。
3 基于主题分割的文本篇章结构分析框架
根据文本篇章结构表示体系可知,从篇章内容本身来说,一篇文本可以包含篇章段落结构、按篇章结构组织的文本内容、按篇章结构组织的多级主题和其他重点描述内容;为了获得这些内容,本文建立的文本篇章结构分析框架如下图所示,包括篇章结构解析和主题中相关重要内容的抽取。对于篇章段落的层次结构和关系识别是对文章宏观层面的分析,是自顶向下对文章的分解,当前篇章关系识别多从篇章基本单元入手,分析句子之间文本片段的连接关系,是以自底向上的角度进行篇章关系的分析,但难以对篇幅规模较大的文本进行全面归纳,因此,本文提出了一种自顶向下的基于主题分割的文本篇章结构分析框架。如图5所示。
基于主题分割的文本篇章结构分析框架中,通过多级主题分割,识别出篇章中包含的所有主题;同时结合篇章关系识别,将主题之间的关系和层次构建出来;并对各个主题进行描述。其中,篇章关系识别包括主题间的篇章关系和主题内的篇章关系,本文中,篇章关系的最小粒度即基本篇章单元(EDU)为小句。本文基于文献[11],定义了汉语篇章关系类型,如表1所示。
表中“[ ]”内表示英文标记符。关系包含大、中、小三种关系类型,显示了不同粒度下的类型区分。大类上(CLASS)区分了“附属”“联合”“主从”三个类型。中类上划分为 6 个类别,最细致的小类上划分为 17 个类别。在上述大、中、小三层语义关系下,进行篇章关系分析时可以根据实际应用需求选择不同的粒度。
例如,在识别主题间的篇章关系时,关注的是相对宏观的篇章关系,就可以选择第2层中的并列、对比、推理、条件、总分、分总来表述。而在识别句间的主题内篇章关系时,就可以选择第2层到第3层的语义关系。
内容抽取主要包括元事件及实体抽取,完成句子级或篇章级的元事件抽取、实体相关内容抽取(包括实体抽取、实体相关描述、属性及关系的抽取等)。其中,元事件是表示一个动作的状态或变化的细粒度事件,是各级主题内容的重要组成。根据ACE测评中对元事件描述的相关术语有:事件类型、事件描述、事件触发词、事件实体、事件实体描述、事件论元角色等。
4 关键技术实现方法概述
基于主题层次的文本篇章结构分析中,主要涉及的关键技术有主题分割、篇章关系识别、元事件抽取、实体抽取、实体关系抽取等。总体处理思路是:人工标注一定规模的训练语料,包括通用领域和特定领域,而后采用机器学习方法训练模型进行自动分析和抽取。本文重点对主题分割、篇章关系识别方法进行概述。
4.1 主题分割
文本分割算法中需要解决的两个根本问题是主题相关性度量以及边界划分策略。目前,文本分割方法主要有如下三种:(1)根据语言学特征,认为特定的语言现象,比如提示短语、新词出现、命名实体、韵律特征、停顿标记、重复特征、指代使用、句法以及词汇的形态同化等与片段首尾隐含着某种必然联系;(2)假定相同、相似或语义相关的词汇倾向于描述同一个主题,即倾向于出现在同一主题片段內。需要从语料库中统计分析词搭配、互信息和词汇共现频率等语言知识,作为分割的依据;(3)认为合适的概率统计模型能够为片段边界的估计提供可靠依据。近几年,主题模型幵始应用在文本分割领域,取得了很好的分割效果,特别是LDA模型的应用。提下面介绍基于LDA模型的文本分割算法。
主题分割方面,可以采用基于LDA模型的文本分割。
一个文本通常需要讨论若干个主题,而文本中的特定词汇表征了所讨论的主题。在文本主题建模中,将主题视为词汇的概率分布,文本为这些主题的随机混合。假设有T个主题,则所给文本中第i 个词汇可以表示为:
利用局部最小值的边界估计策略,通过句间相似值识别段落边界。按相关度结果绘图,高相关处出现波峰,低相关处出现波谷,选择波谷处作为分界线,将自然段组合成语义段。进一步,选择该语义段中概率最高的前L个词作为主题词。
4.2 篇章关系分析
如前所述,篇章关系分析根据关系粒度可以分为宏观篇章关系识别和句际关系识别。篇章关系分析根据是否存在连接词,分为显式篇章关系识别和隐式篇章关系识别两大类。显式关系的显著特征是篇章的基本单元之间存在显式连接词,因此,显式篇章关系识别主要包含了汉语连接词识别和篇章关系分类两个步骤。隐式关系识别由于连接词缺失,判断两个基本篇章单元之间存在何种逻辑关系较困难,通常只能根据一些语言学特征进行关系识别。
目前国内的篇章关系研究仍处于初级阶段,文献[15]提出构建中文篇章树库的任务,文献[16]根据中文特点基于PDTB语料的标注特征提出具体的中文篇章关系标注准则,文献[17]参照PDTB中定义的篇章关系类型,初步构建面向中文的篇章关系分析数据。
下面介绍一种基于监督学习和规则相结合的方法。
自下而上进行篇章关系识别时,可以分为三个步骤:第一步,将句子切分为基本篇章单元(EDU);第二步,分析句子之间的修辞关系,构建层级结构树,以表征各个EDU的层级结构;第三步,识别结构树中节点之间的内部关系,以表征各个EDU的关系标签。
第一步中,直接利用标点符号“,”将句子切分为互不重叠、交叉、连续的“小句”,即基本篇章单元(EDU)。
第二步,层级结构分析,可以采用排序SVM和基于规则的方法。
排序SVM方法中,将连续三个篇章单元作为一个样例,通过比较此相邻两对篇章单元的结合紧密程度定义正例和负,来训练分类器。
基于规则的方法中,一个IF-THEN规则是一个如下的表达式:IF条件THEN结论。规则的结论包含一个类预测,这里指的是是否合并节点。
规则和 SVM 分类器融合的方法为:
1)使用冒号和分号将整个句子切分成多个子句序列;
2)对于分号切分开的并列语句,分别使用 SVM 方法建树;
3)对于使用冒号切分开的语句,如果左半部分包含不止一个小句,那么先将最后一个小句与右半部分合并建树,再和左半部分其余节点一块儿使用 SVM 方法建树。
第三步,句际关系识别,基于SVM的方法:在人工标记语料上训练多分类SVM模型,然后利用训练好的模型对句子层级结构树中每一个内部节点进行关系识别。规则方法:主要是借助连接词和副词信息进行规则判定。
