基于CBR技术的能耗在线监测系统异常数据检测方法研究
2019-07-05徐振兴葛志松许骏龙张进明
徐振兴 葛志松 许骏龙 张进明
上海市计量测试技术研究院
0 概述
能耗在线监测系统的数据是面向能源主题的数据集合,这些数据从多个业务系统中抽取而来,并包含历史数据,不可避免会包含错误数据,或有相互之间有冲突的数据。这些错误的、有冲突的数据通常被称为异常数据。在实际的数据统计分析中,异常数据通常有以下几种表现形式:数据遗失、信息缺失、数据不一致、数据重复、数据离群等数据质量问题。
异常数据检测是数据清洗(data cleaning)过程的第一步,是指对数据质量问题的监测和识别,其任务是发现数据观测值中真正的异常点,将数学特征显著不同于其他数据的观测值识别并标识出来,以便于后续对数据的修复和纠正。对于数据遗失、信息缺失问题,通常是通过人工检索的方式进行识别和修复,对于数据不一致、数据重复、数据离群等问题,通常通过四分法、差分法、滑动平均法或者聚类分析等方法进行多角度的识别,综合判断、纠正和修复数据。
基于案例的推理(Case-Based Reasoning,简称CBR)是人工智能的一个分支,它是一种根据过去的实际经验或经历的深度学习,并用以支撑未来问题的解决。在解决能耗在线监测系统异常数据问题的过程中,也是一个经验不断积累过程,可以用人工智能的方式尝试从以往类似的案例中找到合适的解决方案。本文对CBR技术的数据质量管控流程进行归纳,并采用CBR技术对能耗在线监测系统中的异常数据进行检测和识别,对该技术在能耗数据质量问题的应用进行试验。
1 能耗在线监测系统数据质量现状
当能耗在线监测的对象从一个单体的工业企业或一栋大楼,扩展成一个区域乃至一个城市时,带来的变化不仅是项目边界的扩大、传输网络复杂程度的提高,还会带来数据采集节点的几何倍数的数量增大,以及数据种类、数据量的爆炸式增长。以上海市重点用能单位能耗在线监测系统信息化平台为例,在接入500多个重点用能单位的部分能源种类一级计量数据时,接入3 000多个数据采集节点,包含电能、蒸汽、燃气、煤等不同能源种类。其中,电能采集对象进一步细分为有功功率、无功功率、有功累积电量、无功累积电量等;蒸汽采集对象细分为工况流速、工况流量、温度、压力等;燃气细分为天然气、人工煤气、工况流速、工况流量、温度、压力等;加上时间戳、采集位置等基本信息以及计量单位等辅助信息,以15min/次的频率进行采集,每天的实时采集能源数据已超过300 000条次,动态流量约1Mb/min。随着系统平台对于企业范围、能源种类覆盖面的不断扩大,接入的能耗数据量进一步提升之后,系统的数据处理能力面临着较大的挑战。
在对系统中的能耗数据进行分析时,抽取了某种能源3 340个采集节点每天0:00的数据,连续采样352天。经初步统计分析,得到的结果见表1。
在352天的时间范围内,应该获得的数据条数为1 175 680条,实际获得的数据条数为1 065 932条,为应有数据的91%;遗失的数据条数为109 748条,占应有数据的9%。
在获得的1 065 932条数据中,由于数据中所包含字段信息缺失而无法计算能耗的数据条数为18 972条,占实际数据的1.8%;根据数据中所包含字段计算得到能耗值为零值或者负值等明显不合理的数据条数为28 919条,占实际数据的2.7%;包含完整字段信息的数据条数为1 018 041条,占实际数据的95.5%。数据情况见表2。

表1 系统能耗数据抽样分析表

表2 系统实际获取的能耗数据抽样分析表
需要指出的是,即使在信息完整的1 018 041条数据中,仍然存在数据重复、计量单位错误、极大值、极小值等问题,需要通过多种的数据处理手段对这些问题进行识别,进而剔除或修复,使能耗数据可供后期统计和分析使用。
2 基于CBR技术的异常数据检测方法
耶鲁大学R.Schank首先提出了CBR技术的概念和原理,提出了动态存储、历史环境及环境模式回忆对问题求解的作用。案例推理的过程可以看作是一个4R(Retrieve,Reuse,Revise,Retain)的循环过程,即相似案例检索、案例重用、案例的修改和调整、案例学习等四个步骤的循环。
当遇到新的数据质量问题时,将新问题通过案例描述输入基于CBR技术搭建的模型;模型将检索出与目标案例最匹配的案例,若有与目标案例情况一致的源案例,则将其解决方案直接提交给用户;若没有完全一致的案例则根据目标案例的情况对相似案例的解决方案进行调整和修改,若效果满意则将新的解决方案提交给使用者,若不满意则需要继续对解决方案进行调整和修改;对效果满意的解决方案进行评价和学习,并将其保存到案例库,如图1所示。

