基于Python的推荐系统的设计与实现
2019-07-08张玉叶
张玉叶

摘 要: 大数据时代的推荐系统可以帮助用户从海量信息中高效地获取自己的潜在需求,是大数据在互联网领域的典型应用。文章介绍了利用Python语言实现的一个基于物品的协同过滤算法推荐系统,给出了系统的基本架构、系统的具体实现过程及相应代码。
关键词: 大数据; 推荐系统; 协同过滤; Python
中图分类号:TP391.1 文献标志码:A 文章编号:1006-8228(2019)06-59-04
Abstract: The recommendation system in the big data era can help users to obtain their potential needs efficiently from the huge amount of information, which is a typical application of big data in the Internet field. A recommendation system based on object-based collaborative filtering algorithm and implemented with Python language is introduced in this paper, and the basic architecture of the system, the specific implementation process of the system, and the corresponding code are given.
Key words: big data; recommendation system; collaborative filtering; Python
0 引言
随着网络技术的飞速发展,网络信息量也快速增长,为了更好地满足用户的个性化需求,各种推荐系统应运而生,它通过研究用户的兴趣偏好,自动建立起用户和信息之间的联系,从而帮助用户从海量信息中去发掘自己潜在的需求。推荐系统的关键是推荐算法,常用的推荐算法主要有专家推荐、基于统计的推荐、基于内容的推荐和协同过滤推荐等。Python语言是一开源、免费、跨平台的解释型高级动态编程语言,其强大的功能及使用的简洁方便使其成为互联网应用系统开发的首选语言。本文利用Python语言实现了一个基于物品的协同过滤算法的推荐系统。
1 推荐系统
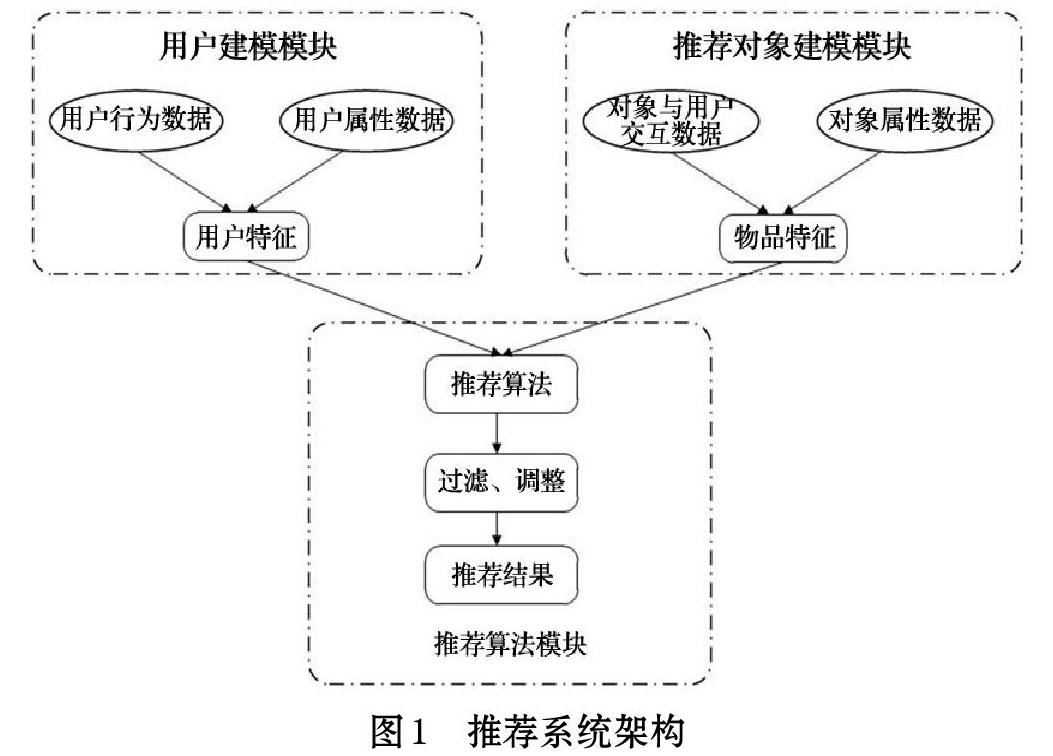
推荐系统是建立在海量数据挖掘基础上的,通过分析用户的历史数据来了解用户的需求和兴趣,从而将用户感兴趣的信息、物品等主动推荐给用户,其本质是建立用户与物品之间的联系。一个完整的推荐系统通常包含三个模块:用户建模模块、推荐对象建模模块和推荐算法模块。推荐系统首先对用户建模,根据用户的行为数据和属性数据来分析用户的兴趣和需求,同时也对推荐对象进行建模。接着,基于用户特征和物品对象特征,采用推荐算法计算得到用户可能感兴趣的物品,然后根据推荐场景对推荐结果进行一定的推荐和调整,最终将推荐结果展示给用户,其基本架构如图1所示[1]。
