Swift的哈希一致性副本数据备份节点自适应选取研究
2019-07-08杜华郭俊刘华春
杜华 郭俊 刘华春



摘 要: 冗余数据备份是云数据中心下数据可靠性的重要保障机制之一,OpenStack是一种开源的云计算IaaS层私有云服务搭建平台,目前已经在行业界广泛应用。OpenStack的Swift模块采用一致性哈希算法,通过Ring环选取副本备份节点的方式完成负载均衡和数据备份。通过对Swift的实现机理和代码进行分析研究,指出其在副本放置节点选取上的不足,进而提出优化选取策略ABS。该机制在实时监控当前存储节点的负载情况基础上,根据预先设定的阈值上、下限自适应选取最近可用的节点完成备份,以优化整体备份效率。通过与现有副本备份策略进行对比和实验验证表明,ABS在保持数据副本分配均衡性的基础上,将系统存储的四种读写性能分别提高了3.4%~9.1%,达到了优化存取的目的。
关键词: 副本; 数据备份; Swift; ABS; 自适应选取; 负载均衡
中图分类号: TN915.9?34; TP311 文献标识码: A 文章编号: 1004?373X(2019)13?0090?06
Research on adaptive selection of Swift′s Hash consistency replica data backup node
DU Hua1, 2, GUO Jun2, LIU Huachun2
(1. Southwestern Institute of Physics, Chengdu 610225, China; 2. Department of Electronic Information and Computer Engineering, The Engineering
and Technical College of Chengdu University of Technology, Leshan 614000, China)
Abstract: Redundant data backup is one of the important guarantee mechanisms to ensure the reliability of data under the cloud data center. OpenStack is an open source platform for cloud computing, which belongs to IaaS layer private cloud services, and is widely used in computer field. The Swift module, as one of the OpenStack′s modules, uses the consistent Hash algorithm, and adopts Ring loop method to choose the replica backup node for load balancing and data backup. The implementation mechanism and code of Swift are researched to point out the shortcomings of the selection of the nodes in the replica placement nodes, and then the optimization selection strategy adaptive backup strategy (ABS) is put forward. On the basis of real?time monitoring of the current storage node load, the mechanism selects the recently available nodes adaptively to complete the backup according to predetermined threshold, which can optimize the overall backup efficiency. The proposed replica strategy is compared with the existing replica backup strategy. The experimental results show that the ABS can improve four reading and writing performances of the system by 3.4%~9.1% while maintaining the balance of data replica allocation, and achieves the purpose of optimizing access.