图1 基于CBR技术的数据质量管控流程示意图
CBR技术是在特定领域内进行问题求解和自学习的方法,不存在普遍使用的CBR方法,是一个动态的、不断学习的过程。对于特定领域的应用,基于该技术搭建的系统均由4个部分组成:案例表示、案例检索、案例的调整和修改和案例学习。基于CBR技术的异常数据检测流程如图2所示:
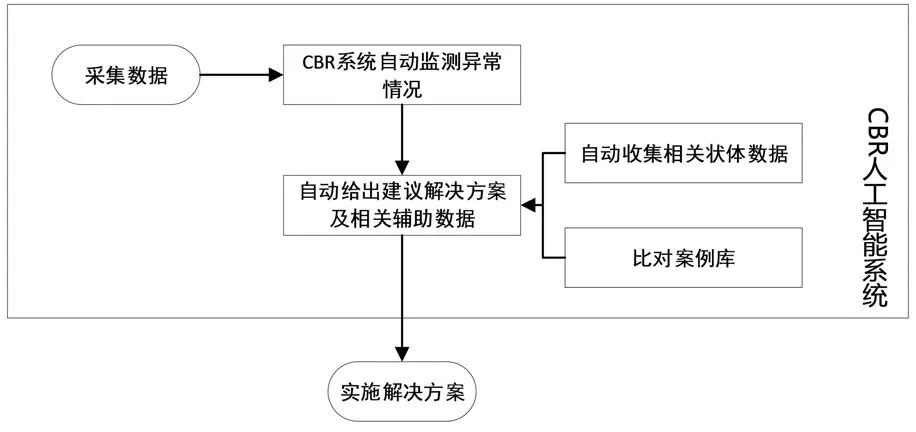
图2 基于CBR技术的异常数据检测流程示意图
整个异常数据检测的流程由CBR模型自动完成,只需人工最后确认实施解决方案即可,提高了数据质量管控的效率。同时,由于异常数据的检查、判断、解决方案的建议均由计算机自动进行,对数据管控人员的计算机知识要求不高,可以提高数据质量管控结果的有效性。
3 基于CBR技术对能耗在线监测系统异常数据检测的试验
基于CBR技术的能耗在线监测系统异常数据检测方法是从案例库中找到与当前问题最相关的案例,然后对该案例做必要的改动以适合当前需解决的问题。在对系统进行综合判断和评价时,可将当前运行数据(如电力、温度、压力、流量、通讯状况、数据等重要监测参数)、数据质量评价、诊断结果、处理意见等,以案例的形式存入案例库,作为知识库的一部分。当下次对数据质量管控进行综合判断、评价或遇到问题时,可以从案例库中检索相似案例,为当前问题提供参考。相似案例一般是按最显著的特征进行索引,这样可高效检索那些与当前问题具有相当数量公共特征的案例。检索相似案例的算法有最近邻算法、决策树算法、朴素贝叶斯等机器学习算法,及深度神经网络算法等。当检索到相似案例之后,可以重用这个案例,给出初步解决或处理意见,可以是文字性描述,或是推导过程,也可以是参数化关系模型;当进行案例重用时,系统根据提前预定义的某种案例修改策略对相似案例的解决方案进行调整和修改,并将调整和修改后的方案交给用户。用户也可对维修或处理意见进行手工修改,以满足数据质量管控问题的需要。当问题解决后,可以将这些数据保存起来,作为新的案例,成为案例库的一个案例,以使案例库不断丰富,案例库中案例越多,覆盖面越广,越有利于故障诊断质量的提高。
以能耗在线监测系统中的能耗数据作为试验对象,基于CBR技术建立异常数据检测模型,并抽取某种能源某一个采集节点连续352天的能耗数据进行长周期(352天)、中周期(30天)、短周期(7天)三个不同周期的异常数据检测试验,可得到如图3的结果。

图3 长周期异常数据检测结果示意图
在长周期(352天)异常数据检测试验中,使用基于CBR技术的异常数据检测方法可以准确识别到所有的异常点,包括数据极大值和数据负值两种情况均可被正常识别,没有发生误判的情况。
在中周期(30天)异常数据检测试验中,使用基于CBR技术的异常数据检测方法同样可以准确识别到所有的数据负值异常点,见图4。

图4 中周期异常数据检测结果示意图
在短周期(7天)异常数据检测试验中,由于在该时间范围内能耗数据本身没有异常,使用基于CBR技术的异常数据检测方法未出现数据误判的情况见图5。

图5 短周期异常数据检测结果示意图
在本项目所做的其他抽样异常数据检测试验中,也均能得到与展示案例相同的结果,无论在长周期(352天)、中周期(30天)和短周期(7天),基于CBR技术的异常数据检测方法能对各种数据质量异常问题进行识别和判定。
4 结论
能耗在线监测系统需要采集大量的能耗实时数据和相关能耗信息,主要范围包括企业能耗监测数据、公共供能单位数据、其他相关业务数据和各级能源计量平台数据等。随着系统平台持续的运行,大量数据的汇集,及数据质量管控的标准不一致,导致数据质量问题突出。基于CBR技术的异常数据检测方法能够有效地解决数据异常点识别的问题,通过相似案例检索、案例重用、案例的修改与调整和案例学习四个步骤的循环不断完善案例库,并建立案例信息库采集的关键指标项,组织、索引不断提高检索和重用的效率,然后从案例库中搜索出与目标案例最为相似,对目标案例最有帮助的案例,根据需求和新情况对案例进行修改和调整,最终产生适用于新问题的解决方案。通过本项目中对CBR技术的应用试验,论证了该技术在能耗在线监测系统异常数据检测方法上的可行性,有较好的应用前景。