2 协同过滤算法
协同过滤算法分为基于用户的协同过滤算法和基于物品的协同过滤算法[1]。
基于用户的协同过滤算法(简称UserCF),通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法(简称ItemCF),通过用户对不同物品的评分来评测物品之间的相似性,基于物品之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
UserCF算法和ItemCF算法思想类似,其实现过程也基本类似,唯一不同的是一个是计算用户相似度,一个是计算物品相似度。
UserCF算法和ItemCF最主要的区别在于:UserCF推荐的是那些和目標用户有共同兴趣爱好的其他用户所喜欢的物品,ItemCF算法则推荐那些和目标用户之前喜欢的物品类似的其他物品。因此,UserCF算法的推荐更偏向社会化,适合应用于新闻推荐、微博话题推荐等应用场景;而ItemCF算法的推荐则更偏向于个性化,适合应用于电子商务、电影、图书等应用场景。
3 推荐系统的设计与实现
3.1 推荐算法
本推荐系统以一电影推荐系统为例,因此采用基于物品的协同过滤算法(简称ItemCF)。基于物品的协同过滤算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品。此算法并不利用物品的内容属性计算物品之间的相似度,而主要通过分析用户的行为记录来计算物品之间的相似度。该算法基于的假设是:物品I1和物品I2具有很大的相似度,是因为喜欢物品I1的用户大多也喜欢物品I2。ItemCF算法主要包括两步。
step1:计算物品之间的相似度
计算相似度的算法有很多,如泊松相关系数、余弦相似度等,在此可直接利用同现矩阵[2,3]进行计算。
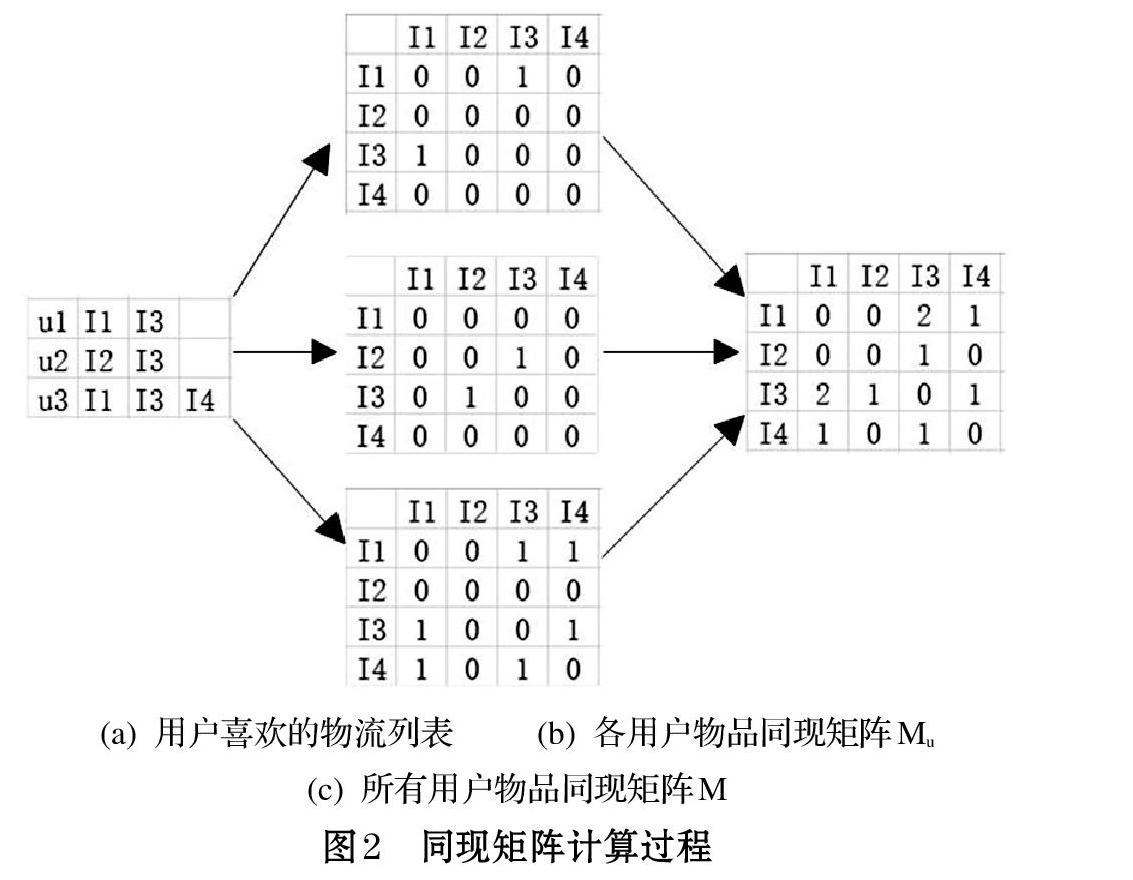
设有三个用户u1、u2、u3和四件物品I1、I2、I3、I4,每个用户喜欢的物品列表如图2中的(a)所示。
对每个用户u喜欢的物品列表都建立一个物品同现矩阵Mu,如用户u1喜欢物品I1和I3,则其物品同现矩阵中Mu1[I1][I3]和Mu1[I3][I1]的值为1,依次类推,由用户喜欢的物品列表可得到每个用户的物品同现矩阵Mu,如图2中的(b)所示。然后将所有用户的物品同现矩阵相加得到最终的所有用户物品同现矩阵M,如图2中的(c)所示。
根据物品的同现矩阵和用户的历史行为,来求解推荐评分,然后根据推荐评分给用户生成推荐列表。推荐评分=物品同现矩阵*用户评分向量[4]。
3.2 数据准备