Keywords: replica; data backup; Swift; ABS; adaptive selection; load balancing
0 引 言
根据NIST对云计算的定义,云计算是利用虚拟化技术将各种IT资源整合到一起,以IT资源池的形式向云用户提供“按需获取、按量计费”的一种新的资源使用形式。存储资源是IT资源中比较基础的资源之一,云计算采用大量低成本、低性能的基础设施构建大容量、高性能存储服务[1],所以在行业范围内快速发展。
OpenStack是目前国内外较为流行的开源云计算IaaS层搭建平台,该平台技术已经在多个实践业务领域有过成功的项目经验,且处在快速的版本迭代中,平台功能日趋完善,平台性能日趋稳定。
OpenStack的Swift模块专门负责云存储功能[2],该模块目前主要采用基于复制的静态副本管理策略。其主要思路是根据机架敏感与原理,将数据的一个副本放置在本地机架的存储节点上,以获取较高的网络交换速度,从而提高数据备份的效率;另一个副本放置在不同机架的存储节点上,以牺牲一定的网络交换速度的方式来获取更高的数据可靠性,避免一个机架的故障造成同一机架上的原始数据和备份数据同时损坏,从而造成数据不可恢复。
但是Swift在保持数据一致性时,通过简单的再次哈希方式选取副本存储节点[3],而没有具体分析不同节点在存储性能上的差异,可能形成性能瓶颈并造成整体存储性能优化不够的问题。
为此,本文在深入分析Swift的一致性哈希算法和Ring环机制的基础上,提出一种自适应备份机制,通过综合分析副本节点的计算、存储和网络带宽性能,选取更加合适的副本节点,提高Swift的存储效率。
1 Swift模块
1.1 Swift的存储组织结构
OpenStack是2010年7月,由RackSpace和美国国家航空航天局合作,分别贡献出RackSpace云文件平台代码和NASA Nebula,并以Apache许可证开源发布的一个云计算IaaS层搭建平台[4]。它是一种云操作系统,通过数据中心控制计算、存储和网络资源池,所有的管理工作只需要通过网络接口使用系统自带的Dashboard来操作。
OpenStack主要支持两种形式的存储:一种是对象存储(Object?Based Storage),由Swift模块负责完成;另一种是块存储(Block Storage),由Cinder模块负责完成。
对象存储适合用于存放静态数据[5]。所谓静态数据是指不太可能发生更新,或是更新频率比较低的数据。例如虚拟机的镜像、多媒体数据以及数据备份的副本都属于此类。
Swift从架构上可以分为两个层次:访问层和存储层。访问层负责RESTful请求的处理和用户身份的认证。存储层由一系列的物理存储节点组成,负责对象数据的存储。为了在系统出现故障的情况下有效隔离,存储层在物理上又划分为以下4个部分[6]:
1) Region:物理位置上相互隔绝的地区,每个Swift系统默认至少有一个Region。
2) Zone:一个Region内部相互隔离的硬件区域,一个Zone代表一个独立的存储节点。
3) Device:在OpenStack中,通常是指一个廉价的磁盘。
4) Partition:OpenStack的Partition是指在Device上的文件系统中的目录,不是通常意义上的磁盘分区。在Swift中,副本是以Partition为单位实现的,Swift管理副本的最小粒度是Partition。
Swift所存储的对象在逻辑上又分为Account,Container和Object三个层次[7],如图1所示。
图1 Swift对象存储的逻辑结构
Account代表對象存储过程中的顶层隔离。一个Account代表一个租户,一个租户可能由多个个人账户共同使用。Container代表一组对象的封装,类似文件夹或目录。Swift要求一个对象必须存储在某个Container中,所以一个Account至少应该由一个Container来提供对象的存储。Object代表被存储的确切的数据对象。
1.2 Swift的负载均衡
通过对用Python语言编写的Swift源代码(/common/ring/ring.py文件)进行分析可以发现:Swift主要采用一致性哈希算法来选择存储节点,存放原始数据,以保证节点存储负载的均衡,其核心工作机制如图2所示。
Ring环的主要工作原理如下:根据数据中心存储节点的个数[n],将Ring均匀地分为[n]段,然后每个分段的长度就是[232n]。计算每个待存储对象的Hash值,如果计算结果为[m],那么它就应该分配到[m×232n]分段所对应的节点服务器上。