每个训练样例(待识别的层级结构关系树内部节点)都由两个篇章单元(当前关系树的左右子树)组成,分别记为左单元(UL)和右单元(UR)。方便起见,将左单元最后一个EDU记为EUL,右单元第一个EDU记为EUR。实验中SVM模型采用的特征如表2 所示:
5 实验
本文基于文本篇章结构表示体系,采用基于文本分割的篇章结构分析方法,参考文献[11]的篇章级句际关系标注体系,开发了标注工具,进行了一定数据的篇章关系语料标注;在文本结构层次分析中采用基于LDA的文本分割方法,对于一篇有42个自然段的长文本,实验结果如图6所示。
然后采用文中基于监督学习和规则相结合的方法,对主题内的句际篇章关系进行分析,其中一段的分析结果如图7所示。
基于人工标注数据进行测试,层级结构分析的正确率为 66.5%,关系类型识别的F值为71%。实验表明,本文提出的自顶向下的篇章结构分析思路具备良好的有效性。
6 结论
在本文中,我们提出了一种基于主题层次的文本篇章结构分析方法,这是一种自顶向下的篇章结构表示体系,能够从宏观和微观角度建立文本篇章的画像,扩展了篇章结构的表示维度;基于该表示体系,本文提出了基于文本分割的篇章结构分析框架,能有效实现对篇章结构的分析。
参考文献:
[1] Hobbs J. R. Coherence and coreference[J]. Cognitive Science, 1979,3(1):67-90.
[2] Hobbs J. R. Information, Intention, and Structure in Discourse: A first draft[C]. In Burning Issues in Discourse, NATO Advanced Research Workshop, 1993:41-66.
[3] Mann W. C. and Thompson S. A. Relational propositions in discourse[J]. Discourse processes, 1986, 9(1):57-90.
[4] Mann W. C. and Thompson S. A. Rhetorical structure theory: A theory of text organization[M]. University of Southern California, Information Sciences Institute, 1987.
[5] Mann W. C., Matthiessen C., and Thompson S. A. Rhetorical structure theory and text analysis[J]. Discourse description: Diverse linguistic analyses of a fund-raising text, 1992:39-78.
[6] Prasad R., Dinesh N., et al. The Penn Discourse Treebank 2.0[C]. In Proceedings of LREC, 2008:2961-2968.
[7] PDTB Research Group. The Penn discourse treebank 2.0 annotation manual[R]. IRCS Technical Reports Series, 2007, 99p.
[8] 丁彬, 孔芳, 李生. 漢语显式篇章关系分析[J]. 北京大学学报(自然科学版),2014, 28(6):101-106.
[9] 孙静, 李艳翠, 周国栋. 汉语隐式篇章关系识别[J]. 中文信息学报, 2014,50(1): 111-117.
[10] 吕国英, 苏娜, 李茹. 基于框架的汉语篇章结构生成和篇章关系识别[J]. 中文信息学报,2015,11.29(6): 98-109.
[11] 吴云芳, 徐艺峰, 王恺然. 汉语篇章级小句关系的标注体系[J]. 中文信息学报,2015,5. 29(3): 71-81.
[12] 严为绒, 徐扬, 朱珊珊. 篇章关系分析研究综述[J]. 中文信息学报.,2016,7. 30(4): 1-11.
[13] 李国臣, 张雅星, 李 茹. 基于汉语框架语义网的篇章关系识别[J]. 中文信息学报, 2017,11. 31(6): 172-189.
[14] 李效晋. 基于统计模型的文本分割方法及其改进[J]. 山东: 山东大学, 2014.
[15] N Xue. Annotating discourse connectives in the Chinese Treebank[C]. Proceedings of the Workshop on Frontiers in Corpus Annotations II: Pie in the Sky, 2005: 84-91.
[16] Y Zhou, N Xue. Pdtb-style discourse annotation of Chinese text[C]. Proceedings of the 50th Annual Meeting of the ACL, 2012: 69-77.
[17] H H Huang, H H Chen. Chinese Discourse Relation Recognition[C]. Proceedings of the 5th International Joint Conference on Natural Language Processing (IJCNLP), 2011: 1142-1146.
【通联编辑:唐一东】