在此以MovieLens(http://grouplens.org/datasets/movielens)作為本推荐系统中的实验数据。MovieLens是GroupLens Research实验室的一个非商业性质、以研究为目的的实验性项目,采集了一组从20世纪90年代末到21世纪初的电影评分数据,包含大小不同的数据集,每个数据集中包括电影信息数据及电影评分记录等。
本系统采用MovieLens 1M数据集。该数据集中存放电影评分记录的文件是“ratings.csv”,其数据格式如图3所示,每一行用逗号分隔的四个数据分别表示用户ID、电影ID、评分和评分时间戳,本推荐系统中只使用前三个数据元素。
数据集中存放电影信息数据的文件是“movies.csv”,其数据格式如图4所示,系统中主要使用前两个数据:电影ID和电影名称(年份)。
基于此数据集,如何通过已知的用户评分记录来预测未知的用户评分,通过此评分来预测用户是否会喜欢某部电影,从而决定是否给用户推荐该电影。实现时采用Top-N推荐,即为目标用户提供一个长度为N的推荐列表。
3.3 数据处理
首先,将所需数据读入并进行一定的预处理,将用户评分记录的前3项(用户ID、电影ID、评分)和电影信息文件的前2项(电影ID和电影名称)依次读出并放到字典中。评分记录信息用于求解电影相似度,电影信息用于推荐结果展示。其Python代码[4-6]如下:
3.4 建立同现矩阵
同现矩阵是一稀疏矩阵,在此采用Python内置序列字典来存放,可有效提高算法空间和时间效率。其实现代码如下:
3.5 计算推荐评分及推荐结果
当同现矩阵计算完成后,根据同现矩阵和用户评分来计算用户对未观看过的相似电影的推荐评分(也即兴趣度),根据推荐评分高低来针对用户进行电影推荐。其实现代码如下:
3.6 输出推荐结果
根据需要来输出某个用户的Top-N推荐结果,其代码如下:
调用主函数main("ratings.csv","movies.csv","2",10)对用户2,为其推荐10部未曾看过的电影,得到的推荐结果如图5所示。
4 结束语
推荐系统可帮助用户从海量信息中高效地获取自己潜在需求,是大数据在互联网领域的典型应用,通过分析用户的历史记录来了解用户的喜好,从而主动为用户推荐其感兴趣的信息,满足用户的个性化需求。本文利用Python语言实现的基于物品的协同过滤算法的电影推荐系统具有普适性,在该系统基础上稍加修改,就可应用于音乐推荐系统、图书推荐系统、商品推荐系统等,具有广阔的应用前景。
参考文献(References):
[1] [美]查鲁.C.阿加沃尔.推荐系统:原理与实践[M].机械工业出版社,2018.
[2] 项亮.推荐系统实践[M].人民邮电出版社,2012.
[3] 林子雨.大数据技术原理与应用[M].人民邮电出版社,2017.
[4] 王建芳.机器学习算法实践[M].清华大学出版社,2018.
[5] 黑马程序员.Python实战编程[M].中国铁道出版社,2018.
[6] 董付国.Python程序设计开发宝典[M].清华大学出版社,2017.