为了快速寻找对象的副本数据所在节点位置,Ring还要使用2个数据结构表:设备表(Device Table)和设备查询表(Device Lookup Table)。其中,设备表用来记录每一个确切的Device所在的具体位置信息。设备表包含Region,Zone,IP,Port和Weight信息。而设备查询表存储的就是每个副本(默认为3个)所在Device的确切信息。
图2 Swift的Ring环映射图
1.3 Swift的负载均衡
按照Eric Brewer的CAP(Consistency,Availability,Partition Tolerance)理论,数据存储无法同时满足三个方面。
假设变量[N]代表数据的副本总数,变量[W]代表写操作被确认接受的副本数量,变量[R]代表读操作的副本数量。则有如下定义:
强一致性([R+W>N]):在这种一致性原则下,副本的读写操作一定会产生交集,从而保证可以读取到最新版本。
弱一致性([R+W≤N]):在这种一致性原则下,读写操作的副本集合不产生交集,所以可能会读到脏数据;适合对一致性要求比较低的场景。
Swift采用比较折中的策略,写操作需要满足至少一半以上成功,即[W>N2],再保证读操作与写操作的副本集合至少产生一个交集,即[R+W>N]。这种方式称作最终一致性模型(Eventual Consistency),目的是兼顾高可用性和无限水平扩展能力[8]。
Swift默认配置是[N=3],[W=2>N2],[R=1]或2,即每个对象会存在3个副本,这些副本会尽量被存储在不同区域的节点上,[W=2]表示至少需要更新2个副本才算写成功。
当[R=1]时,意味着某一个读操作成功便立刻返回,此种情况下可能会读取到旧版本(弱一致性模型);
当[R=2]时,需要通过在读操作请求中增加[x-]newest=true参数来同时读取2个副本的元数据信息。
然后比较时间戳来确定哪个是最新版本(强一致性模型);如果数据出现不一致,后台服务进程会在一定时间窗口内通过检测和复制协议来完成数据同步,从而保证达到最终一致性。
Swift通过三种服务解决副本数据的一致性问题[9]:
Auditor:通过持续扫描磁盘来检查Account,Container和Object的完整性。如果发现数据有所损坏,Auditor就会对文件进行隔离,然后通过Replicator从其他节点上获取对应的副本以恢复本地数据。
Updater:在创建一个Container时需要对包含该Container的Account信息进行更新,使得该Account数据库里面的Container列表包含新创建的Container。同时,在创建一个Object时,需要对包含该Object的Container信息进行更新,使得该Container的数据库里面的Object列表包含新创建的Object信息。
Replicator:负责检测各个节点上的数据及其副本是否一致。当发现不一致时,会将过时的副本更新为最新版本,并且将标记为删除的数据真正从物理介质上删除。
2 自适应备份策略ABS
2.1 Swift存在的不足
从前面对Swift的分析可以发现:Swift采用Ring结构,使用一致性哈希的原理很好地解决了负载均衡性问题。但是在副本存放节点的选择上,简单地查找通过进一步Hash的方式随机获取放置节点,没有考虑所选节点本身的实时存储性能和网络带宽,这在理论上可能形成两个结果:
1) 副本所在节点设备存储性能有差异,使得数据同步读写时性能降低到与性能较低的设备匹配,降低了系统的整体存储性能。
2) 副本所在Zone的网络带宽有差异,可能使得网络带宽成为数据读写时的瓶颈,降低系统的整体存储性能。
从以往的研究来看也证实了这两种现象。文献[10]发现在千兆网环境下,负载均衡服务器网卡的数据吞吐能力是存储节点利用率的瓶颈。在万兆网和超高并发连接时,存储节点的带宽基本用完,而负载均衡节点和代理节点的带宽还有富余。文献[11]中采用单线程测试上传速率,发现在相同存储环境下,传输相同大小的文件,并发量越大Swift传输性能越高。文献[12]中实测发现多线程比单线程性能提升约25%的Swift写性能,但即使如此,从整体上看,Swift的大文件写性能依然比较差,没有充分利用磁盘的带宽[13]。
2.2 Swift的改进方法
为了弥补Swift的上述两个不足,提高存储效率,可以从存储节点的网络带宽、读写速率、磁盘负载方面着力,尽可能提高基础设施的利用率,在整体上发挥设备性能。
因此,考虑为不同的存储节点增加性能评估预测,在保持整个Ring负载均衡的前提下,选择性能较优的节点作为副本放置的节点[14]。所谓性能较优主要表现为两个方面:
1) 网络性能较优:带宽更高、交换速率更快的网络设备所在节点在选择性上应该更优。
2) 存储性能较优:CPU处理速度更快、磁盘的平均读写速率更快、IOPS更高,当前存取负载较低的节点,在选择性上应该更优。
所以,为了改进Swift的工作性能,必须在对现有节点的负载进行实时监控的情况下[15],根据监控数据评估各个节点,然后根据Hash值和评估结果选择较好的副本存储节点。
2.3 ABS
根据前面的改进思路,绘制出ABS(Adaptive Backup Strategy)工作机制示意图,如图3所示。
图3 ABS工作机制示意图
为了便于描述算法,定义如下概念:
1) 实时负载率[R]:某存储节点的实际负载与满负载情况下的比值。特别地,[Ri]表示第[i]个存储节点的实时负载率。
2) 资源利用率:存儲节点的CPU、磁盘、网络带宽之中任何一个的实时利用情况。
3) 资源上阈值:存储节点的某项资源利用率上限值。
4) 资源下阈值:存储节点的某项资源空闲时的利用率。
并据此定义节点[i]的实时负载率为:
5) 定义VIM(Virtual Infrastructure Manager)负责计算当前所有存储节点的[Ri]值,并依据该值维护负载排序表LST(Load Sorting Table)。
定义当前Ring中所有节点的平均负载率为[Ravg]:
ABS算法的目标就是实时监测当前所选节点的实时负载率。如果实时负载率低于平均负载率,那么选择该节点作为副本放置目标;如果实时负载率高于平均负载率,那么在LST中选择紧挨着该节点的、首个低于平均负载率的节点作为副本放置目标。
2.4 ABS的实现
构建的LST数据结构表中包含三种重要信息,即设备所在的物理地址信息(设备ID),设备的实时负载率和设备的优先级排序。一个可能的LST示意表如表1所示。
表1 LST示意表

3 ABS仿真和分析
3.1 算法仿真
系統仿真使用了6台Dell PowerEdgeT30服务器搭建了基本的OpenStack平台,其中1台作为控制节点,1台作为计算节点,4台作为存储节点。服务器CPU为E3?1225,3.3 GHz,8 MB缓存;内存为16 GB;STAT硬盘,容量1 TB;PCIe接口千兆网卡构成局域网络。
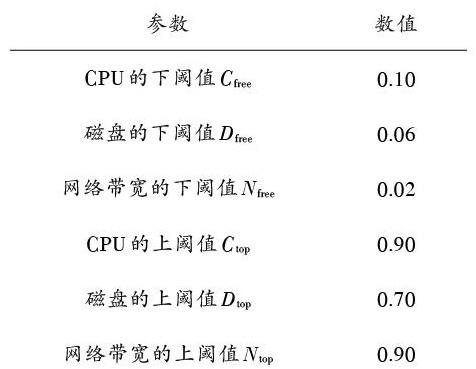
初始参数设置如表2所示。
表2 各项参数数值表
3.2 算法分析
从算法1可以分析得知,整个ABS算法的核心语句就是第6,12,18的if语句块。它们的执行次数决定了整个算法的执行次数量级。
所以,ABS算法在随机状况下近似于最优状况下的执行次数,时间复杂程度随问题规模呈[Ο(n2)]增长态势。
3.3 实测分析
本文所提出的ABS副本放置策略与Swift原来的简单放置策略在负载均衡、资源利用和网络动荡三方面进行了比较。
1) 负载均衡
实验方法:选取大量*.py文件(即OpenStack的源代码文件)放置于/tmp/files目录下。然后用server.py程序启动服务器,将大量的源码文件向测试系统进行上传。所使用命令如下:
图4 负载均衡情况对比

从图4中可以看出,文件总数为1 896,在ABS算法下,存储文件数最多的节点是Node3,有481个,比理论预期值超出0.37%;文件数存储最少的节点是Node4,有466个,比理论预期值偏少0.42%。整体而言,新算法在负载均衡方面基本上保持了原有算法的均衡性。
2) 资源利用
实验方法:通过使用TestDFSIO基准测试来随机评价单个节点磁盘的I/O效率,包括顺序写、顺序读、随机读、反向读四种。得到的对比结果如图5所示。
图5 磁盘资源利用率对比

从图5中可以看出,ABS算法在顺序读和随机读两项操作中提升相对明显,分别提升了9.1%和6.7%的读取性能。但在反向读的读取性能上提升比较有限,仅有4.8%。顺序写的提升最不明显,仅有3.4%。
4 结 语
本文提出的ABS算法在原来Swift一致性哈希原理对副本放置节点的顺序选取基础上进行改进,实现了一种根据实时负载情况进行存储节点选取的增强算法。通过实验分析,ABS算法在保持原来较好的负载均衡优点之上,磁盘读写性能提高了3.4%~9.1%,有了一定的改进。
考虑到磁盘读写带宽和IOPS基本已经达到极限,要想在现有机制下更进一步提高整体存储的效率很难,因此,如何使用纠删码等新方式,通过未来云的强大计算性能来提升副本备份的效率可能成为一个可行的研究方向。
参考文献
[1] XU Jing, YANG Shoubao, WANG Shuling, et al. CDRS: an adaptive cost?driven replication strategy in cloud storage [J]. Journal of the Graduate School of the Chinese Academy of Sciences, 2011, 28(6): 759?767.
[2] 英特尔开源技术中心.OpenStack设计与实现[M].北京:电子工业出版社,2015:183?217.
Intel Open Source Technology Center. The design & implementation of OpenStack [M]. Beijing: Electronic Industry Press, 2015: 183?217.
[3] 戢友.OpenStack开源云王者归来[M].北京: 清华大学出版社,2014:337?369.
JI You. Return of the Open Source Cloud King [M]. Beijing: Tsinghua University Press, 2014: 337?369.
[4] TSUYUZAKI K, SHIRAISHI M. Recent activities involving OpenStack Swift [J]. NTT technical review, 2015, 13(12): 1?6.
[5] KIM J M, JEONG H Y, CHO I, et al. A secure smart?work service model based OpenStack for cloud computing [J]. Cluster computing, 2014, 17(3): 691?702.
[6] ZHANG Tianwei, LEE R B. Monitoring and attestation of virtual machine security health in cloud computing [J]. IEEE micro, 2016, 36(5): 28?37.
[7] YAMATO Yoji. Cloud storage application area of HDD?SSD hybrid storage, distributed storage, and HDD storage [J]. IEEE transactions on electrical & electronic engineering, 2016, 11(5): 674?675.
[8] 荀亚玲,张继福,秦啸.MapReduce集群环境下的数据放置策略[J].软件学报,2015,26(8):2056?2073.
XUN Yaling, ZHANG Jifu, QIN Xiao. Data placement strategy for MapReduce cluster environment [J]. Journal of software, 2015, 26(8): 2056?2073.
[9] 唐震,吴恒,王伟,等.虚拟化环境下面向多目标优化的自适应SSD缓存系统[J].软件学报,2017,28(8):1982?1998.
TANG Zhen, WU Heng, WANG Wei, et al. Self?adaptive SSD caching system for multiobjective optimization in virtualization environment [J]. Journal of software, 2017, 28(8): 1982?1998.
[10] 郑驰.基于OpenStack的对象存储性能实验及研究[J].微型机与应用,2014,33(18):14?16.
ZHENG Chi. Object storage performance testing and research based on the OpenStack [J]. Microcomputer & its applications, 2014, 33(18): 14?16.
[11] 王胜俊.Openstack云平台中Swift组件的研究与测试[J].电脑知识与技术,2016,12(7):77?78.
WANG Shengjun. Research and test of Swift components in Openstack cloud platform [J]. Computer knowledge and technology, 2016, 12(7): 77?78.
[12] 葛江浩.OpenStack Swift关键技术分析与性能评测[J].微型电脑应用,2013,29(11):9?12.
GE Jianghao. The main technology analysis and performance evaluation on OpenStack Swift [J]. Microcomputer applications, 2013, 29(11): 9?12.
[13] 陶永才,巴阳,石磊,等.一种基于可用性的动态云数据副本管理机制[J].小型微型计算机系统,2018,39(3):490?495.
TAO Yongcai, BA Yang, SHI Lei, et al. Management mechanism of dynamic cloud data replica based on availability [J]. Journal of Chinese computer systems, 2018, 39(3): 490?495.
[14] 徐敏.基于OpenStack的Swift负载均衡算法[J].计算机系统应用,2018,27(1):127?131.
XU Min. Swift load balancing algorithm based on OpenStack [J]. Computer systems & applications, 2018, 27(1): 127?131.
[15] 周敬利.改进的云存储系统数据分布策略[J].计算机应用,2012,32(2):309?312.
ZHOU Jingli. Improved data distribution strategy for cloud storage system [J]. Journal of computer applications, 2012, 32(2): 309?312.
[16] 胡丽聪.基于动态反馈的一致性哈希负载均衡算法[J].微电子学与计算机,2012,29(1):177?180.
HU Licong. A consistent Hash load balancing algorithm based on dynamic feedback [J]. Microelectronics & computer, 2012, 29(1): 177?180.
